Move the docs folder
This commit is contained in:
committed by
 LINxiansheng
LINxiansheng
parent
7c6dcc6712
commit
d42f317422
@ -0,0 +1,23 @@
|
||||
SQL 请求执行流程
|
||||
===============================
|
||||
|
||||
|
||||
|
||||
SQL 引擎从接受 SQL 请求到执行的典型流程如下图所示:
|
||||
|
||||

|
||||
|
||||
下表为 SQL 请求执行流程的步骤说明。
|
||||
|
||||
|
||||
| **步骤** | **说明** |
|
||||
|-----------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Parser(词法/语法解析模块) | 在收到用户发送的 SQL 请求串后,Parser 会将字符串分成一个个的"单词",并根据预先设定好的语法规则解析整个请求,将 SQL 请求字符串转换成带有语法结构信息的内存数据结构,称为语法树(Syntax Tree)。 |
|
||||
| Plan Cache(执行计划缓存模块) | 执行计划缓存模块会将该 SQL 第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免了重复查询优化的过程。 |
|
||||
| Resolver(语义解析模块) | Resolver 将生成的语法树转换为带有数据库语义信息的内部数据结构。在这一过程中,Resolver 将根据数据库元信息将 SQL 请求中的 Token 翻译成对应的对象(例如库、表、列、索引等),生成的数据结构叫做 Statement Tree。 |
|
||||
| Transfomer(逻辑改写模块) | 分析用户 SQL 的语义,并根据内部的规则或代价模型,将用户 SQL 改写为与之等价的其他形式,并将其提供给后续的优化器做进一步的优化。Transformer 的工作方式是在原 Statement Tree 上做等价变换,变换的结果仍然是一棵 Statement Tree。 |
|
||||
| Optimizer(优化器) | 优化器是整个 SQL 请求优化的核心,其作用是为 SQL 请求生成最佳的执行计划。在优化过程中,优化器需要综合考虑 SQL 请求的语义、对象数据特征、对象物理分布等多方面因素,解决访问路径选择、联接顺序选择、联接算法选择、分布式计划生成等多个核心问题,最终选择一个对应该 SQL 的最佳执行计划。 |
|
||||
| Code Generator(代码生成器) | 将执行计划转换为可执行的代码,但是不做任何优化选择。 |
|
||||
| Executor(执行器) | 启动 SQL 的执行过程。 * 对于本地执行计划,Executor 会简单的从执行计划的顶端的算子开始调用,根据算子自身的逻辑完成整个执行的过程,并返回执行结果。 * 对于远程或分布式计划,将执行树分成多个可以调度的子计划,并通过 RPC 将其发送给相关的节点去执行。 |
|
||||
|
||||
|
||||
@ -0,0 +1,190 @@
|
||||
SQL 执行计划简介
|
||||
===============================
|
||||
|
||||
执行计划(EXPLAIN)是对一条 SQL 查询语句在数据库中执行过程的描述。
|
||||
|
||||
用户可以通过 `EXPLAIN` 命令查看优化器针对给定 SQL 生成的逻辑执行计划。如果要分析某条 SQL 的性能问题,通常需要先查看 SQL 的执行计划,排查每一步 SQL 执行是否存在问题。所以读懂执行计划是 SQL 优化的先决条件,而了解执行计划的算子是理解 `EXPLAIN` 命令的关键。
|
||||
|
||||
EXPLAIN 命令格式
|
||||
---------------------------------
|
||||
|
||||
OceanBase 数据库的执行计划命令有三种模式:`EXPLAIN BASIC`、`EXPLAIN` 和 `EXPLAIN EXTENDED`。这三种模式对执行计划展现不同粒度的细节信息:
|
||||
|
||||
* `EXPLAIN BASIC` 命令用于最基本的计划展示。
|
||||
|
||||
|
||||
|
||||
* `EXPLAIN EXTENDED` 命令用于最详细的计划展示(通常在排查问题时使用这种展示模式)。
|
||||
|
||||
|
||||
|
||||
* `EXPLAIN` 命令所展示的信息可以帮助普通用户了解整个计划的执行方式。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
命令格式如下:
|
||||
|
||||
```sql
|
||||
EXPLAIN [BASIC | EXTENDED | PARTITIONS | FORMAT = format_name] explainable_stmt
|
||||
format_name: { TRADITIONAL | JSON }
|
||||
explainable_stmt: { SELECT statement
|
||||
| DELETE statement
|
||||
| INSERT statement
|
||||
| REPLACE statement
|
||||
| UPDATE statement }
|
||||
```
|
||||
|
||||
|
||||
|
||||
执行计划形状与算子信息
|
||||
--------------------------------
|
||||
|
||||
在数据库系统中,执行计划在内部通常是以树的形式来表示的,但是不同的数据库会选择不同的方式展示给用户。
|
||||
|
||||
如下示例分别为 PostgreSQL 数据库、Oracle 数据库和 OceanBase 数据库对于 TPCDS Q3 的计划展示。
|
||||
|
||||
```sql
|
||||
obclient>SELECT /*TPC-DS Q3*/ *
|
||||
FROM (SELECT dt.d_year,
|
||||
item.i_brand_id brand_id,
|
||||
item.i_brand brand,
|
||||
Sum(ss_net_profit) sum_agg
|
||||
FROM date_dim dt,
|
||||
store_sales,
|
||||
item
|
||||
WHERE dt.d_date_sk = store_sales.ss_sold_date_sk
|
||||
AND store_sales.ss_item_sk = item.i_item_sk
|
||||
AND item.i_manufact_id = 914
|
||||
AND dt.d_moy = 11
|
||||
GROUP BY dt.d_year,
|
||||
item.i_brand,
|
||||
item.i_brand_id
|
||||
ORDER BY dt.d_year,
|
||||
sum_agg DESC,
|
||||
brand_id)
|
||||
WHERE rownum <= 100;
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
* PostgreSQL 数据库执行计划展示如下:
|
||||
|
||||
```sql
|
||||
Limit (cost=13986.86..13987.20 rows=27 width=91)
|
||||
-> Sort (cost=13986.86..13986.93 rows=27 width=65)
|
||||
Sort Key: dt.d_year, (sum(store_sales.ss_net_profit)), item.i_brand_id
|
||||
-> HashAggregate (cost=13985.95..13986.22 rows=27 width=65)
|
||||
-> Merge Join (cost=13884.21..13983.91 rows=204 width=65)
|
||||
Merge Cond: (dt.d_date_sk = store_sales.ss_sold_date_sk)
|
||||
-> Index Scan using date_dim_pkey on date_dim dt (cost=0.00..3494.62 rows=6080 width=8)
|
||||
Filter: (d_moy = 11)
|
||||
-> Sort (cost=12170.87..12177.27 rows=2560 width=65)
|
||||
Sort Key: store_sales.ss_sold_date_sk
|
||||
-> Nested Loop (cost=6.02..12025.94 rows=2560 width=65)
|
||||
-> Seq Scan on item (cost=0.00..1455.00 rows=16 width=59)
|
||||
Filter: (i_manufact_id = 914)
|
||||
-> Bitmap Heap Scan on store_sales (cost=6.02..658.94 rows=174 width=14)
|
||||
Recheck Cond: (ss_item_sk = item.i_item_sk)
|
||||
-> Bitmap Index Scan on store_sales_pkey (cost=0.00..5.97 rows=174 width=0)
|
||||
Index Cond: (ss_item_sk = item.i_item_sk)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* Oracle 数据库执行计划展示如下:
|
||||
|
||||
```sql
|
||||
Plan hash value: 2331821367
|
||||
--------------------------------------------------------------------------------------------------
|
||||
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
|
||||
--------------------------------------------------------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 100 | 9100 | 3688 (1)| 00:00:01 |
|
||||
|* 1 | COUNT STOPKEY | | | | | |
|
||||
| 2 | VIEW | | 2736 | 243K| 3688 (1)| 00:00:01 |
|
||||
|* 3 | SORT ORDER BY STOPKEY | | 2736 | 256K| 3688 (1)| 00:00:01 |
|
||||
| 4 | HASH GROUP BY | | 2736 | 256K| 3688 (1)| 00:00:01 |
|
||||
|* 5 | HASH JOIN | | 2736 | 256K| 3686 (1)| 00:00:01 |
|
||||
|* 6 | TABLE ACCESS FULL | DATE_DIM | 6087 | 79131 | 376 (1)| 00:00:01 |
|
||||
| 7 | NESTED LOOPS | | 2865 | 232K| 3310 (1)| 00:00:01 |
|
||||
| 8 | NESTED LOOPS | | 2865 | 232K| 3310 (1)| 00:00:01 |
|
||||
|* 9 | TABLE ACCESS FULL | ITEM | 18 | 1188 | 375 (0)| 00:00:01 |
|
||||
|* 10 | INDEX RANGE SCAN | SYS_C0010069 | 159 | | 2 (0)| 00:00:01 |
|
||||
| 11 | TABLE ACCESS BY INDEX ROWID| STORE_SALES | 159 | 2703 | 163 (0)| 00:00:01 |
|
||||
--------------------------------------------------------------------------------------------------
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* OceanBase 数据库执行计划展示如下:
|
||||
|
||||
```sql
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------
|
||||
|0 |LIMIT | |100 |81141|
|
||||
|1 | TOP-N SORT | |100 |81127|
|
||||
|2 | HASH GROUP BY | |2924 |68551|
|
||||
|3 | HASH JOIN | |2924 |65004|
|
||||
|4 | SUBPLAN SCAN |VIEW1 |2953 |19070|
|
||||
|5 | HASH GROUP BY | |2953 |18662|
|
||||
|6 | NESTED-LOOP JOIN| |2953 |15080|
|
||||
|7 | TABLE SCAN |ITEM |19 |11841|
|
||||
|8 | TABLE SCAN |STORE_SALES|161 |73 |
|
||||
|9 | TABLE SCAN |DT |6088 |29401|
|
||||
=======================================================
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
由示例可见,OceanBase 数据库的计划展示与 Oracle 数据库类似。OceanBase 数据库执行计划中的各列的含义如下:
|
||||
|
||||
|
||||
| 列名 | 含义 |
|
||||
|-----------|----------------------------|
|
||||
| ID | 执行树按照前序遍历的方式得到的编号(从 0 开始)。 |
|
||||
| OPERATOR | 操作算子的名称。 |
|
||||
| NAME | 对应表操作的表名(索引名)。 |
|
||||
| EST. ROWS | 估算该操作算子的输出行数。 |
|
||||
| COST | 该操作算子的执行代价(微秒)。 |
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
在表操作中,NAME 字段会显示该操作涉及的表的名称(别名),如果是使用索引访问,还会在名称后的括号中展示该索引的名称, 例如 t1(t1_c2) 表示使用了 t1_c2 这个索引。如果扫描的顺序是逆序,还会在后面使用 RESERVE 关键字标识,例如 `t1(t1_c2,RESERVE)`。
|
||||
|
||||
OceanBase 数据库 `EXPLAIN` 命令输出的第一部分是执行计划的树形结构展示。其中每一个操作在树中的层次通过其在 operator 中的缩进予以展示。树的层次关系用缩进来表示,层次最深的优先执行,层次相同的以特定算子的执行顺序为标准来执行。
|
||||
|
||||
上述 TPCDS Q3 示例的计划展示树如下:
|
||||
|
||||
OceanBase 数据库 `EXPLAIN` 命令输出的第二部分是各操作算子的详细信息,包括输出表达式、过滤条件、分区信息以及各算子的独有信息(包括排序键、连接键、下压条件等)。示例如下:
|
||||
|
||||
```unknow
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), sort_keys([t1.c1, ASC], [t1.c2, ASC]), prefix_pos(1)
|
||||
1 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil),
|
||||
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
|
||||
2 - output([t2.c1], [t2.c2]), filter(nil), sort_keys([t2.c2, ASC])
|
||||
3 - output([t2.c2], [t2.c1]), filter(nil),
|
||||
access([t2.c2], [t2.c1]), partitions(p0)
|
||||
4 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
TABLE SCAN
|
||||
===============================
|
||||
|
||||
TABLE SCAN 算子是存储层和 SQL 层的接口,用于展示优化器选择哪个索引来访问数据。
|
||||
|
||||
在 OceanBase 数据库中,对于普通索引,索引的回表逻辑是封装在 TABLE SCAN 算子中的;而对于全局索引,索引的回表逻辑由 TABLE LOOKUP 算子完成。
|
||||
|
||||
示例:含 TABLE SCAN 算子的执行计划
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT, c3 INT, c4 INT,
|
||||
INDEX k1(c2,c3));
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN EXTENDED SELECT * FROM t1 WHERE c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ==================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
----------------------------------
|
||||
|0 |TABLE GET|t1 |1 |53 |
|
||||
==================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1(0x7f22fbe69340)], [t1.c2(0x7f22fbe695c0)], [t1.c3(0x7f22fbe69840)], [t1.c4(0x7f22fbe69ac0)]), filter(nil),
|
||||
access([t1.c1(0x7f22fbe69340)], [t1.c2(0x7f22fbe695c0)], [t1.c3(0x7f22fbe69840)], [t1.c4(0x7f22fbe69ac0)]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1(0x7f22fbe69340)]), range[1 ; 1],
|
||||
range_cond([t1.c1(0x7f22fbe69340) = 1(0x7f22fbe68cf0)])
|
||||
|
||||
Q2:
|
||||
obclient>EXPLAIN EXTENDED SELECT * FROM t1 WHERE c2 < 1 AND c3 < 1 AND
|
||||
c4 < 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |TABLE SCAN|t1(k1)|100 |12422|
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1(0x7f22fbd1e220)], [t1.c2(0x7f227decec40)], [t1.c3(0x7f227decf9b0)], [t1.c4(0x7f22fbd1dfa0)]), filter([t1.c3(0x7f227decf9b0) < 1(0x7f227decf360)], [t1.c4(0x7f22fbd1dfa0) < 1(0x7f22fbd1d950)]),
|
||||
access([t1.c2(0x7f227decec40)], [t1.c3(0x7f227decf9b0)], [t1.c4(0x7f22fbd1dfa0)], [t1.c1(0x7f22fbd1e220)]), partitions(p0),
|
||||
is_index_back=true, filter_before_indexback[true,false],
|
||||
range_key([t1.c2(0x7f227decec40)], [t1.c3(0x7f227decf9b0)], [t1.c1(0x7f22fbd1e220)]),
|
||||
range(NULL,MAX,MAX ; 1,MIN,MIN),
|
||||
range_cond([t1.c2(0x7f227decec40) < 1(0x7f227dece5f0)])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细展示了 TABLE SCAN 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|---------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| operator | TABLE SCAN 算子的 operator 有两种形式:TABLE SCAN 和 TABLE GET。 * TABLE SCAN:属于范围扫描,会返回 0 行或者多行数据。 * TABLE GET:直接用主键定位,返回 0 行或者 1 行数据。 |
|
||||
| name | 选择用哪个索引来访问数据。选择的索引的名字会跟在表名后面,如果没有索引的名字,则说明执行的是主表扫描。 这里需要注意,在 OceanBase 数据库中,主表和索引的组织结构是一样的,主表本身也是一个索引。 |
|
||||
| output | 该算子的输出列。 |
|
||||
| filter | 该算子的过滤谓词。 由于示例中 TABLE SCAN 算子没有设置 filter,所以为 nil。 |
|
||||
| partitions | 查询需要扫描的分区。 |
|
||||
| is_index_back | 该算子是否需要回表。 例如,在 Q1 查询中,因为选择了主表,所以不需要回表。在 Q2 查询中,索引列是 `(c2,c3,c1)`, 由于查询需要返回 c4 列,所以需要回表。 |
|
||||
| filter_before_indexback | 与每个 filter 对应,表明该 filter 是可以直接在索引上进行计算,还是需要索引回表之后才能计算。 例如,在 Q2 查询中,filter `c3 < 1` 可以直接在索引上计算,能减少回表数量;filter `c4 < 1` 需要回表取出 c4 列之后才能计算。 |
|
||||
| range_key/range/range_cond | * range_key:索引的 rowkey 列。 <!-- --> * range:索引开始扫描和结束扫描的位置。判断是否是全表扫描需要关注 range 的范围。例如,对于一个 rowkey 有三列的场景,`range(MIN,MIN, MIN ; MAX, MAX, MAX)`代表的就是真正意义上的全表扫描。 * range_cond:决定索引开始扫描和结束扫描位置的相关谓词。 |
|
||||
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
MATERIAL
|
||||
=============================
|
||||
|
||||
MATERIAL 算子用于物化下层算子输出的数据。
|
||||
|
||||
OceanBase 数据库以流式数据执行计划,但有时算子需要等待下层算子输出所有数据后才能够开始执行,所以需要在下方添加一个 MATERIAL 算子物化所有的数据。或者在子计划需要重复执行的时候,使用 MATERIAL 算子可以避免重复执行。
|
||||
|
||||
如下示例中,t1 表与 t2 表执行 NESTED LOOP JOIN 运算时,右表需要重复扫描,可以在右表有一个 MATERIAL 算子,保存 t2 表的所有数据。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT, c3 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT ,c2 INT ,c3 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+ORDERED USE_NL(T2)*/* FROM t1,t2
|
||||
WHERE t1.c1=t2.c1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |2970 |277377|
|
||||
|1 | TABLE SCAN |t1 |3 |37 |
|
||||
|2 | MATERIAL | |100000 |176342|
|
||||
|3 | TABLE SCAN |t2 |100000 |70683 |
|
||||
===========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2], [t1.c3], [t2.c1], [t2.c2], [t2.c3]), filter(nil),
|
||||
conds([t1.c1 = t2.c1]), nl_params_(nil)
|
||||
1 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil),
|
||||
access([t1.c1], [t1.c2], [t1.c3]), partitions(p0)
|
||||
2 - output([t2.c1], [t2.c2], [t2.c3]), filter(nil)
|
||||
3 - output([t2.c1], [t2.c2], [t2.c3]), filter(nil),
|
||||
access([t2.c1], [t2.c2], [t2.c3]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中 2 号算子 MATERIAL 的功能是保存 t2 表的数据,以避免每次联接都从磁盘扫描 t2 表的数据。执行计划展示中的 outputs \& filters 详细展示了 MATERIAL 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 其中 rownum() 表示 ROWNUM 对应的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 MATERIAL 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
@ -0,0 +1,42 @@
|
||||
SORT
|
||||
=========================
|
||||
|
||||
SORT 算子用于对输入的数据进行排序。
|
||||
|
||||
示例:对 t1 表的数据排序,并按照 c1 列降序排列和 c2 列升序排列
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT c1 FROM t1 ORDER BY c1 DESC, c2 ASC\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |SORT | |3 |40 |
|
||||
|1 | TABLE SCAN|t1 |3 |37 |
|
||||
====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1]), filter(nil), sort_keys([t1.c1, DESC], [t1.c2, ASC])
|
||||
1 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中 0 号算子 SORT 对 t1 表的数据进行排序,执行计划展示中的 outputs \& filters 详细展示了 SORT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子的输出列。 |
|
||||
| filter | 该算子的过滤谓词。 由于示例中 SORT 算子没有设置 filter,所以为 nil。 |
|
||||
| sort_keys(\[column, DESC\],\[column, ASC\] ...) | 按 column 列排序。 * DESC:降序。 * ASC:升序。 例如,`sort_keys([t1.c1, DESC],[t1.c2, ASC])`中指定排序键分别为 c1 和 c2,并且以 c1 列降序, c2 列升序排列。 |
|
||||
|
||||
|
||||
@ -0,0 +1,226 @@
|
||||
LIMIT
|
||||
==========================
|
||||
|
||||
LIMIT 算子用于限制数据输出的行数,与 MySQL 的 LIMIT 算子功能相同。
|
||||
|
||||
在 OceanBase 数据库的 MySQL 模式中处理含有 LIMIT 的 SQL 时,SQL 优化器都会为其生成一个 LIMIT 算子,但在一些特殊场景不会给与分配,例如 LIMIT 可以下压到基表的场景,就没有分配的必要性。
|
||||
|
||||
而对于 OceanBase 数据库的 Oracle 模式,以下两种场景会为其分配 LIMIT 算子:
|
||||
|
||||
* ROWNUM 经过 SQL 优化器改写生成
|
||||
|
||||
|
||||
|
||||
* 为了兼容 Oracle12c 的 FETCH 功能
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
MySQL 模式含有 LIMIT 的 SQL 场景
|
||||
----------------------------------------------
|
||||
|
||||
示例 1:OceanBase 数据库的 MySQL 模式含有 LIMIT 的 SQL 场景
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT t1.c1 FROM t1,t2 LIMIT 1 OFFSET 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =====================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------------
|
||||
|0 |LIMIT | |1 |39 |
|
||||
|1 | NESTED-LOOP JOIN CARTESIAN| |2 |39 |
|
||||
|2 | TABLE SCAN |t1 |1 |36 |
|
||||
|3 | TABLE SCAN |t2 |100000 |59654|
|
||||
=====================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1]), filter(nil), limit(1), offset(1)
|
||||
1 - output([t1.c1]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
2 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0)
|
||||
3 - output([t2.__pk_increment]), filter(nil),
|
||||
access([t2.__pk_increment]), partitions(p0)
|
||||
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT * FROM t1 LIMIT 2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |2 |37 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0),
|
||||
limit(2), offset(nil)
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q1 查询的执行计划展示中的 outputs \& filters 详细列出了 LIMIT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|--------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 LIMIT 算子没有设置 filter,所以为 nil。 |
|
||||
| limit | 限制输出的行数,是一个常量。 |
|
||||
| offset | 距离当前位置的偏移行数,是一个常量。 由于示例中的 SQL 中不含有 offset,因此生成的计划中为 nil。 |
|
||||
|
||||
|
||||
|
||||
Q2 查询的执行计划展示中,虽然 SQL 中含有 LIMIT,但是并未分配 LIMIT 算子,而是将相关表达式下压到了 TABLE SCAN 算子上,这种下压 LIMIT 行为是 SQL 优化器的一种优化方式,详细信息请参见 [TABLE SCAN](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/1.table-scan-2.md)。
|
||||
|
||||
Oracle 模式含有 COUNT 的 SQL 改写为 LIMIT 场景
|
||||
---------------------------------------------------------
|
||||
|
||||
由于 Oracle 模式含有 COUNT 的 SQL 改写为 LIMIT 场景在 COUNT 算子章节已经有过相关介绍,详细信息请参见 [COUNT](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/4.COUNT-1-2-3-4.md)。
|
||||
|
||||
Oracle 模式含有 FETCH 的 SQL 场景
|
||||
-----------------------------------------------
|
||||
|
||||
示例 2:OceanBase 数据库的 Oracle 模式含有 FETCH 的 SQL 场景
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE T1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE T1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q3:
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2 OFFSET 1 ROWS
|
||||
FETCH NEXT 1 ROWS ONLY\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =====================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------------
|
||||
|0 |LIMIT | |1 |238670 |
|
||||
|1 | NESTED-LOOP JOIN CARTESIAN| |2 |238669 |
|
||||
|2 | TABLE SCAN |T1 |1 |36 |
|
||||
|3 | MATERIAL | |100000 |238632 |
|
||||
|4 | TABLE SCAN |T2 |100000 |64066|
|
||||
=====================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil), limit(?), offset(?)
|
||||
1 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
3 - output([T2.C1], [T2.C2]), filter(nil)
|
||||
4 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
|
||||
Q4:
|
||||
obclient>EXPLAIN SELECT * FROM t1 FETCH NEXT 1 ROWS ONLY\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|T1 |1 |37 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0),
|
||||
limit(?), offset(nil)
|
||||
|
||||
|
||||
Q5:
|
||||
obclient>EXPLAIN SELECT * FROM t2 ORDER BY c1 FETCH NEXT 10
|
||||
PERCENT ROW WITH TIES\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
---------------------------------------
|
||||
|0 |LIMIT | |10000 |573070|
|
||||
|1 | SORT | |100000 |559268|
|
||||
|2 | TABLE SCAN|T2 |100000 |64066 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T2.C1], [T2.C2]), filter(nil), limit(nil), offset(nil), percent(?), with_ties(true)
|
||||
1 - output([T2.C1], [T2.C2]), filter(nil), sort_keys([T2.C1, ASC])
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q3 和 Q4 的查询的执行计划展示中,与之前 MySQL 模式的 Q1 和 Q2 查询基本相同,这是因为 Oracle 12c 的 FETCH 功能和 MySQL 的 LIMIT 功能类似,两者的区别如 Q5 执行计划展示中所示。
|
||||
|
||||
执行计划展示中的 outputs \& filters 详细列出了 LIMIT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-----------|-------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 LIMIT 算子没有设置 filter,所以为 nil。 |
|
||||
| limit | 限制输出的行数,是一个常量。 |
|
||||
| offset | 距离当前位置的偏移行数,是一个常量。 |
|
||||
| percent | 按照数据总行数的百分比输出,是一个常量。 |
|
||||
| with_ties | 是否在排序后的将最后一行按照等值一起输出。 例如,要求输出最后一行,但是排序之后有两行的值都为 1,如果设置了最后一行按照等值一起输出,那么这两行都会被输出。 |
|
||||
|
||||
|
||||
|
||||
以上 LIMIT 算子的新增的计划展示属性,都是在 Oracle 模式下的 FETCH 功能特有的,不影响 MySQL 模式计划。关于 Oracle12c 的 FETCH 语法的详细信息,请参见 [Oracle 12c Fetch Rows](https://renenyffenegger.ch/notes/development/databases/Oracle/SQL/select/first-n-rows/index#ora-sql-row-limiting-clause)。
|
||||
@ -0,0 +1,135 @@
|
||||
FOR UPDATE
|
||||
===============================
|
||||
|
||||
FOR UPDATE 算子用于对表中的数据进行加锁操作。
|
||||
|
||||
OceanBase 数据库支持的 FOR UPDATE 算子包括 FOR UPDATE 和 MULTI FOR UPDATE。
|
||||
|
||||
FOR UPDATE 算子执行查询的一般流程如下:
|
||||
|
||||
1. 首先执行 `SELECT` 语句部分,获得查询结果集。
|
||||
|
||||
|
||||
|
||||
2. 对查询结果集相关的记录进行加锁操作。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
FOR UPDATE
|
||||
-------------------------------
|
||||
|
||||
FOR UPDATE 用于对单表(或者单个分区)进行加锁。
|
||||
|
||||
如下示例中,Q1 查询是对 t1 表中满足 `c1 = 1` 的行进行加锁。这里 t1 表是一张单分区的表,所以 1 号算子生成了一个 FOR UPDATE 算子。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1, 1);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t2 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 = 1 FOR UPDATE\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |MATERIAL | |10 |856 |
|
||||
|1 | FOR UPDATE | |10 |836 |
|
||||
|2 | TABLE SCAN|T1 |10 |836 |
|
||||
=====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2]), filter(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil), lock tables(T1)
|
||||
2 - output([T1.C1], [T1.C2], [T1.__pk_increment]), filter([T1.C1 = 1]),
|
||||
access([T1.C1], [T1.C2], [T1.__pk_increment]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q1 查询的执行计划展示中的 outputs \& filters 详细列出了 FOR UPDATE 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-------------|--------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 FOR UPDATE 算子没有设置 filter,所以为 nil。 |
|
||||
| lock tables | 需要加锁的表。 |
|
||||
|
||||
|
||||
|
||||
MULTI FOR UPDATE
|
||||
-------------------------------------
|
||||
|
||||
MULTI FOR UPDATE 用于对多表(或者多个分区)进行加锁操作。
|
||||
|
||||
如下示例中,Q2 查询是对 t1 和 t2 两张表的数据进行加锁,加锁对象是满足 `c1 = 1 AND c1 = d1` 的行。由于需要对多个表的行进行加锁,因此 1 号算子是 MULTI FOR UPDATE。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (d1 INT, d2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1, t2 WHERE c1 = 1 AND c1 = d1
|
||||
FOR UPDATE\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=====================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------------------------
|
||||
|0 |MATERIAL | |10 |931 |
|
||||
|1 | MULTI FOR UPDATE | |10 |895 |
|
||||
|2 | NESTED-LOOP JOIN CARTESIAN| |10 |895 |
|
||||
|3 | TABLE GET |T2 |1 |52 |
|
||||
|4 | TABLE SCAN |T1 |10 |836 |
|
||||
=====================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.D1], [T2.D2]), filter(nil)
|
||||
1 - output([T1.C1], [T1.C2], [T2.D1], [T2.D2]), filter(nil), lock tables(T1, T2)
|
||||
2 - output([T1.C1], [T1.C2], [T2.D1], [T2.D2], [T1.__pk_increment]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
3 - output([T2.D1], [T2.D2]), filter(nil),
|
||||
access([T2.D1], [T2.D2]), partitions(p0)
|
||||
4 - output([T1.C1], [T1.C2], [T1.__pk_increment]), filter([T1.C1 = 1]),
|
||||
access([T1.C1], [T1.C2], [T1.__pk_increment]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q2 查询的执行计划展示中的 outputs \& filters 详细列出了 MULTI FOR UPDATE 算子的信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-------------|--------------------------------------------------------------------------|
|
||||
| output | 该算子输出的列。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 MULTI FOR UPDATE 算子没有设置 filter,所以为 nil。 |
|
||||
| lock tables | 需要加锁的表。 |
|
||||
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
SELECT INTO
|
||||
================================
|
||||
|
||||
SELECT INTO 算子用于将查询结果赋值给变量列表,查询仅返回一行数据。
|
||||
|
||||
如下示例查询中, `SELECT` 输出列为 `COUNT(*)` 和 `MAX(c1)`,其查询结果分别赋值给变量 @a 和 @b。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1,1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2,2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT COUNT(*), MAX(c1) INTO @a, @b FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------------
|
||||
|0 |SELECT INTO | |0 |37 |
|
||||
|1 | SCALAR GROUP BY| |1 |37 |
|
||||
|2 | TABLE SCAN |t1 |2 |37 |
|
||||
=========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_COUNT(*)], [T_FUN_MAX(t1.c1)]), filter(nil)
|
||||
1 - output([T_FUN_COUNT(*)], [T_FUN_MAX(t1.c1)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_COUNT(*)], [T_FUN_MAX(t1.c1)])
|
||||
2 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了 SELECT INTO 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|---------------------------------------------------------------------|
|
||||
| output | 该算子赋值给变量列表的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 SELECT INTO 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
SUBPLAN SCAN
|
||||
=================================
|
||||
|
||||
SUBPLAN SCAN 算子用于展示优化器从哪个视图访问数据。
|
||||
|
||||
当查询的 FROM TABLE 为视图时,执行计划中会分配 SUBPLAN SCAN 算子。SUBPLAN SCAN 算子类似于 TABLE SCAN 算子,但它不从基表读取数据,而是读取孩子节点的输出数据。
|
||||
|
||||
如下示例中,Q1 查询中 1 号算子为视图中查询生成,0 号算子 SUBPLAN SCAN 读取 1 号算子并输出。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1,1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2,2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE VIEW v AS SELECT * FROM t1 LIMIT 5;
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT * FROM V WHERE c1 > 0\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |SUBPLAN SCAN|v |1 |37 |
|
||||
|1 | TABLE SCAN |t1 |2 |37 |
|
||||
=====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([v.c1], [v.c2]), filter([v.c1 > 0]),
|
||||
access([v.c1], [v.c2])
|
||||
1 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0),
|
||||
limit(5), offset(nil)
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
目前 LIMIT 算子只支持 MySQL 模式的 SQL 场景。详细信息请参考 [LIMIT](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/12.LIMIT-1-2.md)。
|
||||
|
||||
上述示例中,Q1 查询的执行计划展示中的 outputs \& filters 详细列出了 SUBPLAN SCAN 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|-------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 例如 `filter([v.c1 > 0])` 中的 `v.c1 > 0`。 |
|
||||
| access | 该算子从子节点读取的需要使用的列名。 |
|
||||
|
||||
|
||||
|
||||
当 `FROM TABLE` 为视图并且查询满足一定条件时能够对查询进行视图合并改写,此时执行计划中并不会出现 SUBPLAN SCAN。如下例所示,Q2 查询相比 Q1 查询减少了过滤条件,不再需要分配 SUBPLAN SCAN 算子。
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT * FROM v\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |2 |37 |
|
||||
===================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0),
|
||||
limit(5), offset(nil)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,121 @@
|
||||
UNION
|
||||
==========================
|
||||
|
||||
UNION 算子用于将两个查询的结果集进行并集运算。
|
||||
|
||||
OceanBase 数据库支持的 UNION 算子包括 UNION ALL、 HASH UNION DISTINCT 和 MERGE UNION DISTINCT。
|
||||
|
||||
UNION ALL
|
||||
------------------------------
|
||||
|
||||
UNION ALL 用于直接对两个查询结果集进行合并输出。
|
||||
|
||||
如下示例中,Q1 对两个查询使用 UNION ALL 进行联接,使用 UNION ALL 算子进行并集运算。算子执行时依次输出左右子节点所有输出结果。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1,1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2,2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT c1 FROM t1 UNION ALL SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |UNION ALL | |4 |74 |
|
||||
|1 | TABLE SCAN|T1 |2 |37 |
|
||||
|2 | TABLE SCAN|T1 |2 |37 |
|
||||
====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([UNION(T1.C1, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C1]), filter(nil),
|
||||
access([T1.C1]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了 UNION ALL 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|-------------------------------------------------------------------|
|
||||
| output | 该算子的输出表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 UNION ALL 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
MERGE UNION DISTINCT
|
||||
-----------------------------------------
|
||||
|
||||
MERGE UNION DISTINCT 用于对结果集进行并集、去重后进行输出。
|
||||
|
||||
如下示例中,Q2 对两个查询使用 UNION DISTINCT 进行联接, c1 有可用排序,0 号算子生成 MERGE UNION DISTINCT 进行取并集、去重。由于 c2 无可用排序,所以在 3 号算子上分配了 SORT 算子进行排序。算子执行时从左右子节点读取有序输入,进行合并得到有序输出并去重。
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT c1 FROM t1 UNION SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
---------------------------------------------
|
||||
|0 |MERGE UNION DISTINCT| |4 |77 |
|
||||
|1 | TABLE SCAN |T1 |2 |37 |
|
||||
|2 | SORT | |2 |39 |
|
||||
|3 | TABLE SCAN |T1 |2 |37 |
|
||||
=============================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([UNION(T1.C1, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C1]), filter(nil),
|
||||
access([T1.C1]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil), sort_keys([T1.C2, ASC])
|
||||
3 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 MERGE UNION DISTINCT 算子的输出信息,字段的含义与 UNION ALL 算子相同。
|
||||
|
||||
HASH UNION DISTINCT
|
||||
----------------------------------------
|
||||
|
||||
HASH UNION DISTINCT 用于对结果集进行并集、去重后进行输出。
|
||||
|
||||
如下示例中,Q3 对两个查询使用 UNION DISTINCT 进行联接,无可利用排序,0 号算子使用 HASH UNION DISTINCT 进行并集、去重。算子执行时读取左右子节点输出,建立哈希表进行去重,最终输出去重后结果。
|
||||
|
||||
```javascript
|
||||
Q3:
|
||||
obclient>EXPLAIN SELECT c2 FROM t1 UNION SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
--------------------------------------------
|
||||
|0 |HASH UNION DISTINCT| |4 |77 |
|
||||
|1 | TABLE SCAN |T1 |2 |37 |
|
||||
|2 | TABLE SCAN |T1 |2 |37 |
|
||||
============================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([UNION(T1.C2, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 HASH UNION DISTINCT 算子的输出信息,字段的含义与 UNION ALL 算子相同。
|
||||
@ -0,0 +1,86 @@
|
||||
INTERSECT
|
||||
==============================
|
||||
|
||||
INTERSECT 算子用于对左右孩子算子输出进行交集运算,并进行去重。
|
||||
|
||||
OceanBase 数据库支持的 INTERSECT 算子包括 MERGE INTERSECT DISTINCT 和 HASH INTERSECT DISTINCT。
|
||||
|
||||
MERGE INTERSECT DISTINCT
|
||||
---------------------------------------------
|
||||
|
||||
如下示例中,Q1 对两个查询使用 INTERSECT 联接,c1 有可用排序,0 号算子生成了 MERGE INTERSECT DISTINCT 进行求取交集、去重。由于 c2 无可用排序,所以在 3 号算子上分配了 SORT 算子进行排序。算子执行时从左右子节点读取有序输入,利用有序输入进行 MERGE,实现去重并得到交集结果。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1,1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2,2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT c1 FROM t1 INTERSECT SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------------------
|
||||
|0 |MERGE INTERSECT DISTINCT| |2 |77 |
|
||||
|1 | TABLE SCAN |T1 |2 |37 |
|
||||
|2 | SORT | |2 |39 |
|
||||
|3 | TABLE SCAN |T1 |2 |37 |
|
||||
=================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([INTERSECT(T1.C1, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C1]), filter(nil),
|
||||
access([T1.C1]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil), sort_keys([T1.C2, ASC])
|
||||
3 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了所有 INTERSECT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|------------------------------------------------------------------------------------------|
|
||||
| output | 该算子的输出表达式。 使用 INTERSECT 联接的两个子算子对应输出,即表示交集运算输出结果中的一列,括号内部为左右子节点对应此列的输出列。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 INTERSECT 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
HASH INTERSECT DISTINCT
|
||||
--------------------------------------------
|
||||
|
||||
如下例所示,Q2 对两个查询使用 INTERSECT 进行联接,不可利用排序,0 号算子使用 HASH INTERSECT DISTINCT 进行求取交集、去重。算子执行时先读取一侧子节点输出建立哈希表并去重,再读取另一侧子节点利用哈希表求取交集并去重。
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT c2 FROM t1 INTERSECT SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------------------
|
||||
|0 |HASH INTERSECT DISTINCT| |2 |77 |
|
||||
|1 | TABLE SCAN |T1 |2 |37 |
|
||||
|2 | TABLE SCAN |T1 |2 |37 |
|
||||
================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([INTERSECT(T1.C2, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 HASH INTERSECT DISTINCT 算子的输出信息,字段的含义与 MERGE INTERSECT DISTINCT 算子相同。
|
||||
@ -0,0 +1,87 @@
|
||||
EXCEPT/MINUS
|
||||
=================================
|
||||
|
||||
EXCEPT 算子用于对左右孩子算子输出集合进行差集运算,并进行去重。
|
||||
|
||||
Oracle 模式下一般使用 MINUS 进行差集运算,MySQL 模式下一般使用 EXCEPT 进行差集运算。OceanBase 数据库的 MySQL 模式不区分 EXCEPT 和 MINUS,两者均可作为差集运算关键字使用。
|
||||
|
||||
OceanBase 数据库支持的 EXCEPT 算子包括 MERGE EXCEPT DISTINCT 和 HASH EXCEPT DISTINCT。
|
||||
|
||||
MERGE EXCEPT DISTINCT
|
||||
------------------------------------------
|
||||
|
||||
如下示例中,Q1 对两个查询使用 MINUS 进行联接, c1 有可用排序,0 号算子生成了 MERGE EXCEPT DISTINCT 进行求取差集、去重,由于 c2 无可用排序,所以在 3 号算子上分配了 SORT 算子进行排序。算子执行时从左右孩子节点读取有序输入,利用有序输入进行 MERGE, 实现去重并得到差集结果。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1,1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2,2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT c1 FROM t1 MINUS SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
----------------------------------------------
|
||||
|0 |MERGE EXCEPT DISTINCT| |2 |77 |
|
||||
|1 | TABLE SCAN |T1 |2 |37 |
|
||||
|2 | SORT | |2 |39 |
|
||||
|3 | TABLE SCAN |T1 |2 |37 |
|
||||
==============================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([MINUS(T1.C1, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C1]), filter(nil),
|
||||
access([T1.C1]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil), sort_keys([T1.C2, ASC])
|
||||
3 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了 EXCEPT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|----------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子的输出表达式。 使用 EXCEPT/MINUS 联接的两孩子算子对应输出(Oracle 模式使用 MINUS,MySQL 模式使用 EXCEPT),表示差集运算输出结果中的一列,括号内部为左右孩子节点对应此列的输出列。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 EXCEPT 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
HASH EXCEPT DISTINCT
|
||||
-----------------------------------------
|
||||
|
||||
如下示例中,Q2 对两个查询使用 MINUS 进行联接,不可利用排序,0 号算子使用 HASH EXCEPT DISTINCT 进行求取差集、去重。算子执行时先读取左侧孩子节点输出建立哈希表并去重,再读取右侧孩子节点输出利用哈希表求取差集并去重。
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT c2 FROM t1 MINUS SELECT c2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
---------------------------------------------
|
||||
|0 |HASH EXCEPT DISTINCT| |2 |77 |
|
||||
|1 | TABLE SCAN |T1 |2 |37 |
|
||||
|2 | TABLE SCAN |T1 |2 |37 |
|
||||
=============================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([MINUS(T1.C2, T1.C2)]), filter(nil)
|
||||
1 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
2 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 HASH EXCEPT DISTINCT 算子的输出信息,字段的含义与 MERGE EXCEPT DISTINCT 算子相同。
|
||||
@ -0,0 +1,232 @@
|
||||
INSERT
|
||||
===========================
|
||||
|
||||
INSERT 算子用于将指定的数据插入数据表,数据来源包括直接指定的值和子查询的结果。
|
||||
|
||||
OceanBase 数据库支持的 INSERT 算子包括 INSERT 和 MULTI PARTITION INSERT。
|
||||
|
||||
INSERT
|
||||
---------------------------
|
||||
|
||||
INSERT 算子用于向数据表的单个分区中插入数据。
|
||||
|
||||
如下例所示,Q1 查询将值 (1, '100') 插入到非分区表 t1 中。其中 1 号算子 EXPRESSION 用来生成常量表达式的值。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 VARCHAR2(10));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 VARCHAR2(10)) PARTITION BY
|
||||
HASH(c1) PARTITIONS 10;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t3 (c1 INT PRIMARY KEY, c2 VARCHAR2(10));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE INDEX IDX_t3_c2 ON t3 (c2) PARTITION BY HASH(c2) PARTITIONS 3;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN INSERT INTO t1 VALUES (1, '100')\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |INSERT | |1 |1 |
|
||||
|1 | EXPRESSION| |1 |1 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([__values.C1], [__values.C2]), filter(nil),
|
||||
columns([{T1: ({T1: (T1.C1, T1.C2)})}]), partitions(p0)
|
||||
1 - output([__values.C1], [__values.C2]), filter(nil)
|
||||
values({1, '100'})
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了 INSERT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|------------|----------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 INSERT 算子没有设置 filter,所以为 nil。 |
|
||||
| columns | 插入操作涉及的数据表的列。 |
|
||||
| partitions | 插入操作涉及到的数据表的分区(非分区表可以认为是一个只有一个分区的分区表)。 |
|
||||
|
||||
|
||||
|
||||
更多 INSERT 算子的示例如下:
|
||||
|
||||
* Q2 查询将值(2, '200')、(3, '300')插入到表 t1 中。
|
||||
|
||||
```unknow
|
||||
Q2:
|
||||
obclient>EXPLAIN INSERT INTO t1 VALUES (2, '200'),(3, '300')\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |INSERT | |2 |1 |
|
||||
|1 | EXPRESSION| |2 |1 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([__values.C1], [__values.C2]), filter(nil),
|
||||
columns([{T1: ({T1: (T1.C1, T1.C2)})}]), partitions(p0)
|
||||
1 - output([__values.C1], [__values.C2]), filter(nil)
|
||||
values({2, '200'}, {3, '300'})
|
||||
```
|
||||
|
||||
|
||||
|
||||
* Q3 查询将子查询 `SELECT * FROM t3` 的结果插入到表 t1 中。
|
||||
|
||||
```unknow
|
||||
Q3:
|
||||
obclient>EXPLAIN INSERT INTO t1 SELECT * FROM t3\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|0 |INSERT | |100000 |117862|
|
||||
|1 | EXCHANGE IN DISTR | |100000 |104060|
|
||||
|2 | EXCHANGE OUT DISTR| |100000 |75662 |
|
||||
|3 | SUBPLAN SCAN |VIEW1|100000 |75662 |
|
||||
|4 | TABLE SCAN |T3 |100000 |61860 |
|
||||
================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([VIEW1.C1], [VIEW1.C2]), filter(nil),
|
||||
columns([{T1: ({T1: (T1.C1, T1.C2)})}]), partitions(p0)
|
||||
1 - output([VIEW1.C1], [VIEW1.C2]), filter(nil)
|
||||
2 - output([VIEW1.C1], [VIEW1.C2]), filter(nil)
|
||||
3 - output([VIEW1.C1], [VIEW1.C2]), filter(nil),
|
||||
access([VIEW1.C1], [VIEW1.C2])
|
||||
4 - output([T3.C1], [T3.C2]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* Q4 查询将值(1, '100')插入到分区表 t2 中,通过 `partitions` 参数可以看出,该值会被插入到 t2 的 p5 分区。
|
||||
|
||||
```javascript
|
||||
Q4:
|
||||
obclient>EXPLAIN INSERT INTO t2 VALUES (1, '100')\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |INSERT | |1 |1 |
|
||||
|1 | EXPRESSION| |1 |1 |
|
||||
====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([__values.C1], [__values.C2]), filter(nil),
|
||||
columns([{T2: ({T2: (T2.C1, T2.C2)})}]), partitions(p5)
|
||||
1 - output([__values.C1], [__values.C2]), filter(nil)
|
||||
values({1, '100'})
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
MULTI PARTITION INSERT
|
||||
-------------------------------------------
|
||||
|
||||
MULTI PARTITION INSERT 算子用于向数据表的多个分区中插入数据。
|
||||
|
||||
如下例所示,Q5 查询将值(2, '200')、(3, '300')插入到分区表 t2 中,通过 `partitions` 可以看出,这些值会被插入到 t2 的 p0 和 p6 分区。
|
||||
|
||||
```javascript
|
||||
Q5:
|
||||
obclient>EXPLAIN INSERT INTO t2 VALUES (2, '200'),(3, '300')\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------------------
|
||||
|0 |MULTI PARTITION INSERT| |2 |1 |
|
||||
|1 | EXPRESSION | |2 |1 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([__values.C1], [__values.C2]), filter(nil),
|
||||
columns([{T2: ({T2: (T2.C1, T2.C2)})}]), partitions(p0, p6)
|
||||
1 - output([__values.C1], [__values.C2]), filter(nil)
|
||||
values({2, '200'}, {3, '300'})
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 MULTI PARTITION INSERT 算子的信息,字段的含义与 INSERT 算子相同。
|
||||
|
||||
更多 MULTI PARTITION INSERT 算子的示例如下:
|
||||
|
||||
* Q6 查询将子查询 `SELECT * FROM t3` 的结果插入到分区表 t2 中,因为无法确定子查询的结果集,因此数据可能插入到 t2 的 p0 到 p9 的任何一个分区中。从1 号算子可以看到,这里的 `SELECT * FROM t3` 会被放在一个子查询中,并将子查询命名为 VIEW1。当 OceanBase 数据库内部改写 SQL 产生了子查询时,会自动为子查询命名,并按照子查询生成的顺序命名为 VIEW1、VIEW2、VIEW3...
