Move the docs folder
This commit is contained in:
committed by
 LINxiansheng
LINxiansheng
parent
7c6dcc6712
commit
d42f317422
@ -0,0 +1,11 @@
|
||||
概述
|
||||
=======================
|
||||
|
||||
数据库中的联接语句用于将数据库中的两个或多个表根据联接条件,把表的属性通过它们的值组合在一起。由"联接"生成的集合,可以被保存为表,或者当成表来使用。
|
||||
|
||||
不同方式的联接算法为 SQL 调优提供了更多的选择,可以使得 SQL 调优时能够根据表的数据特性选择合适的联接算法,从而让多表联接组合起来变得更加高效。
|
||||
|
||||
联接语句在数据库中由联接算法实现,主要的联接算法有 Nested Loop Join、Hash Join 和 Merge Join。由于三种算法在不同的场景下各有优劣,优化器会自主选择最佳联接算法。关于各算法的原理,请参见 [联接算法](../../../../12.sql-optimization-guide-1/4.sql-optimization-1/5.query-optimization-2/2.join-algorithm-5/2.join-algorithm-6.md)。
|
||||
|
||||
针对联接顺序及联接算法的选择,OceanBase 数据库也提供了相关 Hint 机制进行控制,以方便用户根据自身的实际需求去选择何种联接顺序及联接算法以进行多表联接。
|
||||
|
||||
@ -0,0 +1,446 @@
|
||||
联接算法
|
||||
=========================
|
||||
|
||||
OceanBase 数据库当前版本支持 Nested Loop Join、Hash Join 和 Merge Join 三种不同的联接算法。
|
||||
|
||||
Hash Join 和 Merge Join 只适用于等值的联接条件,Nested Loop Join 可用于任意的联接条件。
|
||||
|
||||
Nested Loop Join
|
||||
-------------------------
|
||||
|
||||
Nested Loop Join 原理是扫描一个表(外表),每读到该表中的一条记录,就去"扫描"另一张表(内表)找到满足条件的数据。
|
||||
|
||||
这里的"扫描"可以是利用索引快速定位扫描,也可以是全表扫描。通常来说,全表扫描的性能很差,所以如果联接条件的列上没有索引,优化器一般就不会选择 Nested Loop Join。在 OceanBase 数据库中,执行计划中展示了是否能够利用索引快速定位扫描。
|
||||
|
||||
如下例所示,第一个计划对于内表的扫描是全表扫描,因为联接条件是 `t1.c = t2.c`,而 `t2` 表没有在 `c` 列上的索引。第二个计划对于内表的扫描能够使用索引快速找到匹配的行,主要原因是联接条件为 `t1.b = t2.b`,而且 `t2` 表选择了创建在 `b` 列上的索引 `k1` 作为访问路径,这样对于 `t1` 表中的每一行的每个 `b` 值,`t2` 表都可以根据索引快速找到满足条件的匹配行。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.24 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT/*+USE_NL(t1 t2)*/ * FROM t1, t2
|
||||
WHERE t1.c = t2.c;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |1980 |623742|
|
||||
|1 | TABLE SCAN |t1 |1000 |455 |
|
||||
|2 | TABLE SCAN |t2 |2 |622 |
|
||||
===========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
conds(nil), nl_params_([t1.c])
|
||||
1 - output([t1.c], [t1.a], [t1.b]), filter(nil),
|
||||
access([t1.c], [t1.a], [t1.b]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.a]), range(MIN ; MAX)always true
|
||||
2 - output([t2.c], [t2.a], [t2.b]), filter([? = t2.c]),
|
||||
access([t2.c], [t2.a], [t2.b]), partitions(p0),
|
||||
is_index_back=false, filter_before_indexback[false],
|
||||
range_key([t2.a]), range(MIN ; MAX)
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT/*+USE_NL(t1 t2)*/ * FROM t1, t2
|
||||
WHERE t1.b = t2.b;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ============================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
--------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |1980 |94876|
|
||||
|1 | TABLE SCAN |t1 |1000 |455 |
|
||||
|2 | TABLE SCAN |t2(k1)|2 |94 |
|
||||