|
||||
|
||||
```unknow
|
||||
Q6:
|
||||
obclient>EXPLAIN INSERT INTO t2 SELECT * FROM t3\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
--------------------------------------------------
|
||||
|0 |MULTI PARTITION INSERT| |100000 |117862|
|
||||
|1 | EXCHANGE IN DISTR | |100000 |104060|
|
||||
|2 | EXCHANGE OUT DISTR | |100000 |75662 |
|
||||
|3 | SUBPLAN SCAN |VIEW1|100000 |75662 |
|
||||
|4 | TABLE SCAN |T3 |100000 |61860 |
|
||||
==================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([VIEW1.C1], [VIEW1.C2]), filter(nil),
|
||||
columns([{T2: ({T2: (T2.C1, T2.C2)})}]), partitions(p[0-9])
|
||||
1 - output([VIEW1.C1], [VIEW1.C2]), filter(nil)
|
||||
2 - output([VIEW1.C1], [VIEW1.C2]), filter(nil)
|
||||
3 - output([VIEW1.C1], [VIEW1.C2]), filter(nil),
|
||||
access([VIEW1.C1], [VIEW1.C2])
|
||||
4 - output([T3.C1], [T3.C2]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* Q7 查询将值(1, '100')插入到非分区表 t3 中。虽然 t3 本身是一个非分区表,但因为 t3 上存在全局索引 idx_t3_c2,因此本次插入也涉及到了多个分区。
|
||||
|
||||
```javascript
|
||||
Q7:
|
||||
obclient>EXPLAIN INSERT INTO t3 VALUES (1, '100')\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------------------
|
||||
|0 |MULTI PARTITION INSERT| |1 |1 |
|
||||
|1 | EXPRESSION | |1 |1 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([__values.C1], [__values.C2]), filter(nil),
|
||||
columns([{T3: ({T3: (T3.C1, T3.C2)}, {IDX_T3_C2: (T3.C2, T3.C1)})}]), partitions(p0)
|
||||
1 - output([__values.C1], [__values.C2]), filter(nil)
|
||||
values({1, '100'})
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,45 @@
|
||||
TABLE LOOKUP
|
||||
=================================
|
||||
|
||||
TABLE LOOKUP 算子用于表示全局索引的回表逻辑。
|
||||
|
||||
示例:全局索引回表
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT, c3 INT) PARTITION BY
|
||||
HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE INDEX i1 ON t1(c2) GLOBAL;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1 WHERE c2 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |TABLE LOOKUP|t1 |3960 |31065|
|
||||
|1 | TABLE SCAN |t1(i1)|3960 |956 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil),
|
||||
partitions(p[0-3])
|
||||
1 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,1 号算子是扫描全局索引 i1, 0 号算子表明从主表中获取不在全局索引的列。执行计划展示中的 outputs \& filters 详细展示了 TABLE LOOKUP 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|------------|---------------------------------------------------------------------|
|
||||
| output | 该算子的输出列。 |
|
||||
| filter | 该算子的过滤谓词。 由于示例中 TABLE LOOKUP 算子没有设置 filter,所以为 nil。 |
|
||||
| partitions | 查询需要扫描的分区。 |
|
||||
|
||||
|
||||
@ -0,0 +1,176 @@
|
||||
DELETE
|
||||
===========================
|
||||
|
||||
DELETE 算子用于删除数据表中满足指定条件的数据行。
|
||||
|
||||
OceanBase 数据库支持的 DELETE 算子包括 DELETE 和 MULTI PARTITION DELETE。
|
||||
|
||||
DELETE
|
||||
---------------------------
|
||||
|
||||
DELETE 算子用于删除数据表单个分区中的数据。
|
||||
|
||||
如下例所示,Q1 查询删除了表 t1 中所有满足 `c2>'100'` 的行。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 VARCHAR2(10));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 VARCHAR2(10)) PARTITION BY
|
||||
HASH(c1) PARTITIONS 10;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t3 (c1 INT PRIMARY KEY, c2 VARCHAR2(10));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE INDEX IDX_t3_c2 ON t3 (c2) PARTITION BY HASH(c2) PARTITIONS 3;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN DELETE FROM t1 WHERE c2 > '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |DELETE | |10000 |118697|
|
||||
|1 | TABLE SCAN|T1 |10000 |108697|
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T1: ({T1: (T1.C1, T1.C2)})}])
|
||||
1 - output([T1.C1], [T1.C2]), filter([T1.C2 > '100']),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了 DELETE 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|---------------|-----------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。由于示例中 DELETE 算子没有设置 filter,所以为 nil。对于删除语句,WHERE 中的谓词会下推到基表上,比如 Q1 查询中的 `c2>'100'` 被下推到了 1 号算子上。 |
|
||||
| table_columns | 删除操作涉及的数据表的列。 |
|
||||
|
||||
|
||||
|
||||
更多 DELETE 算子的示例如下:
|
||||
|
||||
* Q2 查询删除 t1 中的所有数据行。
|
||||
|
||||
|
||||
|
||||
* Q3 查询删除分区表 t2 中满足 `c1 = 1` 的数据行。
|
||||
|
||||
|
||||
|
||||
* Q4 查询删除分区表 t2 中满足 `c2 > '100' ` 的数据行。从执行计划中可以看到,DELETE 算子分配在 EXCHANGE 算子下面,因此 2 号和 3 号算子会作为一个 task 以分区的粒度进行调度。在计划执行时, 3 号算子扫描出 t2 一个分区中满足 `c2 > '100'` 的数据,2 号算子 DELETE 则只会删除相应分区下扫描出的数据。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN DELETE FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |DELETE | |100000 |161860|
|
||||
|1 | TABLE SCAN|T1 |100000 |61860 |
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T1: ({T1: (T1.C1, T1.C2)})}])
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
|
||||
|
||||
Q3:
|
||||
obclient>EXPLAIN DELETE FROM t2 WHERE c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |DELETE | |1 |53 |
|
||||
|1 | TABLE GET|T2 |1 |52 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T2: ({T2: (T2.C1, T2.C2)})}])
|
||||
1 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p5)
|
||||
|
||||
|
||||
Q4:
|
||||
obclient>EXPLAIN DELETE FROM t2 WHERE c2 > '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================
|
||||
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |100000 |1186893|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|100000 |1186893|
|
||||
|2 | PX PARTITION ITERATOR| |100000 |1186893|
|
||||
|3 | DELETE | |100000 |1186893|
|
||||
|4 | TABLE SCAN |T2 |100000 |1086893|
|
||||
==================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil)
|
||||
1 - output(nil), filter(nil), dop=1
|
||||
2 - output(nil), filter(nil)
|
||||
3 - output(nil), filter(nil), table_columns([{T2: ({T2: (T2.C1, T2.C2)})}])
|
||||
4 - output([T2.C1], [T2.C2]), filter([T2.C2 > '100']),
|
||||
access([T2.C1], [T2.C2]), partitions(p[0-9])
|
||||
```
|
||||
|
||||
|
||||
|
||||
MULTI PARTITION DELETE
|
||||
-------------------------------------------
|
||||
|
||||
MULTI PARTITION DELETE 算子用于删除数据表多个分区中的数据。
|
||||
|
||||
如下例所示,Q5 查询删除了表 t3 中所有满足 `c2 > '100' ` 的数据行。虽然 t3 本身是一个非分区表,但因为 t3 上存在全局索引 idx_t3_c2,因此每一条数据行会存在于多个分区中。
|
||||
|
||||
```javascript
|
||||
Q5:
|
||||
obclient>EXPLAIN DELETE FROM t3 WHERE c2 > '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
========================================================
|
||||
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-----------------------------------------------------------
|
||||
|0 |MULTI PARTITION DELETE | |10001 |27780|
|
||||
|1 | PX COORDINATOR | |10001 |17780|
|
||||
|2 | EXCHANGE OUT DISTR |:EX10000 |10001 |14941|
|
||||
|3 | PX PARTITION ITERATOR| |10001 |14941|
|
||||
|4 | TABLE SCAN |T3(IDX_T3_C2)|10001 |14941|
|
||||
===========================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T3: ({T3: (T3.C1, T3.C2)}, {IDX_T3_C2: (T3.C2, T3.C1)})}])
|
||||
1 - output([T3.C1], [T3.C2]), filter(nil)
|
||||
2 - output([T3.C2], [T3.C1]), filter(nil), dop=1
|
||||
3 - output([T3.C2], [T3.C1]), filter(nil)
|
||||
4 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p[0-2])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 MULTI PARTITION DELETE 算子的信息,字段的含义与 DELETE 算子相同。
|
||||
@ -0,0 +1,219 @@
|
||||
UPDATE
|
||||
===========================
|
||||
|
||||
UPDATE 算子用于更新数据表中满足指定条件的数据行。
|
||||
|
||||
OceanBase 数据库支持的 UPDATE 算子包括 UPDATE 和 MULTI PARTITION UPDATE。
|
||||
|
||||
UPDATE
|
||||
---------------------------
|
||||
|
||||
UPDATE 算子用于更新数据表单个分区中的数据。
|
||||
|
||||
如下例所示,Q1 查询更新了表 t1 中所有满足 `c2 = '100'` 的行,并将 c2 的值设置为 200。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 VARCHAR2(10));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 VARCHAR2(10)) PARTITION BY
|
||||
HASH(c1) PARTITIONS 10;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t3 (c1 INT PRIMARY KEY, c2 VARCHAR2(10));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE INDEX IDX_t3_c2 ON t3 (c2) PARTITION BY HASH(c2) PARTITIONS 3;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN UPDATE t1 SET c2 = '200' WHERE c2 = '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------
|
||||
|0 |EXCHANGE IN REMOTE | |990 |109687|
|
||||
|1 | EXCHANGE OUT REMOTE| |990 |109687|
|
||||
|2 | UPDATE | |990 |109687|
|
||||
|3 | TABLE SCAN |T1 |990 |108697|
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil)
|
||||
1 - output(nil), filter(nil)
|
||||
2 - output(nil), filter(nil), table_columns([{T1: ({T1: (T1.C1, T1.C2)})}]),
|
||||
update([T1.C2=?])
|
||||
3 - output([T1.C1], [T1.C2], [?]), filter([T1.C2 = '100']),
|
||||
access([T1.C2], [T1.C1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细列出了 UPDATE 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|---------------|-----------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。由于示例中 UPDATE 算子没有 filter,所以为 nil。对于更新语句,WHERE 中的谓词会下推到基表上,比如 Q1 查询中的 `c2 = '100'` 被下推到了 1 号算子上。 |
|
||||
| table_columns | 更新操作涉及的数据表的列。 |
|
||||
| update | 更新操作中所有的赋值表达式。 |
|
||||
|
||||
|
||||
|
||||
更多 UPDATE 算子的示例如下:
|
||||
|
||||
* Q2 查询更新 t1 中的所有数据行,并将 c2 的值置为 200。
|
||||
|
||||
|
||||
|
||||
* Q3 查询更新分区表 t2 中满足 `c1='100'` 的数据行,并将 c2 的值置为 150。
|
||||
|
||||
|
||||
|
||||
* Q4 查询更新分区表 t2 中满足 `c2 ='100'` 的数据行,并将`c2` 的值置为`rpad(t2.c2, 10, '9')`。从执行计划中可以看到,UPDATE 算子分配在 EXCHANGE 算子下面,因此 2 号和 3 号算子会作为一个 task 以分区的粒度进行调度。执行时 3 号算子扫描出 t2 一个分区中满足 `c2 = '100'` 的数据,2 号 UPDATE 算子则只会更新相应分区下扫描出的数据。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN UPDATE t1 SET c2 = '200'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------
|
||||
|0 |EXCHANGE IN REMOTE | |100000 |161860|
|
||||
|1 | EXCHANGE OUT REMOTE| |100000 |161860|
|
||||
|2 | UPDATE | |100000 |161860|
|
||||
|3 | TABLE SCAN |T1 |100000 |61860 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil)
|
||||
1 - output(nil), filter(nil)
|
||||
2 - output(nil), filter(nil), table_columns([{T1: ({T1: (T1.C1, T1.C2)})}]),
|
||||
update([T1.C2=?])
|
||||
3 - output([T1.C1], [T1.C2], [?]), filter(nil),
|
||||
access([T1.C2], [T1.C1]), partitions(p0)
|
||||
|
||||
|
||||
Q3:
|
||||
obclient>EXPLAIN UPDATE t2 SET t2.c2 = '150' WHERE t2.c1 = '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |UPDATE | |1 |53 |
|
||||
|1 | TABLE GET|T2 |1 |52 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T2: ({T2: (T2.C1, T2.C2)})}]),
|
||||
update([T2.C2=?])
|
||||
1 - output([T2.C1], [T2.C2], [?]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p5)
|
||||
|
||||
|
||||
Q4:
|
||||
obclient>EXPLAIN UPDATE t2 SET t2.c2 = RPAD(t2.c2, 10, '9') WHERE t2.c2 = '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |9900 |1096793|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|9900 |1096793|
|
||||
|2 | PX PARTITION ITERATOR| |9900 |1096793|
|
||||
|3 | UPDATE | |9900 |1096793|
|
||||
|4 | TABLE SCAN |T2 |9900 |1086893|
|
||||
=======================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil)
|
||||
1 - output(nil), filter(nil), dop=1
|
||||
2 - output(nil), filter(nil)
|
||||
3 - output(nil), filter(nil), table_columns([{T2: ({T2: (T2.C1, T2.C2)})}]),
|
||||
update([T2.C2=column_conv(VARCHAR,utf8mb4_bin,length:10,NULL,RPAD(T2.C2, 10, ?))])
|
||||
4 - output([T2.C1], [T2.C2], [column_conv(VARCHAR,utf8mb4_bin,length:10,NULL,RPAD(T2.C2, 10, ?))]), filter([T2.C2 = '100']),
|
||||
access([T2.C1], [T2.C2]), partitions(p[0-9])
|
||||
```
|
||||
|
||||
|
||||
|
||||
MULTI PARTITION UPDATE
|
||||
-------------------------------------------
|
||||
|
||||
MULTI PARTITION UPDATE 算子表示更新数据表多个分区中的数据。如下例所示,Q5 查询更新表 t3 中所有满足`c2 < '100'`的数据行,并将 c2 的值置为 200。虽然 t3 本身是一个非分区表,但 t3 上存在全局索引 idx_t3_c2,因此每一条数据行会存在于多个分区中。
|
||||
|
||||
```javascript
|
||||
Q5:
|
||||
obclient>EXPLAIN UPDATE t3 SET c2 = '200' WHERE c2 < '100'\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
========================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-----------------------------------------------------------
|
||||
|0 |MULTI PARTITION UPDATE | |10001 |27780|
|
||||
|1 | PX COORDINATOR | |10001 |17780|
|
||||
|2 | EXCHANGE OUT DISTR |:EX10000 |10001 |14941|
|
||||
|3 | PX PARTITION ITERATOR| |10001 |14941|
|
||||
|4 | TABLE SCAN |T3(IDX_T3_C2)|10001 |14941|
|
||||
===========================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T3: ({T3: (T3.C1, T3.C2)}, {IDX_T3_C2: (T3.C2, T3.C1)})}]),
|
||||
update([T3.C2=?])
|
||||
1 - output([T3.C1], [T3.C2], [?]), filter(nil)
|
||||
2 - output([T3.C2], [T3.C1], [?]), filter(nil), dop=1
|
||||
3 - output([T3.C2], [T3.C1], [?]), filter(nil)
|
||||
4 - output([T3.C2], [T3.C1], [?]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p[0-2])
|
||||
```
|
||||
|
||||
|
||||
|
||||
更多 MULTI PARTITION UPDATE 的示例如下:
|
||||
|
||||
* Q6 查询更新分区表 t2 中满足 `c1 = 100` 的数据行,并将 c1 的值设置为 101。因为更新的列是主键列,可能会导致更新后的数据行与更新前的数据行位于不同的分区,因此需要使用 MULTI PARTITION UPDATE 算子进行更新。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
Q6:
|
||||
obclient>EXPLAIN UPDATE t2 SET t2.c1 = 101 WHERE t2.c1 = 100\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------------------
|
||||
|0 |MULTI PARTITION UPDATE| |1 |54 |
|
||||
|1 | EXCHANGE IN DISTR | |1 |53 |
|
||||
|2 | EXCHANGE OUT DISTR | |1 |52 |
|
||||
|3 | TABLE GET |T2 |1 |52 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output(nil), filter(nil), table_columns([{T2: ({T2: (T2.C1, T2.C2)})}]),
|
||||
update([T2.C1=?])
|
||||
1 - output([T2.C1], [T2.C2], [?]), filter(nil)
|
||||
2 - output([T2.C1], [T2.C2], [?]), filter(nil)
|
||||
3 - output([T2.C1], [T2.C2], [?]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p5)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,120 @@
|
||||
MERGE
|
||||
==========================
|
||||
|
||||
MERGE 算子用于将源表中的数据行以更新或插入的方式合并到目标表中。
|
||||
|
||||
OceanBase 数据库支持的 MERGE 算子包括 MERGE 和 MULTI PARTITION MERGE。
|
||||
|
||||
MERGE
|
||||
--------------------------
|
||||
|
||||
MERGE 算子用于合并数据表单个分区中的数据。
|
||||
|
||||
如下例所示,Q1 查询将 src_tbl 表中的数据行合并到 t1 表中,对于 src_tbl 中的每一条数据行按照如下方式进行合并:
|
||||
|
||||
* 当 t1 中存在满足 `t1.c1=src_tbl.c1` 条件的数据行:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 当 t1 中不存在满足 `t1.c1 = src_tbl.c1` 条件的数据行:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 其中,OUTER JOIN 是合并功能实现时依赖的一次联接操作,使用 MERGE 算子时,一定会在 `source_table` 和 `target_table` 上做一次外联接,目的是为了区分哪些行是匹配的,哪些是不匹配的。
|
||||
|
||||
* 执行计划展示中的 outputs \& filters 详细列出了 MERGE 算子的输出信息如下:
|
||||
|
||||
|
||||
|
||||
|
||||
MULTI PARTITION MERGE
|
||||
------------------------------------------
|
||||
|
||||
MULTI PARTITION MERGE 算子用于合并数据表多个分区中的数据。
|
||||
|
||||
如下例所示,Q2 查询将 src_tbl 表中的数据行合并到分区表 t2 表中,对于 src_tbl 中的每一条数据行按照如下方式进行合并:
|
||||
|
||||
* 当 t2 中存在满足 `t2.c1 = src_tbl.c1` 条件的数据行:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 当 t2 中不存在满足 `t2.c1 = src_tbl.c1` 条件的数据行,执行插入操作,向 t2 中插入 `(src_tbl.c1, src_tbl.c2)`。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN MERGE INTO t2 USING SRC_TBL ON (t2.c1 = src_tbl.c1)
|
||||
WHEN MATCHED THEN
|
||||
UPDATE SET t2.c2 = SUBSTR(src_tbl.c2, 1, 5)
|
||||
DELETE WHERE t2.c2 > '80000'
|
||||
WHEN NOT MATCHED THEN
|
||||
INSERT (t2.c1, t2.c2) VALUES (src_tbl.c1,src_tbl.c2)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================================
|
||||
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------------------------------
|
||||
|0 |MULTI PARTITION MERGE | |100000 |100000 |
|
||||
|1 | PX COORDINATOR | |100000 |956685 |
|
||||
|2 | EXCHANGE OUT DISTR |:EX10001|100000 |899889 |
|
||||
|3 | MERGE OUTER JOIN | |100000 |899889 |
|
||||
|4 | EXCHANGE IN DISTR | |100000 |90258 |
|
||||
|5 | EXCHANGE OUT DISTR (PKEY)|:EX10000|100000 |61860 |
|
||||
|6 | TABLE SCAN |SRC_TBL |100000 |61860 |
|
||||
|7 | SORT | |1000000 |5447108|
|
||||
|8 | PX PARTITION ITERATOR | |1000000 |618524 |
|
||||
|9 | TABLE SCAN |T2 |1000000 |618524 |
|
||||
==============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([column_conv(DECIMAL,PS:(38,0),NOT NULL,SRC_TBL.C1)], [column_conv(VARCHAR,utf8mb4_bin,length:10,NULL,SRC_TBL.C2)]), filter(nil),
|
||||
columns([{T2: ({T2: (T2.C1, T2.C2)})}]), partitions(p[0-9]),
|
||||
update([T2.C2=column_conv(VARCHAR,utf8mb4_bin,length:10,NULL,SUBSTR(SRC_TBL.C2, 1, 5))]),
|
||||
match_conds([T2.C1 = SRC_TBL.C1]), insert_conds(nil),
|
||||
update_conds(nil), delete_conds([T2.C2 > '80000'])
|
||||
1 - output([SRC_TBL.C1], [SRC_TBL.C2], [T2.C1], [T2.C1 = SRC_TBL.C1], [T2.C2]), filter(nil)
|
||||
2 - output([SRC_TBL.C1], [SRC_TBL.C2], [T2.C1], [T2.C1 = SRC_TBL.C1], [T2.C2]), filter(nil), dop=1
|
||||
3 - output([SRC_TBL.C1], [SRC_TBL.C2], [T2.C1], [T2.C1 = SRC_TBL.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T2.C1 = SRC_TBL.C1]), other_conds(nil)
|
||||
4 - output([SRC_TBL.C1], [SRC_TBL.C2]), filter(nil)
|
||||
5 - (#keys=1, [SRC_TBL.C1]), output([SRC_TBL.C1], [SRC_TBL.C2]), filter(nil), is_single, dop=1
|
||||
6 - output([SRC_TBL.C1], [SRC_TBL.C2]), filter(nil),
|
||||
access([SRC_TBL.C1], [SRC_TBL.C2]), partitions(p0)
|
||||
7 - output([T2.C1], [T2.C2]), filter(nil), sort_keys([T2.C1, ASC]), local merge sort
|
||||
8 - output([T2.C1], [T2.C2]), filter(nil)
|
||||
9 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p[0-9])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 MULTI PARTITION MERGE 算子的输出信息,字段的含义与 MERGE 算子相同。
|
||||
@ -0,0 +1,263 @@
|
||||
EXCHANGE
|
||||
=============================
|
||||
|
||||
EXCHANGE 算子用于线程间进行数据交互的算子。
|
||||
|
||||
EXCHANGE 算子适用于在分布式场景,一般都是成对出现的,数据源端有一个 OUT 算子,目的端会有一个 IN 算子。
|
||||
|
||||
EXCH-IN/OUT
|
||||
--------------------------------
|
||||
|
||||
EXCH-IN/OUT 即 EXCHANGE IN/ EXCHANGE OUT 用于将多个分区上的数据汇聚到一起,发送到查询所在的主节点上。
|
||||
|
||||
如下例所示,下面的查询中访问了 5 个分区的数据(p0-p4),其中 1 号算子接受 2 号算子产生的输出,并将数据传出;0 号算子接收多个分区上 1 号算子产生的输出,并将结果汇总输出。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 5;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |500000 |545109|
|
||||
|1 | EXCHANGE OUT DISTR| |500000 |320292|
|
||||
|2 | TABLE SCAN |T |500000 |320292|
|
||||
==============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T.C1], [T.C2]), filter(nil)
|
||||
1 - output([T.C1], [T.C2]), filter(nil)
|
||||
2 - output([T.C1], [T.C2]), filter(nil),
|
||||
access([T.C1], [T.C2]), partitions(p[0-4])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 EXCH-IN/OUT 算子的输出信息如下:
|
||||
|
||||
|
||||
| 信息名称 | 含义 |
|
||||
|--------|---------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 EXCH-IN/OUT 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
EXCH-IN/OUT (REMOTE)
|
||||
-----------------------------------------
|
||||
|
||||
EXCH-IN/OUT (REMOTE) 算子用于将远程的数据(单个分区的数据)拉回本地。
|
||||
|
||||
如下例所示,在 A 机器上创建了一张非分区表,在 B 机器上执行查询,读取该表的数据。此时,由于待读取的数据在远程,执行计划中分配了 0 号算子和 1 号算子来拉取远程的数据。其中,1 号算子在 A 机器上执行,读取 t 表的数据,并将数据传出;0 号算子在 B 机器上执行,接收 1 号算子产生的输出。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t (c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------
|
||||
|0 |EXCHANGE IN REMOTE | |100000 |109029|
|
||||
|1 | EXCHANGE OUT REMOTE| |100000 |64066 |
|
||||
|2 | TABLE SCAN |T |100000 |64066 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T.C1], [T.C2]), filter(nil)
|
||||
1 - output([T.C1], [T.C2]), filter(nil)
|
||||
2 - output([T.C1], [T.C2]), filter(nil),
|
||||
access([T.C1], [T.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 EXCH-IN/OUT (REMOTE) 算子的输出信息,字段的含义与 EXCH-IN/OUT 算子相同。
|
||||
|
||||
EXCH-IN/OUT (PKEY)
|
||||
---------------------------------------
|
||||
|
||||
EXCH-IN/OUT (PKEY) 算子用于数据重分区。它通常用于二元算子中,将一侧孩子节点的数据按照另外一些孩子节点的分区方式进行重分区。
|
||||
|
||||
如下示例中,该查询是对两个分区表的数据进行联接,执行计划将 s 表的数据按照 t 的分区方式进行重分区,4 号算子的输入是 s 表扫描的结果,对于 s 表的每一行,该算子会根据 t 表的数据分区,以及根据查询的联接条件,确定一行数据应该发送到哪个节点进行。
|
||||
|
||||
此外,可以看到 3 号算子是一个 EXCHANGE IN MERGE SORT DISTR,它是一个特殊的 EXCHANGE IN 算子,它用于在汇总多个分区的数据时,会进行一定的归并排序,在这个执行计划中,3 号算子接收到的每个分区的数据都是按照 c1 有序排列的,它会对每个接收到的数据进行归并排序,从而保证结果输出结果也是按照 c1 有序排列的。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 5;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE s (c1 INT PRIMARY KEY, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM s, t WHERE s.c1 = t.c1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS |COST |
|
||||
---------------------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |1960200000|3090308367|
|
||||
|1 | EXCHANGE OUT DISTR | |1960200000|1327558071|
|
||||
|2 | MERGE JOIN | |1960200000|1327558071|
|
||||
|3 | EXCHANGE IN MERGE SORT DISTR| |400000 |436080 |
|
||||
|4 | EXCHANGE OUT DISTR (PKEY) | |400000 |256226 |
|
||||
|5 | TABLE SCAN |S |400000 |256226 |
|
||||
|6 | TABLE SCAN |T |500000 |320292 |
|
||||
===============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([S.C1], [S.C2], [T.C1], [T.C2]), filter(nil)
|
||||
1 - output([S.C1], [S.C2], [T.C1], [T.C2]), filter(nil)
|
||||
2 - output([S.C1], [S.C2], [T.C1], [T.C2]), filter(nil),
|
||||
equal_conds([S.C1 = T.C1]), other_conds(nil)
|
||||
3 - output([S.C1], [S.C2]), filter(nil), sort_keys([S.C1, ASC])
|
||||
4 - (#keys=1, [S.C1]), output([S.C1], [S.C2]), filter(nil)
|
||||
5 - output([S.C1], [S.C2]), filter(nil),
|
||||
access([S.C1], [S.C2]), partitions(p[0-3])
|
||||
6 - output([T.C1], [T.C2]), filter(nil),
|
||||
access([T.C1], [T.C2]), partitions(p[0-4])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 EXCH-IN/OUT (PKEY) 算子的输出信息如下:
|
||||
|
||||
|
||||
| 信息名称 | 含义 |
|
||||
|--------|--------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 EXCH-IN/OUT(PKEY)算子没有设置 filter,所以为 nil。 |
|
||||
| pkey | 按照哪一列进行重分区。 例如,`#keys=1, [s.c1]` 表示按照 c1 这一列重分区 |
|
||||
|
||||
|
||||
|
||||
EXCH-IN/OUT (HASH)
|
||||
---------------------------------------
|
||||
|
||||
EXCH-IN/OUT (HASH) 算子用于对数据使用一组 HASH 函数进行重分区。
|
||||
|
||||
如下例所示的执行计划中,3-5 号以及 7-8 号是两组使用 HASH 重分区的 EXCHANGE 算子。这两组算子的作用是把 t 表和 s 表的数据按照一组新的 HASH 函数打散成多份,在这个例子中 HASH 的列为 t.c2 和 s.c2,这保证了 c2 取值相同的行会被分发到同一份中。基于重分区之后的数据,2 号算子 HASH JOIN 会对每一份数据按照 `t.c2= s.c2` 进行联接。
|
||||
|
||||
此外,由于查询中执行了并行度为 2,计划中展示了 dop = 2 (dop 是 Degree of Parallelism 的缩写)。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE s (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+PQ_DISTRIBUTE(@"SEL$1" ("TEST.S"@"SEL$1" ) HASH HASH),
|
||||
PARALLEL(2)*/ * FROM t, s WHERE t.c2 = s.c2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=================================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS |COST |
|
||||
-----------------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |1568160000|2473629500|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10002|1568160000|1063429263|
|
||||
|2 | HASH JOIN | |1568160000|1063429263|
|
||||
|3 | EXCHANGE IN DISTR | |400000 |436080 |
|
||||
|4 | EXCHANGE OUT DISTR (HASH)|:EX10000|400000 |256226 |
|
||||
|5 | PX PARTITION ITERATOR | |400000 |256226 |
|
||||
|6 | TABLE SCAN |T |400000 |256226 |
|
||||
|7 | EXCHANGE IN DISTR | |400000 |436080 |
|
||||
|8 | EXCHANGE OUT DISTR (HASH)|:EX10001|400000 |256226 |
|
||||
|9 | PX PARTITION ITERATOR | |400000 |256226 |
|
||||
|10| TABLE SCAN |S |400000 |256226 |
|
||||
=================================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T.C1], [T.C2], [S.C1], [S.C2]), filter(nil)
|
||||
1 - output([T.C1], [T.C2], [S.C1], [S.C2]), filter(nil), dop=2
|
||||
2 - output([T.C1], [T.C2], [S.C1], [S.C2]), filter(nil),
|
||||
equal_conds([T.C2 = S.C2]), other_conds(nil)
|
||||
3 - output([T.C1], [T.C2]), filter(nil)
|
||||
4 - (#keys=1, [T.C2]), output([T.C1], [T.C2]), filter(nil), dop=2
|
||||
5 - output([T.C1], [T.C2]), filter(nil)
|
||||
6 - output([T.C1], [T.C2]), filter(nil),
|
||||
access([T.C1], [T.C2]), partitions(p[0-3])
|
||||
7 - output([S.C1], [S.C2]), filter(nil)
|
||||
8 - (#keys=1, [S.C2]), output([S.C1], [S.C2]), filter(nil), dop=2
|
||||
9 - output([S.C1], [S.C2]), filter(nil)
|
||||
10 - output([S.C1], [S.C2]), filter(nil),
|
||||
access([S.C1], [S.C2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,PX PARTITION ITERATO 算子用于按照分区粒度迭代数据,详细信息请参见 [GI](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/24.GI-1-2.md)。
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 EXCH-IN/OUT (HASH) 算子的输出信息如下:
|
||||
|
||||
|
||||
| 信息名称 | 含义 |
|
||||
|--------|--------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 EXCH-IN/OUT (HASH) 算子没有设置 filter,所以为 nil。 |
|
||||
| pkey | 按照哪一列进行 HASH 重分区。 例如,`#keys=1, [s.c2]` 表示按照 c2 这一列进行 HASH 重分区。 |
|
||||
|
||||
|
||||
|
||||
EXCH-IN/OUT(BROADCAST)
|
||||
-------------------------------------------
|
||||
|
||||
EXCH-IN/OUT(BROADCAST) 算子用于对输入数据使用 BROADCAST 的方法进行重分区,它会将数据广播到其他线程上。
|
||||
|
||||
如下示例的执行计划中,3-4 号是一组使用 BROADCAST 重分区方式的 EXCHANGE 算子。它会将 t 表的数据广播到每个线程上,s 表每个分区的数据都会尝试和被广播的 t 表数据进行联接。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE s (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO s VALUES (1, 1), (2, 2), (3, 3), (4, 4);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPALIN SELECT /*+PARALLEL(2) */ * FROM t, s WHERE t.c2 = s.c2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS |COST |
|
||||
----------------------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |1568160000|2473449646|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|1568160000|1063249409|
|
||||
|2 | HASH JOIN | |1568160000|1063249409|
|
||||
|3 | EXCHANGE IN DISTR | |400000 |436080 |
|
||||
|4 | EXCHANGE OUT DISTR (BROADCAST)|:EX10000|400000 |256226 |
|
||||
|5 | PX PARTITION ITERATOR | |400000 |256226 |
|
||||
|6 | TABLE SCAN |T |400000 |256226 |
|
||||
|7 | PX PARTITION ITERATOR | |400000 |256226 |
|
||||
|8 | TABLE SCAN |S |400000 |256226 |
|
||||
======================================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T.C1], [T.C2], [S.C1], [S.C2]), filter(nil)
|
||||
1 - output([T.C1], [T.C2], [S.C1], [S.C2]), filter(nil), dop=2
|
||||
2 - output([T.C1], [T.C2], [S.C1], [S.C2]), filter(nil),
|
||||
equal_conds([T.C2 = S.C2]), other_conds(nil)
|
||||
3 - output([T.C1], [T.C2]), filter(nil)
|
||||
4 - output([T.C1], [T.C2]), filter(nil), dop=2
|
||||
5 - output([T.C1], [T.C2]), filter(nil)
|
||||
6 - output([T.C1], [T.C2]), filter(nil),
|
||||
access([T.C1], [T.C2]), partitions(p[0-3])
|
||||
7 - output([S.C1], [S.C2]), filter(nil)
|
||||
8 - output([S.C1], [S.C2]), filter(nil),
|
||||
access([S.C1], [S.C2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 EXCH-IN/OUT (BROADCAST) 算子的信息,字段的含义与 EXCH-IN/OUT 算子相同。
|
||||
@ -0,0 +1,86 @@
|
||||
GI
|
||||
=======================
|
||||
|
||||
GI 算子用于并行执行中,用于按照分区或者按照数据块迭代整张表。
|
||||
|
||||
按照迭代数据的粒度划分,GI 算子包括 PX PARTITION ITERATOR 和 PX BLOCK ITERATOR。
|
||||
|
||||
PX PARTITION ITERATOR
|
||||
------------------------------------------
|
||||
|
||||
PX PARTITION ITERATOR 算子用于按照分区粒度迭代数据。
|
||||
|
||||
如下示例中,2 号算子按分区粒度迭代出数据。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE INDEX idx ON t (c1);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+FULL(t)*/ c1 FROM t\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |400000 |427257|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|400000 |247403|
|
||||
|2 | PX PARTITION ITERATOR| |400000 |247403|
|
||||
|3 | TABLE SCAN |T |400000 |247403|
|
||||
======================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T.C1], [T.C2]), filter(nil)
|
||||
1 - output([T.C1], [T.C2]), filter(nil), dop=1
|
||||
2 - output([T.C1], [T.C2]), filter(nil)
|
||||
3 - output([T.C1], [T.C2]), filter(nil),
|
||||
access([T.C1], [T.C2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 PX PARTITION ITERATOR 算子的输出信息如下:
|
||||
|
||||
|
||||
| 信息名称 | 含义 |
|
||||
|--------|-------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 PX PARTITION ITERATOR 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
PX BLOCK ITERATOR
|
||||
--------------------------------------
|
||||
|
||||
PX BLOCK ITERATOR 算子用于按照数据块粒度迭代数据。
|
||||
|
||||
相对于 PX PARTITION ITERATOR,PX BLOCK ITERATOR 算子按照数据块迭代的方式粒度更小,能够切分出更多的任务,支持更高的并行度。
|
||||
|
||||
```sql
|
||||
obclient>EXPLAIN SELECT /*+PARALLEL(4)*/ c1 FROM t\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------------------
|
||||
|0 |PX COORDINATOR | |400000 |279171|
|
||||
|1 | EXCHANGE OUT DISTR|:EX10000|400000 |189244|
|
||||
|2 | PX BLOCK ITERATOR| |400000 |189244|
|
||||
|3 | TABLE SCAN |T(IDX) |400000 |189244|
|
||||
==================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T.C1]), filter(nil)
|
||||
1 - output([T.C1]), filter(nil), dop=4
|
||||
2 - output([T.C1]), filter(nil)
|
||||
3 - output([T.C1]), filter(nil),
|
||||
access([T.C1]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例的执行计划展示中的 outputs \& filters 详细列出了 PX BLOCK ITERATOR 算子的输出信息,字段的含义与 PX PARTITION ITERATOR 算子相同。
|
||||
@ -0,0 +1,262 @@
|
||||
JOIN
|
||||
=========================
|
||||
|
||||
JOIN 算子用于将两张表的数据,按照特定的条件进行联接。
|
||||
|
||||
JOIN 的类型主要包括内联接(INNER JOIN)、外联接(OUTER JOIN)和半联接(SEMI/ANTI JOIN)三种。
|
||||
|
||||
OceanBase 数据库支持的 JOIN 算子主要有 NESTED LOOP JOIN (NLJ)、MERGE JOIN (MJ) 和 HASH JOIN (HJ)。
|
||||
|
||||
NESTED LOOP JOIN (NLJ)
|
||||
-------------------------------------------
|
||||
|
||||
如下示例中,Q1 和 Q2 查询使用 HINT 指定了查询使用 NLJ。其中,0 号算子是一个 NLJ 算子。这个算子存在两个子节点,分别是 1 号算子和 2 号算子,它的执行逻辑为:
|
||||
|
||||
1. 从 1 号算子读取一行。
|
||||
|
||||
|
||||
|
||||
2. 打开 2 号算子,读取所有的行。
|
||||
|
||||
|
||||
|
||||
3. 联接接 1和 2 号算子的输出结果,并执行过滤条件,输出结果。
|
||||
|
||||
|
||||
|
||||
4. 重复第一步,直到 1 号算子迭代结束。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (d1 INT, d2 INT, PRIMARY KEY (d1));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT /*+USE_NL(t1, t2)*/ t1.c2 + t2.d2 FROM t1, t2
|
||||
WHERE c2 = d2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |9782 |411238|
|
||||
|1 | TABLE SCAN |T1 |999 |647 |
|
||||
|2 | MATERIAL | |999 |1519 |
|
||||
|3 | TABLE SCAN |T2 |999 |647 |
|
||||
===========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C2 + T2.D2]), filter(nil),
|
||||
conds([T1.C2 = T2.D2]), nl_params_(nil)
|
||||
1 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
2 - output([T2.D2]), filter(nil)
|
||||
3 - output([T2.D2]), filter(nil),
|
||||
access([T2.D2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,MATERIAL 算子用于物化下层算子输出的数据,详细信息请参见 [MATERIAL](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/10.MATERIAL-1-2.md)。
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT /*+USE_NL(t1, t2)*/ t1.c2 + t2.d2 FROM t1, t2
|
||||
WHERE c1 = d1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ==========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |990 |37346|
|
||||
|1 | TABLE SCAN |T1 |999 |669 |
|
||||
|2 | TABLE GET |T2 |1 |36 |
|
||||
==========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C2 + T2.D2]), filter(nil),
|
||||
conds(nil), nl_params_([T1.C1])
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.D2]), filter(nil),
|
||||
access([T2.D2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细展示了 NESTED LOOP JOIN 算子的具体输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 NLJ 算子没有设置 filter,所以为 nil。 |
|
||||
| conds | 联接条件。 例如 Q1 查询中 `t1.c2 = t2.d2` 联接条件。 |
|
||||
| nl_params_ | 根据 NLJ 左表的数据产生的下推参数。 例如 Q2 查询中的 `t1.c1`。 NLJ 在迭代到左表的每一行时,都会根据 `nl_params` 构造一个参数,根据这个参数和原始的联接条件 `c1 = d1` ,构造一个右表上的过滤条件: `d1 = ?`。 这个过滤条件会下推到右表上,并抽取索引上的查询范围,即需要扫描索引哪个范围的数据。在 Q2 查询中,由于存在下推条件 `d1 = ?`,所以 2 号算子是 TABLE GET 算子。 |
|
||||
|
||||
|
||||
|
||||
如下示例中,Q3 查询中没有指定任何的联接条件,0 号算子展示成了一个 `NESTED-LOOP JOIN CARTESIAN`,逻辑上它还是一个 NLJ 算子,代表一个没有任何联接条件的 NLJ。
|
||||
|
||||
```javascript
|
||||
Q3:
|
||||
obclient>EXPLAIN SELECT t1.c2 + t2.d2 FROM t1, t2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =====================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN CARTESIAN| |998001 |747480|
|
||||
|1 | TABLE SCAN |T1 |999 |647 |
|
||||
|2 | MATERIAL | |999 |1519 |
|
||||
|3 | TABLE SCAN |T2 |999 |647 |
|
||||
=====================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C2 + T2.D2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
1 - output([T1.C2]), filter(nil),
|
||||
access([T1.C2]), partitions(p0)
|
||||
2 - output([T2.D2]), filter(nil)
|
||||
3 - output([T2.D2]), filter(nil),
|
||||
access([T2.D2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
MERGE JOIN (MJ)
|
||||
------------------------------------
|
||||
|
||||
如下示例中,Q4 查询使用 `USE_MERGE` 的 HINT 指定了查询使用 MJ。其中,0 号算子是一个 MJ 算子,它有两个子节点,分别是 1 和 3 号算子。该算子会对左右子节点的数据进行归并联接,因此,要求左右子节点的数据相对于联接列是有序的。
|
||||
|
||||
以 Q4 查询为例,联接条件为 `t1.c2 = t2.d2`,它要求 t1 的数据是按照 c2 排序的,t2 的数据是按照 d2 排序的。在 Q4 查询中,2 号算子的输出是无序的;4 号算子的输出是按照 d2 排序的,均不满足 MERGE JOIN 对序的要求,因此,分配了 1 和 3 号算子进行排序。
|
||||
|
||||
```javascript
|
||||
Q4:
|
||||
obclient>EXPLAIN SELECT /*+USE_MERGE(t1, t2)*/ t1.c2 + t2.d2 FROM t1, t2
|
||||
WHERE c2 = d2 AND c1 + d1 > 10\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |MERGE JOIN | |3261 |14199|
|
||||
|1 | SORT | |999 |4505 |
|
||||
|2 | TABLE SCAN|T1 |999 |669 |
|
||||
|3 | SORT | |999 |4483 |
|
||||
|4 | TABLE SCAN|T2 |999 |647 |
|
||||
======================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C2 + T2.D2]), filter(nil),
|
||||
equal_conds([T1.C2 = T2.D2]), other_conds([T1.C1 + T2.D1 > 10])
|
||||
1 - output([T1.C2], [T1.C1]), filter(nil), sort_keys([T1.C2, ASC])
|
||||
2 - output([T1.C2], [T1.C1]), filter(nil),
|
||||
access([T1.C2], [T1.C1]), partitions(p0)
|
||||
3 - output([T2.D2], [T2.D1]), filter(nil), sort_keys([T2.D2, ASC])
|
||||
4 - output([T2.D2], [T2.D1]), filter(nil),
|
||||
access([T2.D2], [T2.D1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
如下示例中,Q5 查询中联接条件是 `t1.c1 = t2.d1` ,它要求 t1 的数据是按照 c1 排序的,t2 的数据是按照 d1 排序的。在这个执行计划中,t2 选择了主表扫描,结果是按照 d1 有序的,因此不需要额外分配一个 SORT 算子。理想情况下,JOIN 的左右表选择了合适的索引,索引提供的数据顺序能够满足 MJ 的要求,此时不需要分配任何 SORT 算子。
|
||||
|
||||
```javascript
|
||||
Q5:
|
||||
obclient>EXPLAIN SELECT /*+USE_MERGE(t1, t2)*/ t1.c2 + t2.d2 FROM t1, t2
|
||||
WHERE c1 = d1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |MERGE JOIN | |990 |6096|
|
||||
|1 | SORT | |999 |4505|
|
||||
|2 | TABLE SCAN|T1 |999 |669 |
|
||||
|3 | TABLE SCAN |T2 |999 |647 |
|
||||
=====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C2 + T2.D2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.D1]), other_conds(nil)
|
||||
1 - output([T1.C2], [T1.C1]), filter(nil), sort_keys([T1.C1, ASC])
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
3 - output([T2.D1], [T2.D2]), filter(nil),
|
||||
access([T2.D1], [T2.D2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示的 outputs \& filters 中详细展示了 MERGE JOIN 算子的具体输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-------------|-----------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于 MJ 算子没有设置 filter,所以为 nil。 |
|
||||
| equal_conds | 归并联接时使用的等值联接条件,左右子节点的结果集相对于联接列必须是有序的。 |
|
||||
| other_conds | 其他联接条件。 例如 Q4 查询中的 `t1.c1 + t2.d1 > 10` 。 |
|
||||
|
||||
|
||||
|
||||
HASH JOIN (HJ)
|
||||
-----------------------------------
|
||||
|
||||
如下示例中,Q6 查询使用 `USE_HASH` 的 HINT 指定了查询使用 HJ。其中,0 号算子是一个 HJ 算子,它有两个子节点,分别是 1 和 2 号算子。该算子的执行逻辑步骤如下:
|
||||
|
||||
1. 读取左子节点的数据,根据联接列计算哈希值(例如 `t1.c1`),构建一张哈希表。
|
||||
|
||||
|
||||
|
||||
2. 读取右子节点的数据,根据联接列计算哈希值(例如 `t2.d1`),尝试与对应哈希表中 t1 的数据进行联接。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
Q6:
|
||||
obclient>EXPLAIN SELECT /*+USE_HASH(t1, t2)*/ t1.c2 + t2.d2 FROM t1, t2
|
||||
WHERE c1 = d1 AND c2 + d2 > 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |HASH JOIN | |330 |4850|
|
||||
|1 | TABLE SCAN|T1 |999 |669 |
|
||||
|2 | TABLE SCAN|T2 |999 |647 |
|
||||
====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C2 + T2.D2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.D1]), other_conds([T1.C2 + T2.D2 > 1])
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.D1], [T2.D2]), filter(nil),
|
||||
access([T2.D1], [T2.D2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细展示了 HASH JOIN 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-------------|---------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于 HJ 算子没有设置 filter,所以为 nil。 |
|
||||
| equal_conds | 等值联接,左右两侧的联接列会用于计算哈希值。 |
|
||||
| other_conds | 其他联接条件。 例如 Q6 查询中的 `t1.c2 + t2.d2 > 1`。 |
|
||||
|
||||
|
||||
@ -0,0 +1,94 @@
|
||||
COUNT
|
||||
==========================
|
||||
|
||||
COUNT 算子用于兼容 Oracle 的 ROWNUM 功能,实现 ROWNUM 表达式的自增操作。
|
||||
|
||||
在一般场景下,当 SQL 查询含有 ROWNUM 时,SQL 优化器就会在生成执行计划的时候分配一个 COUNT 算子。当然在一些情况下,SQL 优化器会将含有 ROWNUM 的 SQL 改写为 LIMIT 算子,这时就不会再分配 COUNT 算子。
|
||||
|
||||
正常分配 COUNT 算子的场景
|
||||
-------------------------------------
|
||||
|
||||
示例 1:含有 ROWNUM 的 SQL 查询正常分配 COUNT 算子场景。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(5, 5);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT c1,ROWNUM FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |COUNT | |1 |37 |
|
||||
|1 | TABLE SCAN|T1 |1 |36 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [rownum()]), filter(nil)
|
||||
1 - output([T1.C1]), filter(nil),
|
||||
access([T1.C1]), partitions(p0)
|
||||
|
||||
obclient>SELECT c1,ROWNUM FROM t1;
|
||||
+------+--------+
|
||||
| C1 | ROWNUM |
|
||||
+------+--------+
|
||||
| 1 | 1 |
|
||||
| 3 | 2 |
|
||||
| 5 | 3 |
|
||||
+------+--------+
|
||||
3 rows in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中的 outputs \& filters 详细展示了 COUNT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|---------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 其中 rownum() 表示 ROWNUM 对应的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 COUNT 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
从上述执行计划示例的输出结果可以发现,ROWNUM 对应的表达式的初始值为 1,每通过一次 COUNT 算子,COUNT 算子就会为 ROWNUM 对应的表达式的值加上 1,实现 ROWNUM 表达式的自增操作。
|
||||
|
||||
不分配 COUNT 算子的场景
|
||||
------------------------------------
|
||||
|
||||
示例 2:含有 rownum 的 SQL 改写为 LIMIT 后,不分配 COUNT 算子的场景。
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT 1 FROM DUAL WHERE ROWNUM < 2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |LIMIT | |1 |1 |
|
||||
|1 | EXPRESSION| |1 |1 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([1]), filter(nil), limit(?), offset(nil)
|
||||
1 - output([1]), filter(nil)
|
||||
values({1})
|
||||
```
|
||||
|
||||
|
||||
|
||||
从上述执行计划示例的输出结果可以发现,虽然 SQL 中含有 ROWNUM,但是经过 SQL 优化器改写之后,已经将涉及含有 ROWNUM 的表达式转换为了等价的 LIMIT 表达式,转换的好处在于可以做更多的优化,详细信息请参见 [LIMIT](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/12.LIMIT-1-2.md)。
|
||||
@ -0,0 +1,140 @@
|
||||
GROUP BY
|
||||
=============================
|
||||
|
||||
GROUP BY 算子主要用于在 SQL 中进行分组聚合计算操作。
|
||||
|
||||
用于对数据进行分组的算法有 HASH 算法和 MERGE 算法,因此根据算法可以将 GROUP BY 算子分为两种:HASH GROUP BY 和 MERGE GROUP BY。执行计划生成时根据 SQL 优化器对于两种算子的代价评估,来选择使用哪种 GROUP BY 算子。
|
||||
|
||||
对于普通的聚合函数(SUM/MAX/MIN/AVG/COUNT/STDDEV)也是通过分配 GROUP BY 算子来完成,而对于只有聚合函数而不含有 GROUP BY 的 SQL,分配的是 SCALAR GROUP BY 算子,因此 GROUP BY 算子又可以分为三种:SCALAR GROUP BY、HASH GROUP BY 和 MERGE GROUP BY。
|
||||
|
||||
SCALAR GROUP BY
|
||||
------------------------------------
|
||||
|
||||
示例 1:含 SCALAR GROUP BY 算子的执行计划
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient> EXPLAIN SELECT SUM(c1) FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
----------------------------------------
|
||||
|0 |SCALAR GROUP BY| |1 |37 |
|
||||
|1 | TABLE SCAN |T1 |3 |37 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_SUM(T1.C1)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_SUM(T1.C1)])
|
||||
1 - output([T1.C1]), filter(nil),
|
||||
access([T1.C1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q1 查询的执行计划展示中的 outputs \& filters 中详细列出了 SCALAR GROUP BY 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 SCALAR GROUP BY 算子未设置 filter,所以为 nil。 |
|
||||
| group | 需要进行分组的列。 例如,Q1 查询中是 SCALAR GROUP BY 算子,所以为 nil。 |
|
||||
| agg_func | 所涉及的聚合函数。 例如,Q1 查询是计算表 t1 的 c1 列数据之和,因此为 `T_FUN_SUM(t1.c1)`。 |
|
||||
|
||||
|
||||
|
||||
HASH GROUP BY
|
||||
----------------------------------
|
||||
|
||||
示例 2:含 HASH GROUP BY 算子的执行计划
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>EXPLAIN SELECT SUM(c2) FROM t1 GROUP BY c1 HAVING SUM(c2) > 2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
--------------------------------------
|
||||
|0 |HASH GROUP BY| |1 |40 |
|
||||
|1 | TABLE SCAN |T1 |3 |37 |
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_SUM(T1.C2)]), filter([T_FUN_SUM(T1.C2) > 2]),
|
||||
group([T1.C1]), agg_func([T_FUN_SUM(T1.C2)])
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q2 查询的执行计划展示中的 outputs \& filters 详细列出了 HASH GROUP BY 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于设置要求分组后的 c2 列求和大于 2,因此为 `T_FUN_SUM(t1.c2) > 2`。 |
|
||||
| group | 需要进行分组的列。 例如,Q2 查询是 HASH GROUP BY 算子,所以为 nil。 |
|
||||
| agg_func | 所涉及的聚合函数。 例如,Q2 查询中计算表 t1 的 c1 列之和,因此为 `T_FUN_SUM(t1.c1)`。 |
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
HASH GROUP BY 算子将会保证在执行时采用 HASH 算法进行分组。
|
||||
|
||||
MERGE GROUP BY
|
||||
-----------------------------------
|
||||
|
||||
示例 3:含 MERGE GROUP BY 算子的执行计划
|
||||
|
||||
```javascript
|
||||
Q3:
|
||||
obclient>EXPLAIN SELECT /*+NO_USE_HASH_AGGREGATION*/SUM(c2) FROM
|
||||
t1 GROUP BY c1 HAVING SUM(c2) > 2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
---------------------------------------
|
||||
|0 |MERGE GROUP BY| |1 |45 |
|
||||
|1 | SORT | |3 |44 |
|
||||
|2 | TABLE SCAN |T1 |3 |37 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_SUM(T1.C2)]), filter([T_FUN_SUM(T1.C2) > 2]),
|
||||
group([T1.C1]), agg_func([T_FUN_SUM(T1.C2)])
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C1, ASC])
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,Q3 查询的执行计划展示中的 outputs \& filters 中详细列出了 MERGE GROUP BY 算子的信息,可以看出相同的 SQL 生成执行计划时选择了 MERGE GROUP BY 算子,其算子基本信息都是相同的,最大的区别是在执行的时候选择的分组算法不一样。同时,这里的 2 号算子 TABLE SCAN 返回的结果是一个无序结果,而 GROUP BY 算法采用的是 MERGE GROUP BY,因此必须分配一个 SORT 算子。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
NO_USE_HASH_AGGREGATION 和 USE_HASH_AGGREGATION 的 HINT 可以用于控制 GROUP BY 算子选择何种算法进行分组。
|
||||
@ -0,0 +1,63 @@
|
||||
WINDOW FUNCTION
|
||||
====================================
|
||||
|
||||
WINDOW FUNCTION 算子用于实现 SQL 中的分析函数(也叫窗口函数),计算窗口下的相关行的结果。
|
||||
|
||||
窗口函数与聚集函数不同的是,聚集函数一组只能返回一行,而窗口函数每组可以返回多行,组内每一行都是基于窗口的逻辑计算的结果。因此,在执行含有 WINDOW FUNCTION 的 SQL 时 (格式一般为 `OVER(...)`),都会在生成执行计划的时候分配一个 WINDOW FUNCTION 算子。
|
||||
|
||||
示例:含 WINDOW FUNCTION 算子的执行计划
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(1, 1);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(2, 2);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES(3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
Q1:
|
||||
obclient>EXPLAIN SELECT MAX(c1) OVER(PARTITION BY c1 ORDER BY c2) FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
----------------------------------------
|
||||
|0 |WINDOW FUNCTION| |3 |45 |
|
||||
|1 | SORT | |3 |44 |
|
||||
|2 | TABLE SCAN |T1 |3 |37 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_MAX(T1.C1)]), filter(nil),
|
||||
win_expr(T_FUN_MAX(T1.C1)), partition_by([T1.C1]), order_by([T1.C2, ASC]), window_type(RANGE), upper(UNBOUNDED PRECEDING), lower(CURRENT ROW)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C1, ASC], [T1.C2, ASC])
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,窗口函数中指定了一个 ORDER BY/PARTITION BY 的时候,会在下层分配一个 SORT 算子,将排序结果返回给窗口函数算子使用。
|
||||
|
||||
上述示例中,Q1 查询的执行计划展示中的 outputs \& filters 详细列出了 WINDOW FUNCTION 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|--------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的表达式。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中 WINDOW FUNCTION 算子没有设置 filter,所以为 nil。 |
|
||||
| win_expr | 在窗口中使用何种聚合函数。 例如,Q1 查询为求 c1 列的最大值,因此为`T_FUN_MAX(t1.c1)`。 |
|
||||
| partition_by | 在窗口中按照何种方式分组。 例如,Q1 查询为按照 c1 列分组,因此为 `t1.c1`。 |
|
||||
| order_by | 在窗口中按照何种方式排序。 例如,Q1 查询为按照 c2 列排序,因此为 `t1.c2`。 |
|
||||
| window_type | 窗口类型,包括 range 和 rows 两种: * range :按照逻辑位置偏移进行计算窗口上下界限,默认使用 range 方式。 * rows :按照实际物理位置偏移进行计算窗口上下界限。 例如,Q1 查询未设置窗口类型,因此选择了默认方式 range。 |
|
||||
| upper | 设定窗口的上边界: * UNBOUNDED :无边界,选择最大的值(默认)。 * CURRENT ROW :从当前行开始,如果出现数字则表示移动的行数。 * PRECEDING :向前取边 * FOLLOWING:向后取边界。 例如,Q1 查询设置的上边界为向前无边界。 |
|
||||
| lower | 设定窗口的下边界,边界属性设置同 upper。 例如,Q1 查询设置的下边界为当前行。 |
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
SUBPLAN FILTER
|
||||
===================================
|
||||
|
||||
SUBPLAN FILTER 算子用于驱动表达式中的子查询执行。
|
||||
|
||||
OceanBase 数据库以 NESTED-LOOP 算法执行 SUBPLAN FILTER 算子,执行时左边取一行数据,然后执行右边的子计划。SUBPLAN FILTER 算子可以驱动相关子查询和非相关子查询计算,并且两种执行方式不同。
|
||||
|
||||
驱动非相关子查询计算
|
||||
-------------------------------
|
||||
|
||||
示例 1:SUBPLAN FILTER 算子驱动非相关子查询计算
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+NO_REWRITE*/c1 FROM t1 WHERE
|
||||
c2 > (SELECT MAX(c2) FROM t2)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |SUBPLAN FILTER | |33334 |167652|
|
||||
|1 | TABLE SCAN |T1 |100000 |68478 |
|
||||
|2 | SCALAR GROUP BY| |1 |85373 |
|
||||
|3 | TABLE SCAN |T2 |100000 |66272 |
|
||||
===========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1]), filter(nil),
|
||||
exec_params_(nil), onetime_exprs_([subquery(1)]), init_plan_idxs_(nil)
|
||||
1 - output([T1.C1]), filter([T1.C2 > ?]),
|
||||
access([T1.C2], [T1.C1]), partitions(p0)
|
||||
2 - output([T_FUN_MAX(T2.C2)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_MAX(T2.C2)])
|
||||
3 - output([T2.C2]), filter(nil),
|
||||
access([T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中 0 号算子 SUBPLAN FILTER 驱动右边 SCALAR GROUP BY 子计划执行,outputs \& filters 详细列出了 SUBPLAN FILTER 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的列。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中的 SUBPLAN FILTER 算子没有设置 filter,所以为 nil。 |
|
||||
| exec_params_ | 右子计划依赖左子计划的参数,执行期由SUBPLAN FILTER 从左子计划中获取,传递给右子计划执行。 由于示例中 SUBPLAN FILTER 算子驱动非相关子查询没有涉及该参数,所以为 nil。 |
|
||||
| onetime_exprs_ | 计划中只计算一次的表达式,如果右子计划是非相关子查询,每次重复执行的结果都是一样的,所以执行一次后保存在参数集合中。 每次执行 SUBPLAN FILTER 时,可以直接从参数集获取右子计划的执行结果。参数 subquery(1) 表示 SUBPLAN FILTER 右边第一个子计划是 onetime expr。 |
|
||||
| init_plan_ids_ | 该算子中只需要执行一次的子计划。 它与 onetime_exprs_ 的区别是,init_plan_返回多行多列,onetime_expr_ 返回单行单列。 由于示例中的 SQL 查询未设置此项,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
SUBPLAN FILTER 算子驱动非相关子查询计算的一般执行流程如下:
|
||||
|
||||
1. SUBPLAN FILTER 在启动时会执行 onetime_exprs_。
|
||||
|
||||
|
||||
|
||||
2. 从参数中拿到右边非相关子查询的结果,下推 filter 到左边计划,执行左边的查询。
|
||||
|
||||
|
||||
|
||||
3. 输出左边查询的行。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
驱动相关子查询计算
|
||||
------------------------------
|
||||
|
||||
示例 2:SUBPLAN FILTER 算子驱动相关子查询计算
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT /*+NO_REWRITE*/c1 FROM t1 WHERE c2 > (SELECT
|
||||
MAX(c2) FROM t2 WHERE t1.c1=t2.c1)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ===============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------
|
||||
|0 |SUBPLAN FILTER | |33334 |8541203533|
|
||||
|1 | TABLE SCAN |T1 |100000 |68478 |
|
||||
|2 | SCALAR GROUP BY| |1 |85412 |
|
||||
|3 | TABLE SCAN |T2 |990 |85222 |
|
||||
===============================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1]), filter([T1.C2 > subquery(1)]),
|
||||
exec_params_([T1.C1]), onetime_exprs_(nil), init_plan_idxs_(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T_FUN_MAX(T2.C2)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_MAX(T2.C2)])
|
||||
3 - output([T2.C2]), filter([? = T2.C1]),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中 0 号算子 SUBPLAN FILTER 驱动右边 SCALAR GROUP BY 子计划执行,outputs \& filters 详细列出了 SUBPLAN FILTER 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-----------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的列。 |
|
||||
| filter | 该算子上的过滤条件。 例如,示例 2 中的 SQL 查询过滤条件为 `t1.c2 > subquery(1)`。 |
|
||||
| exec_params_ | 右子计划依赖左子计划的参数,执行期由SUBPLAN FILTER 从左子计划中获取,传递给右子计划执行。 左边输出一行数据后需要下推的参数,在非相关子查询中一般没有下推的参数。 |
|
||||
| onetime_exprs_ | 计划中只计算一次的表达式,如果右子计划是非相关子查询,每次重复执行的结果都是一样的,所以执行一次后保存在参数集合中。 每次执行 SUBPLAN FILTER 时,可以直接从参数集获取右子计划的执行结果。参数 subquery(1) 表示 SUBPLAN FILTER 右边第一个子计划是 onetime expr。 由于示例中的 SQL 查询未设置此项,所以为 nil。 |
|
||||
| init_plan_idxs_ | 该算子中只需要执行一次的子计划。 与 onetime_exprs_ 的区别是,init_plan_返回多行多列,onetime_expr_ 返回单行单列。 由于示例中的 SQL 查询未设置此项,所以为 nil。 |
|
||||
|
||||
|
||||
|
||||
SUBPLAN FILTER 算子驱动相关子查询计算的一般执行流程如下:
|
||||
|
||||
1. SUBPLAN FILTER 在启动时会执行 `onetime_exprs_`。
|
||||
|
||||
|
||||
|
||||
2. 执行左边的查询,输出一行后,计算相关参数,下推到右边,执行右边的子查询。
|
||||
|
||||
|
||||
|
||||
3. 执行 filter,输出符合条件的数据行。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,91 @@
|
||||
DISTINCT
|
||||
=============================
|
||||
|
||||
DISTINCT 算子用于为对数据行去重,包括去除重复的 NULL 值。
|
||||
|
||||
DISTINCT 算子包括 HASH DISTINCT 和 MERGE DISTINCT。
|
||||
|
||||
HASH DISTINCT
|
||||
----------------------------------
|
||||
|
||||
HASH DISTINCT 算子使用 HASH 算法执行 DISTINCT 运算。
|
||||
|
||||
示例 1:使用 HASH 算法执行 DISTINCT 运算,对 t1 表的 c1 列进行去重处理
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_HASH_AGGREGATION*/ DISTINCT c1 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
|=======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
---------------------------------------
|
||||
|0 |HASH DISTINCT| |101 |99169|
|
||||
|1 | TABLE SCAN |t1 |100000 |66272|
|
||||
=======================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1]), filter(nil),
|
||||
distinct([t1.c1])
|
||||
1 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中 0 号算子 HASH DISTINCT 执行去重运算,outputs \& filters 详细展示了 HASH DISTINCT 算子的具体输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|-----------|-------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子的输出列。 |
|
||||
| filter | 该算子的过滤谓词。 由于示例中 HASH DISTINCT 算子没有设置 filter,所以为 nil。 |
|
||||
| partition | 查询需要扫描的分区。 |
|
||||
| distinct | 指定需要去重的列。 例如,`distinct([t1.c1])` 的参数 `t1.c1` 指定对 t1 表的 c1 列进行去重处理,并且采用 HASH 算法。 |
|
||||
|
||||
|
||||
|
||||
MERGE DISTINCT
|
||||
-----------------------------------
|
||||
|
||||
MERGE DISTINCT 算子使用 MERGE 算法执行 DISTINCT 运算。
|
||||
|
||||
示例 2:使用 MERGE 算法执行 DISTINCT 运算
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT /*+NO_USE_HASH_AGGREGATION*/ DISTINCT c1 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
|=======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
---------------------------------------
|
||||
|0 |MERGE DISTINCT| |3 |40 |
|
||||
|1 | SORT | |3 |39 |
|
||||
|2 | TABLE SCAN |t1 |3 |37 |
|
||||
=======================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1]), filter(nil),
|
||||
distinct([t1.c1])
|
||||
1 - output([t1.c1]), filter(nil), sort_keys([t1.c1, ASC])
|
||||
2 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,0 号算子 MERGE DISTINCT 执行去重运算,采用了 MERGE 算法,并且由于 2 号算子输出的数据是无序的,而 MERGE DISTINCT 算子需要输入的数据有序,所以在执行去重运算前需要使用 SORT 算子对数据排序。执行计划展示中的 outputs \& filters 详细展示了 MERGE DISTINCT 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|--------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子的输出列。 |
|
||||
| filter | 该算子的过滤谓词。 由于示例中 MERGE DISTINCT 算子没有设置 filter,所以为 nil。 |
|
||||
| distinct | 指定需要去重的列。 例如,`distinct([t1.c1])` 的参数 `t1.c1` 指定对 t1 表的 c1 列进行去重处理,并且采用 MERGE 算法。 |
|
||||
|
||||
|
||||
@ -0,0 +1,46 @@
|
||||
SEQUENCE
|
||||
=============================
|
||||
|
||||
SEQUENCE 算子用于计算伪列 SEQUENCE 的值。
|
||||
|
||||
伪列 SEQUENCE 是由 `CREATE SEQUENCE` 创建的序列,下层算子每输出一行执行一次计算。
|
||||
|
||||
示例:计算伪列 SEQUENCE 的当前值与下一个值
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE SEQUENCE seq INCREMENT BY 1 START WITH 1;
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT seq.NEXTVAL, seq.CURRVAL FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
|=====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------
|
||||
|0 |SEQUENCE | |100000 |77868|
|
||||
|1 | TABLE SCAN|T1 |100000 |64066|
|
||||
=====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([SEQ.NEXTVAL], [SEQ.CURRVAL]), filter(nil)
|
||||
1 - output([T1.__pk_increment]), filter(nil),
|
||||
access([T1.__pk_increment]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中,执行计划展示中 0 号算子 SEQUENCE 用来计算序列的值,`output([SEQ.NEXTVAL],[SEQ.CURRVAL]` 指定了 SEQUENCE 需要计算序列的当前值与下一个值。t1 表每输出一行数据,SEQUENCE 就会计算一次序列的值。执行计划展示中 outputs \& filters 详细列出了 SEQUENCE 算子的输出信息如下:
|
||||
|
||||
|
||||
| **信息名称** | **含义** |
|
||||
|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| output | 该算子输出的列。 SEQUENCE 算子参数信息如下: * CURRVAl:计算序列的当前值。 * NEXTVAL:计算序列的下一个值。 |
|
||||
| filter | 该算子上的过滤条件。 由于示例中的 SEQUENCE 算子没有设置 filter,所以为 nil。 |
|
||||
|
||||
|
||||
@ -0,0 +1,199 @@
|
||||
执行计划缓存
|
||||
===========================
|
||||
|
||||
执行计划缓存(Plan Cache)用于减少执行计划的生成次数。
|
||||
|
||||
OceanBase 数据库会缓存之前生成的执行计划,以便在下次执行该 SQL 时直接使用,可以避免反复执行,从而优化执行过程,这种策略被称为"Optimize Once",即"一次优化"。
|
||||
|
||||
计划缓存是一个典型的 Key-Value 结构,Key 就是参数化后的 SQL 字符串,Value 就是该条 SQL 所对应的执行计划。
|
||||
|
||||
每个租户在每一台服务器上都有一个独立的计划缓存,用以缓存在此服务器上处理过的 SQL 计划。在 OceanBase 数据库的计划缓存中,SQL 的执行计划可以分为本地计划、远程计划和分布式计划三种类型。在计划缓存中,同一条 SQL 根据其需要访问的数据不同,可能同时具有三种执行计划。
|
||||
|
||||
对于一条 SQL 的一种执行计划,OceanBase 数据库默认只会保留第一次执行 SQL 时生成的计划;但在某些情况下,同一条 SQL 的参数值可能会影响到执行计划的选择,所以计划缓存会根据需要,为不同的参数值保留不同的执行计划,从而保证每次执行时可以使用最合适的计划。
|
||||
|
||||
计划缓存的淘汰
|
||||
----------------
|
||||
|
||||
计划缓存的淘汰是指将执行计划从计划缓存中删除,减少计划缓存对内存的使用。OceanBase 数据库支持自动淘汰和手动淘汰两种方式。
|
||||
|
||||
#### **自动淘汰**
|
||||
|
||||
自动淘汰是指当计划缓存占用的内存达到了需要淘汰计划的内存上限(即淘汰计划的高水位线)时,对计划缓存中的计划执行自动淘汰。
|
||||
|
||||
* 触发执行计划淘汰的条件
|
||||
|
||||
每隔一段时间(具体时间间隔由配置项 `plan_cache_evict_interval` 设置)系统会自动检查不同租户在不同服务器上的计划缓存,并判断是否需要执行计划淘汰。如果某个计划缓存占用的内存超过该租户设置的淘汰计划的高水位线,则会触发计划缓存淘汰。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 执行计划淘汰策略
|
||||
|
||||
当触发计划缓存淘汰后,优先淘汰最久没被使用的执行计划,淘汰一部分执行计划后,当计划缓存使用的内存为该租户设置的淘汰计划的低水位线时,停止淘汰。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 与计划缓存淘汰相关配置
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
|
||||
例如,租户内存大小为 10 G,各参数值设置如下:
|
||||
|
||||
* `ob_plan_cache_percentage`=10
|
||||
|
||||
|
||||
|
||||
* `ob_plan_cache_evict_high_percentage`=90
|
||||
|
||||
|
||||
|
||||
* `ob_plan_cache_evict_low_percentage`=50
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
则计算得出:
|
||||
|
||||
* 计划缓存内存上限绝对值 = 10G \* 10 / 100 = 1 G
|
||||
|
||||
|
||||
|
||||
* 淘汰计划的高水位线 = 1G \* 90 / 100 = 0.9 G
|
||||
|
||||
|
||||
|
||||
* 淘汰计划的低水位线 = 1G \* 50 / 100 = 0.5 G
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
由计算结果可知,当该租户在某个服务器上计划缓存使用超过 0.9 G 时,会触发淘汰,优先淘汰最久没执行的计划,当淘汰到使用内存只有 0.5 G 时,则停止淘汰。 如果淘汰速度没有新计划生成速度快,计划缓存使用内存达到内存上限绝对值 1 G 时,将不在往计划缓存中添加新计划,直到执行淘汰后所占内存小于 1 G 才会添加新计划到计划缓存中。
|
||||
|
||||
#### **手动淘汰**
|
||||
|
||||
手动淘汰是指强制将计划缓存中计划进行删除。现在支持指定不同租户对应的当前服务器或全部服务器中计划缓存全部删除,具体命令如下:
|
||||
|
||||
```javascript
|
||||
obclient>ALTER SYSTEM FLUSH PLAN CACHE [tenant_list] [global]
|
||||
/*其中 tenant_list 的格式为 tenant = 'tenant1, tenant2, tenant3....'*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中 tenant_list 和 global 为可选字段,使用说明如下:
|
||||
|
||||
* 如果没有指定 tenant_list,则清空所有租户的计划缓存。反之,则只清空特定租户的计划缓存。
|
||||
|
||||
|
||||
|
||||
* 如果没有指定 global,则清空本机的计划缓存。反之,则清空该租户所在的所有服务器上的计划缓存。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
计划缓存的刷新
|
||||
----------------
|
||||
|
||||
计划缓存中执行计划可能因为各种原因而失效,这时需要将计划缓存中失效计划进行刷新,即将该执行计划删除后重新优化生成计划再加入计划缓存。
|
||||
|
||||
如下场景会导致执行计划失效,需要对执行计划进行刷新:
|
||||
|
||||
* SQL 中涉及表的 Schema 变更时(比如添加索引、删除或增加列等),该 SQL 在计划缓存中所对应的执行计划将被刷新。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* SQL 中涉及重新收集表的统计信息时,该 SQL 在计划缓存中所对应的执行计划会被刷新。由于 OceanBase 数据库在数据合并时会统一进行统计信息的收集,因此在每次进行合并后,计划缓存中所有计划将被刷新。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
计划缓存的使用控制
|
||||
------------------
|
||||
|
||||
计划缓存可以使用系统变量及 HINT 实现使用控制。
|
||||
|
||||
* 系统变量控制
|
||||
|
||||
当 `ob_enable_plan_cache` 设置为 TURE 时,表示 SQL 请求可以使用计划缓存;设置为 FALSE 时,表示 SQL 请求不使用计划缓存。默认为 TURE。此系统变量可被设置为 SESSION 级别或者 GLOBAL 级别。
|
||||
|
||||
|
||||
* HINT 控制
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
|
||||
计划缓存暂不支持的场景
|
||||
--------------------
|
||||
|
||||
* 执行计划所占内存超过 20 M 时,不会加入计划缓存。
|
||||
|
||||
|
||||
|
||||
* 如果该计划为分布式执行计划且涉及多个表,不会加入计划缓存。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
计划缓存的视图
|
||||
----------------
|
||||
|
||||
执行计划相关视图包括:
|
||||
|
||||
* `(g)v$plan_cache_stat`
|
||||
|
||||
记录每个计划缓存的状态,每个计划缓存在该视图中有一条记录。
|
||||
|
||||
|
||||
* `(g)v$plan_cache_plan_stat`
|
||||
|
||||
记录计划缓存中所有执行计划的具体信息及每个计划总的执行统计信息。
|
||||
|
||||
|
||||
* `(g)v$plan_cache_plan_explain`
|
||||
|
||||
记录某条 SQL 在计划缓存中的执行计划。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
有关视图的详细参数信息,请参考 [计划缓存相关视图](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/3.plan-cache-view.md)。
|
||||
@ -0,0 +1,212 @@
|
||||
快速参数化
|
||||
==========================
|
||||
|
||||
参数化过程是指把 SQL 查询中的常量变成变量的过程。
|
||||
|
||||
同一条 SQL 语句在每次执行时可能会使用不同的参数,将这些参数做参数化处理,可以得到与具体参数无关的 SQL 字符串,并使用该字符串作为计划缓存的键值,用于在计划缓存中获取执行计划,从而达到参数不同的 SQL 能够共用相同的计划目的。
|
||||
|
||||
由于传统数据库在进行参数化时一般是对语法树进行参数化,然后使用参数化后的语法树作为键值在计划缓存中获取计划,而 OceanBase 数据库使用的词法分析对文本串直接参数化后作为计划缓存的键值,因此叫做快速参数化。
|
||||
|
||||
OceanBase 数据库支持自适应计划共享(Adaptive Cursor Sharing)功能以支持不同参数条件下的计划选择。
|
||||
|
||||
基于快速参数化而获取执行计划的流程如下图所示:
|
||||
|
||||
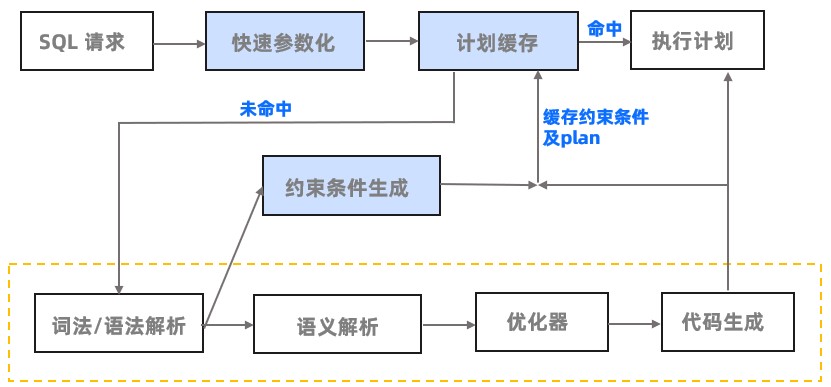
|
||||
|
||||
**示例解析**
|
||||
|
||||
```javascript
|
||||
obclient>SELECT * FROM T1 WHERE c1 = 5 AND c2 ='oceanbase';
|
||||
```
|
||||
|
||||
|
||||
|
||||
上述示例中的 SQL 查询参数化后结果如下所示,常量 5 和 oceanbase 被参数化后变成了变量 @1 和 @2:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT * FROM T1 WHERE c1 = @1 AND c2 = @2;
|
||||
```
|
||||
|
||||
|
||||
|
||||
但在计划匹配中,不是所有常量都可以被参数化,例如 ORDER BY 后面的常量,表示按照 SELECT 投影列中第几列进行排序,所以不可以被参数化。
|
||||
|
||||
如下例所示,表 t1 中含 c1、c2 列,其中 c1 为主键列,SQL 查询的结果按照 c1 列进行排序,由于 c1 作为主键列是有序的,所以使用主键访问可以免去排序。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY,c2 INT);
|
||||
Query OK, 0 rows affected (0.06 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES (1,2);
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES (2,1);
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient>INSERT INTO t1 VALUES (3,1);
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient>SELECT c1, c2 FROM t1 ORDER BY 1;
|
||||
|
||||
+----+------+
|
||||
| C1 | C2 |
|
||||
+----+------+
|
||||
| 1 | 2 |
|
||||
| 2 | 1 |
|
||||
| 3 | 1 |
|
||||
+----+------+
|
||||
3 rows in set (0.00 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT c1, c2 FROM t1 ORDER BY 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1000 |1381|
|
||||
===================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
但如果执行如下命令:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT c1, c2 FROM t1 ORDER BY 2;
|
||||
|
||||
+----+------+
|
||||
| C1 | C2 |
|
||||
+----+------+
|
||||
| 2 | 1 |
|
||||
| 3 | 1 |
|
||||
| 1 | 2 |
|
||||
+----+------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
则结果需要对 c2 排序,因此需要执行显示的排序操作,执行计划如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT c1, c2 FROM t1 ORDER BY 2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |SORT | |1000 |1886|
|
||||
|1 | TABLE SCAN|t1 |1000 |1381|
|
||||
====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C2, ASC])
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
因此,如果将 ORDER BY 后面的常量参数化,不同 ORDER BY 的值具有相同的参数化后的 SQL,从而导致命中错误的计划。除此之外,如下场景中的常量均不能参数化(即参数化的约束条件):
|
||||
|
||||
* 所有 ORDER BY 后常量(例如 `ORDER BY 1,2;`)
|
||||
|
||||
|
||||
|
||||
* 所有 GROUP BY 后常量(例如 `GROUP BY 1,2;`)
|
||||
|
||||
|
||||
|
||||
* LIMIT 后常量(例如 `LIMIT 5;`)
|
||||
|
||||
|
||||
|
||||
* 作为格式串的字符串常量(例如 `SELECT DATE_FORMAT('2006-06-00', '%d');` 里面的` %d`)
|
||||
|
||||
|
||||
|
||||
* 函数输入参数中,影响函数结果并最终影响执行计划的常量(例如 `CAST(999.88 as NUMBER(2,1)) `中的 `NUMBER(2,1)`,或者 `SUBSTR('abcd', 1, 2) `中的 1 和 2)
|
||||
|
||||
|
||||
|
||||
* 函数输入参数中,带有隐含信息并最终影响执行计划的常量(例如 `SELECT UNIX_TIMESTAMP('2015-11-13 10:20:19.012');` 里面的"2015-11-13 10:20:19.012",指定输入时间戳的同时,隐含指定了函数处理的精度值为毫秒)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
为了解决上面这种可能存在的误匹配问题,在硬解析生成执行计划过程中会对 SQL 请求使用分析语法树的方法进行参数化,并获取相应的不一致的信息。例如,某语句对应的信息是"快速参数化参数数组的第 3 项必须为数字 3",可将其称为"约束条件"。
|
||||
|
||||
对于下例所示的 Q1 查询:
|
||||
|
||||
```javascript
|
||||
Q1:
|
||||
obclient>SELECT c1, c2, c3 FROM t1
|
||||
WHERE c1 = 1 AND c2 LIKE 'senior%' ORDER BY 3;
|
||||
```
|
||||
|
||||
|
||||
|
||||
经过词法分析,可以得到参数化后的 SQL 语句如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT c1, c2, c3 FROM t1
|
||||
WHERE c1 = @1 AND c2 LIKE @2 ORDER BY @3 ;
|
||||
/*参数化数组为 {1,'senior%' ,3}*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
当 ORDER BY 后面的常量不同时,不能共用相同的执行计划,因此在通过分析语法树进行参数化时会获得另一种参数化结果,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT c1, c2, c3 FROM t1
|
||||
WHERE c1 = @1 AND c2 LIKE @2 ORDER BY 3 ;
|
||||
|
||||
/*参数化数组为{1, 'senior'}
|
||||
约束条件为"快速参数化参数数组的第 3 项必须为数字 3"*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
Q1 请求新生成的参数化后的文本及约束条件和执行计划均会存入计划缓存中。
|
||||
|
||||
当用户再次发出如下 Q2 请求命令:
|
||||
|
||||
```javascript
|
||||
Q2:
|
||||
obclient>SELECT c1, c2, c3 FROM t1
|
||||
WHERE c1 = 1 AND c2 LIKE 'senior%' ORDER BY 2;
|
||||
```
|
||||
|
||||
|
||||
|
||||
经过快速参数化后结果如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT c1, c2, c3 FROM t1
|
||||
WHERE c1 = @1 and c2 like @2 ORDER BY @3;
|
||||
/*参数化数组为 {1,'senior%' ,2}*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
这与 Q1 请求快速参数化后 SQL 结果一样,但由于不满足"快速参数化参数数组的第 3 项必须为数字 3"这个约束条件,无法匹配该计划。此时 Q2 会通过硬解析生成新的执行计划及约束条件(即"快速参数化参数数组的第 3 项必须为数字 2"),并将新的计划和约束条件加入到缓存中,这样在下次执行 Q1 和 Q2 时均可命中对应正确的执行计划。
|
||||
|
||||
基于快速参数化的执行计划缓存优点如下:
|
||||
|
||||
* 节省了语法分析过程。
|
||||
|
||||
|
||||
|
||||
* 查找 HASH MAP 时,可以将对参数化后语法树的 HASH 和比较操作,替换为对文本串进行 HASH 和 MEMCMP 操作,以提高执行效率。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
实时执行计划展示
|
||||
=============================
|
||||
|
||||
|
||||
|
||||
使用 EXPLAIN 命令可以展示出当前优化器所生成的执行计划,但由于统计信息变化、用户 session 变量设置变化等,会造成该 SQL 在计划缓存中实际对应的计划可能与 EXPLAIN 的结果并不相同。为了确定该 SQL 在系统中实际使用的执行计划,需要进一步分析计划缓存中的物理执行计划。
|
||||
|
||||
用户可以通过查询 `(g)v$plan_cache_plan_explain` 视图来展示某条 SQL 在计划缓存中的执行计划。
|
||||
|
||||
如下例所示:
|
||||
|
||||
```sql
|
||||
obclient>VIEW_DEFINITION='SELECT *
|
||||
FROM oceanbase.gv$plan_cache_plan_explain
|
||||
WHERE IP =host_ip() AND PORT = rpc_port()'
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数解释如下表:
|
||||
|
||||
|
||||
| **字段名称** | **类型** | **描述** |
|
||||
|-----------|--------------|-----------------|
|
||||
| TENANT_ID | bigint(20) | 租户 ID |
|
||||
| IP | varchar(32) | IP 地址 |
|
||||
| PORT | bigint(20) | 端口号 |
|
||||
| PLAN_ID | bigint(20) | 执行计划的 ID |
|
||||
| OPERATOR | varchar(128) | operator 的名称 |
|
||||
| NAME | varchar(128) | 表的名称 |
|
||||
| ROWS | bigint(20) | 预估的结果行数 |
|
||||
| COST | bigint(20) | 预估的代价 |
|
||||
| PROPERTY | varchar(256) | 对应 operator 的信息 |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
第一步 查询 SQL 在计划缓存中的 plan_id
|
||||
-----------------------------------
|
||||
|
||||
OceanBase 数据库每个服务器的计划缓存都是独立的。用户可以直接访问 `v$plan_cache_plan_stat` 视图查询本服务器上的计划缓存并提供 tenant_id 和需要查询的 SQL 字符串(可以使用模糊匹配),查询该条 SQL 在计划缓存中对应的 plan_id。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT * FROM v$plan_cache_plan_stat WHERE tenant_id= 1001
|
||||
AND STATEMENT LIKE 'INSERT INTO T1 VALUES%'\G
|
||||
|
||||
***************************1. row ***************************
|
||||
tenant_id: 1001
|
||||
svr_ip:100.81.152.44
|
||||
svr_port:15212
|
||||
plan_id: 7
|
||||
sql_id:0
|
||||
type: 1
|
||||
statement: insert into t1 values(1)
|
||||
plan_hash:1
|
||||
last_active_time:2016-05-28 19:08:57.416670
|
||||
avg_exe_usec:0
|
||||
slowest_exe_time:1970-01-01 08:00:00.000000
|
||||
slowest_exe_usec:0
|
||||
slow_count:0
|
||||
hit_count:0
|
||||
mem_used:8192
|
||||
1 rowin set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
第二步 使用 plan_id 展示对应执行计划
|
||||
--------------------------------
|
||||
|
||||
获得 plan_id 后,用户可以使用 tenant_id 和 plan_id 访问 `v$plan_cache_plan_explain` 来展示该执行计划。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
这里展示的计划为物理执行计划,在算子命名上会与 EXPLAIN 所展示的逻辑执行计划有所不同。
|
||||
|
||||
```sql
|
||||
obclient>SELECT * FROM v$plan_cache_plan_explain
|
||||
WHERE tenant_id = 1001 AND plan_id = 7;
|
||||
|
||||
+-----------+---------------+-------+---------+--------------------+------+------+------+
|
||||
| TENANT_ID | IP | PORT | PLAN_ID | OPERATOR | NAME | ROWS | COST |
|
||||
+-----------+---------------+-------+---------+--------------------+------+------+------+
|
||||
| 1001 | 100.81.152.44 | 15212 | 7 | PHY_ROOT_TRANSMIT | NULL | 0 | 0 |
|
||||
| 1001 | 100.81.152.44 | 15212 | 7 | PHY_INSERT | NULL | 0 | 0 |
|
||||
| 1001 | 100.81.152.44 | 15212 | 7 | PHY_EXPR_VALUES | NULL | 0 | 0 |
|
||||
+-----------+---------------+-------+---------+--------------------+------+------+------+
|
||||
3 rows in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
* 如果访问 `gv$plan_cache_plan_explain`,必须给定 IP、port、tenant_id 和 plan_id 这四列的值。
|
||||
|
||||
|
||||
|
||||
* 如果访问 `v$plan_cache_plan_explain`,必须给定 tenant_id 和 plan_id 的值,否则系统将返回空集。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
分布式执行和并行查询
|
||||
===============================
|
||||
|
||||
本章节介绍分布式执行和并行查询。
|
||||
|
||||
分布式执行
|
||||
--------------------------
|
||||
|
||||
对于 Shared-Nothing 的分布式系统,由于一个关系数据表的数据会以分区的方式存放在系统里面的各个节点上,所以对于跨分区的数据查询请求,必然会要求执行计划能够对多个节点的数据进行操作,因而 OceanBase 数据库具有分布式执行计划生成和执行能力。
|
||||
|
||||
对于分布式执行计划,分区可以提高查询性能。如果数据库关系表比较小,则不必要进行分区,如果关系表比较大,则需要根据上层业务需求谨慎选择分区键,以保证大多数查询能够使用分区键进行分区裁剪,从而减少数据访问量。
|
||||
|
||||
同时,对于有关联性的表,建议使用关联键作为分区键,并采用相同分区方式,使用 Table Group 将相同的分区配置在同样的节点上,以减少跨节点的数据交互。
|
||||
|
||||
OceanBase 数据库的优化器会自动根据查询和数据的物理分布生成分布式执行计划。
|
||||
|
||||
并行查询
|
||||
-------------------------
|
||||
|
||||
并行查询是指通过对查询计划的改造,提升对每一个查询计划的 CPU 和 IO 处理能力,从而缩短单个查询的响应时间。并行查询技术可以用于分布式执行计划,也可以用于本地查询计划。
|
||||
|
||||
当单个查询的访问数据不在同一个节点上时,需要通过数据重分布的方式,将相关的数据分布到相同的节点进行计算。以每一次的数据重分布节点为上下界,OceanBase 数据库的执行计划在垂直方向上被划分为多个 DFO(Data Flow Object),而每一个 DFO 可以被切分为指定并行度的任务,通过并发执行以提高执行效率。
|
||||
|
||||
一般来说,当并行度提高时,查询的响应时间会缩短,更多的 CPU、IO 和内存资源会被用于执行查询命令。对于支持大数据量查询处理的 DSS(Decision Support Systems)系统或者数据仓库型应用来说,查询时间的提升尤为明显。
|
||||
|
||||
整体来说,并行查询的总体思路和分布式执行计划有相似之处,即将执行计划分解之后,将执行计划的每个部分由多个执行线程执行,通过一定的调度的方式,实现执行计划的 DFO 之间的并发执行和 DFO 内部的并发执行。并行查询特别适用于在线交易(OLTP)场景的批量更新操作、创建索引和维护索引等操作。
|
||||
|
||||
当系统满足以下条件时,并行查询可以有效提升系统处理性能:
|
||||
|
||||
* 充足的 IO 带宽
|
||||
|
||||
|
||||
|
||||
* 系统 CPU 负载较低
|
||||
|
||||
|
||||
|
||||
* 充足的内存资源
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
如果系统没有充足的资源进行额外的并行处理,使用并行查询或者提高并行度并不能提高执行性能。相反,在系统过载的情况下,操作系统会被迫进行更多的调度,例如,执行上下文切换或者页面交换,可能会导致性能的下降。
|
||||
|
||||
通常在 DSS 系统中,需要访问大量分区和数据仓库环境,这时并行执行能够提升执行响应时间。对于简单的 DML 操作或者分区内查询以及涉及分区数比较小的查询来说,使用并行查询并不能很明显的降低查询响应时间。
|
||||
@ -0,0 +1,294 @@
|
||||
分布式计划的生成
|
||||
=============================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库的优化器会分为以下两大阶段来生成分布式的执行计划。
|
||||
|
||||
1. 第一阶段:不考虑数据的物理分布,生成所有基于本地关系优化的最优执行计划。在本地计划生成后,优化器会检查数据是否访问了多个分区,或者是否访问的是本地单分区表但是用户使用 HINT 强制采用了并行查询执行。
|
||||
|
||||
2. 第二阶段:生成分布式计划。根据执行计划树,在需要进行数据重分布的地方,插入 EXCHANGE 节点,从而将原先的本地计划树变成分布式执行计划。
|
||||
|
||||
分布式执行计划的算子
|
||||
-------------------------------
|
||||
|
||||
生成分布式计划的过程就是在原始计划树上寻找恰当位置插入 EXCHANGE 算子的过程,在自顶向下遍历计划树的时候,需要根据相应算子的数据处理情况以及输入算子的数据分区情况,来决定是否需要插入 EXCHANGE 算子。
|
||||
|
||||
如下示例为最简单的单表扫描:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t1 (v1 INT, v2 INT) PARTITION BY HASH(v1) PARTITIONS 5;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==============================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |500000 |545109|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|500000 |320292|
|
||||
|2 | PX PARTITION ITERATOR| |500000 |320292|
|
||||
|3 | TABLE SCAN |T1 |500000 |320292|
|
||||
======================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.V1], [T1.V2]), filter(nil)
|
||||
1 - output([T1.V1], [T1.V2]), filter(nil), dop=1
|
||||
2 - output([T1.V1], [T1.V2]), filter(nil)
|
||||
3 - output([T1.V1], [T1.V2]), filter(nil),
|
||||
access([T1.V1], [T1.V2]), partitions(p[0-4])
|
||||
```
|
||||
|
||||
|
||||
|
||||
当 t1 是一个分区表,可以在 TABLE SCAN 上插入配对的 EXCHANGE 算子,从而将 TABLE SCAN 和 EXCHANGE OUT 封装成一个 job,可以用于并行的执行。
|
||||
|
||||
**单输入可下压算子**
|
||||
|
||||
单输入可下压算子主要包括 AGGREGATION、SORT、GROUP BY 和 LIMIT 算子等,除了 LIMIT 算子以外,其余所列举的算子都会有一个操作的键,如果操作的键和输入数据的数据分布是一致的,则可以做一阶段聚合操作,也即 Partition Wise Aggregation。如果操作的键和输入数据的数据分布是不一致的,则需要做两阶段聚合操作,聚合算子需要做下压操作。
|
||||
|
||||
一阶段聚合操作如下例所示:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t2 (v1 INT, v2 INT) PARTITION BY HASH(v1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT SUM(v1) FROM t2 GROUP BY v1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |101 |357302|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|101 |357297|
|
||||
|2 | PX PARTITION ITERATOR| |101 |357297|
|
||||
|3 | MERGE GROUP BY | |101 |357297|
|
||||
|4 | TABLE SCAN |t2 |400000 |247403|
|
||||
======================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_SUM(t2.v1)]), filter(nil)
|
||||
1 - output([T_FUN_SUM(t2.v1)]), filter(nil), dop=1
|
||||
2 - output([T_FUN_SUM(t2.v1)]), filter(nil)
|
||||
3 - output([T_FUN_SUM(t2.v1)]), filter(nil),
|
||||
group([t2.v1]), agg_func([T_FUN_SUM(t2.v1)])
|
||||
4 - output([t2.v1]), filter(nil),
|
||||
access([t2.v1]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
二阶段聚合操作如下例所示:
|
||||
|
||||
```sql
|
||||
| ============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
------------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |101 |561383|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|101 |561374|
|
||||
|2 | HASH GROUP BY | |101 |561374|
|
||||
|3 | EXCHANGE IN DISTR | |101 |408805|
|
||||
|4 | EXCHANGE OUT DISTR (HASH)|:EX10000|101 |408795|
|
||||
|5 | HASH GROUP BY | |101 |408795|
|
||||
|6 | PX PARTITION ITERATOR | |400000 |256226|
|
||||
|7 | TABLE SCAN |t2 |400000 |256226|
|
||||
============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_SUM(T_FUN_SUM(t2.v1))]), filter(nil)
|
||||
1 - output([T_FUN_SUM(T_FUN_SUM(t2.v1))]), filter(nil), dop=1
|
||||
2 - output([T_FUN_SUM(T_FUN_SUM(t2.v1))]), filter(nil),
|
||||
group([t2.v2]), agg_func([T_FUN_SUM(T_FUN_SUM(t2.v1))])
|
||||
3 - output([t2.v2], [T_FUN_SUM(t2.v1)]), filter(nil)
|
||||
4 - (#keys=1, [t2.v2]), output([t2.v2], [T_FUN_SUM(t2.v1)]), filter(nil), dop=1
|
||||
5 - output([t2.v2], [T_FUN_SUM(t2.v1)]), filter(nil),
|
||||
group([t2.v2]), agg_func([T_FUN_SUM(t2.v1)])
|
||||
6 - output([t2.v1], [t2.v2]), filter(nil)
|
||||
7 - output([t2.v1], [t2.v2]), filter(nil),
|
||||
access([t2.v1], [t2.v2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
**二元输入算子**
|
||||
|
||||
二元输入算子主要考虑 JOIN 算子的情况。对于 JOIN 算子来说,主要基于规则来生成分布式执行计划和选择数据重分布方法。JOIN 算子主要有以下三种联接方式:
|
||||
|
||||
* Partition-Wise Join
|
||||
|
||||
当左右表都是分区表且分区方式相同,物理分布一样,并且 JOIN 的联接条件为分区键时,可以使用以分区为单位的联接方法。如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t3 (v1 INT, v2 INT) PARTITION BY HASH(v1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t2, t3 WHERE t2.v1 = t3.v1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===========================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS |COST |
|
||||
|0 |PX COORDINATOR | |1568160000|1227554264|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|1568160000|930670004 |
|
||||
|2 | PX PARTITION ITERATOR| |1568160000|930670004 |
|
||||
|3 | MERGE JOIN | |1568160000|930670004 |
|
||||
|4 | TABLE SCAN |t2 |400000 |256226 |
|
||||
|5 | TABLE SCAN |t3 |400000 |256226 |
|
||||
===========================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t2.v1], [t2.v2], [t3.v1], [t3.v2]), filter(nil)
|
||||
1 - output([t2.v1], [t2.v2], [t3.v1], [t3.v2]), filter(nil), dop=1
|
||||
2 - output([t2.v1], [t2.v2], [t3.v1], [t3.v2]), filter(nil)
|
||||
3 - output([t2.v1], [t2.v2], [t3.v1], [t3.v2]), filter(nil),
|
||||
equal_conds([t2.v1 = t3.v1]), other_conds(nil)
|
||||
4 - output([t2.v1], [t2.v2]), filter(nil),
|
||||
access([t2.v1], [t2.v2]), partitions(p[0-3])
|
||||
5 - output([t3.v1], [t3.v2]), filter(nil),
|
||||
access([t3.v1], [t3.v2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* Partial Partition-Wise Join
|
||||
|
||||
当左右表中一个表为分区表,另一个表为非分区表,或者两者皆为分区表但是联接键仅和其中一个分区表的分区键相同的情况下,会以该分区表的分区分布为基准,重新分布另一个表的数据。如下例所示:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t4 (v1 INT, v2 INT) PARTITION BY HASH(v1) PARTITIONS 3;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t4, t2 WHERE t2.v1 = t4.v1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===========================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-----------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |11880 |17658|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|11880 |15409|
|
||||
|2 | NESTED-LOOP JOIN | |11880 |15409|
|
||||
|3 | EXCHANGE IN DISTR | |3 |37 |
|
||||
|4 | EXCHANGE OUT DISTR (PKEY)|:EX10000|3 |37 |
|
||||
|5 | PX PARTITION ITERATOR | |3 |37 |
|
||||
|6 | TABLE SCAN |t4 |3 |37 |
|
||||
|7 | PX PARTITION ITERATOR | |3960 |2561 |
|
||||
|8 | TABLE SCAN |t2 |3960 |2561 |
|
||||
===========================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil)
|
||||
1 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil), dop=1
|
||||
2 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil),
|
||||
conds(nil), nl_params_([t4.v1])
|
||||
3 - output([t4.v1], [t4.v2]), filter(nil)
|
||||
4 - (#keys=1, [t4.v1]), output([t4.v1], [t4.v2]), filter(nil), dop=1
|
||||
5 - output([t4.v1], [t4.v2]), filter(nil)
|
||||
6 - output([t4.v1], [t4.v2]), filter(nil),
|
||||
access([t4.v1], [t4.v2]), partitions(p[0-2])
|
||||
7 - output([t2.v1], [t2.v2]), filter(nil)
|
||||
8 - output([t2.v1], [t2.v2]), filter(nil),
|
||||
access([t2.v1], [t2.v2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 数据重分布
|
||||
|
||||
当联接键和左右表的分区键都没有关系的情况下,可以根据规则计算来选择使用 BROADCAST 还是 HASH HASH 的数据重分布方式,如下例所示:
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
只有在并行度大于 1 时, 以下示例中两种数据重分发方式才有可能被选中。
|
||||
|
||||
```sql
|
||||
obclient>EXPLAIN SELECT /*+ PARALLEL(2)*/* FROM t4, t2 WHERE t2.v2 = t4.v2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=================================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-----------------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |11880 |396863|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|11880 |394614|
|
||||
|2 | HASH JOIN | |11880 |394614|
|
||||
|3 | EXCHANGE IN DISTR | |3 |37 |
|
||||
|4 | EXCHANGE OUT DISTR (BROADCAST)|:EX10000|3 |37 |
|
||||
|5 | PX BLOCK ITERATOR | |3 |37 |
|
||||
|6 | TABLE SCAN |t4 |3 |37 |
|
||||
|7 | PX PARTITION ITERATOR | |400000 |256226|
|
||||
|8 | TABLE SCAN |t2 |400000 |256226|
|
||||
=================================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil)
|
||||
1 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil), dop=2
|
||||
2 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil),
|
||||
equal_conds([t2.v2 = t4.v2]), other_conds(nil)
|
||||
3 - output([t4.v1], [t4.v2]), filter(nil)
|
||||
4 - output([t4.v1], [t4.v2]), filter(nil), dop=2
|
||||
5 - output([t4.v1], [t4.v2]), filter(nil)
|
||||
6 - output([t4.v1], [t4.v2]), filter(nil),
|
||||
access([t4.v1], [t4.v2]), partitions(p[0-2])
|
||||
7 - output([t2.v1], [t2.v2]), filter(nil)
|
||||
8 - output([t2.v1], [t2.v2]), filter(nil),
|
||||
access([t2.v1], [t2.v2]), partitions(p[0-3])
|
||||
|
||||
|
||||
obclient>EXPLAIN SELECT /*+ PQ_DISTRIBUTE(t2 HASH HASH) PARALLEL(2)*/* FROM t4, t2
|
||||
WHERE t2.v2 = t4.v2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
------------------------------------------------------------
|
||||
|0 |PX COORDINATOR | |11880 |434727|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10002|11880 |432478|
|
||||
|2 | HASH JOIN | |11880 |432478|
|
||||
|3 | EXCHANGE IN DISTR | |3 |37 |
|
||||
|4 | EXCHANGE OUT DISTR (HASH)|:EX10000|3 |37 |
|
||||
|5 | PX BLOCK ITERATOR | |3 |37 |
|
||||
|6 | TABLE SCAN |t4 |3 |37 |
|
||||
|7 | EXCHANGE IN DISTR | |400000 |294090|
|
||||
|8 | EXCHANGE OUT DISTR (HASH)|:EX10001|400000 |256226|
|
||||
|9 | PX PARTITION ITERATOR | |400000 |256226|
|
||||
|10| TABLE SCAN |t2 |400000 |256226|
|
||||
============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil)
|
||||
1 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil), dop=2
|
||||
2 - output([t4.v1], [t4.v2], [t2.v1], [t2.v2]), filter(nil),
|
||||
equal_conds([t2.v2 = t4.v2]), other_conds(nil)
|
||||
3 - output([t4.v1], [t4.v2]), filter(nil)
|
||||
4 - (#keys=1, [t4.v2]), output([t4.v1], [t4.v2]), filter(nil), dop=2
|
||||
5 - output([t4.v1], [t4.v2]), filter(nil)
|
||||
6 - output([t4.v1], [t4.v2]), filter(nil),
|
||||
access([t4.v1], [t4.v2]), partitions(p[0-2])
|
||||
7 - output([t2.v1], [t2.v2]), filter(nil)
|
||||
8 - (#keys=1, [t2.v2]), output([t2.v1], [t2.v2]), filter(nil), dop=2
|
||||
9 - output([t2.v1], [t2.v2]), filter(nil)
|
||||
10 - output([t2.v1], [t2.v2]), filter(nil),
|
||||
access([t2.v1], [t2.v2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
分布式执行计划调度
|
||||
==============================
|
||||
|
||||
|
||||
|
||||
分布式执行计划的简单调度模型如下:
|
||||
|
||||
在执行计划生成的最后阶段,以 EXCHANGE 节点为界,拆分成多个子计划,每个子计划被封装成为一个 DFO,在并行度大于 1 的场景下,会一次调度两个 DFO,依次完成 DFO 树的遍历执行;在并行度等于 1 的场景下,每个 DFO 会将产生的数据存入中间结果管理器,按照后序遍历的形式完成整个 DFO 树的遍历执行。
|
||||
|
||||
单 DFO 调度
|
||||
-----------------------------
|
||||
|
||||
示例:在并行度为 1 的场景下,对于查询计划执行单 DFO 调度。
|
||||
|
||||
```sql
|
||||
======================================================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS |COST |
|
||||
--------------------------------------------------------------------------------------
|
||||
|0 |LIMIT | |10 |6956829987|
|
||||
|1 | PX COORDINATOR MERGE SORT | |10 |6956829985|
|
||||
|2 | EXCHANGE OUT DISTR |:EX10002 |10 |6956829976|
|
||||
|3 | LIMIT | |10 |6956829976|
|
||||
|4 | TOP-N SORT | |10 |6956829975|
|
||||
|5 | HASH GROUP BY | |454381562 |5815592885|
|
||||
|6 | HASH JOIN | |500918979 |5299414557|
|
||||
|7 | EXCHANGE IN DISTR | |225943610 |2081426759|
|
||||
|8 | EXCHANGE OUT DISTR (PKEY) |:EX10001 |225943610 |1958446695|
|
||||
|9 | MATERIAL | |225943610 |1958446695|
|
||||
|10| HASH JOIN | |225943610 |1480989849|
|
||||
|11| JOIN FILTER CREATE | |30142669 |122441311 |
|
||||
|12| PX PARTITION ITERATOR | |30142669 |122441311 |
|
||||
|13| TABLE SCAN |CUSTOMER |30142669 |122441311 |
|
||||
|14| EXCHANGE IN DISTR | |731011898 |900388059 |
|
||||
|15| EXCHANGE OUT DISTR (PKEY)|:EX10000 |731011898 |614947815 |
|
||||
|16| JOIN FILTER USE | |731011898 |614947815 |
|
||||
|17| PX BLOCK ITERATOR | |731011898 |614947815 |
|
||||
|18| TABLE SCAN |ORDERS |731011898 |614947815 |
|
||||
|19| PX PARTITION ITERATOR | |3243094528|1040696710|
|
||||
|20| TABLE SCAN |LINEITEM(I_L_Q06_001)|3243094528|1040696710|
|
||||
======================================================================================
|
||||
```
|
||||
|
||||
|
||||
|
||||
如下图所示,DFO 树除 ROOT DFO 外,在垂直方向上被分别划分为 0、1、2 号 DFO, 从而后序遍历调度的顺序为 0-\>1-\>2,即可完成整个计划树的迭代。
|
||||
|
||||
|
||||
|
||||
两 DFO 调度
|
||||
-----------------------------
|
||||
|
||||
示例:对于并行度大于 1 的计划, 对于查询计划执行两 DFO 调度。
|
||||
|
||||
```javascript
|
||||
Query Plan
|
||||
=============================================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-----------------------------------------------------------------------------
|
||||
|0 |PX COORDINATOR MERGE SORT | |9873917 |692436562|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10002|9873917 |689632565|
|
||||
|2 | SORT | |9873917 |689632565|
|
||||
|3 | SUBPLAN SCAN |VIEW5 |9873917 |636493382|
|
||||
|4 | WINDOW FUNCTION | |29621749 |629924873|
|
||||
|5 | HASH GROUP BY | |29621749 |624266752|
|
||||
|6 | HASH JOIN | |31521003 |591048941|
|
||||
|7 | JOIN FILTER CREATE | |407573 |7476793 |
|
||||
|8 | EXCHANGE IN DISTR | |407573 |7476793 |
|
||||
|9 | EXCHANGE OUT DISTR (BROADCAST) |:EX10001|407573 |7303180 |
|
||||
|10| HASH JOIN | |407573 |7303180 |
|
||||
|11| JOIN FILTER CREATE | |1 |53 |
|
||||
|12| EXCHANGE IN DISTR | |1 |53 |
|
||||
|13| EXCHANGE OUT DISTR (BROADCAST)|:EX10000|1 |53 |
|
||||
|14| PX BLOCK ITERATOR | |1 |53 |
|
||||
|15| TABLE SCAN |NATION |1 |53 |
|
||||
|16| JOIN FILTER USE | |10189312 |3417602 |
|
||||
|17| PX BLOCK ITERATOR | |10189312 |3417602 |
|
||||
|18| TABLE SCAN |SUPPLIER|10189312 |3417602 |
|
||||
|19| JOIN FILTER USE | |803481600|276540086|
|
||||
|20| PX PARTITION ITERATOR | |803481600|276540086|
|
||||
|21| TABLE SCAN |PARTSUPP|803481600|276540086|
|
||||
=============================================================================
|
||||
```
|
||||
|
||||
|
||||
|
||||
如下图所示,DFO 树除 ROOT DFO 外,被划分为 3 个 DFO,调度时会先调 0 和 1 对应的 DFO,待 0 号 DFO 执行完毕后,会再调度 1 号和 2 号 DFO,依次迭代完成执行。
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,238 @@
|
||||
分布式执行计划管理
|
||||
==============================
|
||||
|
||||
分布式执行计划可以使用 HINT 管理,以提高 SQL 查询性能。
|
||||
|
||||
分布式执行框架支持的 HINT 包括 ORDERED、LEADING、USE_NL、USE_HASH 和 USE_MERGE 等。
|
||||
|
||||
NO_USE_PX
|
||||
------------------------------
|
||||
|
||||
如果某个 query 确定不希望走并行执行框架,使用 NO_USE_PX 拉回数据并生成本地执行计划。
|
||||
|
||||
PARALLEL
|
||||
-----------------------------
|
||||
|
||||
指定分布式执行的并行度。启用 3 个 worker 并行执行扫描,如下例所示:
|
||||
|
||||
```sql
|
||||
obclient>SELECT /*+ PARALLEL(3) */ MAX(L_QUANTITY) FROM table_name;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
在复杂查询中,调度器可以调度 2 个 DFO 并行流水执行,此时,启用的 worker 数量为并行度的2倍,即 PARALLEL \* 2。
|
||||
|
||||
ORDERED
|
||||
----------------------------
|
||||
|
||||
ORDERED HINT 指定并行查询计划中 JOIN 的顺序,严格按照 FROM 语句中的顺序生成。
|
||||
|
||||
如下例所示,强制要求 CUSTOMER 为左表,ORDERS 为右表,并且使用 NESTED LOOP JOIN:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE lineitem(
|
||||
l_orderkey NUMBER(20) NOT NULL ,
|
||||
|
||||
l_linenumber NUMBER(20) NOT NULL ,
|
||||
l_quantity NUMBER(20) NOT NULL ,
|
||||
l_extendedprice DECIMAL(10,2) NOT NULL ,
|
||||
l_discount DECIMAL(10,2) NOT NULL ,
|
||||
l_tax DECIMAL(10,2) NOT NULL ,
|
||||
|
||||
l_shipdate DATE NOT NULL,
|
||||
|
||||
PRIMARY KEY(L_ORDERKEY, L_LINENUMBER));
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient>CREATE TABLE customer(
|
||||
c_custkey NUMBER(20) NOT NULL ,
|
||||
c_name VARCHAR(25) DEFAULT NULL,
|
||||
c_address VARCHAR(40) DEFAULT NULL,
|
||||
c_nationkey NUMBER(20) DEFAULT NULL,
|
||||
c_phone CHAR(15) DEFAULT NULL,
|
||||
c_acctbal DECIMAL(10,2) DEFAULT NULL,
|
||||
c_mktsegment CHAR(10) DEFAULT NULL,
|
||||
c_comment VARCHAR(117) DEFAULT NULL,
|
||||
PRIMARY KEY(c_custkey));
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient>CREATE TABLE orders(
|
||||
o_orderkey NUMBER(20) NOT NULL ,
|
||||
o_custkey NUMBER(20) NOT NULL ,
|
||||
o_orderstatus CHAR(1) DEFAULT NULL,
|
||||
o_totalprice DECIMAL(10,2) DEFAULT NULL,
|
||||
o_orderdate DATE NOT NULL,
|
||||
o_orderpriority CHAR(15) DEFAULT NULL,
|
||||
o_clerk CHAR(15) DEFAULT NULL,
|
||||
o_shippriority NUMBER(20) DEFAULT NULL,
|
||||
o_comment VARCHAR(79) DEFAULT NULL,
|
||||
PRIMARY KEY(o_orderkey,o_orderdate,o_custkey));
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO lineitem VALUES(1,2,3,6.00,0.20,0.01,'01-JUN-02');
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient> INSERT INTO customer VALUES(1,'Leo',null,null,'13700461258',null,'BUILDING',null);
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient> INSERT INTO orders VALUES(1,1,null,null,'01-JUN-20',10,null,8,null);
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient>SELECT /*+ ORDERED USE_NL(orders) */o_orderdate, o_shippriority
|
||||
FROM customer, orders WHERE c_mktsegment = 'BUILDING' AND
|
||||
c_custkey = o_custkey GROUP BY o_orderdate, o_shippriority;
|
||||
|
||||
+-------------+----------------+
|
||||
| O_ORDERDATE | O_SHIPPRIORITY |
|
||||
+-------------+----------------+
|
||||
| 01-JUN-20 | 8 |
|
||||
+-------------+----------------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
在手写 SQL 时,ORDERED 较为有用,用户知道 JOIN 的最佳顺序时,可以将表按照顺序写在 FROM 的后面,然后加上 ORDERED HINT。
|
||||
|
||||
LEADING
|
||||
----------------------------
|
||||
|
||||
LEADING HINT 指定并行查询计划中最先 JOIN 哪些表,LEADING 中的表从左到右的顺序,也是 JOIN 的顺序。它比 ORDERED 有更大的灵活性。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
如果 ORDERED 和 LEADING 同时使用,仅 ORDERED 生效。
|
||||
|
||||
PQ_DISTRIBUTE
|
||||
----------------------------------
|
||||
|
||||
PQ HINT 即 `PQ_DISTRIBUTE`,用于指定并行查询计划中的数据分布方式。PQ HINT 会改变分布式 JOIN 时的数据分发方式。
|
||||
|
||||
PQ HINT 的基本语法如下:
|
||||
|
||||
```unknow
|
||||
PQ_DISTRIBUTE(tablespec outer_distribution inner_distribution)
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数解释如下:
|
||||
|
||||
* tablespec 指定关注的表,关注 JOIN 的右表。
|
||||
|
||||
|
||||
|
||||
* outer_distribution 指定左表的数据分发方式。
|
||||
|
||||
|
||||
|
||||
* inner_distribution 指定右表的数据分发方式。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
两表的数据分发方式共有以下六种:
|
||||
|
||||
* HASH, HASH
|
||||
|
||||
|
||||
|
||||
* BROADCAST, NONE
|
||||
|
||||
|
||||
|
||||
*
|
||||
NONE, BROADCAST
|
||||
|
||||
|
||||
|
||||
* PARTITION, NONE
|
||||
|
||||
|
||||
|
||||
*
|
||||
NONE, PARTITION
|
||||
|
||||
|
||||
|
||||
*
|
||||
NONE, NONE
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
其中,带分区的两种分发方式要求左表或右表有分区,而且分区键就是 JOIN 的键。如果不满足要求的话,PQ HINT 不会生效。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT, c3 INT, c4 DATE);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE INDEX i1 ON t1(c3);
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT(11) NOT NULL, c2 INT(11) NOT NULL, c3 INT(11)
|
||||
NOT NULL,
|
||||
PRIMARY KEY (c1, c2, c3)) PARTITION BY KEY(c2) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>EXPLAIN BASIC SELECT /*+USE_PX PARALLEL(3) PQ_DISTRIBUTE
|
||||
(t2 BROADCAST NONE) LEADING(t1 t2)*/ * FROM t1 JOIN t2 ON
|
||||
t1.c2 = t2.c2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
================================================
|
||||
|ID|OPERATOR |NAME |
|
||||
------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|
|
||||
|2 | HASH JOIN | |
|
||||
|3 | EXCHANGE IN DISTR | |
|
||||
|4 | EXCHANGE OUT DISTR (BROADCAST)|:EX10000|
|
||||
|5 | PX BLOCK ITERATOR | |
|
||||
|6 | TABLE SCAN |t1 |
|
||||
|7 | PX BLOCK ITERATOR | |
|
||||
|8 | TABLE SCAN |t2 |
|
||||
================================================
|
||||
```
|
||||
|
||||
|
||||
|
||||
USE_NL
|
||||
---------------------------
|
||||
|
||||
USE_NL HINT 指定 JOIN 使用 NESTED LOOP JOIN,并且需要满足 USE_NL 中指定的表是 JOIN 的右表。
|
||||
|
||||
如下例所示,如果希望 join1 为 NESTED LOOP JOIN,则 HINT 写法为 `LEADING(a, (b,c)) USE_NL((b,c))`。
|
||||
|
||||
当 USE_NLJ 和 ORDERED、LEADING HINT 一起使用时,如果 USE_NLJ 中注明的表不是右表,则 USE_NLJ HINT 会被忽略。
|
||||
|
||||
|
||||
|
||||
USE_HASH
|
||||
-----------------------------
|
||||
|
||||
USE_HASH HINT 指定 JOIN 使用 HASH JOIN,并且需要满足 USE_HASH 中指定的表是 JOIN 的右表。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
如果没有使用 ORDERED 和 LEADING HINT,并且优化器生成的 JOIN 顺序中指定的表之间不是直接 JOIN 的关系,那么 USE_HASH HINT 会被忽略。
|
||||
|
||||
USE_MERGE
|
||||
------------------------------
|
||||
|
||||
USE_MERGE HINT 指定 JOIN 使用 MERGE JOIN,并且需要满足 USE_MERGE 中指定的表是 JOIN 的右表。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
如果没有使用 ORDERED 和 LEADING HINT,并且优化器生成的 JOIN 顺序中指定的表之间不是直接 JOIN 的关系,那么 USE_MERGE HINT 会被忽略。
|
||||
@ -0,0 +1,334 @@
|
||||
并行查询的执行
|
||||
============================
|
||||
|
||||
并行执行(Parallel Execution)是将一个较大的任务切分为多个较小的任务,启动多个线程或者进程来并行处理这些小任务,这样可以利用更多的 CPU 与 IO 资源来缩短操作的响应时间。
|
||||
|
||||
并行执行分为并行查询(Parallel Query)、并行 DDL(Parallel DDL)和并行 DML(Parallel DML)。目前 OceanBase 数据库仅支持并行查询,并行 DDL 与并行 DML 还未支持。
|
||||
|
||||
启动并行查询的方式有以下两种:
|
||||
|
||||
* 通过 PARALLEL HINT 指定并行度(dop)的方式启动并行查询。
|
||||
|
||||
|
||||
|
||||
* 针对查询分区数大于 1 的分区表会自动启动并行查询。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
启用分区表并行查询
|
||||
------------------------------
|
||||
|
||||
针对分区表的查询,如果查询的目标分区数大于 1,系统会自动启用并行查询,dop 的值由系统默认指定为 1。
|
||||
|
||||
如下例所示,创建一个分区表 ptable,对 ptable 进行全表数据的扫描操作,通过 EXPLAIN 命令查看生成的执行计划。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE PTABLE(c1 INT , c2 INT) PARTITION BY HASH(c1) PARTITIONS 16;
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM ptable\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=======================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |1600000 |1246946|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|1600000 |1095490|
|
||||
|2 | PX PARTITION ITERATOR| |1600000 |1095490|
|
||||
|3 | TABLE SCAN |ptable |1600000 |1095490|
|
||||
=======================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
1 - output([ptable.c1], [ptable.c2]), filter(nil), dop=1
|
||||
2 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
3 - output([ptable.c1], [ptable.c2]), filter(nil),
|
||||
access([ptable.c1], [ptable.c2]), partitions(p[0-15])
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过执行计划可以看出,分区表默认的并行查询的 dop 为 1。如果 OceanBase 集群一共有 3 个 OBServer,表 ptable 的 16 个分区分散在 3 个 OBServer 中,那么每一个 OBServer 都会启动一个工作线程(Worker Thread)来执行分区数据的扫描工作,一共需要启动 3 个工作线程来执行表的扫描工作。
|
||||
|
||||
针对分区表,添加 PARALLEL HINT 启动并行查询,并指定 dop,通过 EXPLAIN 命令查看生成的执行计划。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT /*+ PARALLEL(8) */ * FROM ptable\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=======================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |1600000 |1246946|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|1600000 |1095490|
|
||||
|2 | PX PARTITION ITERATOR| |1600000 |1095490|
|
||||
|3 | TABLE SCAN |ptable |1600000 |1095490|
|
||||
=======================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
1 - output([ptable.c1], [ptable.c2]), filter(nil), dop=8
|
||||
2 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
3 - output([ptable.c1], [ptable.c2]), filter(nil),
|
||||
access([ptable.c1], [ptable.c2]), partitions(p[0-15])
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过执行计划可以看出,并行查询的 dop 为 8。如果查询分区所在的 OBServer 的个数小于等于 dop,那么工作线程(总个数等于 dop)会按照一定的策略分配到涉及的 OBServer 上;如果查询分区所在的 OBServer 的个数大于 dop,那么每一个 OBServer 都会至少启动一个工作线程,一共需要启动的工作线程的数目会大于 dop。
|
||||
|
||||
例如,当 `dop=8`,如果 16 个分区均匀的分布在 4 台 OBServer 节点上,那么每一个 OBServer 上都会启动 2 个工作线程来扫描其对应的分区(一共启动 8 个工作线程);如果 16 个分区分布在 16 台 OBServer 节点上(每一个节点一个分区),那么每一台 OBServer 上都会启动 1 个工作线程来扫描其对应的分区(一共启动 16 个工作线程)。
|
||||
|
||||
如果针对分区表的查询,查询分区数目小于等于 1,系统不会启动并行查询。如下例所示,对 ptable 的查询添加一个过滤条件 `c1=1`。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT * FROM ptable WHERE c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |TABLE SCAN|ptable|990 |85222|
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([ptable.c1], [ptable.c2]), filter([ptable.c1 = 1]),
|
||||
access([ptable.c1], [ptable.c2]), partitions(p1)
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过计划可以看出,查询的目标分区个数为 1,系统没有启动并行查询。如果希望针对一个分区的查询也能够进行并行执行,就只能通过添加 PARALLEL HINT 的方式进行分区内并行查询,通过 EXPLAIN 命令查看生成的执行计划。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT /*+ PARALLEL(8) */ * FROM ptable WHERE c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |990 |85316|
|
||||
|1 | EXCHANGE OUT DISTR|:EX10000|990 |85222|
|
||||
|2 | PX BLOCK ITERATOR| |990 |85222|
|
||||
|3 | TABLE SCAN |ptable |990 |85222|
|
||||
=================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
1 - output([ptable.c1], [ptable.c2]), filter(nil), dop=8
|
||||
2 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
3 - output([ptable.c1], [ptable.c2]), filter([ptable.c1 = 1]),
|
||||
access([ptable.c1], [ptable.c2]), partitions(p1)
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
* 如果希望在查询分区数等于 1 的情况下,能够采用 HINT 的方式进行分区内并行查询,需要对应的 dop 的值大于等于 2。
|
||||
|
||||
|
||||
|
||||
* 如果 dop 的值为空或者小于 2 将不启动并行查询。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
启用非分区表并行查询
|
||||
-------------------------------
|
||||
|
||||
非分区表本质上是只有 1 个分区的分区表,因此针对非分区表的查询,只能通过添加 PARALLEL HINT 的方式启动分区内并行查询,否则不会启动并行查询。
|
||||
|
||||
如下例所示,创建一个非分区表 stable,对 stable 进行全表数据的扫描操作,通过 EXPLAIN 命令查看生成的执行计划。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE stable(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM stable\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
======================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |TABLE SCAN|stable|100000 |68478|
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([stable.c1], [stable.c2]), filter(nil),
|
||||
access([stable.c1], [stable.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过执行计划可以看出,非分区表不使用 HINT 的情况下,不会启动并行查询。
|
||||
|
||||
针对非分区表,添加 PARALLEL HINT 启动分区内并行查询,并指定 dop(大于等于 2),通过 EXPLAIN 命令查看生成的执行计划。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT /*+ PARALLEL(4)*/ * FROM stable\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |100000 |77944|
|
||||
|1 | EXCHANGE OUT DISTR|:EX10000|100000 |68478|
|
||||
|2 | PX BLOCK ITERATOR| |100000 |68478|
|
||||
|3 | TABLE SCAN |stable |100000 |68478|
|
||||
=================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([stable.c1], [stable.c2]), filter(nil)
|
||||
1 - output([stable.c1], [stable.c2]), filter(nil), dop=4
|
||||
2 - output([stable.c1], [stable.c2]), filter(nil)
|
||||
3 - output([stable.c1], [stable.c2]), filter(nil),
|
||||
access([stable.c1], [stable.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
启用多表并行查询
|
||||
-----------------------------
|
||||
|
||||
在查询中,多表 JOIN 查询最为常见。
|
||||
|
||||
如下例所示,首先创建两张分区表 p1table 和 p2table:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE p1table(c1 INT ,c2 INT) PARTITION BY HASH(c1) PARTITIONS 2;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
|
||||
obclient>CREATE TABLE p2table(c1 INT ,c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
查询 p1table 与 p2table 的 JOIN 结果,JOIN 条件是 `p1table.c1=p2table.c2`,执行计划如下:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT * FROM p1table p1 JOIN p2table p2 ON p1.c1=p2.c2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |784080000|614282633|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|784080000|465840503|
|
||||
|2 | HASH JOIN | |784080000|465840503|
|
||||
|3 | EXCHANGE IN DISTR | |200000 |155887 |
|
||||
|4 | EXCHANGE OUT DISTR (BROADCAST)|:EX10000|200000 |136955 |
|
||||
|5 | PX PARTITION ITERATOR | |200000 |136955 |
|
||||
|6 | TABLE SCAN |p1 |200000 |136955 |
|
||||
|7 | PX PARTITION ITERATOR | |400000 |273873 |
|
||||
|8 | TABLE SCAN |p2 |400000 |273873 |
|
||||
====================================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([p1.c1], [p1.c2], [p2.c1], [p2.c2]), filter(nil)
|
||||
1 - output([p1.c1], [p1.c2], [p2.c1], [p2.c2]), filter(nil), dop=1
|
||||
2 - output([p1.c1], [p1.c2], [p2.c1], [p2.c2]), filter(nil),
|
||||
equal_conds([p1.c1 = p2.c2]), other_conds(nil)
|
||||
3 - output([p1.c1], [p1.c2]), filter(nil)
|
||||
4 - output([p1.c1], [p1.c2]), filter(nil), dop=1
|
||||
5 - output([p1.c1], [p1.c2]), filter(nil)
|
||||
6 - output([p1.c1], [p1.c2]), filter(nil),
|
||||
access([p1.c1], [p1.c2]), partitions(p[0-1])
|
||||
7 - output([p2.c1], [p2.c2]), filter(nil)
|
||||
8 - output([p2.c1], [p2.c2]), filter(nil),
|
||||
access([p2.c1], [p2.c2]), partitions(p[0-3])
|
||||
```
|
||||
|
||||
|
||||
|
||||
默认情况下针对 p1table 与 p2table(两张表需要查询的分区数都大于 1)都会采用并行查询,默认的 dop 为 1。同样,也可以通过使用 PARALLEL HINT 的方式来改变并行度。
|
||||
|
||||
如下例所示,改变 JOIN 的条件为 `p1table.c1=p2table.c2` 和 `p2table.c1=1`,这样针对 p2table 仅仅会选择单个分区,执行计划如下所示:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT * FROM p1table p1 JOIN p2table p2 ON p1.c1=p2.c2 AND p2.c1=1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |1940598 |1807515|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10001|1940598 |1440121|
|
||||
|2 | HASH JOIN | |1940598 |1440121|
|
||||
|3 | EXCHANGE IN DISTR | |990 |85316 |
|
||||
|4 | EXCHANGE OUT DISTR (PKEY)|:EX10000|990 |85222 |
|
||||
|5 | TABLE SCAN |p2 |990 |85222 |
|
||||
|6 | PX PARTITION ITERATOR | |200000 |136955 |
|
||||
|7 | TABLE SCAN |p1 |200000 |136955 |
|
||||
=============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([p1.c1], [p1.c2], [p2.c1], [p2.c2]), filter(nil)
|
||||
1 - output([p1.c1], [p1.c2], [p2.c1], [p2.c2]), filter(nil), dop=1
|
||||
2 - output([p1.c1], [p1.c2], [p2.c1], [p2.c2]), filter(nil),
|
||||
equal_conds([p1.c1 = p2.c2]), other_conds(nil)
|
||||
3 - output([p2.c1], [p2.c2]), filter(nil)
|
||||
4 - (#keys=1, [p2.c2]), output([p2.c1], [p2.c2]), filter(nil), dop=1
|
||||
5 - output([p2.c1], [p2.c2]), filter([p2.c1 = 1]),
|
||||
access([p2.c1], [p2.c2]), partitions(p1)
|
||||
6 - output([p1.c1], [p1.c2]), filter(nil)
|
||||
7 - output([p1.c1], [p1.c2]), filter(nil),
|
||||
access([p1.c1], [p1.c2]), partitions(p[0-1])
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过计划可以看出,p2table 仅需要扫描一个分区,在默认情况下不进行并行查询;p1table 需要扫描两个分区,默认情况下进行并行查询。同样,也可以通过添加 PARALLEL HINT 的方式改变并行度,使 p2table 针对一个分区的查询变为分区内并行查询。
|
||||
|
||||
关闭并行查询
|
||||
---------------------------
|
||||
|
||||
分区表在查询的时候会自动启动并行查询(查询分区个数大于 1),如果不想启动并行查询,可以使用添加 HINT `/*+ NO_USE_PX */` 来关闭并行查询。
|
||||
|
||||
例如,针对分区表 ptable,添加 HINT `/*+ NO_USE_PX */` 来关闭并行查询,通过生成的执行计划可以看出对 ptable 表的扫描没有进行并行查询。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT /*+ NO_USE_PX */ * FROM ptable\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |1600000 |1246946|
|
||||
|1 | EXCHANGE OUT DISTR| |1600000 |1095490|
|
||||
|2 | TABLE SCAN |ptable|1600000 |1095490|
|
||||
=================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
1 - output([ptable.c1], [ptable.c2]), filter(nil)
|
||||
2 - output([ptable.c1], [ptable.c2]), filter(nil),
|
||||
access([ptable.c1], [ptable.c2]), partitions(p[0-15])
|
||||
```
|
||||
|
||||
|
||||
|
||||
并行执行相关的系统视图
|
||||
--------------------------------
|
||||
|
||||
OceanBase 数据库提供了系统视图 `gv$sql_audit/v$sql_audit` 来查看并行执行的运行状态以及一些统计信息。
|
||||
|
||||
`gv$sql_audit/v$sql_audit` 包含字段较多,其中与并行执行相关的字段为:qc_id、dfo_id、sqc_id 和 worker_id。
|
||||
|
||||
详细信息请参考 [(g)v$sql_audit 介绍](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/1.g-v-sql_audit-introduction.md)。
|
||||
@ -0,0 +1,69 @@
|
||||
并行查询的参数调优
|
||||
==============================
|
||||
|
||||
Oceanbase 数据库并行查询(PX)的参数决定了并行查询的速度,主要包括并行度和 EXCHANGE 相关参数 。
|
||||
|
||||
并行度参数
|
||||
--------------------------
|
||||
|
||||
并行度相关参数主要决定每个 query 并发时的 worker 个数。
|
||||
|
||||
|
||||
| **参数名称** | **描述** | **取值范围** | **默认值** | **配置建议** |
|
||||
|-------------------------|------------------------------------------------------------------------------------------|-------------|------------------------------|---------------------------------------------------------------------------|
|
||||
| parallel_max_servers | 控制每个服务器最大的并行执行线程个数,所有PX worker 加起来不能超过该值。 | \[0, 1800\] | 10(目前会根据 CPU 个数计算得到,以实际大小为准) | 该参数主要是控制 PX 场景下所有 PX worker 总数,建议值为可用 CPU个数的倍数关系。 |
|
||||
| parallel_servers_target | 当 query 准备排队之前,控制检查 query 要求的并行度和已统计的 worker 总和是否超过该值。如果超过该值,则 query 需要排队,否则 query 继续执行。 | \[0, 1800\] | 10(目前会根据 CPU 个数计算得到,以实际大小为准) | 该参数主要是控制 PX 场景下,当 query 准备进行并行查询时,如果没有足够 worker 处理该 query,决定是否继续进行还是排队等待。 |
|
||||
|
||||
|
||||
|
||||
`parallel_max_servers` 参数用于控制最大的并发度,`parallel_servers_target` 参数用来决策 query 在并行查询时是否排队,两者需要协同工作。如果只使用 `parallel_max_servers` 设置最大并行度,当查询过多时,会导致所有 worker 都被调度起来,导致 CPU 等资源紧张,查询性能下降。在 CPU 等资源有限的情况下,使用 `parallel_servers_target` 控制 query 进行排队可以提高整个并发的吞吐量。
|
||||
|
||||
可以通过 `SHOW VARIABLES` 来查看这些参数的值,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SHOW VARIABLES LIKE '%paral%';
|
||||
|
||||
+-------------------------+-------+
|
||||
| Variable_name | Value |
|
||||
+-------------------------+-------+
|
||||
| ob_max_parallel_degree | 32 |
|
||||
| ob_stmt_parallel_degree | 1 |
|
||||
| parallel_max_servers | 5 |
|
||||
| parallel_servers_target | 4 |
|
||||
+-------------------------+-------+
|
||||
4 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
`ob_stmt_parallel_degree` 参数不需要设置,对 PX 框架无效。
|
||||
|
||||
EXCHANGE(Shuffle)参数
|
||||
----------------------------------------
|
||||
|
||||
EXCHANGE(Shuffle)参数主要用来控制在每个 DFO 之间进行数据传输时的参数控制,也就是数据进行 shuffle 时的内存控制。Oceanbase 数据库将数据传输封装成了叫做 DTL(Data Transfer layer)的模块。
|
||||
|
||||
|
||||
| **参数名称** | **描述** | **取值范围** | **默认值** | **配置建议** |
|
||||
|-----------------|----------------------------------------------------------------------------------------------|-------------|------------------------------|-------------------------------------------------------------------------------|
|
||||
| dtl_buffer_size | 控制 EXCHANGE 算子之间(即transmit 和 receive 之间)发送数据时,每次发送数据的 buffer 的大小。即当数据达到了该值上限才进行发送,减少每行传输的代价。 | \[0, 1800\] | 10(目前会根据 CPU 个数计算得到,以实际大小为准) | PX 场景下,EXCHANGE 之间发送数据依赖于该参数大小,一般不需要调整该参数,如果是为了减少发送数据次数等可以尝试进行修改,一般不建议修改该值大小。 |
|
||||
|
||||
|
||||
|
||||
可以通过 `SHOW PARAMETERS` 来查看参数的值,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SHOW PARAMETERS LIKE '%dtl%';
|
||||
|
||||
+-------+----------+----------------+----------+-----------------+-----------+-------+---------------+----------+---------+---------+-------------------+
|
||||
| zone | svr_type | svr_ip | svr_port | name | data_type | value | info | section | scope | source | edit_level |
|
||||
+-------+----------+----------------+----------+-----------------+-----------+-------+---------------+----------+---------+---------+-------------------+
|
||||
| zone1 | observer | 100.81.152.114 | 36500 | dtl_buffer_size | NULL | 64K | to be removed | OBSERVER | CLUSTER | DEFAULT | DYNAMIC_EFFECTIVE |
|
||||
+-------+----------+----------------+----------+-----------------+-----------+-------+---------------+----------+---------+---------+-------------------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,37 @@
|
||||
SQL 调优概览
|
||||
=============================
|
||||
|
||||
SQL 调优是指通过综合分析 SQL 的执行计划、执行监控信息、系统配置、系统负载等多方面因素,调整 SQL 的执行策略,以实现资源利用最大化。
|
||||
|
||||
SQL 调优方式一般可分为单条 SQL 调优和系统 SQL 调优。
|
||||
|
||||
单条 SQL 调优
|
||||
------------------------------
|
||||
|
||||
单一的 SQL 调优的优化主体是被调试的 SQL 执行本身,一般调优的目标包括该 SQL 的执行时间、试行期的资源消耗等。常见的调优手段包括调整访问路径、执行顺序、逻辑改写等。
|
||||
|
||||
针对单条 SQL 的执行计划性能调优又可以分为单表访问和多表访问两种场景。
|
||||
|
||||
|
||||
| **场景** | **SQL 调优的关注点** |
|
||||
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| 单表访问 | * 访问路径是否开启索引扫描:使用索引扫描可以减小数据的访问量。 * 是否创建合适的索引:使用索引排序以减少排序或聚合等耗时操作。 * 分区裁剪是否正确:适当的分区条件可以减少不必要的分区访问。 * 是否提高查询的并行度:分区数目较多时,通过提高并行度以更多资源的代价获取单条 SQL 查询的性能提升。 |
|
||||
| 多表访问 | 不仅要关注单表的 SQL 调优问题,还要关注多表间的联接问题: * 联接顺序 * 联接算法 * 跨机或并行联接的数据再分布方式 * 查询改写 |
|
||||
|
||||
|
||||
|
||||
系统的 SQL 调优
|
||||
-------------------------------
|
||||
|
||||
系统的 SQL 调优的目的是提高整个系统的吞吐量或者系统利用率等。系统的 SQL 调优过程往往需要结合多条 SQL 的执行计划,综合分析当前系统的负载特征,主要关注热点行竞争、buffer cache 命中率等全局性的调优点。
|
||||
|
||||
针对吞吐量的性能调优主要是考虑在一定资源(CPU、IO、网络等)情况下,将数据库系统处理请求量最大化。主要关注以下几个方面:
|
||||
|
||||
|
||||
| **主要方法** | **说明** |
|
||||
|-------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| 优化慢 SQL | 找到具体的慢 SQL 后,针对单条 SQL 进行性能调优,请参见示例 [查询某段时间内执行时间排名 TOP N 的请求](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/8.query-the-top-n-requests-with-the-most-execution-time-1.md)。 |
|
||||
| 均衡 SQL 的请求流量资源 | 请参见示例 [查看集群 SQL 请求流量是否均衡](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/6.check-whether-the-sql-request-traffic-is-balanced-1.md)。 影响均衡的因素主要有: * `ob_read_consistency` 如何设置 * Primary Zone 如何设置 * Proxy 或 Java 客户端路由策略相关设置 * 业务热点查询分区是否均衡 |
|
||||
| 均衡子计划的 RPC 请求流量资源 | 请参见示例 [查看分布式子计划 RPC 执行数是否均衡](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/12.check-whether-the-number-of-distributed-rpc-executions-is-balanced-1.md)。 影响子计划请求是否均匀的主要因素如下: * OBServer 内部路由策略相关设置 * 业务热点查询的分区是否均衡 |
|
||||
|
||||
|
||||
@ -0,0 +1,27 @@
|
||||
SQL 调优基本流程
|
||||
===============================
|
||||
|
||||
|
||||
|
||||
在 SQL 调优中,针对慢 SQL 的分析步骤如下:
|
||||
|
||||
1. 通过全局 SQL 审计表 (g)v$sql_audit、 SQL Trace 和计划缓存视图查看 SQL 执行信息,初步查找 SQL 请求的流程中导致耗时或消耗资源(如内存、磁盘 IO 等)的 SQL。请参见示例 [查询某段时间内执行时间排名 TOP N 的请求](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/8.query-the-top-n-requests-with-the-most-execution-time-1.md)。
|
||||
|
||||
|
||||
|
||||
2. 单条 SQL 的执行性能往往与该 SQL 的执行计划相关,因此,执行计划的分析是最重要的手段。通过执行 EXPALIN 命令查看优化器针对给定 SQL 生成的逻辑执行计划,确定可能的调优方向。请参见示例 [查看执行计划形状并做分析](../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/3.view-and-analyze-the-execution-plan-1.md)。
|
||||
|
||||
关于执行计划的详细信息请参考 [SQL 执行计划简介](../../12.sql-optimization-guide-1/2.sql-execution-plan-3/1.introduction-to-sql-execution-plans-2.md)。
|
||||
|
||||
|
||||
3. 找到具体的慢 SQL,为了使某些 SQL 的执行时间或资源消耗符合预期,常见的优化方式如下:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,160 @@
|
||||
(g)v$sql_audit 介绍
|
||||
======================================
|
||||
|
||||
(g)v$sql_audit 是全局 SQL 审计表,可以用来查看每次请求客户端来源、执行服务器信息、执行状态信息、等待事件以及执行各阶段耗时等。
|
||||
|
||||
sql_audit 相关设置
|
||||
-----------------------
|
||||
|
||||
* 设置 sql_audit 使用开关。
|
||||
|
||||
```javascript
|
||||
obclient>ALTER SYSTEM SET enable_sql_audit = true;
|
||||
/*开启 sql_audit*/
|
||||
|
||||
obclient>ALTER SYSTEM SET enable_sql_audit = false;
|
||||
/*关闭 sql_audit*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 设置 sql_audit 内存上限。默认内存上限为 3 G,可设置范围为 \[64M,+∞\]。
|
||||
|
||||
```javascript
|
||||
obclient>ALTER SYSTEM SET sql_audit_memory_limit = '3G';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
sql_audit 淘汰机制
|
||||
-----------------------
|
||||
|
||||
* sql_audit 每隔 1s 会检测后台任务并根据以下标准决定是否淘汰:
|
||||
|
||||
* sql_audit 内存最大可使用上限为 `avail_mem_limit = min (OBServer 可使用内存 *10%`,`sql_audit_memory_limit)`。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 当 sql_audidt 记录数超过 900 万条时,触发淘汰。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* sql_audit 根据以下标准决定是否停止淘汰:
|
||||
|
||||
* 如果是达到内存上限触发淘汰则:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 如果是达到记录数上限触发的淘汰则淘汰到 800 万行记录时停止淘汰。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
sql_audit 字段解释
|
||||
-----------------------
|
||||
|
||||
|
||||
|
||||
| **字段名称** | **类型** | **描述** |
|
||||
|-------------------------|---------------------|----------------------------------|
|
||||
| SVR_IP | varchar(32) | IP 地址 |
|
||||
| SVR_PORT | bigint(20) | 端口号 |
|
||||
| REQUEST_ID | bigint(20) | 请求的 ID 号 |
|
||||
| TRACE_ID | varchar(128) | 这条语句的 trace ID |
|
||||
| CLIENT_IP | varchar(32) | 发送请求的 client IP |
|
||||
| CLIENT_PORT | bigint(20) | 发送请求的 client port |
|
||||
| TENANT_ID | bigint(20) | 发送请求的租户 ID |
|
||||
| TENANT_NAME | varchar(64) | 发送请求的租户名称 |
|
||||
| USER_ID | bigint(20) | 发送请求的用户 ID |
|
||||
| USER_NAME | varchar(64) | 发送请求的用户名称 |
|
||||
| SQL_ID | varchar(32) | 这条 SQL 的 ID |
|
||||
| QUERY_SQL | varchar(32768) | 实际的 SQL 语句 |
|
||||
| PLAN_ID | bigint(20) | 执行计划 ID |
|
||||
| AFFECTED_ROWS | bigint(20) | 影响行数 |
|
||||
| RETURN_ROWS | bigint(20) | 返回行数 |
|
||||
| PARTITION_CNT | bigint(20) | 该请求涉及的分区数 |
|
||||
| RET_CODE | bigint(20) | 执行结果返回码 |
|
||||
| EVENT | varchar(64) | 最长等待事件名称 |
|
||||
| P1TEXT | varchar(64) | 等待事件参数 1 |
|
||||
| P1 | bigint(20) unsigned | 等待事件参数 1 的值 |
|
||||
| P2TEXT | varchar(64) | 等待事件参数 2 |
|
||||
| P2 | bigint(20) unsigned | 等待事件参数 2 的值 |
|
||||
| P3TEXT | varchar(64) | 等待事件参数 3 |
|
||||
| P3 | bigint(20) unsigned | 等待事件参数 3 的值 |
|
||||
| LEVEL | bigint(20) | 等待事件的 level 级别 |
|
||||
| WAIT_CLASS_ID | bigint(20) | 等待事件所属的 class ID |
|
||||
| WAIT_CLASS# | bigint(20) | 等待事件所属的 class 的下标 |
|
||||
| WAIT_CLASS | varchar(64) | 等待事件所属的 class 名称 |
|
||||
| STATE | varchar(19) | 等待事件的状态 |
|
||||
| WAIT_TIME_MICRO | bigint(20) | 该等待事件所等待的时间(微秒) |
|
||||
| TOTAL_WAIT_TIME_MICRO | bigint(20) | 执行过程所有等待的总时间(微秒) |
|
||||
| TOTAL_WAITS | bigint(20) | 执行过程总等待的次数 |
|
||||
| RPC_COUNT | bigint(20) | 发送 RPC 个数 |
|
||||
| PLAN_TYPE | bigint(20) | 执行计划类型(local/ remote/distribute) |
|
||||
| IS_INNER_SQL | tinyint(4) | 是否为内部 SQL 请求 |
|
||||
| IS_EXECUTOR_RPC | tinyint(4) | 当前请求是否为 RPC 请求 |
|
||||
| IS_HIT_PLAN | tinyint(4) | 是否命中计划缓存 |
|
||||
| REQUEST_TIME | bigint(20) | 开始执行时间点 |
|
||||
| ELAPSED_TIME | bigint(20) | 接收到请求到执行结束消耗总时间 |
|
||||
| NET_TIME | bigint(20) | 发送 RPC 到接收到请求时间 |
|
||||
| NET_WAIT_TIME | bigint(20) | 接收到请求到进入队列时间 |
|
||||
| QUEUE_TIME | bigint(20) | 请求在队列等待事件 |
|
||||
| DECODE_TIME | bigint(20) | 出队列后 decode 时间 |
|
||||
| GET_PLAN_TIME | bigint(20) | 开始执行到获得计划时间 |
|
||||
| EXECUTE_TIME | bigint(20) | plan 执行消耗时间 |
|
||||
| APPLICATION_WAIT_TIME | bigint(20) unsigned | 所有 application 类事件的总时间 |
|
||||
| CONCURRENCY_WAIT_TIME | bigint(20) unsigned | 所有 concurrency 类事件的总时间 |
|
||||
| USER_IO_WAIT_TIME | bigint(20) unsigned | 所有 user_io 类事件的总时间 |
|
||||
| SCHEDULE_TIME | bigint(20) unsigned | 所有 schedule 类事件的时间 |
|
||||
| ROW_CACHE_HIT | bigint(20) | 行缓存命中次数 |
|
||||
| BLOOM_FILTER_CACHE_HIT | bigint(20) | bloom filter 缓存命中次数 |
|
||||
| BLOCK_CACHE_HIT | bigint(20) | 块缓存命中次数 |
|
||||
| BLOCK_INDEX_CACHE_HIT | bigint(20) | 块索引缓存命中次数 |
|
||||
| DISK_READS | bigint(20) | 物理读次数 |
|
||||
| EXECUTION_ID | bigint(20) | 执行 ID |
|
||||
| SESSION_ID | bigint(20) | SESSION 的 ID |
|
||||
| RETRY_CNT | bigint(20) | 重试次数 |
|
||||
| TABLE_SCAN | tinyint(4) | 判断该请求是否含全表扫描 |
|
||||
| CONSISTENCY_LEVEL | bigint(20) | 一致性级别 |
|
||||
| MEMSTORE_READ_ROW_COUNT | bigint(20) | MEMSTORE 中读的行数 |
|
||||
| SSSTORE_READ_ROW_COUNT | bigint(20) | SSSTORE 中读的行数 |
|
||||
| REQUEST_MEMORY_USED | bigint(20) | 该请求消耗的内存 |
|
||||
|
||||
|
||||
@ -0,0 +1,151 @@
|
||||
SQL Trace
|
||||
==============================
|
||||
|
||||
SQL Trace 能够交互式的提供上一次执行的 SQL 请求执行过程信息及各阶段的耗时。
|
||||
|
||||
SQL Trace 开关
|
||||
---------------------
|
||||
|
||||
SQL Trace 功能默认是关闭的,可通过 session 变量来控制其打开和关闭。
|
||||
|
||||
* 打开 SQL Trace 功能的语句如下:
|
||||
|
||||
```unknow
|
||||
obclient>SET ob_enable_trace_log = 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 关闭 SQL Trace 功能的语句如下:
|
||||
|
||||
```unknow
|
||||
obclient>SET ob_enable_trace_log = 0;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Show Trace
|
||||
-------------------
|
||||
|
||||
当 SQL Trace 功能打开后,执行需要诊断的 SQL,然后通过 `SHOW TRACE` 能够查看该 SQL 执行的信息。这些执行信息以表格方式输出,每列说明如下:
|
||||
|
||||
|
||||
| **列名** | **说明** |
|
||||
|----------|------------------------|
|
||||
| Title | 记录执行过程某一个阶段点 |
|
||||
| KeyValue | 记录某一个阶段点产生的一些执行信息 |
|
||||
| Time | 记录上一个阶段点到这次阶段点执行耗时(us) |
|
||||
|
||||
|
||||
|
||||
示例
|
||||
-----------
|
||||
|
||||
1. 打开 SQL Trace:
|
||||
|
||||
```unknow
|
||||
obclient> SET ob_enable_trace_log = 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
2. 执行目标 SQL:
|
||||
|
||||
```unknow
|
||||
obclient> CREATE TABLE t1(c1 INT,c2 INT,c3 INT);
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
|
||||
obclient> INSERT INTO t1 VALUES(1,1,1);
|
||||
Query OK, 1 rows affected (0.02 sec)
|
||||
|
||||
obclient> INSERT INTO t1 VALUES(2,2,2);
|
||||
Query OK, 1 rows affected (0.02 sec)
|
||||
|
||||
obclient>SELECT * FROM t1 WHERE c1 = 1;
|
||||
|
||||
+----+------+------+
|
||||
| c1 | c2 | c3 |
|
||||
+----+------+------+
|
||||
| 1 | 1 | 1 |
|
||||
+----+------+------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
3. 显示 Trace:
|
||||
|
||||
```unknow
|
||||
obclient> SHOW TRACE;
|
||||
+------------------------------+---------------------------------------------------------------------------------------------------+
|
||||
|
||||
| TITLE | KEYVALUE | TIME |
|
||||
+------------------------------+----------------------------------------------------------------------------+------+
|
||||
| process begin | in_queue_time:17, receive_ts:1612420489580707, enqueue_ts:1612420489580709 | 0 |
|
||||
| query begin | trace_id:YB42AC1E87E6-0005B8AB2D57844F | 1 |
|
||||
| parse begin | stmt:"set ob_enable_trace_log = 1", stmt_len:27 | 62 |
|
||||
| pc get plan begin | NULL | 9 |
|
||||
| pc get plan end | NULL | 19 |
|
||||
| transform_with_outline begin | NULL | 1 |
|
||||
| transform_with_outline end | NULL | 31 |
|
||||
| resolve begin | NULL | 21 |
|
||||
| resolve end | NULL | 33 |
|
||||
| execution begin | arg1:false, end_trans_cb:false | 14 |
|
||||
| start_auto_end_plan begin | NULL | 39 |
|
||||
| start_auto_end_plan end | NULL | 1 |
|
||||
| execution end | NULL | 11 |
|
||||
| query end | NULL | 39 |
|
||||
+------------------------------+---------------------------------------------------------------------------------------------+------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例中 `SHOW TRACE` 结果说明如下:
|
||||
* Title 列包含整个 SQL 执行经历的各个阶段的信息以及该 SQL 真实的执行路径。上述示例的结果中有经过 Resolve、Transform、Optimizer 和 Code Generate 四个流程,说明该 SQL 重新生成了计划,没有命中 plan cache。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* KeyValue 列包含一些执行信息,可以用于排查问题:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* Time 列显示上一个阶段点到这次阶段点执行耗时。
|
||||
|
||||
例如,resolve end 对应的 206 us 表示的是 resolve begin 到 resolve 耗时。如果某个 SQL 执行很慢,则通过查看 time 列,能够快速定位出具体是哪个阶段执行较慢,然后再进行具体分析。此例中,执行耗时主要在生成计划过程中,因此只需要分析没有命中 plan cache 的原因,可能是计划淘汰后 第一次执行该 SQL,或是 plan cache 不支持的 SQL。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,117 @@
|
||||
计划缓存视图
|
||||
===========================
|
||||
|
||||
计划缓存视图包含记录执行计划的缓存状态、执行统计的相关信息以及计划信息。
|
||||
|
||||
(g)v$plan_cache_stat
|
||||
-----------------------------
|
||||
|
||||
(g)v$plan_cache_stat 视图用于记录每个计划缓存的状态,每个计划缓存在该视图中有一条记录。
|
||||
|
||||
|
||||
| **字段名称** | **类型** | **描述** |
|
||||
|--------------|-------------|-----------------------------------|
|
||||
| tenant_id | bigint(20) | 租户 ID |
|
||||
| svr_ip | varchar(32) | IP 地址 |
|
||||
| svr_port | bigint(20) | 端口号 |
|
||||
| sql_num | bigint(20) | plan_cache 涉及 SQL 条数 |
|
||||
| mem_used | bigint(20) | plan_cache 已经使用的内存 |
|
||||
| access_count | bigint(20) | 进 plan_cache 的次数 |
|
||||
| hit_count | bigint(20) | 命中 plan_cache 的次数 |
|
||||
| hit_rate | bigint(20) | 命中 plan_cache 的次数 |
|
||||
| plan_num | bigint(20) | plan 的个数 |
|
||||
| mem_limit | bigint(20) | plan_cache 的内存上限 |
|
||||
| hash_bucket | bigint(20) | plan_cache hash map 中的 bucket 的个数 |
|
||||
| stmtkey_num | bigint(20) | plan_cache 中 stmt_key 的个数 |
|
||||
|
||||
|
||||
|
||||
(g)v$plan_cache_plan_stat
|
||||
----------------------------------
|
||||
|
||||
(g)v$plan_cache_plan_stat 用于记录计划缓存中所有 plan 的具体信息及每个计划总的执行统计信息,每个 plan 在该视图中有一条记录。
|
||||
|
||||
|
||||
| **字段名称** | **类型** | **描述** |
|
||||
|-----------------------|---------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| tenant_id | bigint(20) | 租户 ID |
|
||||
| svr_ip | varchar(32) | 机器的 IP 地址 |
|
||||
| svr_port | bigint(20) | 机器端口号 |
|
||||
| plan_id | bigint(20) | 执行计划的 ID |
|
||||
| sql_id | varchar(32) | 这条 SQL 的 ID |
|
||||
| type | bigint(20) | 执行计划的类型: * 1 表示 local plan * 2 表示 remote plan * 3 表示 distribute plan |
|
||||
| db_id | bigint(20) unsigned | database 的 ID |
|
||||
| is_bind_sensitive | bigint(20) | 该计划是否需要打开 ACS |
|
||||
| is_bind_aware | bigint(20) | 该计划已经打开了 ACS |
|
||||
| statement | varchar(4096) | 参数化后的 SQL 语句 |
|
||||
| query_sql | varchar(65536) | 第一次加载计划时查询的原始 SQL 语句 |
|
||||
| sys_vars | varchar(4096) | 影响计划的系统变量的值 |
|
||||
| plan_hash | bigint(20) | 执行计划的 hash 值 |
|
||||
| first_load_time | timestamp(6) | 第一次被加载时间 |
|
||||
| schema_version | bigint(20) | schema 版本号 |
|
||||
| merged_version | bigint(20) | 当前缓存的 plan 对应的合并版本号 |
|
||||
| last_active_time | timestamp(6) | 上一次被执行时间 |
|
||||
| avg_exe_usec | bigint(20) | 平均执行时间 |
|
||||
| slowest_exe_time | timestamp(6) | 最慢一次执行耗时 |
|
||||
| slowest_exe_usec | bigint(20) | 最慢执行时间戳 |
|
||||
| slow_count | bigint(20) | 当前 plan 成为慢查询次数 |
|
||||
| hit_count | bigint(20) | 被命中次数 |
|
||||
| plan_size | bigint(20) | 执行计划的大小 |
|
||||
| executions | bigint(20) | 执行次数 |
|
||||
| disk_reads | bigint(20) | 所有执行物理读次数 |
|
||||
| direct_writes | bigint(20) | 所有执行写盘的次数 |
|
||||
| buffer_gets | bigint(20) | 所有执行逻辑读次数 |
|
||||
| application_wait_time | bigint(20) unsigned | 所有执行所有 application 类事件的总时间 |
|
||||
| concurrency_wait_time | bigint(20) unsigned | 所有执行所有 concurrency 类事件的总时间 |
|
||||
| user_io_wait_time | bigint(20) unsigned | 所有执行所有 user_io 类事件的总时间 |
|
||||
| rows_processed | bigint(20) | 所有执行选择的结果行数或执行更改表中的行数 |
|
||||
| elapsed_time | bigint(20) unsigned | 所有执行接收到请求到执行结束消耗时间 |
|
||||
| cpu_time | bigint(20) unsigned | 所有执行消耗的 CPU 时间 |
|
||||
| large_querys | bigint(20) | 被判断为大查询的次数 |
|
||||
| delayed_large_querys | bigint(20) | 被判断为大查询且被丢入大查询队列的次数 |
|
||||
| outline_version | bigint(20) | outline 版本号 |
|
||||
| outline_id | bigint(20) | outline 的 ID。 如果为 -1 表示不是通过绑定 outline 生成的计划 |
|
||||
| outline_data | varchar(65536) | 计划对应的 outline 信息 |
|
||||
| acs_sel_info | varchar(65536) | 当前 ACS 计划对应的选择率空间 |
|
||||
| table_scan | tinyint(4) | 表示该查询是否为主键扫描 |
|
||||
| evolution | bool | 表示该执行计划是否在演进中 |
|
||||
| evo_executions | bigint(20) | 演进次数 |
|
||||
| evo_cpu_time | bigint(20) unsigned | 演进过程中总的执行 CPU 时间 |
|
||||
| timeout_count | bigint(20) | 超时次数 |
|
||||
| ps_stmt_id | bigint(20) | prepare statement 的 ID |
|
||||
|
||||
|
||||
|
||||
(g)v$plan_cache_plan_explain
|
||||
-------------------------------------
|
||||
|
||||
(g)v$plan_cache_plan_explain 用于查询某条 SQL 在计划缓存中的执行计划。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
* 如果查询 `gv$plan_cache_plan_explain` 表, 则需要指定 IP、port、tenant_id、plan_id 等条件。
|
||||
|
||||
|
||||
|
||||
* 如果查询 `v$plan_cache_plan_explain` 表, 则需要指定 tenant_id、plan_id 等条件。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
| **字段名称** | **类型** | **描述** |
|
||||
|-----------|--------------|-----------------|
|
||||
| TENANT_ID | bigint(20) | 租户 ID |
|
||||
| IP | varchar(32) | IP 地址 |
|
||||
| PORT | bigint(20) | 端口号 |
|
||||
| PLAN_ID | bigint(20) | 执行计划的 ID |
|
||||
| OPERATOR | varchar(128) | operator 的名称 |
|
||||
| NAME | varchar(128) | 表的名称 |
|
||||
| ROWS | bigint(20) | 预估的结果行数 |
|
||||
| COST | bigint(20) | 预估的代价 |
|
||||
| PROPERTY | varchar(256) | 对应 operator 的信息 |
|
||||
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
通过 SQL Audit 分析查询中等待事件
|
||||
===========================================
|
||||
|
||||
|
||||
|
||||
SQL Audit 记录了关于等待事件的如下信息:
|
||||
|
||||
* 记录了 4 大类等待事件分别的耗时(即 APPLICATION_WAIT_TIME、CONCURRENCY_WAIT_TIME、USER_IO_WAIT_TIME 和 SCHEDULE_TIME),每类等待事件都涉及很多具体的等待事件。
|
||||
|
||||
|
||||
|
||||
* 记录了耗时最多的等待事件名称(EVENT)及该等待事件耗时(WAIT_TIME_MICRO)。
|
||||
|
||||
|
||||
|
||||
* 记录了所有等待事件的发生的次数(TOTAL_WAITS)及所有等待事件总耗时(TOTAL_WAIT_TIME_MICRO)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
一般情况下,如果等待事件总耗时较多,通过查看耗时最多的等待事件名称(EVENT)能够基本确定是什么原因导致较慢。
|
||||
|
||||
如下例所示,可分析出等待事件主要耗时在 IO 等待上。
|
||||
|
||||
```sql
|
||||
obclient>SELECT SQL_ID, ELAPSED_TIME, QUEUE_TIME, GET_PLAN_TIME, EXECUTE_TIME,
|
||||
APPLICATION_WAIT_TIME, CONCURRENCY_WAIT_TIME, USER_IO_WAIT_TIME, SCHEDULE_TIME, EVENT,
|
||||
WAIT_CLASS, WAIT_TIME_MICRO, TOTAL_WAIT_TIME_MICRO
|
||||
FROM v$sql_audit
|
||||
WHERE TRACE_ID = 'YB42AC1E87E6-0005B8AB2D578471'\G;
|
||||
|
||||
************************** 1. row ***************************
|
||||
SQL_ID: CAFC81EE933820AEC5A86CBBAC1D0F6D
|
||||
ELAPSED_TIME: 2168
|
||||
QUEUE_TIME: 33
|
||||
GET_PLAN_TIME: 276
|
||||
EXECUTE_TIME: 1826
|
||||
APPLICATION_WAIT_TIME: 0
|
||||
CONCURRENCY_WAIT_TIME: 0
|
||||
USER_IO_WAIT_TIME: 0
|
||||
SCHEDULE_TIME: 0
|
||||
EVENT: sync rpc
|
||||
WAIT_CLASS: NETWORK
|
||||
WAIT_TIME_MICRO: 1596
|
||||
TOTAL_WAIT_TIME_MICRO: 1596
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,21 @@
|
||||
查找某个租户中执行全表扫描的 SQL
|
||||
=======================================
|
||||
|
||||
|
||||
|
||||
运行如下语句可以查询某个租户中执行全表扫描的 SQL:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT query_sql
|
||||
FROM oceanbase.gv$sql_audit
|
||||
WHERE table_scan = 1 AND tenant_id = 1001
|
||||
GROUP BY sql_id;
|
||||
|
||||
+-------------------------------+
|
||||
| query_sql |
|
||||
+-------------------------------+
|
||||
| SHOW VARIABLES LIKE 'version' |
|
||||
+-------------------------------+
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,43 @@
|
||||
分析分布式计划相关的查询问题
|
||||
===================================
|
||||
|
||||
|
||||
|
||||
分布式计划根据以下步骤分析查询问题:
|
||||
|
||||
1. 通过查看 `(g)v$plan_cache_plan_stat` 视图、`(g)v$sql_audit` 中对执行计划类型的记录,确定是否为分布式计划。
|
||||
|
||||
|
||||
|
||||
2. 分析该执行计划是否正确。
|
||||
|
||||
|
||||
|
||||
3. 通过 trace_id 关联查询 `gv$sql_audit`,查看所有执行的子计划耗时情况,每个子计划的 RPC 执行均对应一条 sql_audit 记录,分析该 sql_audit 记录来定位问题。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
如下例所示,`is_executor_rpc = 1` 表示子计划执行在 sql_audit 中记录,主要记录执行相关的信息。`is_executor_rpc = 0` 表示接受 SQL 请求的线程在 sql_audit 中的记录。该记录含有 SQL 执行过程的信息,包括 SQL 信息、获取执行计划信息等。
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/sql_id, is_executor_rpc, elapsed_time
|
||||
FROM oceanbase.gv$sql_audit WHERE trace_id = 'YB420AB74FC6-00056349D323483A';
|
||||
|
||||
+----------------------------------+-----------------+--------------+
|
||||
| sql_id | is_executor_rpc | elapsed_time |
|
||||
+----------------------------------+-----------------+--------------+
|
||||
| | 1 | 124 |
|
||||
| | 1 | 191 |
|
||||
| | 1 | 123447 |
|
||||
| | 1 | 125 |
|
||||
| 20172B18BC9EE3F806D4149895754CE0 | 0 | 125192 |
|
||||
| | 1 | 148 |
|
||||
| | 1 | 149 |
|
||||
| | 1 | 140 |
|
||||
+----------------------------------+-----------------+--------------+
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
查看分布式子计划 RPC 执行数是否均衡
|
||||
=========================================
|
||||
|
||||
|
||||
|
||||
运行如下语句可以查看分布式计划 RPC 执行数是否均衡:
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/t2.zone, t1.svr_ip, COUNT(*) AS RPC_COUNT,
|
||||
AVG(t1.elapsed_time),AVG(t1.queue_time)
|
||||
FROM oceanbase.gv$sql_audit t1, __all_server t2
|
||||
WHERE t1.svr_ip = t2.svr_ip AND IS_EXECUTOR_RPC = 1
|
||||
AND tenant_id = 1001
|
||||
AND request_time > (time_to_usec(now()) - 1000000)
|
||||
AND request_time < time_to_usec(now())
|
||||
GROUP BY t1.svr_ip ORDER BY t2.zone;
|
||||
|
||||
+--------+----------------+-----------+----------------------+--------------------+
|
||||
| zone | svr_ip | RPC_COUNT | avg(t1.elapsed_time) | avg(t1.queue_time) |
|
||||
+--------+----------------+-----------+----------------------+--------------------+
|
||||
| ET2_1 | 10.103.224.119 | 2517 | 514.2241 | 13.5515 |
|
||||
| ET2_1 | 10.103.226.124 | 2786 | 1628.0948 | 13.2915 |
|
||||
| ET2_1 | 10.103.228.177 | 3068 | 1984.0238 | 12.9029 |
|
||||
| ET2_1 | 10.103.229.107 | 3216 | 538.7646 | 12.8629 |
|
||||
| ET2_1 | 10.103.229.94 | 2228 | 802.8577 | 13.4138 |
|
||||
| EU13_2 | 10.183.78.113 | 2000 | 805.0485 | 13.0610 |
|
||||
| EU13_2 | 10.183.78.86 | 3296 | 1115.0725 | 13.2700 |
|
||||
| EU13_2 | 10.183.79.56 | 2460 | 1129.4085 | 14.3293 |
|
||||
| EU13_2 | 10.183.85.152 | 2533 | 891.0683 | 13.8602 |
|
||||
| EU13_3 | 10.183.76.140 | 3045 | 677.6591 | 13.7209 |
|
||||
| EU13_3 | 10.183.78.165 | 2202 | 821.9496 | 12.8247 |
|
||||
| EU13_3 | 10.183.79.198 | 2825 | 1277.0375 | 13.3345 |
|
||||
| EU13_3 | 10.183.86.65 | 2142 | 746.0808 | 13.0121 |
|
||||
| EU13_3 | 11.180.113.7 | 2735 | 765.8731 | 12.4750 |
|
||||
+--------+----------------+-----------+----------------------+--------------------+
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,40 @@
|
||||
分析 RT 突然抖动的 SQL
|
||||
====================================
|
||||
|
||||
|
||||
|
||||
推荐使用外部诊断工具 Tars 进行问题分析,或者使用 `(g)v$sql_audit` 视图进行问题排查。
|
||||
|
||||
使用 `(g)v$sql_audit` 进行问题排查方式如下:
|
||||
|
||||
1. 在线上如果出现 RT 抖动,但 RT 并不是持续很高的情况,可以考虑在抖动出现后,立刻将 sql_audit 关闭 (`alter system set ob_enable_sql_audit = 0`),从而确保该抖动的 SQL 请求在 sql_audit 中存在。
|
||||
|
||||
|
||||
|
||||
2. 通过 SQL Audit 查询抖动附近那段时间 RT 的 TOP N 请求,分析有异常的 SQL。
|
||||
|
||||
|
||||
|
||||
3. 找到对应的 RT 异常请求,则可以分析该请求在 sql_audit 中的记录进行问题排查:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
a. 查看是否有很长等待事件耗时。
|
||||
|
||||
b. 分析逻辑读次数是否异常多(突然有大账户时可能会出现)。
|
||||
|
||||
```sql
|
||||
逻辑读次数 = 2 * ROW_CACHE_HIT
|
||||
+ 2 * BLOOM_FILTER_CACHE_HIT
|
||||
+ BLOCK_INDEX_CACHE_HIT
|
||||
+ BLOCK_CACHE_HIT + DISK_READS
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果在 SQL Audit 中 RT 抖动的请求数据已被淘汰,则需要查看 OBServer 中抖动时间点是否有慢查询的 trace 日志,并分析对应的 trace 日志。
|
||||
@ -0,0 +1,17 @@
|
||||
查看执行计划形状并做分析
|
||||
=================================
|
||||
|
||||
|
||||
|
||||
根据如下步骤查看执行计划形状并做分析:
|
||||
|
||||
1. 通过 `EXPLAIN` 命令查看执行计划形状,或者通过实时执行计划展示查看缓存执行计划。详细信息请参见 [SQL 执行计划简介](../../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/1.introduction-to-sql-execution-plans-2.md)和 [实时执行计划展示](../../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/5.real-time-execution-plan-display-3.md)。
|
||||
|
||||
|
||||
|
||||
2. 获得执行计划形状后,可以分析索引、联接顺序、 联接算法等选择是否合理正确。详细信息请参见 [访问路径](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/1.access-path-3/1.overview-16.md)、[联接顺序](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/2.join-algorithm-5/3.join-order-3.md)和 [联接算法](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/2.join-algorithm-5/2.join-algorithm-6.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,18 @@
|
||||
分析慢 SQL 查询
|
||||
===============================
|
||||
|
||||
|
||||
|
||||
如果已知某条 SQL 查询一直比较慢,可以使用如下方式进行分析:
|
||||
|
||||
* 使用 sql_audit 查看统计数据并分析该 SQL 的执行计划。详细步骤请参考示例
|
||||
|
||||
[分析 RT 突然抖动的 SQL](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/2.sql-statement-that-analyzes-sudden-jitter-of-rt-1.md) 。
|
||||
|
||||
|
||||
* 分析下执行计划是否正确。详细步骤请参考示例 [查看执行计划形状并做分析](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/3.monitor-sql-execution-performance-1/4.sql-performance-analysis-example-1/3.view-and-analyze-the-execution-plan-1.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,21 @@
|
||||
查询 SQL 流量分布情况及 QPS
|
||||
=======================================
|
||||
|
||||
|
||||
|
||||
运行如下语句可以查询 SQL 流量分布情况及 QPS:
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/t2.zone, t1.svr_ip, COUNT(*) AS RPC_COUNT,
|
||||
AVG(t1.elapsed_time), AVG(t1.queue_time)
|
||||
FROM oceanbase.gv$sql_audit t1, __all_server t2
|
||||
WHERE t1.svr_ip = t2.svr_ip
|
||||
AND tenant_id = 1001
|
||||
AND SQL_ID = 'BF7AA13A28DF50BA5C33FF19F1DBD8A9'
|
||||
AND IS_EXECUTOR_RPC = 0
|
||||
AND request_time > (time_to_usec(now()) - 1000000)
|
||||
AND request_time < time_to_usec(now())
|
||||
GROUP BY t1.svr_ip;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,37 @@
|
||||
查看集群 SQL 请求流量是否均衡
|
||||
======================================
|
||||
|
||||
|
||||
|
||||
运行如下语句可以查看集群 SQL 请求流量是否均衡:
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/t2.zone, t1.svr_ip, COUNT(*) AS QPS,
|
||||
AVG(t1.elapsed_time), AVG(t1.queue_time)
|
||||
FROM oceanbase.gv$sql_audit t1, __all_server t2
|
||||
WHERE t1.svr_ip = t2.svr_ip AND IS_EXECUTOR_RPC = 0
|
||||
AND request_time > (time_to_usec(now()) - 1000000)
|
||||
AND request_time < time_to_usec(now())
|
||||
GROUP BY t1.svr_ip ORDER BY t2.zone;
|
||||
|
||||
+--------+----------------+------+----------------------+--------------------+
|
||||
| zone | svr_ip | QPS | avg(t1.elapsed_time) | avg(t1.queue_time) |
|
||||
+--------+----------------+------+----------------------+--------------------+
|
||||
| ET2_1 | 10.103.224.119 | 379 | 5067.3034 | 33.7071 |
|
||||
| ET2_1 | 10.103.226.124 | 507 | 5784.1538 | 12.5878 |
|
||||
| ET2_1 | 10.103.228.177 | 370 | 5958.2162 | 10.9811 |
|
||||
| ET2_1 | 10.103.229.107 | 356 | 5730.9972 | 39.4185 |
|
||||
| ET2_1 | 10.103.229.94 | 369 | 5851.7886 | 64.9621 |
|
||||
| EU13_2 | 10.183.78.113 | 354 | 6182.6384 | 11.3107 |
|
||||
| EU13_2 | 10.183.78.86 | 349 | 5881.3209 | 10.7393 |
|
||||
| EU13_2 | 10.183.79.56 | 347 | 5936.0144 | 11.9049 |
|
||||
| EU13_2 | 10.183.85.152 | 390 | 5988.4846 | 12.0487 |
|
||||
| EU13_3 | 10.183.76.140 | 284 | 5657.2218 | 11.7993 |
|
||||
| EU13_3 | 10.183.78.165 | 372 | 5360.6989 | 11.6290 |
|
||||
| EU13_3 | 10.183.79.198 | 416 | 4154.2861 | 12.2524 |
|
||||
| EU13_3 | 10.183.86.65 | 446 | 6487.6009 | 24.5112 |
|
||||
| EU13_3 | 11.180.113.7 | 364 | 5444.4203 | 12.3462 |
|
||||
+--------+----------------+------+----------------------+--------------------+
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,99 @@
|
||||
查询排名 TOP N 的 SQL
|
||||
=====================================
|
||||
|
||||
|
||||
|
||||
查询某段时间内请求次数排在 TOP N 的 SQL
|
||||
----------------------------------------------
|
||||
|
||||
运行如下语句可以查询某段时间内请求次数排在 TOP N 的 SQL:
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/ SQL_ID, COUNT(*) AS QPS, AVG(t1.elapsed_time) RT
|
||||
FROM oceanbase.gv$sql_audit t1 WHERE tenant_id = 1001 AND
|
||||
IS_EXECUTOR_RPC = 0 AND request_time > (time_to_usec(now()) - 10000000) AND
|
||||
request_time < time_to_usec (now())
|
||||
GROUP BY t1.sql_id ORDER BY QPS DESC LIMIT 10;
|
||||
|
||||
+----------------------------------+------+------------+
|
||||
| SQL_ID | QPS | RT |
|
||||
+----------------------------------+------+------------+
|
||||
| BF7AA13A28DF50BA5C33FF19F1DBD8A9 | 2523 | 4233.2085 |
|
||||
| CE7208ADDE365D0AB5E68EE24E5FD730 | 1268 | 5935.8683 |
|
||||
| E5C7494018989226E69AE7D08B3D0F15 | 1028 | 7275.7490 |
|
||||
| D0E8D8C937E44BC3BB9A5379AE1064C5 | 1000 | 12999.1640 |
|
||||
| 2D45D7BE4E459CFBEAE4803971F0C6F9 | 1000 | 8050.6360 |
|
||||
| C81CE9AA555BE59B088B379CC7AE5B40 | 1000 | 6865.4940 |
|
||||
| BDC4FE903B414203A04E41C7DDA6627D | 1000 | 12751.8960 |
|
||||
| B1B136047D7C3B6B9125F095363A9D23 | 885 | 13293.2237 |
|
||||
| 47993DD69888868E92A7CAB2FDE65380 | 880 | 7282.0557 |
|
||||
| 05C6279D767C7F212619BF4B659D3BAB | 844 | 11474.5438 |
|
||||
+----------------------------------+------+------------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
查询某段时间内平均 RT 排在 TOP N 的 SQL
|
||||
------------------------------------------------
|
||||
|
||||
运行如下语句可以查询某段时间内平均 RT 排在 TOP N 的 SQL:
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/ SQL_ID, COUNT(*) AS QPS, AVG(t1.elapsed_time) RT
|
||||
FROM oceanbase.gv$sql_audit t1
|
||||
WHERE tenant_id = 1001 AND IS_EXECUTOR_RPC = 0
|
||||
AND request_time > (time_to_usec(now()) - 10000000)
|
||||
AND request_time < time_to_usec(now())
|
||||
GROUP BY t1.sql_id ORDER BY RT DESC LIMIT 10;
|
||||
|
||||
|
||||
+----------------------------------+------+------------+
|
||||
| SQL_ID | QPS | RT |
|
||||
+----------------------------------+------+------------+
|
||||
| 0A3D3DCB3343BBBB10E4B4B9777B77FC | 1 | 53618.0000 |
|
||||
| A3831961C337545AF5BD1219BE29867A | 1 | 50764.0000 |
|
||||
| F3DC5EF627DA63AE52044FCE7732267C | 1 | 48497.0000 |
|
||||
| 39C63F143FDDACAEC090F480789DBCA5 | 1 | 47035.0000 |
|
||||
| A3BF306B02FF86E76C96C9CEFADBDB7E | 1 | 45553.0000 |
|
||||
| 7942E8D29BAFBF23EF3E3D29D55F428A | 1 | 45285.0000 |
|
||||
| 20989A74CC1703664BDE9D6EA7830C24 | 1 | 39143.0000 |
|
||||
| 80F40791E76C79D3DCD46FEEFFAB338E | 1 | 37654.0000 |
|
||||
| 07E2FE351E3DD82843E81930B84D3DDE | 1 | 37231.0000 |
|
||||
| 11B19DB5A1393590ABBE08005C155B2E | 1 | 37139.0000 |
|
||||
+----------------------------------+------+------------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
查询所有 SQL 中平均执行时间排在 TOP N 的 SQL
|
||||
---------------------------------------------------
|
||||
|
||||
运行如下语句可以查询所有 SQL 中平均执行时间排在 TOP N 的 SQL:
|
||||
|
||||
```sql
|
||||
obclient>SELECT/*+ PARALLEL(15)*/avg_exe_usec, svr_ip, svr_port, sql_id, plan_id
|
||||
FROM oceanbase.gv$plan_cache_plan_stat
|
||||
WHERE tenant_id = 1001
|
||||
ORDER BY avg_exe_usec DESC LIMIT 3\G;
|
||||
|
||||
*************************** 1. row ***************************
|
||||
avg_exe_usec: 9795912
|
||||
svr_ip: 10.183.76.140
|
||||
svr_port: 2882
|
||||
sql_id: C5D91E6C772D1B87C32BB3C9ED1435E1
|
||||
plan_id: 4668689
|
||||
*************************** 2. row ***************************
|
||||
avg_exe_usec: 9435052
|
||||
svr_ip: 10.103.229.107
|
||||
svr_port: 2882
|
||||
sql_id: 3B6EFEEC8332EB2A0822A3EA7B769500
|
||||
plan_id: 4692858
|
||||
*************************** 3. row ***************************
|
||||
avg_exe_usec: 9335002
|
||||
svr_ip: 11.180.113.7
|
||||
svr_port: 2882
|
||||
sql_id: 3B6EFEEC8332EB2A0822A3EA7B769500
|
||||
plan_id: 4683085
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,33 @@
|
||||
查询某段时间内执行时间排名 TOP N 的请求
|
||||
============================================
|
||||
|
||||
|
||||
|
||||
运行如下语句可以查询某段时间内执行时间排名 TOP N 的请求:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT/*+ PARALLEL(15)*/ sql_id, elapsed_time , trace_id
|
||||
FROM oceanbase.gv$sql_audit
|
||||
WHERE tenant_id = 1001
|
||||
and IS_EXECUTOR_RPC = 0
|
||||
and request_time > (time_to_usec(now()) - 10000000)
|
||||
AND request_time < time_to_usec(now())
|
||||
ORDER BY elapsed_time DESC LIMIT 10;
|
||||
|
||||
+----------------------------------+--------------+-------------------------------+
|
||||
| sql_id | elapsed_time | trace_id |
|
||||
+----------------------------------+--------------+-------------------------------+
|
||||
| CFA269275E3BB270408747C01F64D837 | 87381 | YB420AB75598-0005634FBED5C5E8 |
|
||||
| 1979A5B4A27D5C3DBE08F80383FD6EB6 | 83465 | YB420AB74E56-0005634B4B87353B |
|
||||
| 51248E6C3BB5EF1FC4E8E79CA685723E | 82767 | YB420AB74E56-0005634B4B82E7E1 |
|
||||
| 249C40E669DFCCE80E3D11446272FA11 | 79919 | YB420A67E27C-00056349549A79D3 |
|
||||
| BEFAD568C3858D2C2E35F01558CBEC06 | 77210 | YB420A67E4B1-00056345B0F2E97E |
|
||||
| FB1A6A8BC4125C324A38F91B3808D364 | 75870 | YB420AB74E71-00056347074261E6 |
|
||||
| 0343A519C0C5BF31C68CB68F63721990 | 75666 | YB420BB47107-00056346A5A631FB |
|
||||
| B140BB0C671D9B8616FB048544F3B85B | 73902 | YB420A67E56B-00056342A5A4683E |
|
||||
| 4F9B1D0A3822A3E0DF69DB11ABFBE0EA | 72963 | YB420BB47107-00056346A5AAC5F5 |
|
||||
| 9963E8D252E6CBA72FBA45AC5790BA11 | 72354 | YB420A67E56B-00056342A5A66089 |
|
||||
+----------------------------------+--------------+-------------------------------+
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,18 @@
|
||||
分析系统或某个 SQL 的执行是否出现大量不合理远程执行请求
|
||||
===================================================
|
||||
|
||||
|
||||
|
||||
运行如下 SQL 语句能够分析出某段时间内不同类型的计划的执行次数:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT COUNT(*),plan_type FROM oceanbase.gv$sql_audit WHERE tenant_id = 1001
|
||||
AND IS_EXECUTOR_RPC = 0
|
||||
AND request_time > (time_to_usec(now()) - 10000000)
|
||||
AND request_time < time_to_usec(now())
|
||||
GROUP BY plan_type ;
|
||||
```
|
||||
|
||||
|
||||
|
||||
一般情况下,如果出现远程执行请求比较多时,可能是由于出现切主或 Proxy 客户端路由不准确。
|
||||
@ -0,0 +1,14 @@
|
||||
概述
|
||||
=======================
|
||||
|
||||
数据库中的查询改写(Query Rewrite)是指将一个 SQL 改写成另外一个更加容易优化的 SQL。
|
||||
|
||||
OceanBase 数据库所支持的查询改写规则分为基于规则的查询改写和基于代价的查询改写。
|
||||
|
||||
基于规则的查询改写总是会把 SQL 往"好"的方向进行改写,从而增加该 SQL 的优化空间。一个典型的基于规则的改写是把子查询改写成联接。如果不改写,子查询的执行方式只能是 Nested Loop Join,改写之后,优化器就也可以考虑 Hash Join 和 Merge Join 的执行方式。
|
||||
|
||||
基于代价的查询改写并不能总是把 SQL 往"好"的方向进行改写,需要使用代价模型来判断。一个典型的基于代价的改写就是 Or-Expansion。
|
||||
|
||||
在数据库中,一个改写规则通常需要满足特定的条件才能够实现,而且很多规则的改写可以互相作用(一个规则的改写会触发另外一个规则的改写)。OceanBase 数据库把所有基于规则的查询改写分成若干个规则集合。对于每个规则集合,OceanBase 数据库采用迭代的方式进行改写,一直到 SQL 不能被改写为止或者迭代次数达到预先设定的阈值。类似地,对于基于代价的改写规则也是采用这种方式处理。
|
||||
|
||||
这里需要注意的是,基于代价的改写之后可能又会重新触发基于规则的改写,所以整体上的基于代价的改写和基于规则的改写也会采用这种迭代的方式进行改写。
|
||||
@ -0,0 +1,700 @@
|
||||
基于规则的查询改写
|
||||
==============================
|
||||
|
||||
基于规则的查询改写方式主要包括子查询相关改写、外联接消除、
|
||||
简化条件改写和
|
||||
非 SPJ(SELECT PROJECT JOIN)的改写等。
|
||||
|
||||
子查询相关改写
|
||||
----------------
|
||||
|
||||
优化器对于子查询一般使用嵌套执行的方式,也就是父查询每生成一行数据后,都需要执行一次子查询。使用这种方式需要多次执行子查询,执行效率很低。对于子查询的优化方式,一般会将其改写为联接操作,可大大提高执行效率,主要优点如下:
|
||||
|
||||
* 可避免子查询多次执行。
|
||||
|
||||
|
||||
|
||||
* 优化器可根据统计信息选择更优的联接顺序和联接方法。
|
||||
|
||||
|
||||
|
||||
* 子查询的联接条件、过滤条件改写为父查询的条件后,优化器可以进行进一步优化,比如条件下压等。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
子查询改写的方式主要包括视图合并、子查询展开和将 ANY/ALL 使用 MAX/MIN 改写等。
|
||||
|
||||
#### **视图合并**
|
||||
|
||||
视图合并是指将代表一个视图的子查询合并到包含该视图的查询中,视图合并后,有助于优化器增加联接顺序的选择、访问路径的选择以及进一步做其他改写操作,从而选择更优的执行计划。
|
||||
|
||||
OceanBase 数据库支持对 SPJ 视图进行合并。如下示例为 Q1 改写为 Q2:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient>CREATE TABLE t3 (c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
Q1:
|
||||
obclient>SELECT t1.c1, v.c1
|
||||
FROM t1, (SELECT t2.c1, t3.c2
|
||||
FROM t2, t3
|
||||
WHERE t2.c1 = t3.c1) v
|
||||
WHERE t1.c2 = v.c2;
|
||||
<==>
|
||||
Q2:
|
||||
obclient>SELECT t1.c1, t2.c1
|
||||
FROM t1, t2, t3
|
||||
WHERE t2.c1 = t3.c1 AND t1.c2 = t3.c2;
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果 Q1 不进行改写,则其联接顺序有以下几种:
|
||||
|
||||
* t1, v(t2,t3)
|
||||
|
||||
|
||||
|
||||
* t1, v(t3,t2)
|
||||
|
||||
|
||||
|
||||
* v(t2,t3), t1
|
||||
|
||||
|
||||
|
||||
* v(t3,t2), t1
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
进行视图合并改写后,可选择的联接顺序有:
|
||||
|
||||
* t1, t2, t3
|
||||
|
||||
|
||||
|
||||
* t1, t3, t2
|
||||
|
||||
|
||||
|
||||
* t2, t1, t3
|
||||
|
||||
|
||||
|
||||
* t2, t3, t1
|
||||
|
||||
|
||||
|
||||
* t3, t1, t2
|
||||
|
||||
|
||||
|
||||
* t3, t2, t1
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
可以看出,进行视图合并后,联接顺序可选择空间增加。对于复杂查询,视图合并后,对路径的选择和可改写的空间均会增大,从而使得优化器可生成更优的计划。
|
||||
|
||||
#### **子查询展开**
|
||||
|
||||
子查询展开是指将 WHERE 条件中子查询提升到父查询中,并作为联接条件与父查询并列进行展开。转换后子查询将不存在,外层父查询中会变成多表联接。
|
||||
|
||||
这样改写的好处是优化器在进行路径选择、联接方法和联接排序时都会考虑到子查询中的表,从而可以获得更优的执行计划。涉及的子查询表达式一般有 NOT IN、IN、NOT EXIST、EXIST、ANY、ALL。
|
||||
|
||||
子查询展开的方式如下:
|
||||
|
||||
* 改写条件使生成的联接语句能够返回与原始语句相同的行。
|
||||
|
||||
|
||||
|
||||
* 展开为半联接(SEMI JOIN / ANTI JOIN)
|
||||
|
||||
如下例所示,t2.c2 不具有唯一性,改为 SEMI JOIN,该语句改写后执行计划为:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
obclient>CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.01 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c2 FROM t2)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
---------------------------------------
|
||||
|0 |HASH SEMI JOIN| |495 |3931|
|
||||
|1 | TABLE SCAN |t1 |1000 |499 |
|
||||
|2 | TABLE SCAN |t2 |1000 |433 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
|
||||
1 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
2 - output([t2.c2]), filter(nil),
|
||||
access([t2.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
将查询前面操作符改为 NOT IN 后,可改写为 ANTI JOIN,具体计划如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT * FROM t1 WHERE t1.c1 NOT IN (SELECT t2.c2 FROM t2)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
------------------------------------------------
|
||||
|0 |NESTED-LOOP ANTI JOIN| |0 |520245|
|
||||
|1 | TABLE SCAN |t1 |1000 |499 |
|
||||
|2 | TABLE SCAN |t2 |22 |517 |
|
||||
================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
conds(nil), nl_params_([t1.c1], [(T_OP_IS, t1.c1, NULL, 0)])
|
||||
1 - output([t1.c1], [t1.c2], [(T_OP_IS, t1.c1, NULL, 0)]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
2 - output([t2.c2]), filter([(T_OP_OR, ? = t2.c2, ?, (T_OP_IS, t2.c2, NULL, 0))]),
|
||||
access([t2.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 子查询展开为内联接
|
||||
|
||||
上面示例的 Q1 中如果将 t2.c2 改为 t2.c1,由于 t2.c1 为主键,子查询输出具有唯一性,此时可以直接转换为内联接,如下例所示:
|
||||
|
||||
```javascript
|
||||
Q1:
|
||||
obclient>SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c1 FROM t2)\G;
|
||||
<==>
|
||||
Q2:
|
||||
obclient>SELECT t1.* FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
Q1 改写后的计划如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c1 FROM t2)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |HASH JOIN | |1980 |3725|
|
||||
|1 | TABLE SCAN|t2 |1000 |411 |
|
||||
|2 | TABLE SCAN|t1 |1000 |499 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
equal_conds([t1.c1 = t2.c1]), other_conds(nil)
|
||||
1 - output([t2.c1]), filter(nil),
|
||||
access([t2.c1]), partitions(p0)
|
||||
2 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于 NOT IN、IN、NOT EXIST、EXIST、ANY、ALL 子查询表达式都可以对应做类似的改写操作。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### **ANY/ALL 使用 MAX/MIN 改写**
|
||||
|
||||
对于 ANY/ALL 的子查询,如果子查询中没有 GROUP BY 子句、聚集函数以及 HAVING 时,以下表达式可以使用聚集函数 MIN/MAX 进行等价转换,其中 `col_item` 为单独列且有非 NULL 属性:
|
||||
|
||||
```sql
|
||||
val > ALL(SELECT col_item ...) <==> val > ALL(SELECT MAX(col_item) ...);
|
||||
val >= ALL(SELECT col_item ...) <==> val >= ALL(SELECT MAX(col_item) ...);
|
||||
val < ALL(SELECT col_item ...) <==> val < ALL(SELECT MIN(col_item) ...);
|
||||
val <= ALL(SELECT col_item ...) <==> val <= ALL(SELECT MIN(col_item) ...);
|
||||
val > ANY(SELECT col_item ...) <==> val > ANY(SELECT MIN(col_item) ...);
|
||||
val >= ANY(SELECT col_item ...) <==> val >= ANY(SELECT MIN(col_item) ...);
|
||||
val < ANY(SELECT col_item ...) <==> val < ANY(SELECT MAX(col_item) ...);
|
||||
val <= ANY(SELECT col_item ...) <==> val <= ANY(SELECT MAX(col_item) ...);
|
||||
```
|
||||
|
||||
|
||||
|
||||
将子查询更改为含有 MAX/MIN 的子查询后,再结合使用 MAX/MIN 的改写,可减少改写前对内表的多次扫描,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT c1 FROM t1 WHERE c1 > ANY(SELECT c1 FROM t2);
|
||||
<==>
|
||||
obclient>SELECT c1 FROM t1 WHERE c1 > ANY(SELECT MIN(c1) FROM t2);
|
||||
```
|
||||
|
||||
|
||||
|
||||
结合 MAX/MIN 的改写后,可利用 t2.c1 的主键序将 LIMIT 1 直接下压到 TABLE SCAN,将 MIN 值输出,执行计划如下:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT c1 FROM t1 WHERE c1 > ANY(SELECT c1 FROM t2)\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
---------------------------------------------------
|
||||
|0 |SUBPLAN FILTER | |1 |73 |
|
||||
|1 | TABLE SCAN |t1 |1 |37 |
|
||||
|2 | SCALAR GROUP BY| |1 |37 |
|
||||
|3 | SUBPLAN SCAN |subquery_table|1 |37 |
|
||||
|4 | TABLE SCAN |t2 |1 |36 |
|
||||
===================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1]), filter([t1.c1 > ANY(subquery(1))]),
|
||||
exec_params_(nil), onetime_exprs_(nil), init_plan_idxs_([1])
|
||||
1 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0)
|
||||
2 - output([T_FUN_MIN(subquery_table.c1)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_MIN(subquery_table.c1)])
|
||||
3 - output([subquery_table.c1]), filter(nil),
|
||||
access([subquery_table.c1])
|
||||
4 - output([t2.c1]), filter(nil),
|
||||
access([t2.c1]), partitions(p0),
|
||||
limit(1), offset(nil)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
外联接消除
|
||||
--------------
|
||||
|
||||
外联接操作可分为左外联接、右外联接和全外联接。在联接过程中,由于外联接左右顺序不能变换,优化器对联接顺序的选择会受到限制。外联接消除是指将外联接转换成内联接,从而可以提供更多可选择的联接路径,供优化器考虑。
|
||||
|
||||
如果进行外联接消除,需要存在"空值拒绝条件",即在 WHERE 条件中存在,当内表生成的值为 NULL 时,输出为 FALSE 的条件。
|
||||
|
||||
如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT t1.c1, t2.c2 FROM t1 LEFT JOIN t2 ON t1.c2 = t2.c2;
|
||||
```
|
||||
|
||||
|
||||
|
||||
这是一个外联接,在其输出行中 t2.c2 可能为 NULL。如果加上一个条件 ` t2.c2 > 5`,则通过该条件过滤后,t2.c1 输出不可能为 NULL, 从而可以将外联接转换为内联接。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT t1.c1, t2.c2 FROM t1 LEFT JOIN t2 ON t1.c2 = t2.c2 WHERE t2.c2 > 5;
|
||||
<==>
|
||||
obclient>SELECT t1.c1, t2.c2 FROM t1 LEFT INNER JOIN t2 ON t1.c2 = t2.c2
|
||||
WHERE t2.c2 > 5;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
简化条件改写
|
||||
---------------
|
||||
|
||||
#### HAVING 条件消除
|
||||
|
||||
如果查询中没有聚集操作及 GROUP BY,则 HAVING 可以合并到 WHERE 条件中,并将 HAVING 条件删除, 从而可以将 HAVING 条件在 WHERE 条件中统一管理,并进行进一步相关优化。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1 HAVING t1.c2 > 1;
|
||||
<==>
|
||||
obclient>SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1 AND t1.c2 > 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
改写后计划如下例所示, `t1.c2 > 1` 条件被下压到了 TABLE SCAN 层。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1 HAVING t1.c2 > 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |1 |59 |
|
||||
|1 | TABLE SCAN |t1 |1 |37 |
|
||||
|2 | TABLE GET |t2 |1 |36 |
|
||||
=========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil),
|
||||
conds(nil), nl_params_([t1.c1])
|
||||
1 - output([t1.c1], [t1.c2]), filter([t1.c2 > 1]),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
2 - output([t2.c1], [t2.c2]), filter(nil),
|
||||
access([t2.c1], [t2.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### **等价关系推导**
|
||||
|
||||
等价关系推导是指利用比较操作符的传递性,推倒出新的条件表达式,从而减少需要处理的行数或者选择到更有效的索引。
|
||||
|
||||
OceanBase 数据库可对等值联接进行推导,比如 `a = b AND a > 1` 可以推导出 `a = b AND a > 1 AND b > 1`, 如果 b 上有索引,且 `b > 1` 在该索引选择率很低,则可以大大提升访问 b 列所在表的性能。
|
||||
|
||||
如下例所示,条件 `t1.c1 = t2.c2 AND t1.c1 > 2`,等价推导后为 `t1.c1 = t2.c2 AND t1.c1 > 2 AND t2.c2 > 2`,从计划中可以看到 t2.c2 已下压到 TABLE SCAN,并且使用 t2.c2 对应的索引。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.15 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT PRIMARY KEY, c2 INT, c3 INT, KEY IDX_c2(c2));
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
/*此命令需运行于 MySQL 模式下*/
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT t1.c1, t2.c2 FROM t1, t2
|
||||
WHERE t1.c1 = t2.c2 AND t1.c1 > 2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
------------------------------------------
|
||||
|0 |MERGE JOIN | |5 |78 |
|
||||
|1 | TABLE SCAN|t2(IDX_c2)|5 |37 |
|
||||
|2 | TABLE SCAN|t1 |3 |37 |
|
||||
==========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t2.c2]), filter(nil),
|
||||
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
|
||||
1 - output([t2.c2]), filter(nil),
|
||||
access([t2.c2]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t2.c2], [t2.c1]), range(2,MAX ; MAX,MAX),
|
||||
range_cond([t2.c2 > 2])
|
||||
2 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1]), range(2 ; MAX),
|
||||
range_cond([t1.c1 > 2])
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### **恒真/假消除**
|
||||
|
||||
对于如下恒真恒假条件可以进行消除:
|
||||
|
||||
* false and expr = 恒 false
|
||||
|
||||
|
||||
|
||||
* true or expr = 恒 true
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
如下例所示,对于 `WHERE 0 > 1 AND c1 = 3`,由于 `0 > 1` 使得 AND 恒假, 所以该 SQL 不用执行,可直接返回,从而加快查询的执行。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT * FROM t1 WHERE 0 > 1 AND c1 = 3\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |0 |38 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter([0], [t1.c1 = 3]), startup_filter([0]),
|
||||
access([t1.c1], [t1.c2]), partitions(p0),
|
||||
is_index_back=false, filter_before_indexback[false,false],
|
||||
range_key([t1.__pk_increment], [t1.__pk_cluster_id], [t1.__pk_partition_id]),
|
||||
range(MAX,MAX,MAX ; MIN,MIN,MIN)always false
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
非 SPJ 的改写
|
||||
------------------
|
||||
|
||||
#### **冗余排序消除**
|
||||
|
||||
冗余排序消除是指删除 order item 中不需要的项,减少排序开销。以下三种情况可进行排序消除:
|
||||
|
||||
* ORDER BY 表达式列表中有重复列,可进行去重后排序。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT * FROM t1 WHERE c2 = 5 ORDER BY c1, c1, c2, c3 ;
|
||||
<==>
|
||||
obclient>SELECT * FROM t1 WHERE c2 = 5 ORDER BY c1, c2, c3;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* ORDER BY 列中存在 where 中有单值条件的列,该列排序可删除。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT * FROM t1 WHERE c2 = 5 ORDER BY c1, c2, c3;
|
||||
<==>
|
||||
obclient>SELECT * FROM t1 WHERE c2 = 5 ORDER BY c1, c3;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 如果本层查询有 ORDER BY 但是没有 LIMIT,且本层查询位于父查询的集合操作中,则 ORDER BY 可消除。因为对两个有序的集合做 UNION 操作,其结果是乱序的。但是如果 ORDER BY 中有 LIMIT,则语义是取最大/最小的 N 个,此时不能消除 ORDER BY,否则有语义错误。
|
||||
|
||||
```javascript
|
||||
obclient>(SELECT c1,c2 FROM t1 ORDER BY c1) UNION (SELECT c3,c4 FROM t2 ORDER BY c3);
|
||||
<==>
|
||||
obclient>(SELECT c1,c2 FROM t1) UNION (SELECT c3,c4 FROM t2);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### **LIMIT 下压**
|
||||
|
||||
LIMIT 下压改写是指将 LIMIT 下降到子查询中,OceanBase 数据库现在支持在不改变语义的情况下,将 LIMIT 下压到视图(示例 1)及 UNION 对应子查询(示例 2)中。
|
||||
|
||||
示例 1:
|
||||
|
||||
```sql
|
||||
obclient>SELECT * FROM (SELECT * FROM t1 ORDER BY c1) a LIMIT 1;
|
||||
<==>
|
||||
obclient>SELECT * FROM (SELECT * FROM t1 ORDER BY c1 LIMIT 1) a LIMIT 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例 2:
|
||||
|
||||
```sql
|
||||
obclient>(SELECT c1,c2 FROM t1) UNION ALL (SELECT c3,c4 FROM t2) LIMIT 5;
|
||||
<==>
|
||||
obclient>(SELECT c1,c2 FROM t1 LIMIT 5) UNION ALL (SELECT c3,c4 FROM t2 limit 5) LIMIT 5;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### **DISTINCT 消除**
|
||||
|
||||
* 如果 select item 中只包含常量,则可以消除 DISTINCT,并加上 LIMIT 1。
|
||||
|
||||
```sql
|
||||
obclient>SELECT DISTINCT 1,2 FROM t1 ;
|
||||
<==>
|
||||
obclient>SELECT DISTINCT 1,2 FROM t1 LIMIT 1;
|
||||
|
||||
obclient>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 INT);
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT DISTINCT 1,2 FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1 |36 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([1], [2]), filter(nil),
|
||||
access([t1.c1]), partitions(p0),
|
||||
limit(1), offset(nil),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1]), range(MIN ; MAX)always true
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 如果 select item 中包含确保唯一性约束的列,则 DISTINCT 能够消除,如下示例中 (c1, c2)为主键,可确保 c1、c2 和 c3 唯一性, 从而 DISTINCT 可消除。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT, c3 INT, PRIMARY KEY(c1, c2));
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
obclient>SELECT DISTINCT c1, c2, c3 FROM t2;
|
||||
<==>
|
||||
obclient>SELECT c1, c2 c3 FROM t2;
|
||||
|
||||
obclient>EXPLAIN SELECT DISTINCT c1, c2, c3 FROM t2\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t2 |1000 |455 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t2.c1], [t2.c2], [t2.c3]), filter(nil),
|
||||
access([t2.c1], [t2.c2], [t2.c3]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### **MIN/MAX 改写**
|
||||
|
||||
* 当 MIN/MAX 函数中参数为索引前缀列,且不含 GROUP BY 时,可将该 scalar aggregate 转换为走索引扫描 1 行的情况,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 INT, c3 INT, KEY IDX_c2_c3(c2,c3));
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
obclient>SELECT MIN(c2) FROM t1;
|
||||
<==>
|
||||
obclient>SELECT MIN(c2) FROM (SELECT c2 FROM t2 ORDER BY c2 LIMIT 1) AS t;
|
||||
|
||||
obclient>EXPLAIN SELECT MIN(c2) FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
--------------------------------------------------
|
||||
|0 |SCALAR GROUP BY| |1 |37 |
|
||||
|1 | SUBPLAN SCAN |subquery_table|1 |37 |
|
||||
|2 | TABLE SCAN |t1(idx_c2_c3) |1 |36 |
|
||||
==================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_MIN(subquery_table.c2)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_MIN(subquery_table.c2)])
|
||||
1 - output([subquery_table.c2]), filter(nil),
|
||||
access([subquery_table.c2])
|
||||
2 - output([t1.c2]), filter([(T_OP_IS_NOT, t1.c2, NULL, 0)]),
|
||||
access([t1.c2]), partitions(p0),
|
||||
limit(1), offset(nil)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 如果 `SELECT MIN/MAX` 的参数为常量,而且包含 GROUP BY,可以将 MIN/MAX 改为常量,从而减少 MIN/MAX 的计算开销。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT MAX(1) FROM t1 GROUP BY c1;
|
||||
<==>
|
||||
obclient>SELECT 1 FROM t1 GROUP BY c1;
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT MAX(1) FROM t1 GROUP BY c1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1000 |411 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1]), range(MIN ; MAX)always true
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 如果 `SELECT MIN/MAX` 的参数为常量,而且不含 GROUP BY,可以按照如下示例进行改写,从而走索引只需扫描 1 行。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT MAX(1) FROM t1;
|
||||
<==>
|
||||
obclient>SELECT MAX(t.a) FROM (SELECT 1 AS a FROM t1 LIMIT 1) t;
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT MAX(1) FROM t1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
==================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
--------------------------------------------------
|
||||
|0 |SCALAR GROUP BY| |1 |37 |
|
||||
|1 | SUBPLAN SCAN |subquery_table|1 |37 |
|
||||
|2 | TABLE SCAN |t1 |1 |36 |
|
||||
==================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T_FUN_MAX(subquery_table.subquery_col_alias)]), filter(nil),
|
||||
group(nil), agg_func([T_FUN_MAX(subquery_table.subquery_col_alias)])
|
||||
1 - output([subquery_table.subquery_col_alias]), filter(nil),
|
||||
access([subquery_table.subquery_col_alias])
|
||||
2 - output([1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0),
|
||||
limit(1), offset(nil),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1]), range(MIN ; MAX)always true
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,244 @@
|
||||
基于代价的查询改写
|
||||
==============================
|
||||
|
||||
OceanBase 数据库目前只支持一种基于代价的查询改写------或展开(OR-EXPANSION)。
|
||||
|
||||
数据库中很多高级的改写规则(例如 complex view merge 和窗口函数改写)都需要基于代价进行改写,OceanBase 数据库后续版本会支持这些复杂的改写规则。
|
||||
|
||||
或展开(OR-EXPANSION)
|
||||
--------------------------
|
||||
|
||||
OR-EXPANSION 是将一个查询改写成若干个用 UNION 组成的子查询,可以为每个子查询提供更优的优化空间,但是也会导致多个子查询的执行,所以这个改写需要基于代价去判断。
|
||||
|
||||
OR-EXPANSION 的改写主要有如下三个作用:
|
||||
|
||||
* 允许每个分支使用不同的索引来加速查询。
|
||||
|
||||
如下例所示,Q1 会被改写成 Q2 的形式,其中 Q2 中的谓词 `LNNVL(t1.a = 1)` 保证了这两个子查询不会生成重复的结果。如果不进行改写,Q1 一般来说会选择主表作为访问路径,对于 Q2 来说,如果 t1 上存在索引(a)和索引(b),那么该改写可能会让 Q2 中的每一个子查询选择索引作为访问路径。
|
||||
|
||||
```javascript
|
||||
Q1:
|
||||
obclient>SELECT * FROM t1 WHERE t1.a = 1 OR t1.b = 1;
|
||||
Q2:
|
||||
obclient>SELECT * FROM t1 WHERE t1.a = 1 UNION ALL SELECT * FROM t1.b = 1
|
||||
AND LNNVL(t1.a = 1);
|
||||
```
|
||||
|
||||
|
||||
|
||||
完整示例如下:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(a INT, b INT, c INT, d INT, e INT, INDEX IDX_a(a),
|
||||
INDEX IDX_b(b));
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
/*如果不进行 OR-EXPANSION 的改写,该查询只能使用主表访问路径*/
|
||||
obclient> EXPLAIN SELECT/*+NO_REWRITE()*/ * FROM t1 WHERE t1.a = 1 OR t1.b = 1;
|
||||
+--------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------+
|
||||
| ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |4 |649 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), filter([t1.a = 1 OR t1.b = 1]),
|
||||
access([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), partitions(p0)
|
||||
|
||||
/*改写之后,每个子查询能使用不同的索引访问路径*/
|
||||
obclient>EXPLAIN SELECT * FROM t1 WHERE t1.a = 1 OR t1.b = 1;
|
||||
+------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+------------------------------------------------------------------------+
|
||||
| =========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-----------------------------------------
|
||||
|0 |UNION ALL | |3 |190 |
|
||||
|1 | TABLE SCAN|t1(idx_a)|2 |94 |
|
||||
|2 | TABLE SCAN|t1(idx_b)|1 |95 |
|
||||
=========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)], [UNION(t1.c, t1.c)], [UNION(t1.d, t1.d)], [UNION(t1.e, t1.e)]), filter(nil)
|
||||
1 - output([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), filter(nil),
|
||||
access([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), partitions(p0)
|
||||
2 - output([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), filter([lnnvl(t1.a = 1)]),
|
||||
access([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), partitions(p02
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 允许每个分支使用不同的连接算法来加速查询,避免使用笛卡尔联接。
|
||||
|
||||
如下例所示,Q1 会被改写成 Q2 的形式。对于 Q1 来说,它的联接方式只能是 NESTED LOOP JOIN (笛卡尔乘积), 但是被改写之后,每个子查询都可以选择 NESTED LOOP JOIN、HASH JOIN 或者 MERGE JOIN,这样会有更多的优化空间。
|
||||
|
||||
```javascript
|
||||
Q1:
|
||||
obclient>SELECT * FROM t1, t2 WHERE t1.a = t2.a OR t1.b = t2.b;
|
||||
|
||||
Q2:
|
||||
obclient>SELECT * FROM t1, t2 WHERE t1.a = t2.a UNION ALL
|
||||
SELECT * FROM t1, t2 WHERE t1.b = t2.b AND LNNVL(t1.a = t2.a);
|
||||
```
|
||||
|
||||
|
||||
|
||||
完整示例如下:
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1(a INT, b INT);
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
obclient> CREATE TABLE t2(a INT, b INT);
|
||||
Query OK, 0 rows affected (0.13 sec)
|
||||
|
||||
/*如果不进行改写,只能使用 NESTED LOOP JOIN*/
|
||||
obclient> EXPLAIN SELECT/*+NO_REWRITE()*/ * FROM t1, t2
|
||||
WHERE t1.a = t2.a OR t1.b = t2.b;
|
||||
+--------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------------------+
|
||||
| ===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |3957 |585457|
|
||||
|1 | TABLE SCAN |t1 |1000 |499 |
|
||||
|2 | TABLE SCAN |t2 |4 |583 |
|
||||
===========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t2.a], [t2.b]), filter(nil),
|
||||
conds(nil), nl_params_([t1.a], [t1.b])
|
||||
1 - output([t1.a], [t1.b]), filter(nil),
|
||||
access([t1.a], [t1.b]), partitions(p0)
|
||||
2 - output([t2.a], [t2.b]), filter([? = t2.a OR ? = t2.b]),
|
||||
access([t2.a], [t2.b]), partitions(p0)
|
||||
|
||||
/*被改写之后,每个子查询都使用了 HASH JOIN*/
|
||||
obclient> EXPLAIN SELECT * FROM t1, t2 WHERE t1.a = t2.a OR t1.b = t2.b;
|
||||
+--------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------------------+
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |UNION ALL | |2970 |9105|
|
||||
|1 | HASH JOIN | |1980 |3997|
|
||||
|2 | TABLE SCAN|t1 |1000 |499 |
|
||||
|3 | TABLE SCAN|t2 |1000 |499 |
|
||||
|4 | HASH JOIN | |990 |3659|
|
||||
|5 | TABLE SCAN|t1 |1000 |499 |
|
||||
|6 | TABLE SCAN|t2 |1000 |499 |
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)], [UNION(t2.a, t2.a)], [UNION(t2.b, t2.b)]), filter(nil)
|
||||
1 - output([t1.a], [t1.b], [t2.a], [t2.b]), filter(nil),
|
||||
equal_conds([t1.a = t2.a]), other_conds(nil)
|
||||
2 - output([t1.a], [t1.b]), filter(nil),
|
||||
access([t1.a], [t1.b]), partitions(p0)
|
||||
3 - output([t2.a], [t2.b]), filter(nil),
|
||||
access([t2.a], [t2.b]), partitions(p0)
|
||||
4 - output([t1.a], [t1.b], [t2.a], [t2.b]), filter(nil),
|
||||
equal_conds([t1.b = t2.b]), other_conds([lnnvl(t1.a = t2.a)])
|
||||
5 - output([t1.a], [t1.b]), filter(nil),
|
||||
access([t1.a], [t1.b]), partitions(p0)
|
||||
6 - output([t2.a], [t2.b]), filter(nil),
|
||||
access([t2.a], [t2.b]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 允许每个分支分别消除排序,更加快速的获取 TOP-K 结果。
|
||||
|
||||
如下例所示,Q1 会被改写成 Q2。对于 Q1 来说,执行方式是只能把满足条件的行数找出来,然后进行排序,最终取 TOP-10 结果。对于 Q2 来说,如果存在索引(a,b), 那么 Q2 中的两个子查询都可以使用索引把排序消除,每个子查询取 TOP-10 结果,然后最终对这 20 行数据排序一下取出最终的 TOP-10 行。
|
||||
|
||||
```javascript
|
||||
Q1:
|
||||
obclient>SELECT * FROM t1 WHERE t1.a = 1 OR t1.a = 2 ORDER BY b LIMIT 10;
|
||||
|
||||
Q2:
|
||||
obclient>SELECT * FROM
|
||||
(SELECT * FROM t1 WHERE t1.a = 1 ORDER BY b LIMIT 10 UNION ALL
|
||||
SELECT * FROM t1 WHERE t1.a = 2 ORDER BY b LIMIT 10) AS TEMP
|
||||
ORDER BY temp.b LIMIT 10;
|
||||
```
|
||||
|
||||
|
||||
|
||||
完整示例如下:
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1(a INT, b INT, INDEX IDX_a(a, b));
|
||||
Query OK, 0 rows affected (0.20 sec)
|
||||
|
||||
/*不改写的话,需要排序最终获取 TOP-K 结果*/
|
||||
obclient> EXPLAIN SELECT/*+NO_REWRITE()*/ * FROM t1 WHERE t1.a = 1 OR t1.a = 2
|
||||
ORDER BY b LIMIT 10;
|
||||
+-------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-------------------------------------------------------------------------+
|
||||
| ==========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
------------------------------------------
|
||||
|0 |LIMIT | |4 |77 |
|
||||
|1 | TOP-N SORT | |4 |76 |
|
||||
|2 | TABLE SCAN|t1(idx_a)|4 |73 |
|
||||
==========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b]), filter(nil), limit(10), offset(nil)
|
||||
1 - output([t1.a], [t1.b]), filter(nil), sort_keys([t1.b, ASC]), topn(10)
|
||||
2 - output([t1.a], [t1.b]), filter(nil),
|
||||
access([t1.a], [t1.b]), partitions(p0)
|
||||
|
||||
/* 进行改写的话,排序算子可以被消除,最终获取 TOP-K 结果*/
|
||||
obclient>EXPLAIN SELECT * FROM t1 WHERE t1.a = 1 OR t1.a = 2
|
||||
ORDER BY b LIMIT 10;
|
||||
+-------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-------------------------------------------------------------------------+
|
||||
| ===========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-------------------------------------------
|
||||
|0 |LIMIT | |3 |76 |
|
||||
|1 | TOP-N SORT | |3 |76 |
|
||||
|2 | UNION ALL | |3 |74 |
|
||||
|3 | TABLE SCAN|t1(idx_a)|2 |37 |
|
||||
|4 | TABLE SCAN|t1(idx_a)|1 |37 |
|
||||
===========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)]), filter(nil), limit(10), offset(nil)
|
||||
1 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)]), filter(nil), sort_keys([UNION(t1.b, t1.b), ASC]), topn(10)
|
||||
2 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)]), filter(nil)
|
||||
3 - output([t1.a], [t1.b]), filter(nil),
|
||||
access([t1.a], [t1.b]), partitions(p0),
|
||||
limit(10), offset(nil)
|
||||
4 - output([t1.a], [t1.b]), filter([lnnvl(t1.a = 1)]),
|
||||
access([t1.a], [t1.b]), partitions(p0),
|
||||
limit(10), offset(nil)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
概述
|
||||
=======================
|
||||
|
||||
访问路径是指数据库中访问表的方法,即使用哪个索引来访问表。
|
||||
|
||||
访问路径的分析是单表查询的最重要的问题之一,对于使用主表扫描的访问路径来说,执行时间一般与需要扫描的数据量(范围)成正比。一般来说,可以使用 `EXPLAIN EXTENDED` 命令,将表扫描的范围段展示出来。对于有合适索引的查询,使用索引可以大大减小数据的访问量,因此对于使用主表扫描的查询,要分析没有选中索引扫描的原因,是由于不存在可用的索引,还是索引扫描范围过大以至于代价过高。
|
||||
|
||||
OceanBase 数据库的路径选择方法融合了基于规则的路径选择方法和基于代价的路径选择方法。OceanBase 数据库首先会使用基于规则的路径选择方法,如果基于规则的路径选择方法之后只有一个可选择的路径,那么就直接使用该路径,否则就再使用基于代价的路径选择方法选择一个代价最小的路径。
|
||||
|
||||
在 OceanBase 数据库中,用户可以通过 HINT 来指定访问路径。访问路径的 HINT 形式如下: `/+INDEX(table_name index_name)/`
|
||||
|
||||
其中 `table_name` 表示表的名字,`index_name` 表示索引的名字。如果 `index_name` 是 PRIMARY,代表选择主表扫描路径。
|
||||
|
||||
如下为用 HINT 来指定访问路径的示例:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, INDEX k1(b,c));
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT/*+INDEX(t1 PRIMARY)*/ * FROM t1;
|
||||
| ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1000 |476 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t1.d]), filter(nil),
|
||||
access([t1.a], [t1.b], [t1.c], [t1.d]), partitions(p0)
|
||||
|
||||
|
||||
obclient>EXPLAIN SELECT/*+INDEX(t1 k1)*/ * FROM t1;
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |TABLE SCAN|t1(k1)|1000 |5656|
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t1.d]), filter(nil),
|
||||
access([t1.a], [t1.b], [t1.c], [t1.d]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,325 @@
|
||||
基于规则的路径选择
|
||||
==============================
|
||||
|
||||
本文主要介绍 OceanBase 数据库路径选择的规则体系。
|
||||
|
||||
目前 OceanBase 数据库路径选择的规则体系分为前置规则(正向规则)和 Skyline 剪枝规则(反向规则)。前置规则直接决定了一个查询使用什么样的索引,是一个强匹配的规则体系。
|
||||
|
||||
Skyline 剪枝规则会比较两个索引,如果一个索引在一些定义的维度上优于(dominate)另外一个索引,那么不优的索引会被剪掉,最后没有被剪掉的索引会进行代价比较,从而选出最优的计划。
|
||||
|
||||
目前 OceanBase 数据库的优化器会优先使用前置规则选择索引,如果没有匹配的索引,那么 Skyline 剪枝规则会剪掉一些不优的索引,最后代价模型会在没有被剪掉的索引中选择代价最低的路径。
|
||||
|
||||
如下例所示,OceanBase 数据库的计划展示中会输出相应的路径选择的规则信息。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
|
||||
UNIQUE INDEX k1(b), INDEX k2(b,c), INDEX k3(c,d));
|
||||
Query OK, 0 rows affected (0.38 sec)
|
||||
|
||||
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE b = 1;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |TABLE SCAN|t1(k1)|2 |94 |
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a(0x7f3178058bf0)], [t1.b(0x7f3178058860)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), filter(nil),
|
||||
access([t1.b(0x7f3178058860)], [t1.a(0x7f3178058bf0)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), partitions(p0),
|
||||
is_index_back=true,
|
||||
range_key([t1.b(0x7f3178058860)], [t1.shadow_pk_0(0x7f31780784b8)]), range(1,MIN ; 1,MAX),
|
||||
range_cond([t1.b(0x7f3178058860) = 1(0x7f31780581d8)])
|
||||
Optimization Info:
|
||||
-------------------------------------
|
||||
t1:optimization_method=rule_based, heuristic_rule=unique_index_with_indexback
|
||||
|
||||
|
||||
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE c < 5 ORDER BY c;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |SORT | |200 |1054|
|
||||
|1 | TABLE SCAN|t1 |200 |666 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.c(0x7f3178058e90)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter(nil), sort_keys([t1.c(0x7f3178058e90), ASC])
|
||||
1 - output([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter([t1.c(0x7f3178058e90) < 5(0x7f3178058808)]),
|
||||
access([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), partitions(p0),
|
||||
is_index_back=false, filter_before_indexback[false],
|
||||
range_key([t1.a(0x7f3178059220)]), range(MIN ; MAX)always true
|
||||
t1:optimization_method=cost_based, avaiable_index_name[t1,k3], pruned_index_name[k1,k2]
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中 optimization_method 展示了具体的规则信息,它有以下两种形式:
|
||||
|
||||
* 如果 `optimization_method=rule_based`, 那么就是命中了前置规则,同时会展示出具体命中的规则名称,unique_index_with_indexback 表示命中了前置规则的第三条规则(唯一性索引全匹配+回表+回表数量少于一定的阈值)。
|
||||
|
||||
|
||||
|
||||
* 如果 `optimization_method=cost_based`, 那么就是基于代价选择出来的,同时会展示出来 Skyline 剪枝规则剪掉了那些访问路径(pruned_index_name)以及剩下了那些访问路径(avaiable_index_name)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
前置规则
|
||||
-------------
|
||||
|
||||
目前 OceanBase 数据库的前置规则只用于简单的单表扫描。因为前置规则是一个强匹配的规则体系,一旦命中,就直接选择命中的索引,所以要限制它的使用场景,以防选错计划。
|
||||
|
||||
目前 OceanBase 数据库根据"查询条件是否能覆盖所有索引键"和"使用该索引是否需要回表"这两个信息,将前置规则按照优先级划分成如下三种匹配类型:
|
||||
|
||||
* 匹配"唯一性索引全匹配+不需要回表(主键被当成唯一性索引来处理)",则选择该索引。如果存在多个这样的索引,选择索引列数最小的一个。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 匹配"普通索引全匹配+不需要回表",则选择该索引。如果存在多个这样的索引,选择索引列数最小的一个。
|
||||
|
||||
|
||||
|
||||
* 匹配"唯一性索引全匹配+回表+回表数量少于一定的阈值",则选择该索引。如果存在多个这样的索引,选择回表数量最小的一个。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
这里需要注意的是,索引全匹配是指在索引键上都存在等值条件(对应于 get 或者 multi-get)。
|
||||
|
||||
如下示例中,查询 Q1 命中了索引 uk1(唯一性索引全匹配+不需要回表);查询 Q2 命中了索引 uk2(唯一性索引全匹配+回表+回表行数最多 4 行)。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE test(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
|
||||
UNIQUE KEY UK1(b,c), UNIQUE KEY UK2(c,d) );
|
||||
Query OK, 0 rows affected (0.38 sec)
|
||||
|
||||
Q1:
|
||||
obclient>SELECT b,c FROM test WHERE (b = 1 OR b = 2) AND (c = 1 OR c =2);
|
||||
|
||||
Q2:
|
||||
obclient>SELECT * FROM test WHERE (c = 1 OR c =2) OR (d = 1 OR d = 2);
|
||||
```
|
||||
|
||||
|
||||
|
||||
Skyline 剪枝规则
|
||||
---------------------
|
||||
|
||||
Skyline 算子是学术界在 2001 年提出的一个新的数据库算子(它并不是标准的 SQL 算子)。自此之后,学术界对 Skyline 算子有大量的研究(包括语法、语义和执行等)。
|
||||
|
||||
Skyline 从字面上的理解是指天空中的一些边际点,这些点组成搜索空间中最优解的集合。例如要寻找价格最低并且路途最短的一家旅馆,想象一个二维空间,有两个维度,横轴表示价格,纵轴表示距离,二维空间上的每个点表示一个旅馆。
|
||||
|
||||
如下图所示,不论最后的选择如何,最优解肯定是在这一条天空的边际线上。假设点 A 不在 Skyline 上,那么肯定能够在 Skyline 上找到在两个维度上都比 A 更优的点 B,在这个场景中就是距离更近,价格更便宜的旅馆,称为点 B dominate A。所以 Skyline 一个重要应用场景就是用户没办法去衡量多个维度的比重,或者多个维度不能综合量化(如果可以综合量化,使用 "SQL 函数+ ORDER BY "就可以解决了)。
|
||||
|
||||

|
||||
|
||||
Skyline 操作是在给定对象集 O 中找出不被别的对象所 dominate 的对象集合。若一个对象 A 在所有维度都不被另一个对象 B 所 dominate,并且 A 至少在一个维度上 dominate B,则称 A dominate B。所以在 Skyline 操作中比较重要的是维度的选择以及在每个维度上的 dominate 的关系定义。假设有 N 个索引的路径 `<idx_1,idx_2,idx_3...idx_n>` 可以供优化器选择,如果对于查询 Q,索引 idx_x 在定义的维度上 dominate 索引 idx_y,那就可以提前把索引 idx_y 剪掉,不让它参与最终代价的运算。
|
||||
|
||||
维度的定义
|
||||
--------------
|
||||
|
||||
针对 Skyline 剪枝,对每个索引(主键也是一种索引)定义了如下三个维度:
|
||||
|
||||
* 是否回表
|
||||
|
||||
|
||||
|
||||
* 是否存在 intersting order
|
||||
|
||||
|
||||
|
||||
* 索引前缀能否抽取 query range
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过如下示例进行分析:
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE skyline(
|
||||
pk INT PRIMARY KEY, a INT, b INT, c INT,
|
||||
KEY idx_a_b(a, b),
|
||||
KEY idx_b_c(b, c),
|
||||
KEY idx_c_a(c, a));
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 回表:该查询是否需要需要回查主表。
|
||||
|
||||
```javascript
|
||||
/* 走索引 idx_a_b 的话就需要回查主表,因为索引 idx_a_b 没有 c 列*/
|
||||
obclient>SELECT /*+INDEX(skyline idx_a_b)*/ * FROM skyline;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* interesting order: 考虑是否有合适的序可以利用。
|
||||
|
||||
```javascript
|
||||
/* 索引 idx_b_c 可以把 ORDER BY 语句消除*/
|
||||
obclient>SELECT pk, b FROM skyline ORDER BY b;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 索引前缀能否抽取 query range。
|
||||
|
||||
```javascript
|
||||
/*可以看到走索引 idx_c_a 就可以快速定位到需要的行的范围,不用全表扫描*/
|
||||
obclient>SELECT pk, b FROM skyline WHERE c > 100 AND c < 2000;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
基于这三个维度,定义了索引之间的 dominate 关系,如果索引 A 在三个维度上都不比索引 B 差,并且其中至少有一个维度比 B 好,那么就可以直接把 B 索引剪掉,因为基于索引 B 最后生成的计划肯定不会比索引 A 好。
|
||||
|
||||
* 如果索引 idx_A 不需要回表,而索引 idx_B 需要回表,那么在这个维度上索引 idx_A dominate idx_B。
|
||||
|
||||
|
||||
|
||||
* 如果在索引 idx_A上抽取出来的 intersting order 是向量 `Va<a1, a2, a3 ...an>`, 在索引 idx_B 上抽出来的interesting order 是向量 `Vb<b1, b2, b3...bm>`, 如果 `n > m` , 并且对于`ai = bi (i=1..m`), 那么在这个维度上索引 idx_A dominate idx_B。
|
||||
|
||||
|
||||
|
||||
* 如果在索引 idx_A 能用来抽取的 query range 的列集合是 `Sa<a1, a2, a3 ...an>`,在索引 idx_B 上能用来抽取 query range 的列集合是 `Sb <b1, b2, b3...bm>`, 如果 Sa 是 Sb 的 super set, 那么在这个维度上索引 idx_A dominate idx_B。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### **回表**
|
||||
|
||||
这个维度初看比较简单,就是查询所需列是否在索引中。其中,一些案例需要特殊考虑,例如当主表和索引表都没有 interesting order 和抽取不了 query range 的情况下,直接走主表不一定是最优解。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(
|
||||
pk INT PRIMARY KEY, a INT, b INT, c INT, v1 VARCHAR(1000),
|
||||
v2 VARCHAR(1000), v3 VARCHAR(1000), v4 VARCHAR(1000),INDEX idx_a_b(a, b));
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>SELECT a, b,c FROM t1 WHERE b = 100;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
| **索引** | **Index Back** | **Interesting Order** | **Query Range** |
|
||||
|---------|----------------|-----------------------|-----------------|
|
||||
| primary | no | no | no |
|
||||
| idx_a_b | yes | no | no |
|
||||
|
||||
|
||||
|
||||
主表很宽,而索引表很窄,虽然从维度上主表 dominate 索引 idx_a_b,然而,索引扫描加回表的代价不一定会比主表全表扫描来的慢。简单来说,索引表可能只需要读一个宏块,而主表可能需要十个宏块。这种情况下,需要对规则做一些放宽,考虑具体的过滤条件。
|
||||
|
||||
#### **Interesting Order**
|
||||
|
||||
优化器通过 Interesting Order 利用底层的序,就不需要对底层扫描的行做排序,还可以消除 ORDER BY,进行 MERGE GROUP BY,提高 Pipeline(不需要进行物化)等。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE skyline(
|
||||
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
|
||||
KEY idx_v1_v3_v5(v1, v3, v5),
|
||||
KEY idx_v3_v4(v3, v4));
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
|
||||
obclient>CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
|
||||
Query OK, 0 rows affected (0.06 sec)
|
||||
|
||||
obclient>(SELECT DISTINCT v1, v3 FROM skyline JOIN tmp WHERE skyline.v1 = tmp.c1
|
||||
ORDER BY v1, v3) UNION (SELECT c1, c2 FROM tmp);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
从执行计划可以看到,ORDER BY 被消除了,同时使用了 MERGE DISTINCT,UNION 也没有做 SORT。可以看到,从底层 TABLE SCAN 吐出来的序,可以被上层的算子使用。换句话说,保留 idx_v1_v3_v5 吐出来的行的顺序,可以让后面的算子在保序的情况下执行更优的操作。优化器在识别这些序的情况下,才能生成更优的执行计划。
|
||||
|
||||
所以 Skyline 剪枝对 interesting order 的判断,需要充分考虑各个索引能够最大利用的序。例如上述最大的序其实是 `v1,v3` 而不仅仅是 v1,它从 MERGE JOIN 吐出来的序(v1, v3) 可以到 MERGE DISINCT 算子, 再到最后的 UNISON DISTINCT 算子。
|
||||
|
||||
#### **Query Range**
|
||||
|
||||
Query range 的抽取可以方便底层直接根据抽取出来的 range 定位到具体的宏块,而从减少存储层的 IO。
|
||||
|
||||
例如 `SELECT * FROM t1 WHERE pk < 100 AND pk > 0 `就可以直接根据一级索引的信息定位到具体的宏块,加速查询,越精确的 query range 能够让数据库扫描更少的行。
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1 (
|
||||
pk INT PRIMARY KEY, a INT, b INT,c INT,
|
||||
KEY idx_b_c(b, c),
|
||||
KEY idx_a_b(a, b));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient>SELECT b FROM t1 WHERE a = 100 AND b > 2000;
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于索引 idx_b_c 它能抽出 query range 的索引前缀是 (b),对于索引 idx_a_b 它能抽出 query range 的索引前缀是 (a, b),所以在这个维度上,索引 idx_a_b dominate idx_b_c。
|
||||
|
||||
综合举例
|
||||
-------------
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE skyline(
|
||||
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
|
||||
KEY idx_v1_v3_v5(v1, v3, v5),
|
||||
KEY idx_v3_v4(v3, v4));
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
|
||||
obclient>CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
|
||||
Query OK, 0 rows affected (0.06 sec)
|
||||
|
||||
obclient>SELECT MAX(v5) FROM skyline WHERE v1 = 100 AND v3 > 200 GROUP BY v1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
| **索引** | **Index Back** | **Interesting order** | **Query range** |
|
||||
|--------------|----------------|-----------------------|-----------------|
|
||||
| primary | Not need | No | No |
|
||||
| idx_v1_v3_v5 | Not need | (v1) | (v1, v3) |
|
||||
| idx_v3_v4 | Need | No | (v3) |
|
||||
|
||||
|
||||
|
||||
可以看到索引 idx_v1_v3_v5 在三个维度上都不比主键索引或索引 idx_v3_v4 差。所以在规则系统下,会直接剪掉主键索引和索引 idx_v3_v4。维度的合理定义,决定了 Skyline 剪枝是否合理。错误的维度,将会导致该索引提前被剪掉,从而导致永远生成不了最优的计划。
|
||||
@ -0,0 +1,114 @@
|
||||
基于代价的路径选择
|
||||
==============================
|
||||
|
||||
在基于规则的路径选择之后,如果存在多个可以选择的路径,那么 OceanBase 数据库会计算每个路径的代价,并从中选择代价最小的路径作为最终选择的路径。
|
||||
|
||||
OceanBase 数据库的代价模型考虑了 CPU 代价(比如处理一个谓词的 CPU 开销)和 IO 代价(比如顺序、随机读取宏块和微块的代价),CPU 代价和 IO 代价最终相加得到一个总的代价。
|
||||
|
||||
在 OceanBase 数据库中,每个访问路径的代价会在执行计划中都会展示出来。如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, INDEX k1(b));
|
||||
Query OK, 0 rows affected (0.35 sec)
|
||||
|
||||
/*主表路径的代价*/
|
||||
obclient>EXPLAIN SELECT/*+INDEX(t1 PRIMARY)*/ * FROM t1 WHERE b < 10;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |200 |622 |
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c]), filter([t1.b < 10]),
|
||||
access([t1.b], [t1.a], [t1.c]), partitions(p0)
|
||||
|
||||
/* k1 路径的代价*/
|
||||
obclient> EXPLAIN SELECT/*+INDEX(t1 k1)*/ * FROM t1 WHERE b < 10;
|
||||
+--------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------------+
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |TABLE SCAN|t1(k1)|200 |1114|
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c]), filter(nil),
|
||||
access([t1.b], [t1.a], [t1.c]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于一个访问路径,它的代价主要由扫描访问路径的代价和回表的代价两部分组成。如果一个访问路径不需要回表,那么就没有回表的代价。
|
||||
|
||||
在 OceanBase 数据库中,访问路径的代价取决于很多因素,比如扫描的行数、回表的行数、投影的列数和谓词的个数等。但是对于访问路径来说,代价在很大程度上取决于行数,所以在下面的示例分析中,从行数这个维度来介绍这两部分的代价。
|
||||
|
||||
* 扫描访问路径的代价
|
||||
|
||||
扫描访问路径的代价跟扫描的行数成正比,理论上来说扫描的行数越多,执行时间就会越久。对于一个访问路径,query range 决定了需要扫描的范围,从而决定了需要扫描的行数。Query range 的扫描是顺序 IO。
|
||||
|
||||
|
||||
* 回表的代价
|
||||
|
||||
回表的代价跟回表的行数也也是正相关的,回表的行数越多(回表的行数是指满足所有能在索引上执行的谓词的行数),执行时间就会越长。回表的扫描是随机 IO,所以回表一行的代价会比 query range 扫描一行的代价高很多。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当分析一个访问路径的性能的时候,可以从上面两个因素入手,获取通过 query range 扫描的行数以及回表的行数。这两个行数通常可以通过执行 SQL 语句来获取。
|
||||
|
||||
如下例所示,对于查询 `SELECT * FROM t1 WHERE c2 > 20 AND c2 < 800 AND c3 < 200`,索引 k1 的访问路径是,首先通常计划展示来获取用来抽取 query range 的谓词,谓词 `c2 > 20 AND c2 < 800` 用来抽取 query range,谓词 `c3 < 200` 被当成回表前的谓词。那么可以使用如下两个查询来检查 query range 抽取的行数以及回表之后的行数。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT, c3 INT, c4 INT, c5 INT, INDEX k1(c2,c3));
|
||||
Query OK, 0 rows affected (0.26 sec)
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT/*+INDEX(t1 k1)*/ * FROM t1 WHERE
|
||||
c2 > 20 AND c2 < 800 AND c3 < 200;
|
||||
+--------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------+
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |TABLE SCAN|t1(k1)|156 |1216|
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2], [t1.c3], [t1.c4], [t1.c5]), filter([t1.c3 < 200]),
|
||||
access([t1.c2], [t1.c3], [t1.c1], [t1.c4], [t1.c5]), partitions(p0),
|
||||
is_index_back=true, filter_before_indexback[true],
|
||||
range_key([t1.c2], [t1.c3], [t1.c1]), range(20,MAX,MAX ; 800,MIN,MIN),
|
||||
range_cond([t1.c2 > 20], [t1.c2 < 800])
|
||||
|
||||
/*query range 扫描的行数*/
|
||||
obclient>SELECT/*+INDEX(t1 k1)*/ COUNT(*) FROM t1 WHERE c2 > 20 AND c2 < 800;
|
||||
+----------+
|
||||
| count(*) |
|
||||
+----------+
|
||||
| 779 |
|
||||
+----------+
|
||||
1 row in set (0.02 sec)
|
||||
|
||||
/* 回表的行数*/
|
||||
obclient> SELECT/*+INDEX(t1 k1)*/ COUNT(*) FROM t1 WHERE c2 > 20 AND c2 < 800
|
||||
AND c3 < 200;
|
||||
+----------+
|
||||
| count(*) |
|
||||
+----------+
|
||||
| 179 |
|
||||
+----------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,13 @@
|
||||
概述
|
||||
=======================
|
||||
|
||||
|
||||
|
||||
数据库中的联接语句用于将数据库中的两个或多个表根据联接条件,把表的属性通过它们的值组合在一起。由"联接"生成的集合,可以被保存为表,或者当成表来使用。
|
||||
|
||||
不同方式的联接算法为 SQL 调优提供了更多的选择,可以使得 SQL 调优时能够根据表的数据特性选择合适的联接算法,从而让多表联接组合起来变得更加高效。
|
||||
|
||||
联接语句在数据中由联接算法实现,主要的联接算法有 NESTED LOOP JOIN、HASH JOIN 和 MERGE JOIN。由于三种算法在不同的场景下各有优劣,优化器会自动选择联接算法。关于各算法的原理,请参见 [联接算法](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/2.join-algorithm-5/2.join-algorithm-6.md)。
|
||||
|
||||
针对联接顺序及联接算法的选择,OceanBase 数据库也提供了相关 HINT 机制进行控制,以方便用户根据自身的实际需求去选择何种联接顺序及联接算法以进行多表的联接。
|
||||
|
||||
@ -0,0 +1,446 @@
|
||||
联接算法
|
||||
=========================
|
||||
|
||||
OceanBase 数据库当前版本支持 NESTED LOOP JOIN、 HASH JOIN 和 MERGE JOIN 三种不同的联接算法。
|
||||
|
||||
HASH JOIN 和 MERGE JOIN 只适用于等值的联接条件,NESTED LOOP JOIN 可用于任意的联接条件。
|
||||
|
||||
NESTED LOOP JOIN
|
||||
-------------------------
|
||||
|
||||
NESTED LOOP JOIN 就是扫描一个表(外表),每读到该表中的一条记录,就去"扫描"另一张表(内表)找到满足条件的数据。
|
||||
|
||||
这里的"扫描"可以是利用索引快速定位扫描,也可以是全表扫描。通常来说,全表扫描的性能是很差的,所以如果联接条件的列上没有索引,优化器一般就不会选择 NESTED LOOP JOIN。在 OceanBase 数据库中,执行计划中展示了是否能够利用索引快速定位扫描。
|
||||
|
||||
如下例所示,第一个计划对于内表的扫描是全表扫描,因为联接条件是 `t1.c = t2.c`,而 t2 没有在 c 上面的索引。第二个计划对于内表的扫描能够使用索引快速找到匹配的行,主要原因是联接条件为 `t1.b = t2.b`,而且 t2 选择了创建在 b 列上的索引 k1 作为访问路径,这样对于 t1 中的每一行的每个 b 值,t2 都可以根据索引快速找到满足条件的匹配行。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.24 sec)
|
||||
|
||||
obclient>>CREATE TABLE t2(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient> EXPLAIN EXTENDED_NOADDR SELECT/*+USE_NL(t1 t2)*/ * FROM t1, t2
|
||||
WHERE t1.c = t2.c;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |1980 |623742|
|
||||
|1 | TABLE SCAN |t1 |1000 |455 |
|
||||
|2 | TABLE SCAN |t2 |2 |622 |
|
||||
===========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
conds(nil), nl_params_([t1.c])
|
||||
1 - output([t1.c], [t1.a], [t1.b]), filter(nil),
|
||||
access([t1.c], [t1.a], [t1.b]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.a]), range(MIN ; MAX)always true
|
||||
2 - output([t2.c], [t2.a], [t2.b]), filter([? = t2.c]),
|
||||
access([t2.c], [t2.a], [t2.b]), partitions(p0),
|
||||
is_index_back=false, filter_before_indexback[false],
|
||||
range_key([t2.a]), range(MIN ; MAX)
|
||||
|
||||
obclient> EXPLAIN EXTENDED_NOADDR SELECT/*+USE_NL(t1 t2)*/ * FROM t1, t2
|
||||
WHERE t1.b = t2.b;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ============================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |1980 |94876|
|
||||
|1 | TABLE SCAN |t1 |1000 |455 |
|
||||
|2 | TABLE SCAN |t2(k1)|2 |94 |
|
||||
============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
conds(nil), nl_params_([t1.b])
|
||||
1 - output([t1.b], [t1.a], [t1.c]), filter(nil),
|
||||
access([t1.b], [t1.a], [t1.c]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.a]), range(MIN ; MAX)always true
|
||||
2 - output([t2.b], [t2.a], [t2.c]), filter(nil),
|
||||
access([t2.b], [t2.a], [t2.c]), partitions(p0),
|
||||
is_index_back=true,
|
||||
range_key([t2.b], [t2.a]), range(MIN ; MAX),
|
||||
range_cond([? = t2.b])
|
||||
```
|
||||
|
||||
|
||||
|
||||
NESTED LOOP JOIN 可能会对内表进行多次全表扫描,因为每次扫描都需要从存储层重新迭代一次,这个代价相对是比较高的,所以 OceanBase 数据库支持对内表进行一次扫描并把结果物化在内存中,这样在下一次执行扫描时就可以直接在内存中扫描相关的数据,而不需要从存储层进行多次扫描。但是物化在内存中是有代价的,所以 OceanBase 数据库的优化器基于代价去判断是否需要物化内表。
|
||||
|
||||
NESTED LOOP JOIN 的一个优化变种是 BLOCKED NESTED LOOP JOIN,它每次从外表中读取一个 block 大小的行,然后再去扫描内表找到满足条件的数据,这样可以减少内表的读取次数。
|
||||
|
||||
NESTED LOOP JOIN 通常用在内表行数比较少,而且外表在联接条件的列上有索引的场景,因为内表中的每一行都可以快速的使用索引定位到相对应的匹配的数据。
|
||||
|
||||
同时,OceanBase 数据库也提供了 HINT 机制 `/*+ USE_NL(table_name_list) */` 去控制多表联接的时候选择 NESTED LOOP JOIN。例如下述场景联接算法选择的是 HASH JOIN,而用户希望使用 NESTED LOOP JOIN,就可以使用上述 HINT 进行控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2 WHERE t1.c1 = t2.c1;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |HASH JOIN | |98010000 |66774608|
|
||||
|1 | TABLE SCAN|T1 |100000 |68478 |
|
||||
|2 | TABLE SCAN|T2 |100000 |68478 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_NL(t1, c2)*/* FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ===============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |98010000 |4595346207|
|
||||
|1 | TABLE SCAN |T1 |100000 |68478 |
|
||||
|2 | MATERIAL | |100000 |243044 |
|
||||
|3 | TABLE SCAN |T2 |100000 |68478 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
conds([T1.C1 = T2.C1]), nl_params_(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil)
|
||||
3 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
NESTED LOOP JOIN 还有以下两种实现的算法:
|
||||
|
||||
* 缓存块嵌套循环联接(BLOCKED NESTED LOOP JOIN)
|
||||
|
||||
BLOCKED NESTED LOOP JOIN 在 OceanBase 数据库中的实现方式是 BATCH NESTED LOOP JOIN,通过从外表中批量读取数据行(默认是 1000 行),然后再去扫描内表找到满足条件的数据。这样将批量的数据与内层表的数据进行匹配,减少了内表的读取次数和内层循环的次数。
|
||||
|
||||
如下示例中,`batch_join=true` 字段表示本次查询使用了 BATCH NESTED LOOP JOIN。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT PRIMARY KEY);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT /*+USE_NL(t1,t2)*/* FROM t1,t2
|
||||
WHERE t1.c1=t2.c1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |100001 |3728786|
|
||||
|1 | TABLE SCAN |t1 |100000 |59654 |
|
||||
|2 | TABLE GET |t2 |1 |36 |
|
||||
============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t2.c1]), filter(nil),
|
||||
conds(nil), nl_params_([t1.c1]), inner_get=false, self_join=false, batch_join=true
|
||||
1 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1]), range(MIN ; MAX)always true
|
||||
2 - output([t2.c1]), filter(nil),
|
||||
access([t2.c1]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t2.c1]), range(MIN ; MAX),
|
||||
range_cond([? = t2.c1])
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 索引嵌套循环联接(INDEX NESTED LOOP JOIN)
|
||||
|
||||
INDEX NESTED LOOP JOIN 是基于索引进行联接的算法,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较,减少了对内层表的匹配次数。
|
||||
|
||||
如下示例中存在联接条件 `t1.c1 = t2.c1`,则在 t2 表的 c1 列上有索引或 t1 表的 c1 列上有索引的时候,会使用 INDEX NESTED LOOP JOIN。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT ,c2 INT);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+ORDERED USE_NL(t2,t1)*/ * FROM t2,
|
||||
(SELECT /*+NO_MERGE*/ * FROM t1)t1
|
||||
WHERE t1.c1 = t2.c1 AND t2.c2 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |981 |117272|
|
||||
|1 | TABLE SCAN |t2 |990 |80811 |
|
||||
|2 | SUBPLAN SCAN |t1 |1 |37 |
|
||||
|3 | TABLE GET |t1 |1 |36 |
|
||||
===========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t2.c1], [t2.c2], [t1.c1]), filter(nil), conds(nil), nl_params_([t2.c1])
|
||||
1 - output([t2.c1], [t2.c2]), filter([t2.c2 = 1]), access([t2.c1], [t2.c2]), partitions(p0)
|
||||
2 - output([t1.c1]), filter(nil), access([t1.c1])
|
||||
3 - output([t1.c1]), filter(nil), access([t1.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 outputs \& filters 的输出结果中 `nl_param` 出现参数 `[t2.c1]`,说明执行了条件下压优化。详细信息请参考 [JOIN](../../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/3.JOIN-1-2.md)。
|
||||
|
||||
一般地,在进行查询优化时,OceanBase 数据库优化器会优先选择 INDEX NESTED LOOP JOIN,然后检查是否可以使用 BATCH NESTED LOOP JOIN,这两种优化方式可以一起使用,最后才会选择 NESTED LOOP JOIN。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
MERGE JOIN
|
||||
-------------------
|
||||
|
||||
MERGE JOIN 首先会按照联接的字段对两个表进行排序(如果内存空间不够,就需要进行外排),然后开始扫描两张表进行合并。
|
||||
|
||||
合并的过程会从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
|
||||
|
||||
在多对多的两张表上进行合并时,通常需要使用临时空间进行操作。例如 A JOIN B 使用 MERGE JOIN 时,如果对于关联字段的某一组值,在 A 和 B 中都存在多条记录 A1、A2...An 和 B1、B2...Bn,则为 A 中每一条记录 A1、A2...An,都必须对 B 中对所有相等的记录 B1、B2...Bn 进行一次匹配。这样,指针需要多次从 B1 移动到 Bn,每一次都需要读取相应的 B1...Bn 记录。将 B1...Bn 的记录预先读出来放入内存临时表中,比从原数据页或磁盘读取要快。在一些场景中,如果联接字段上有可用的索引,并且排序一致,那么可以直接跳过排序操作。
|
||||
|
||||
通常来说,MERGE JOIN 比较适合两个输入表已经有序的情况,否则 HASH JOIN 会更加好。如下示例,展示了两个 MERGE JOIN 的计划,其中第一个是需要排序的,第二个是不需要排序的(因为两个表都选择了 k1 这两个索引访问路径,这两个索引本身就是按照 b 排序的)。
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.24 sec)
|
||||
|
||||
obclient> CREATE TABLE t2(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient> EXPLAIN SELECT/*+USE_MERGE(t1 t2)*/ * FROM t1, t2 WHERE t1.c = t2.c;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |MERGE JOIN | |1980 |6011|
|
||||
|1 | SORT | |1000 |2198|
|
||||
|2 | TABLE SCAN|t1 |1000 |455 |
|
||||
|3 | SORT | |1000 |2198|
|
||||
|4 | TABLE SCAN|t2 |1000 |455 |
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
equal_conds([t1.c = t2.c]), other_conds(nil)
|
||||
1 - output([t1.a], [t1.b], [t1.c]), filter(nil), sort_keys([t1.c, ASC])
|
||||
2 - output([t1.c], [t1.a], [t1.b]), filter(nil),
|
||||
access([t1.c], [t1.a], [t1.b]), partitions(p0)
|
||||
3 - output([t2.a], [t2.b], [t2.c]), filter(nil), sort_keys([t2.c, ASC])
|
||||
4 - output([t2.c], [t2.a], [t2.b]), filter(nil),
|
||||
access([t2.c], [t2.a], [t2.b]), partitions(p0)
|
||||
|
||||
|
||||
obclient>EXPLAIN SELECT/*+USE_MERGE(t1 t2),INDEX(t1 k1),INDEX(t2 k1)*/ *
|
||||
FROM t1, t2 WHERE t1.b = t2.b;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =======================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
---------------------------------------
|
||||
|0 |MERGE JOIN | |1980 |12748|
|
||||
|1 | TABLE SCAN|t1(k1)|1000 |5566 |
|
||||
|2 | TABLE SCAN|t2(k1)|1000 |5566 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
equal_conds([t1.b = t2.b]), other_conds(nil)
|
||||
1 - output([t1.b], [t1.a], [t1.c]), filter(nil),
|
||||
access([t1.b], [t1.a], [t1.c]), partitions(p0)
|
||||
2 - output([t2.b], [t2.a], [t2.c]), filter(nil),
|
||||
access([t2.b], [t2.a], [t2.c]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
同时,OceanBase 数据库也提供了 HINT 机制 `/*+ USE_MERGE(table_name_list) */` 去控制多表联接的时候选择 MERGE JOIN 联接算法。例如下述场景中联接算法选择的是 HASH JOIN,而用户希望使用 MERGE JOIN,则可以使用上述 HINT 进行控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |HASH JOIN | |98010000 |66774608|
|
||||
|1 | TABLE SCAN|T1 |100000 |68478 |
|
||||
|2 | TABLE SCAN|T2 |100000 |68478 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_MERGE(t1,t2)*/* FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------
|
||||
|0 |MERGE JOIN | |98010000 |67488837|
|
||||
|1 | SORT | |100000 |563680 |
|
||||
|2 | TABLE SCAN|T1 |100000 |68478 |
|
||||
|3 | SORT | |100000 |563680 |
|
||||
|4 | TABLE SCAN|T2 |100000 |68478 |
|
||||
=========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C1, ASC])
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
3 - output([T2.C1], [T2.C2]), filter(nil), sort_keys([T2.C1, ASC])
|
||||
4 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
HASH JOIN
|
||||
------------------
|
||||
|
||||
HASH JOIN 就是用两个表中相对较小的表(通常称为 build table)根据联接条件创建 hash table,然后逐行扫描较大的表(通常称为 probe table)并通过探测 hash table 找到匹配的行。 如果 build table 非常大,构建的 hash table 无法在内存中容纳时,Oceanbase 数据库会分别将 build table 和 probe table 按照联接条件切分成多个分区(partition),每个 partition 都包括一个独立的、成对匹配的 build table 和 probe table,这样就将一个大的 HASH JOIN 切分成多个独立、互相不影响的 HASH JOIN,每一个分区的 HASH JOIN 都能够在内存中完成。在绝大多数情况下,HASH JOIN 效率比其他 JOIN 方式效率更高。
|
||||
|
||||
如下是 HASH JOIN 计划的示例。
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.24 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient> EXPLAIN SELECT/*+USE_HASH(t1 t2)*/ * FROM t1, t2 WHERE t1.c = t2.c;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |HASH JOIN | |1980 |4093|
|
||||
|1 | TABLE SCAN|t1 |1000 |455 |
|
||||
|2 | TABLE SCAN|t2 |1000 |455 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
equal_conds([t1.c = t2.c]), other_conds(nil)
|
||||
1 - output([t1.c], [t1.a], [t1.b]), filter(nil),
|
||||
access([t1.c], [t1.a], [t1.b]), partitions(p0)
|
||||
2 - output([t2.c], [t2.a], [t2.b]), filter(nil),
|
||||
access([t2.c], [t2.a], [t2.b]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
同时,OcenaBase 数据库也提供了 HINT 机制 `/*+ USE_HASH(table_name_list) */` 去控制多表联接的时候选择 HASH JOIN 联接算法。例如下述场景中联接算法选择的是 MERGE JOIN,而用户希望使用 HASH JOIN,则可以使用上述 HINT 进行控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.31 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.33 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |MERGE JOIN | |100001 |219005|
|
||||
|1 | TABLE SCAN|T1 |100000 |61860 |
|
||||
|2 | TABLE SCAN|T2 |100000 |61860 |
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_HASH(t1, t2)*/ * FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |HASH JOIN | |100001 |495180|
|
||||
|1 | TABLE SCAN|T1 |100000 |61860 |
|
||||
|2 | TABLE SCAN|T2 |100000 |61860 |
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,127 @@
|
||||
联接顺序
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
在多表联接的场景中,优化器的一个很重要的任务是决定各个表之间的联接顺序(Join Order),因为不同的联接顺序会影响中间结果集的大小,进而影响到计划整体的执行代价。
|
||||
|
||||
为了减少执行计划的搜索空间和计划执行的内存占用,OceanBase 数据库优化器在生成联接顺序时主要考虑左深树的联接形式。下图展示了左深树、右深树和多支树的计划形状。
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库联接顺序的生成采用了 System-R 的动态规划算法,考虑的因素包括每一个表可能的访问路径、Interesting Order、联接算法(NESTED-LOOP、BLOCK-BASED NESTED-LOOP 或者 SORT-MERGE 等)以及不同表之间的联接选择率等。
|
||||
|
||||
给定 N 个表的联接,OceanBase 数据库生成联接顺序的方法如下:
|
||||
|
||||
1. 为每一个基表生成访问路径,保留代价最小的访问路径以及有所有有 Interesting Order 的路径。一个路径 如果具有 Interesting Order,它的序能够被后续的算子使用。
|
||||
|
||||
|
||||
|
||||
2. 生成所有表集合的大小为 `i (1 < i <= N)` 的计划。 OceanBase 数据库一般只考虑左深树,表集合大小为 i 的计划可以由一个表集合大小为 i 的计划和一个基表的计划组成。OceanBase 数据库按照这种策略,考虑了所有的联接算法以及 Interesting Order 的继承等因素把所有表集合大小为 i 的计划生成。这里也只是保留代价最小的计划以及所有具有 Interesting Order 的计划。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
同时,OceanBase 数据库提供了 HINT 机制 `/*+LEADING(table_name_list)*/`去控制多表联接的顺序。
|
||||
|
||||
如下例所示,开始选择的联接顺序是先做 t1、t2 的 JOIN 联接,然后再和 t3 做 JOIN 联接;如果用户希望先做 t2、t3 的 JOIN 联接,然后再和 t1做 JOIN 联接,则可以使用 HINT `/*+LEADING(t2,t3,t1)*/`去控制;如果用户希望先做 t1、t3 的 JOIN 联接,然后再和 t2 做 JOIN 联接,则可以使用 HINT `/*+LEADING(t1,t3,t2)*/`去控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.31 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.33 sec)
|
||||
|
||||
obclient>CREATE TABLE t3(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.44 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2,t3 WHERE t1.c1 = t2.c2 AND t2.c1 = t3.c2;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| =======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
---------------------------------------
|
||||
|0 |HASH JOIN | |98010 |926122|
|
||||
|1 | TABLE SCAN |T3 |100000 |61860 |
|
||||
|2 | HASH JOIN | |99000 |494503|
|
||||
|3 | TABLE SCAN|T1 |100000 |61860 |
|
||||
|4 | TABLE SCAN|T2 |100000 |61860 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T2.C1 = T3.C2]), other_conds(nil)
|
||||
1 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
2 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C2]), other_conds(nil)
|
||||
3 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
4 - output([T2.C2], [T2.C1]), filter(nil),
|
||||
access([T2.C2], [T2.C1]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+LEADING(t2,t3,t1)*/* FROM t1,t2,t3 WHERE t1.c1 = t2.c2
|
||||
AND t2.c1 = t3.c2;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |HASH JOIN | |98010 |1096613|
|
||||
|1 | HASH JOIN | |99000 |494503 |
|
||||
|2 | TABLE SCAN|T2 |100000 |61860 |
|
||||
|3 | TABLE SCAN|T3 |100000 |61860 |
|
||||
|4 | TABLE SCAN |T1 |100000 |61860 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C2]), other_conds(nil)
|
||||
1 - output([T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T2.C1 = T3.C2]), other_conds(nil)
|
||||
2 - output([T2.C2], [T2.C1]), filter(nil),
|
||||
access([T2.C2], [T2.C1]), partitions(p0)
|
||||
3 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
4 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+LEADING(t1,t3,t2)*/* FROM t1,t2,t3 WHERE t1.c1 = t2.c2
|
||||
AND t2.c1 = t3.c2;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| =============================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS |COST |
|
||||
-------------------------------------------------------------
|
||||
|0 |HASH JOIN | |98010 |53098071243|
|
||||
|1 | NESTED-LOOP JOIN CARTESIAN| |10000000000|7964490204 |
|
||||
|2 | TABLE SCAN |T1 |100000 |61860 |
|
||||
|3 | MATERIAL | |100000 |236426 |
|
||||
|4 | TABLE SCAN |T3 |100000 |61860 |
|
||||
|5 | TABLE SCAN |T2 |100000 |61860 |
|
||||
=============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C2], [T2.C1 = T3.C2]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
3 - output([T3.C1], [T3.C2]), filter(nil)
|
||||
4 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
5 - output([T2.C2], [T2.C1]), filter(nil),
|
||||
access([T2.C2], [T2.C1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,461 @@
|
||||
Optimizer Hint
|
||||
===================================
|
||||
|
||||
HINT 机制可以使优化器生成某种特定的计划。
|
||||
|
||||
一般情况下,优化器会为用户查询选择最佳的执行计划,不需要用户使用 HINT 指定,但在某些场景下,优化器生成的执行计划可能不满足用户的要求,这时就需要用户使用 HINT 来指定生成某种执行计划。
|
||||
|
||||
HINT 语法
|
||||
----------------
|
||||
|
||||
HINT 从语法上看是一种特殊的 SQL 注释,所不同的是在注释的左标记后('/\*' 符号)增加了一个"+"。 既然是注释,如果服务器端无法识别 SQL 语句中的 HINT,优化器会选择忽略用户 HINT 而使用默认的计划生成逻辑结构。另外,HINT 只影响优化器生成计划的逻辑结构,而不影响 SQL 语句的语义。
|
||||
|
||||
```javascript
|
||||
{DELETE|INSERT|SELECT|UPDATE|REPLACE} /*+ [hint_text] [hin_text]... */
|
||||
*<span data-type="background" style="background-color: rgb(191, 191, 191);"></span>*
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
如果使用 MySQL 的 C 客户端执行带 HINT 的 SQL 语句,需要使用 -c 选项登陆,否则 MySQL 客户端会将 HINT 作为注释从用户 SQL 中去除,导致系统无法收到用户 HINT。
|
||||
|
||||
#### **HINT 参数**
|
||||
|
||||
HINT 相关参数名称、语义和语法如下表:
|
||||
|
||||
|
||||
| **名称** | **语法** | **语义** |
|
||||
|-----------------------------|------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| NO_REWRITE | NO_REWRITE | 禁止 SQL 改写。 |
|
||||
| READ_CONSISTENCY | READ_CONSISTENCY (WEAK\[STRONGFROZEN\]) | 读一致性设置(弱/强)。 |
|
||||
| INDEX_HINT | /\*+ INDEX(table_name index_name) \*/ | 设置表索引。 |
|
||||
| QUERY_TIMEOUT | QUERY_TIMEOUT(INTNUM) | 设置超时时间。 |
|
||||
| LOG_LEVEL | LOG_LEVEL(\['\]log_level\['\]) | 设置日志级别,当设置模块级别语句时候,以第一个单引号(')作为开始,第二个单引号(')作为结束;例如'DEBUG'。 |
|
||||
| LEADING | LEADING(\[qb_name\] TBL_NAME_LIST) | 设置联接顺序。 |
|
||||
| ORDERED | ORDERED | 设置按照 SQL 中的顺序进行联接。 |
|
||||
| FULL | FULL(\[qb_name\] TBL_NAME) | 设置表访问路径为主表等价于 INDEX(TBL_NAME PRIMARY)。 |
|
||||
| USE_PLAN_CACHE | USE_PLAN_CACHE(NONE\[DEFAULT\]) | 设置是否使用计划缓存: * NONE:表示不使用计划缓存 * DEFAULT:表示按照其他变量进行设置 |
|
||||
| ACTIVATE_BURIED_POINT | ACTIVATE_BURIED_POINT(INTNUM, \[FIX_MOD \| BEFORE_MODE\], INTNUM, \[INTNUM \| -INTNUM\]) | 调试用,触发内部设定的错误点。 |
|
||||
| USE_MERGE | USE_MERGE(\[qb_name\] TBL_NAME_LIST) | 设置指定表在作为右表的时候使用 MERGE JOIN。 |
|
||||
| USE_HASH | USE_HASH(\[qb_name\] TBL_NAME_LIST) | 设置指定表在作为右表的时候使用 HASH JOIN。 |
|
||||
| NO_USE_HASH | NO_USE_HASH(\[qb_name\] TBL_NAME_LIST) | 设置指定表在作为右表的时候不使用 HASH JOIN。 |
|
||||
| USE_NL | USE_NL(\[qb_name\] TBL_NAME_LIST) | 设置指定表在作为右表的时候使用 NESTED LOOP JOIN。 |
|
||||
| USE_BNL | USE_BNL(\[qb_name\] TBL_NAME_LIST) | 设置指定表在作为右表的时候使用 NESTED LOOP BLOCK JOIN |
|
||||
| USE_HASH_AGGREGATION | USE_HASH_AGGREGATION(\[qb_name\]) | 设置 aggregate 方法为使用 HASH AGGREGATE。例如 HASH GROUP BY 或者 HASH DISTINCT。 |
|
||||
| NO_USE_HASH_AGGREGATION | NO_USE_HASH_AGGREGATION(\[qb_name\]) | 设置 aggregate 方法不使用 HASH AGGREGATE,使用 MERGE GROUP BY 或者MERGE DISTINCT。 |
|
||||
| USE_LATE_MATERIALIZATION | USE_LATE_MATERIALIZATION | 设置使用晚期物化。 |
|
||||
| NO_USE_LATE_MATERIALIZATION | NO_USE_LATE_MATERIALIZATION | 设置不使用晚期物化。 |
|
||||
| TRACE_LOG | TRACE_LOG | 设置收集 trace 记录用于 SHOW TRACE 展示。 |
|
||||
| QB_NAME | QB_NAME( NAME ) | 设置 query block 的名称。 |
|
||||
| PARALLEL | PARALLEL(INTNUM) | 设置分布式执行并行度。 |
|
||||
| TOPK | TOPK(PRECISION MINIMUM_ROWS) | 设置模糊查询的精度和最小行数。其中 PRECSION 为整型,取值范围\[0, 100\],表示模糊查询的行数百分比;MINIMUM_ROWS 为最小返回行数。 |
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
* qb_name 语法是: `@NAME`
|
||||
|
||||
|
||||
|
||||
* TBL_NAME 语法是: `[db_name.]relation_name [qb_name]`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
QB_NAME 介绍
|
||||
-------------------
|
||||
|
||||
在 DML 语句中,每一个 query_block 都会有一个 QB_NAME(query block name),可以用户指定,也可以系统自动生成。在用户没有用 HINT 指定的 QB_NAME 的时候,系统会按照 SEL$1、SEL$2,UPD$1,DEL$1 方式从左到右(实际也是 Resolver 的解析顺序)依次生成。
|
||||
|
||||
通过 QB_NAME 可以精确定位每一个 table,也可以在一处地方指定任意 query block 的行为。在 TBL_NAME 中的 QB_NAME 用于定位 table,在 HINT 中最前面的 qb_name 用于定位 HINT 作用于哪一个 query_block。
|
||||
|
||||
如下例所示,按照默认规则,会为 SEL$1 中的 t 选择 t_c1 路径,为 SEL$2 中的 t 选择 PRIMARY(主表)访问。如果 SQL 通过 HINT 来指定 SEL$1 的 t 走主表,则 SEL$2 的 t 走索引。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t(c1 INT, c2 INT, KEY t_c1(c1));
|
||||
Query OK, 0 rows affected (0.31 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t , (SELECT * FROM t WHERE c2 = 1) ta
|
||||
WHERE t.c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
------------------------------------------------------------
|
||||
|0 |NESTED-LOOP INNER JOIN CARTESIAN| |1 |1895|
|
||||
|1 | TABLE SCAN |t(t_c1)|1 |472 |
|
||||
|2 | TABLE SCAN |t |1 |1397|
|
||||
============================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t.c1], [t.c2], [t.c1], [t.c2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
1 - output([t.c1], [t.c2]), filter(nil),
|
||||
access([t.c1], [t.c2]), partitions(p0)
|
||||
2 - output([t.c2], [t.c1]), filter([t.c2 = 1]),
|
||||
access([t.c2], [t.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
因为改写后,SEL$2 被提升到 SEL$1 所以这里不用指定 HINT 作用的 query block。
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT/*+INDEX(t@SEL$1 PRIMARY) INDEX(t@SEL$2 t_c1)*/ *
|
||||
FROM t , (SELECT * FROM t WHERE c2 = 1) ta WHERE t.c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
=============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
-------------------------------------------------------------
|
||||
|0 |NESTED-LOOP INNER JOIN CARTESIAN| |1 |16166|
|
||||
|1 | TABLE SCAN |t |1 |1397 |
|
||||
|2 | TABLE SCAN |t(t_c1)|1 |14743|
|
||||
=============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t.c1], [t.c2], [t.c1], [t.c2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
1 - output([t.c1], [t.c2]), filter([t.c1 = 1]),
|
||||
access([t.c1], [t.c2]), partitions(p0)
|
||||
2 - output([t.c2], [t.c1]), filter([t.c2 = 1]),
|
||||
access([t.c2], [t.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
此例中 SQL 也可以写成如下方式:
|
||||
|
||||
```javascript
|
||||
obclient>SELECT/*+INDEX(t@SEL$1 PRIMARY) INDEX(@SEL$2 t@SEL$2 t_c1)*/ * FROM t ,
|
||||
(SELECT * FROM t WHERE c2 = 1) ta WHERE t.c1 = 1\G;
|
||||
<==>
|
||||
obclient>SELECT/*+INDEX(t@SEL$1 PRIMARY)*/ * from t , (SELECT/*+INDEX(t@SEL$2 t_c1)*/ * from t
|
||||
WHERE c2 = 1) ta WHERE t.c1 = 1\G;
|
||||
<==>
|
||||
obclient>SELECT/*+INDEX(@SEL$1 t@SEL$1 PRIMARY) INDEX(@SEL$2 t@SEL$2 t_c1)*/ * from t ,
|
||||
(SELECT * FROM t WHERE c2 = 1) ta WHERE t.c1 = 1\G;
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于 HINT 可以通过 `EXPLAIN EXTENDED` 查看 Outline Data 来学习。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN EXTENDED SELECT *
|
||||
FROM t , (SELECT *
|
||||
FROM t WHERE c2 = 1) ta
|
||||
WHERE t.c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
------------------------------------------------------------
|
||||
|0 |NESTED-LOOP INNER JOIN CARTESIAN| |1 |1895|
|
||||
|1 | TABLE SCAN |t(t_c1)|1 |472 |
|
||||
|2 | TABLE SCAN |t |1 |1397|
|
||||
============================================================
|
||||
Used Hint:
|
||||
-------------------------------------
|
||||
/*+
|
||||
*/
|
||||
|
||||
Outline Data:
|
||||
-------------------------------------
|
||||
/*+
|
||||
BEGIN_OUTLINE_DATA
|
||||
USE_NL(@"SEL$1" "test.t"@"SEL$2")
|
||||
LEADING(@"SEL$1" "test.t"@"SEL$1" "test.t"@"SEL$2")
|
||||
INDEX(@"SEL$1" "test.t"@"SEL$1" "t_c1")
|
||||
FULL(@"SEL$2" "test.t"@"SEL$2")
|
||||
END_OUTLINE_DATA
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
HINT 一般规则
|
||||
------------------
|
||||
|
||||
* 对于没有指定 query block 的 HINT 代表作用在本 query block。如下例所示,由于 t1 在 query block 2,同时无法改写提升到 query block 1,所以 HINT 无法生效。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT, INDEX t1_c1(c1), INDEX
|
||||
t1_c2(c2));
|
||||
Query OK, 0 rows affected (0.31 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT/*+INDEX(t1 t1_c2)*/ * FROM t,
|
||||
(SELECT * FROM t1 GROUP BY c1) ta WHERE t.c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
------------------------------------------------------------
|
||||
|0 |NESTED-LOOP INNER JOIN CARTESIAN| |666 |5906|
|
||||
|1 | TABLE SCAN |t(t_c1)|1 |472 |
|
||||
|2 | SUBPLAN SCAN |ta |666 |5120|
|
||||
|3 | HASH GROUP BY | |666 |4454|
|
||||
|4 | TABLE SCAN |t1 |1000 |1397|
|
||||
============================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t.c1], [t.c2], [ta.c1], [ta.c2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
1 - output([t.c1], [t.c2]), filter(nil),
|
||||
access([t.c1], [t.c2]), partitions(p0)
|
||||
2 -
|
||||
output([ta.c1], [ta.c2]), filter(nil),
|
||||
access([ta.c1], [ta.c2])
|
||||
4 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
group([t1.c1]), agg_func(nil)
|
||||
5 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
如下例所示,SQL 可以发生改写,t1 提升到 SEL$1,则 HINT 生效。
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN SELECT/*+INDEX(t1 t1_c2)*/ * FROM t,
|
||||
(SELECT * FROM t1) ta WHERE t.c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
---------------------------------------------------------------
|
||||
|0 |NESTED-LOOP INNER JOIN CARTESIAN| |1000 |15674|
|
||||
|1 | TABLE SCAN |t(t_c1) |1 |472 |
|
||||
|2 | TABLE SCAN |t1(t1_c2)|1000 |14743|
|
||||
===============================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t.c1], [t.c2], [t1.c1], [t1.c2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
1 - output([t1.c1], [t1.c2]), filter(nil),
|
||||
access([t1.c1], [t1.c2]), partitions(p0)
|
||||
2 -
|
||||
output([t.c1], [t.c2]), filter(nil),
|
||||
access([t.c1], [t.c2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 如果指定 table 行为,但在本 query block 中没有找到该 table,或者发生冲突,那么 HINT 无效。
|
||||
|
||||
对于没有找到 table 的 case 可以参考规则 1 中的第一个示例。以下示例为同时找到两个冲突的情况:
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN EXTENDED SELECT/*+INDEX(t PRIMARY)*/ *
|
||||
FROM t , (SELECT * FROM t WHERE c1 = 1) ta
|
||||
WHERE t.c1 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
------------------------------------------------------------
|
||||
|0 |NESTED-LOOP INNER JOIN CARTESIAN| |1 |970 |
|
||||
|1 | TABLE SCAN |t(t_c1)|1 |472 |
|
||||
|2 | TABLE SCAN |t(t_c1)|1 |472 |
|
||||
============================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t.c1(0x7f7b7cdd3e60)], [t.c2(0x7f7b7cdd40f0)], [t.c1(0x7f7b7cdd2bd0)], [t.c2(0x7f7b7cdd2e60)]), filter(nil),
|
||||
conds(nil), nl_params_(nil), inner_get=false, self_join=false, batch_join=false
|
||||
1 - output([t.c1(0x7f7b7cdd3e60)], [t.c2(0x7f7b7cdd40f0)]), filter(nil),
|
||||
access([t.c1(0x7f7b7cdd3e60)], [t.c2(0x7f7b7cdd40f0)]), partitions(p0),
|
||||
is_index_back=true,
|
||||
range_key([t.c1(0x7f7b7cdd3e60)], [t.__pk_increment(0x7f7b7cde86e0)]), range(1,MIN ; 1,MAX),
|
||||
range_cond([t.c1(0x7f7b7cdd3e60) = 1(0x7f7b7cdd3800)])
|
||||
2 -
|
||||
output([t.c1(0x7f7b7cdd2bd0)], [t.c2(0x7f7b7cdd2e60)]), filter(nil),
|
||||
access([t.c1(0x7f7b7cdd2bd0)], [t.c2(0x7f7b7cdd2e60)]), partitions(p0),
|
||||
is_index_back=true,
|
||||
range_key([t.c1(0x7f7b7cdd2bd0)], [t.__pk_increment(0x7f7b7cdf41b0)]), range(1,MIN ; 1,MAX),
|
||||
range_cond([t.c1(0x7f7b7cdd2bd0) = 1(0x7f7b7cdd2570)])
|
||||
|
||||
Used Hint:
|
||||
-------------------------------------
|
||||
/*+
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 联接方法的 HINT 中指定的 table 如果找不到,忽略该 table,其他的指定依然生效;如果优化器不能生成指定的联接方法,就会选择其他方法,HINT 无效。
|
||||
|
||||
|
||||
|
||||
* 联接顺序的 HINT 中如果存在 table 无法找到,则该 HINT 完全失效。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
HINT 主要语法
|
||||
------------------
|
||||
|
||||
与其他数据库的行为相比,OceanBase 数据库优化器是动态规划的,已经考虑了所有可能的最优路径,HINT 主要作用是指定优化器的行为,并按照 HINT 执行。
|
||||
|
||||
#### **INDEX HINT**
|
||||
|
||||
INDEX HINT 的语法同时支持 MySQL 和 Oracle 方式。
|
||||
|
||||
* INDEX HINT 的 Oracle 语法如下:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
obclient> SELECT/*+INDEX(table_name index_name) */ * FROM table_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* INDEX HINT 的 MySQL 语法如下:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```javascript
|
||||
tbl_name [[AS] alias] [index_hint_list]
|
||||
|
||||
index_hint_list:
|
||||
index_hint [, index_hint] ...
|
||||
|
||||
index_hint:
|
||||
USE {INDEX|KEY}
|
||||
[FOR {JOIN|ORDER BY|GROUP BY}] ([index_list])
|
||||
| IGNORE {INDEX|KEY}
|
||||
[FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
|
||||
| FORCE {INDEX|KEY}
|
||||
[FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
|
||||
|
||||
index_list:
|
||||
index_name [, index_name] ...
|
||||
```
|
||||
|
||||
|
||||
|
||||
Oracle 语法中一个表只能指定一个 INDEX,MySQL 语法可以指定多个。但是 OceanBase 数据库中 MySQL 语法虽然支持指定多个,但是对于 USE 和 FORCE,只会用第一个 INDEX 生成 PATH,即使 SQL 语句中没有该 INDEX 的 filter 而导致全部扫描同时回表(即 OceanBase 数据库当前设计是认为写 HINT 的人比程序更明白那条路径是更好的)。IGNORE 类型会忽略所有指定的 INDEX。USE、 FORCE 和 Oracle HINT 方式实际是一样的,该方式的 INDEX 不存在或者处于 invalid 状态,则 HINT 无效。对于 IGNORE 方式,如果将包括主表 (primary) 在内的所有 INDEX 忽略,则 HINT 无效。
|
||||
|
||||
#### **FULL HINT**
|
||||
|
||||
FULL HINT 的语法是用于指定表使用主表扫描,语法如下:
|
||||
|
||||
`/*+ FULL(table_name)*/`
|
||||
|
||||
FULL HINT 用于指定表选择主表扫描等价于 INDEX HINT `/*+ INDEX(table_name PRIMARY)*/`。
|
||||
|
||||
#### **ORDERED HINT**
|
||||
|
||||
ORDERED HINT 可以指定按照 from 后面的表的顺序作为联接顺序,语法如下:
|
||||
|
||||
`/*+ ORDERED*/`
|
||||
|
||||
如果指定该 HINT 后发生改写,那么就按照改写后的 stmt 中 from items 的顺序联接,因为改写时候 sub_query 会在 from items 中对应位置填放新的 table item。
|
||||
|
||||
#### **LEADING HINT**
|
||||
|
||||
LEADING HINT 可以指定表的联接顺序,语法如下:
|
||||
|
||||
`/*+ LEADING(table_name_list)*/`
|
||||
|
||||
table_name_list 中 table_name 比较特殊,其他 table_name 语法如下:
|
||||
|
||||
```javascript
|
||||
db_name . relation_name
|
||||
|
||||
relation_name
|
||||
|
||||
.relation_name
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 table_name_list 中 table_name 语法如下:
|
||||
|
||||
```javascript
|
||||
db_name . relation_name
|
||||
|
||||
relation_name
|
||||
```
|
||||
|
||||
|
||||
|
||||
table_name_list 语法如下:
|
||||
|
||||
```javascript
|
||||
table_name
|
||||
table_name_list table_name
|
||||
table_name_list, table_name
|
||||
```
|
||||
|
||||
|
||||
|
||||
LEADING HINT 为确保按照用户指定的顺序联接检查比较严格,如果发现 HINT 指定的 table_name 不存在,LEADING HINT 失效;如果发现 HINT 中存在重复 table,LEADING HINT 失效。如果在 optimizer 联接期间,按 table_id 无法在 from items 中找到对应的,即可能发生改写,那么该 table 及后面的 table 指定的 JOIN 序失效,前面的依然有效。
|
||||
|
||||
#### **Use_merge**
|
||||
|
||||
可以指定表在 JOIN 时候使用 merge-join 算法,语法为:`/*+ USE_MERGE(table_name_list) */`
|
||||
|
||||
使用 merge-join 将 use_merge 指定的表作为右表。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库中 merge-join 必须有等值条件的 join-condition,因此无等值条件的两个表联接,use_merge 会无效。
|
||||
|
||||
关于 merge-join 是否认为 A merge-join B 等效于 B merge-join A 当前并没有最后结论。按照代价模型,merge-join 计算代价时是区分左右表的。同时考虑到区分左右表可以增加 HINT 灵活性,当前 merge-join 区分左右表,即 use_merge 仅对表作为右表的时候生效。
|
||||
|
||||
#### **Use_nl**
|
||||
|
||||
指定表作为右表在联接的时候使用 NESTED LOOP JOIN 算法,语法如下:
|
||||
|
||||
`/*+ USE_NL(table_name_list) */`
|
||||
|
||||
#### **Use_hash**
|
||||
|
||||
指定表作为右表在联接的时候使用 HASH JOIN 算法,语法如下:
|
||||
|
||||
`/*+ USE_HASH(table_name_list) */`
|
||||
|
||||
#### **Parallel**
|
||||
|
||||
指定语句级别的并发度。当该 HINT 指定时,会忽略系统变量 `ob_stmt_parallel_degree` 的设置。语法如下:
|
||||
|
||||
`/*+ PARALLEL(4) */`
|
||||
@ -0,0 +1,352 @@
|
||||
计划绑定
|
||||
=========================
|
||||
|
||||
在系统上线前,可以直接在 SQL 语句中添加 Hint,控制优化器按 Hint 指定的行为进行计划生成。
|
||||
|
||||
但对于已上线的业务,如果出现优化器选择的计划不够优化时,则需要在线进行计划绑定,即无需业务进行 SQL 更改,而是通过 DDL 操作将一组 Hint 加入到 SQL 中,从而使优化器根据指定的一组 Hint,对该 SQL 生成更优计划。该组 Hint 称为 Outline,通过对某条 SQL 创建 Outline 可实现计划绑定。
|
||||
|
||||
Outline 视图-gv$outline
|
||||
------------------------------
|
||||
|
||||
Outline 视图为 gv$outline,其参数说明如下:
|
||||
|
||||
|
||||
| **字段名称** | **类型** | **描述** |
|
||||
|-------------------|----------------|-----------------------------------------|
|
||||
| tenant_id | bigint(20) | 租户 ID。 |
|
||||
| database_id | bigint(20) | 数据库 ID。 |
|
||||
| outline_id | bigint(20) | Outline ID。 |
|
||||
| database_name | varchar(128) | 数据库名称。 |
|
||||
| outline_name | varchar(128) | Outline 名称。 |
|
||||
| visible_signature | varchar(32768) | Signature 的反序列化结果,为了便于查看 Signature 的信息。 |
|
||||
| sql_text | varchar(32768) | 创建 Outline 时,在 `on clause` 中指定的 SQL。 |
|
||||
| outline_target | varchar(32768) | 创建 Outline 时,在 `to clause` 中指定的 SQL。 |
|
||||
| outline_sql | varchar(32768) | 具有完整 Outline 信息的 SQL。 |
|
||||
|
||||
|
||||
|
||||
创建 OUTLINE
|
||||
-------------------
|
||||
|
||||
OceanBase 数据库支持通过两种方式创建 Outline,一种是通过 SQL_TEXT (用户执行的带参数的原始语句),另一种是通过 SQL_ID 创建。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
创建 Outline 需要进入对应的数据库下执行。
|
||||
|
||||
#### **使用 SQL_TEXT 创建** Outline
|
||||
|
||||
使用 SQL_TEXT 创建 Outline 后,会生成一个 Key-Value 对存储在 Map 中,其中 Key 为绑定的 SQL 参数化后的文本,Value 为绑定的 Hint。具体参数化原则,请参见 **快速参数化的** 约束条件内容。
|
||||
|
||||
使用 SQL_TEXT 创建 Outline 的语法如下:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE [OR REPLACE] OUTLINE <outline_name> ON <stmt> [ TO <target_stmt> ];
|
||||
```
|
||||
|
||||
|
||||
|
||||
说明如下:
|
||||
|
||||
* 指定 `OR REPLACE` 后,可以对已经存在执行计划进行替换。
|
||||
|
||||
|
||||
|
||||
* 其中 `stmt` 一般为一个带有 Hint 和原始参数的 DML 语句。
|
||||
|
||||
|
||||
|
||||
* 如果不指定 `TO target_stmt`, 则表示如果数据库接受的 SQL 参数化后与 stmt 去掉 Hint 参数化文本相同,则将该 SQL 绑定 `stmt` 中 Hint 生成执行计划。
|
||||
|
||||
|
||||
|
||||
* 如果期望对含有 Hint 的语句进行固定计划,则需要 `TO target_stmt` 来指明原始的 SQL。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
在使用 `target_stmt` 时,严格要求 `stmt` 与 `target_stmt` 在去掉 Hint 后完全匹配。
|
||||
|
||||
示例如下:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 INT, c3 INT, INDEX idx_c2(c2));
|
||||
Query OK, 0 rows affected (0.12 sec)
|
||||
|
||||
obclient> INSERT INTO t1 VALUES(1, 1, 1), (2, 2, 2), (3, 3, 3);
|
||||
Query OK, 1 rows affected (0.12 sec)
|
||||
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE c2 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1 |37 |
|
||||
===================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = 1]),
|
||||
access([t1.c2], [t1.c1], [t1.c3]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
优化器选择了走主键扫描,如果数据量增大,如果执行索引 idx_c2,该 SQL 会更优化。此时可以通过创建 Outline 将该 SQL 绑定索引计划并执行。
|
||||
|
||||
根据如下 SQL 语句,创建 Outline:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE OUTLINE otl_idx_c2
|
||||
ON SELECT/*+ INDEX(t1 idx_c2)*/ * FROM t1 WHERE c2 = 1;
|
||||
Query OK, 0 rows affected (0.04 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### **使用 SQL_ID 创建 O** utline
|
||||
|
||||
使用 SQL_ID 创建 Outline 的语法如下:
|
||||
|
||||
|
||||
|
||||
```unknow
|
||||
obclient>CREATE OUTLINE outline_name ON sql_id USING HINT hint_text;
|
||||
```
|
||||
|
||||
|
||||
|
||||
说明如下:
|
||||
|
||||
* `sql_id` 为需要绑定的 SQL 对应的 `sql_id`。`sql_id` 可通过以下方式获取:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
|
||||
使用 `sql_id` 绑定 Outline,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>CREATE OUTLINE otl_idx_c2 ON "ED570339F2C856BA96008A29EDF04C74"
|
||||
USING HINT /*+ INDEX(t1 idx_c2)*/ ;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
* Hint 格式为` /*+ xxx */`,关于 Hint 说明的详细信息,请参考 [Optimizer Hint。](../../../12.sql-optimization-guide-1/4.sql-optimization-1/6.manage-execution-plans-1/1.optimizer-hint-1.md)
|
||||
|
||||
|
||||
|
||||
* 使用 SQL_TEXT 方式创建的 Outline 会覆盖 `sql_id` 方式创建的 Outline。SQL_TEXT 方式创建的优先级更高。
|
||||
|
||||
|
||||
|
||||
* 如果 `sql_id` 对应的 SQL 语句已经有 Hint,则创建 Outline 指定的 Hint 会覆盖原始语句中所有 Hint。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Outline Data是优化器为了完全复现某一计划而生成的一组 Hint 信息,以`BEGIN_OUTLINE_DATA`开始,并以 `END_OUTLINE_DATA`结束。
|
||||
|
||||
Outline Data 可以通过 `EXPLAIN EXTENDED` 命令获得,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient>EXPLAIN EXTENDED SELECT/*+ index(t1 idx_c2)*/ * FROM t1 WHERE c2 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-----------------------------------------
|
||||
|0 |TABLE SCAN|t1(idx_c2)|1 |88 |
|
||||
=========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1(0x7ff95ab37448)], [t1.c2(0x7ff95ab33090)], [t1.c3(0x7ff95ab377f0)]), filter(nil),
|
||||
access([t1.c2(0x7ff95ab33090)], [t1.c1(0x7ff95ab37448)], [t1.c3(0x7ff95ab377f0)]), partitions(p0),
|
||||
is_index_back=true,
|
||||
range_key([t1.c2(0x7ff95ab33090)], [t1.c1(0x7ff95ab37448)]), range(1,MIN ; 1,MAX),
|
||||
range_cond([t1.c2(0x7ff95ab33090) = 1(0x7ff95ab309f0)])
|
||||
|
||||
Used Hint:
|
||||
-------------------------------------
|
||||
/*+
|
||||
INDEX(@"SEL$1" "test.t1"@"SEL$1" "idx_c2")
|
||||
*/
|
||||
|
||||
Outline Data:
|
||||
-------------------------------------
|
||||
/*+
|
||||
BEGIN_OUTLINE_DATA
|
||||
INDEX(@"SEL$1" "test.t1"@"SEL$1" "idx_c2")
|
||||
END_OUTLINE_DATA
|
||||
*/
|
||||
|
||||
Plan Type:
|
||||
-------------------------------------
|
||||
LOCAL
|
||||
|
||||
Optimization Info:
|
||||
-------------------------------------
|
||||
|
||||
t1:table_rows:3, physical_range_rows:1, logical_range_rows:1, index_back_rows:1, output_rows:1, est_method:local_storage, optimization_method=cost_based, avaiable_index_name[idx_c2], pruned_index_name[t1]
|
||||
level 0:
|
||||
***********
|
||||
paths(@1101710651081553(ordering([t1.c2], [t1.c1]), cost=87.951827))
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中 Outline Data 信息如下例所示:
|
||||
|
||||
```javascript
|
||||
/*+
|
||||
BEGIN_OUTLINE_DATA
|
||||
INDEX(@"SEL$1" "test.t1"@"SEL$1" "idx_c2")
|
||||
END_OUTLINE_DATA
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
Outline Data 也是 Hint,因此可以用在计划绑定的过程中,如下例所示:
|
||||
|
||||
```javascript
|
||||
obclient> CREATE OUTLINE otl_idx_c2
|
||||
ON "ED570339F2C856BA96008A29EDF04C74"
|
||||
USING HINT /*+
|
||||
BEGIN_OUTLINE_DATA
|
||||
INDEX(@"SEL$1" "test.t1"@"SEL$1" "idx_c2")
|
||||
END_OUTLINE_DATA
|
||||
*/;
|
||||
Query OK, 0 rows affected (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
确定 Outline 创建生效
|
||||
------------------------
|
||||
|
||||
确定创建的 Outline 是否成功且符合预期,需要进行如下三步的验证:
|
||||
|
||||
1. 确定是否创建 Outline 成功。
|
||||
|
||||
通过查看 gv$outline 中的表,确认是否成功创建对应的 Outline 名称的 Outline。
|
||||
|
||||
```javascript
|
||||
obclient> SELECT * FROM oceanbase.gv$outline WHERE OUTLINE_NAME = 'otl_idx_c2'\G;
|
||||
|
||||
*************************** 1. row ***************************
|
||||
tenant_id: 1001
|
||||
database_id: 1100611139404776
|
||||
outline_id: 1100611139404777
|
||||
database_name: test
|
||||
outline_name: otl_idx_c2
|
||||
visible_signature: SELECT * FROM t1 WHERE c2 = ?
|
||||
sql_text: SELECT/*+ index(t1 idx_c2)*/ * FROM t1 WHERE c2 = 1
|
||||
outline_target:
|
||||
outline_sql: SELECT /*+ BEGIN_OUTLINE_DATA INDEX(@"SEL$1" "test.t1"@"SEL$1" "idx_c2") END_OUTLINE_DATA*/*
|
||||
FROM t1 WHERE c2 = 1
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
2. 确定新的 SQL 执行是否通过绑定的 Outline 生成了新计划。
|
||||
|
||||
当绑定 Outline 的 SQL 有新的流量查询后,查询 `gv$plan_cache_plan_stat` 表中该 SQL 对应的计划信息中 `outline_id`。如果 `outline_id` 是在 gv$outline 中查到的 `outline_id` 则表示该计划是按绑定的 Outline 生成的执行计划,否则不是。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT SQL_ID, PLAN_ID, STATEMENT, OUTLINE_ID, OUTLINE_DATA
|
||||
FROM oceanbase.gv$plan_cache_plan_stat
|
||||
WHERE STATEMENT LIKE '%SELECT * FROM t1 WHERE c2 =%'\G;
|
||||
*************************** 1. row ***************************
|
||||
sql_id: ED570339F2C856BA96008A29EDF04C74
|
||||
plan_id: 17225
|
||||
statement: SELECT * FROM t1 WHERE c2 = ?
|
||||
outline_id: 1100611139404777
|
||||
outline_data: /*+ BEGIN_OUTLINE_DATA INDEX(@"SEL$1" "test.t1"@"SEL$1" "idx_c2") END_OUTLINE_DATA*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
3. 确定生成的执行计划是否符合预期。
|
||||
|
||||
确定是通过绑定的 Outline 生成的计划后,需要确定生成的计划是否符合预期,可以通过查询`gv$plan_cache_plan_stat` 表查看 `plan_cache` 中缓存的执行计划形状,具体查看方式可参考
|
||||
|
||||
[实时执行计划展示](../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/5.real-time-execution-plan-display-3.md)。
|
||||
|
||||
```javascript
|
||||
obclient>SELECT OPERATOR, NAME FROM oceanbase.gv$plan_cache_plan_explain
|
||||
WHERE TENANT_ID = 1001 AND IP = '10.101.163.87'
|
||||
AND PORT = 30474 AND PLAN_ID = 17225;
|
||||
|
||||
+--------------------+------------+
|
||||
| OPERATOR | NAME |
|
||||
+--------------------+------------+
|
||||
| PHY_ROOT_TRANSMIT | NULL |
|
||||
| PHY_TABLE_SCAN | t1(idx_c2) |
|
||||
+--------------------+------------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
删除 Outline
|
||||
-------------------------------
|
||||
|
||||
删除 Outline 后,对应 SQL 重新生成计划时将不再依据绑定的 Outline 生成。删除 Outline 的语法如下:
|
||||
|
||||
```javascript
|
||||
DROP OUTLINE outline_name;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
删除 Outline 需要在 `outline_name` 中指定 Database 名,或者在 `USE DATABASE` 命令后执行。
|
||||
|
||||
计划绑定与执行计划缓存关系
|
||||
----------------------
|
||||
|
||||
* 使用 SQL_TEXT 创建 Outline 后,SQL 请求生成新计划查找 Outline 使用的 Key 与计划缓存使用的 Key 相同,均是 SQL 参数化后的文本串。
|
||||
|
||||
|
||||
|
||||
* 当创建和删除 Outline 后,对应 SQL 有新的请求时,会触发执行计划缓存中对应执行计划失效,更新为绑定的 Outline 生成的执行计划。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,192 @@
|
||||
执行计划管理
|
||||
===========================
|
||||
|
||||
SQL Plan Management(SPM)是一种稳定执行计划、控制计划演进的机制,确保新生成的计划在经过验证后才能使用,保证计划性能朝好的方向不断更新。
|
||||
|
||||
SPM 基于 SQL Plan Baseline 实现,SQL Plan Baseline 是执行计划的一个基线,持久化存储已经验证过的执行计划的信息(outline_data 等信息),每个执行计划可对应一个 Plan Baseline,通过该 Plan Baseline 可复现一个执行计划。
|
||||
|
||||
SPM 包含如下过程:
|
||||
|
||||
1. 计划捕获。
|
||||
|
||||
对于新生成的计划,如果 SQL Plan Baseline 为空,则直接加入 SQL Plan Baseline,否则通过演进验证新生成计划比 SQL Plan Baseline 中计划性能更优后加入 SQL Plan Baseline,并删除旧的 Plan Baseline。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
2. 计划演进。
|
||||
|
||||
相同 SQL 新捕获的计划如果和 SQL Plan Baseline 中计划不一样,则通过流量灰度验证新计划性能是否比以前验证过的计划更优。如果更优,则将新计划加入 SQL Plan Baseline,并执行新计划,否则仍使用旧计划。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
3. 计划选择。
|
||||
|
||||
在优化器新生成计划时,会查看 SQL Plan Baseline 是否有已验证的计划,如果有,则优先使用已验证计划,新计划需要通过演进验证后再使用。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
SPM 的系统变量
|
||||
------------------
|
||||
|
||||
SPM 使用如下系统变量和系统包对执行计划进行管理:
|
||||
|
||||
|
||||
| **系统变量** | **取值** | **解释** |
|
||||
|--------------------------------------|--------|---------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| optimizer_capture_sql_plan_baselines | true | 对于新生成的计划,如果该 SQL 没有对应的 Plan Baseline,则将该计划加入到 SQL Plan Baseline;如果已有 Plan Baseline 且与新计划不同,则会触发计划演进进行验证,确定是否需要将新计划替换老的 Plan Baseline。 |
|
||||
| optimizer_capture_sql_plan_baselines | false | 再自动捕获新计划到 Plan Baseline 中。 |
|
||||
| optimizer_use_sql_plan_baselines | true | 在新生成计划时,优化器会优先使用 Plan Baseline 计划,对于新的不同计划则验证后通过后才使用。 |
|
||||
| optimizer_use_sql_plan_baselines | false | 在新生成计划时,不在考虑 Plan Baseline 中计划,直接使用优化器新生成计划并执行。 |
|
||||
|
||||
|
||||
|
||||
设置说明如下:
|
||||
|
||||
|
||||
| **optimizer_capture_sql_plan_baselines 的取值** | **optimizer_use_sql_plan_baselines 的取值** | **说明** |
|
||||
|----------------------------------------------|------------------------------------------|-------------------------------------------------------------------------------------|
|
||||
| True | True | 计划捕获和演进均打开,优化器会使用 Plan Baseline 计划。 |
|
||||
| True | False | Plan Baseline 中无计划时会捕获计划到 Plan Baseline,不演进,优化器不考虑 Plan Baseline 计划,使用新生成计划。 |
|
||||
| False | True | 不捕获计划到 Plan Baseline, 优化器会使用 Plan Baseline 计划,如果 SQL Plan Baseline 没有对应计划,则使用新生成计划。 |
|
||||
| False | False | 不捕获计划,不演进,优化器不使用 Plan Baseline 计划,使用新生成的计划。 |
|
||||
|
||||
|
||||
|
||||
DBMS_SPM
|
||||
-----------------
|
||||
|
||||
DBMS_SPM 是用于操作 SPM 的命令包,可支持加载、更改以及删除 Plan Baseline 信息。
|
||||
|
||||
#### **LOAD_PLANS_FROM_CURSOR_CACHE**
|
||||
|
||||
LOAD_PLANS_FROM_CURSOR_CACHE 用于将 plan cache 中执行计划对应的 Plan Baseline 信息加载到 _ _all_tenant_plan_baseline 表中。语法如下:
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
_ _all_tenant_plan_baseline 为 OceanBase 数据库内部表。
|
||||
|
||||
```javascript
|
||||
DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE (
|
||||
sql_id IN VARCHAR2,
|
||||
plan_hash_value IN NUMBER := NULL,
|
||||
fixed IN VARCHAR2 := 'NO',
|
||||
enabled IN VARCHAR2 := 'YES')
|
||||
RETURN PLS_INTEGER;
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数解释如下:
|
||||
|
||||
|
||||
| 参数 | 解释 |
|
||||
|-----------------|-------------------------------------------------------------|
|
||||
| sql_id | SQL 的唯一标识。 |
|
||||
| plan_hash_value | plan 的唯一标识。如果为空,则处理 sql_id 下的所有计划。 |
|
||||
| fixed | 加入到 SQL Plan Baseline 后是否将该计划固化。固化后以后优化器会直接选择该计划,不再捕获和演进计划。 |
|
||||
| enabled | 优化器是否可以使用该 Plan Baseline。 |
|
||||
|
||||
|
||||
|
||||
如下例所示:
|
||||
|
||||
```javascript
|
||||
DECLARE
|
||||
v_load_plans number;
|
||||
BEGIN
|
||||
v_load_plans := DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE(
|
||||
sql_id => '529F6E6454EF579C7CC265D1F6131D70',
|
||||
plan_hash_value => 13388268709115914355);
|
||||
END;
|
||||
/
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### **ALTER_SQL_PLAN_BASELINE**
|
||||
|
||||
ALTER_SQL_PLAN_BASELINE 用于修改 Plan Baseline 中某些属性。语法如下:
|
||||
|
||||
```javascript
|
||||
DBMS_SPM.ALTER_SQL_PLAN_BASELINE (
|
||||
sql_handle IN VARCHAR2 := NULL,
|
||||
plan_name IN VARCHAR2 := NULL,
|
||||
attribute_name IN VARCHAR2,
|
||||
attribute_value IN VARCHAR2)
|
||||
RETURN PLS_INTEGER;
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数解释如下:
|
||||
|
||||
|
||||
| 参数 | 解释 |
|
||||
|-----------------|------------------------------------------------|
|
||||
| sql_handle | SQL 的唯一标识。先用 sql_id 代替。 |
|
||||
| plan_name | plan 的唯一标识。先使用 plan_hash_value 代替。 |
|
||||
| attribute_name | 需要更改的字段名。OceanBase 数据库支持修改 enabled 和 fixed 字段。 |
|
||||
| attribute_value | 更改后的值。 |
|
||||
|
||||
|
||||
|
||||
如下示例所示,将某个 Plan Baseline 固化后该 SQL 仅使用该计划:
|
||||
|
||||
```javascript
|
||||
DECLARE
|
||||
v_alter_plans number;
|
||||
BEGIN
|
||||
v_alter_plans := DBMS_SPM.ALTER_SQL_PLAN_BASELINE(
|
||||
sql_handle => '529F6E6454EF579C7CC265D1F6131D70',
|
||||
plan_name => '3388268709115914355',
|
||||
attribute_name => 'fixed',
|
||||
attribute_value => 'YES' );
|
||||
END;
|
||||
/
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### **DROP_SQL_PLAN_BASELINE**
|
||||
|
||||
DROP_SQL_PLAN_BASELINE 用于删掉某个 Plan Baseline。语法如下:
|
||||
|
||||
```javascript
|
||||
DBMS_SPM.DROP_SQL_PLAN_BASELINE (
|
||||
sql_handle IN VARCHAR2 := NULL,
|
||||
plan_name IN VARCHAR2 := NULL)
|
||||
RETURN PLS_INTEGER;
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例如下:
|
||||
|
||||
```javascript
|
||||
DECLARE
|
||||
v_drop_plans number;
|
||||
BEGIN
|
||||
v_drop_plans := DBMS_SPM.DROP_SQL_PLAN_BASELINE(
|
||||
sql_handle => '529F6E6454EF579C7CC265D1F6131D70',
|
||||
plan_name => '3388268709115914355' );
|
||||
END;
|
||||
/
|
||||
```
|
||||
|
||||
|
||||
|
||||
52
docs/docs-cn/12.sql-optimization-guide-1/5.related-terms.md
Normal file
52
docs/docs-cn/12.sql-optimization-guide-1/5.related-terms.md
Normal file
@ -0,0 +1,52 @@
|
||||
相关术语
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
**执行计划**
|
||||
|
||||
优化器为某条 SQL 生成的执行过程,一般使用操作符树来表示。
|
||||
|
||||
#### **本地计划**
|
||||
|
||||
当执行计划只涉及到单表或分区表的单个分区,且该表或分区在本节点时,该计划为"本地计划"。
|
||||
|
||||
#### **远程计划**
|
||||
|
||||
当执行计划只涉及到单表或分区表的单个分区,且该表或分区在其他节点时,该计划为"远程计划"。
|
||||
|
||||
#### **分布式计划**
|
||||
|
||||
当执行计划涉及到多表或多分区时,该计划为分布式计划。
|
||||
|
||||
#### **访问路径**
|
||||
|
||||
访问某张表时使用的访问方式,包括主表访问和二级索引访问两类。具体参见 [访问路径](../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/1.access-path-3/1.overview-16.md)。
|
||||
|
||||
#### **联接顺序**
|
||||
|
||||
多表联接时各表之间的联接顺序,目前 OceanBase 数据库仅支持左深树的联接顺序。具体参见 [联接顺序](../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/2.join-algorithm-5/3.join-order-3.md)。
|
||||
|
||||
#### **联接算法**
|
||||
|
||||
执行两表联接时使用的算法,包括 NESTED LOOP JOIN、MERGE JOIN 和 HASH JOIN 三种。
|
||||
|
||||
#### **查询改写**
|
||||
|
||||
通过对用户查询做等价的改写以便于生成最佳执行计划的过程。
|
||||
|
||||
#### **执行计划绑定**
|
||||
|
||||
用户通过给定 outline 来指定某条 SQL 的执行计划的过程,具体参见 [计划绑定](../12.sql-optimization-guide-1/4.sql-optimization-1/6.manage-execution-plans-1/2.plan-binding-1.md)。
|
||||
|
||||
#### **SQL Plan Management(** **SPM)**
|
||||
|
||||
一种计划演进的机制。当优化器生成新的计划时,需要通过演进机制来保证这个计划的性能不会出现回退,如果出现回退,就拒绝使用该计划,否则使用该计划。
|
||||
|
||||
#### **Adaptive Cursor Sharing(ACS)**
|
||||
|
||||
一种可以让优化器每一个参数化 SQL 存储多个计划,并根据 SQL 语句中谓词的选择率空间选择合适的计划的机制。
|
||||
|
||||
#### **Data Flow Object(DFO)**
|
||||
|
||||
分布式计划以数据重分布点为边界,切分为可以并行执行的逻辑子计划,每个子计划由一个 DFO 进行封装。
|
||||
@ -0,0 +1,56 @@
|
||||
SQL 调优常见问题
|
||||
===============================
|
||||
|
||||
|
||||
|
||||
用户 SQL 写法未遵循 OceanBase 数据库开发规范
|
||||
---------------------------------------------------
|
||||
|
||||
用户 SQL 的写法对 SQL 的执行性能有决定性的作用。在使用过程中,用户应尽量遵循 OceanBase 数据库开发规范的要求。
|
||||
|
||||
代价模型缺陷导致的执行计划选择错误
|
||||
--------------------------------------
|
||||
|
||||
OceanBase 数据库内建的代价模型是服务器的固有逻辑,最佳的执行计划依赖此代价模型。因此,一旦出现由代价模型导致的计划选择错误,用户只能通过执行计划绑定来确保选择"正确"的执行计划。
|
||||
|
||||
数据统计信息不准确
|
||||
------------------------------
|
||||
|
||||
查询优化过程依赖数据统计信息的准确性,OceanBase 数据库的优化器默认会在数据合并过程中收集一些统计信息,当用对数据进行了大量修改时,可能会导致统计信息落后于真实数据的特征,用户可以通过发起每日合并,主动更新统计信息。
|
||||
|
||||
除了优化器收集的统计信息以外,优化器还会根据查询条件对存储层进行采样,用以后续的优化选择。OceanBase 数据库目前仅支持对本地存储进行采样,对于数据分区在远程节点上的情况,只能使用默认收集的统计信息进行代价估计,可能会引入代价偏差。
|
||||
|
||||
数据库物理设计降低查询性能
|
||||
----------------------------------
|
||||
|
||||
查询的性能很大程度上取决于数据库的物理设计,包括所访问对象的 schema 信息等。例如,对于二级索引,如果所需的投影列没有包括在索引列之中,则需要使用回表的机制访问主表,查询的代价会增加很多。此时,可以考虑将用户的投影列加入到索引列中,构成所谓的"覆盖索引",避免回表访问。
|
||||
|
||||
系统负载影响单条 SQL 的响应时间
|
||||
---------------------------------------
|
||||
|
||||
系统的整体负载除了会影响系统的整体吞吐量,也会引起单条 SQL 的响应时间变化。OceanBase 数据库的 SQL 引擎采用队列模型,针对用户请求,如果可用线程全部被占用,则新的请求需要在请求队列中排队,直到某个线程完成当前请求。请求在队列中的排队时间可以在 (g)v$sql_audit 中看到。
|
||||
|
||||
客户端路由与服务器之间出现路由反馈逻辑错误
|
||||
------------------------------------------
|
||||
|
||||
OBProxy 的一个主要功能是将 SQL 查询路由到恰当的服务器节点。具体来说,如果用户查询没有指定使用弱一致性读属性,Proxy 需要将其路由到所涉及的表(或具体分区)的主节点上,以避免服务器节点之前的二次转发;否则,Proxy 会根据预先设置好的规则将其转发到恰当的节点。
|
||||
|
||||
由于 Proxy 与服务器之间采用松耦合的方式,Proxy 上缓存的数据物理分布信息刷新可能不及时,导致错误的路由选择。可能导致路由信息变化的场景有:
|
||||
|
||||
* 网络不稳导致服务器间重新选主
|
||||
|
||||
|
||||
|
||||
* 由服务器上下线、轮转合并等导致的重新选主
|
||||
|
||||
|
||||
|
||||
* 负载均衡导致重新选主
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当在 SQL audit 或执行计划缓存中发现有大量远程执行时,需要考虑是否与上述场景吻合。客户端与服务器之间有路由反馈逻辑,一旦发生错误,客户端会主动刷新数据物理分布信息,随后路由的选择也将恢复正常。
|
||||
|
||||
Reference in New Issue
Block a user