============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
conds(nil), nl_params_([t1.b])
|
||||
1 - output([t1.b], [t1.a], [t1.c]), filter(nil),
|
||||
access([t1.b], [t1.a], [t1.c]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.a]), range(MIN ; MAX)always true
|
||||
2 - output([t2.b], [t2.a], [t2.c]), filter(nil),
|
||||
access([t2.b], [t2.a], [t2.c]), partitions(p0),
|
||||
is_index_back=true,
|
||||
range_key([t2.b], [t2.a]), range(MIN ; MAX),
|
||||
range_cond([? = t2.b])
|
||||
```
|
||||
|
||||
|
||||
|
||||
Nested Loop Join 可能会对内表进行多次全表扫描,因为每次扫描都需要从存储层重新迭代一次,这个代价相对比较高,所以 OceanBase 数据库支持对内表进行一次扫描并把结果物化在内存中,这样在下一次执行扫描时就可以直接在内存中扫描相关的数据,而不需要从存储层进行多次扫描。但是物化在内存中的方式是有代价的,所以 OceanBase 数据库优化器是基于代价去判断是否需要物化内表。
|
||||
|
||||
Nested Loop Join 的一个优化变种是 Blocked Nested Loop Join,它每次从外表中读取一个块大小的行,然后再去扫描内表找到满足条件的数据,这样可以减少内表的读取次数。
|
||||
|
||||
Nested Loop Join 通常用在外表行数比较少,而且内表在联接条件的列上有索引的场景,因为内表中的每一行都可以快速的使用索引定位到相对应的匹配的数据。
|
||||
|
||||
同时,OceanBase 数据库也提供了 Hint 机制 `/*+ USE_NL(table_name_list) */` 去控制多表联接时选择 Nested Loop Join 算法。例如下述场景联接算法选择的是 Hash Join,而用户希望使用 Nested Loop Join,就可以使用上述 Hint 进行控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2 WHERE t1.c1 = t2.c1;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |HASH JOIN | |98010000 |66774608|
|
||||
|1 | TABLE SCAN|T1 |100000 |68478 |
|
||||
|2 | TABLE SCAN|T2 |100000 |68478 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_NL(t1, c2)*/* FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ===============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |98010000 |4595346207|
|
||||
|1 | TABLE SCAN |T1 |100000 |68478 |
|
||||
|2 | MATERIAL | |100000 |243044 |
|
||||
|3 | TABLE SCAN |T2 |100000 |68478 |
|
||||
===============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
conds([T1.C1 = T2.C1]), nl_params_(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil)
|
||||
3 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
Nested Loop Join 还有以下两种实现的算法:
|
||||
|
||||
* 缓存块嵌套循环联接(Blocked Nested Loop Join)
|
||||
|
||||
在 OceanBase 数据库中,Blocked Nested Loop Join 的实现方式是 Batch Nested Loop Join,即通过从外表中批量读取数据行(默认是 1000 行),然后再去扫描内表找到满足条件的数据。这样将批量的数据与内层表的数据进行匹配,减少了内表的读取次数和内层循环的次数。
|
||||
|
||||
如下示例中,`batch_join=true` 字段表示本次查询使用了 Batch Nested Loop Join。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT PRIMARY KEY);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>EXPLAIN EXTENDED_NOADDR SELECT /*+USE_NL(t1,t2)*/* FROM t1,t2
|
||||
WHERE t1.c1=t2.c1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |100001 |3728786|
|
||||
|1 | TABLE SCAN |t1 |100000 |59654 |
|
||||
|2 | TABLE GET |t2 |1 |36 |
|
||||
============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t2.c1]), filter(nil),
|
||||
conds(nil), nl_params_([t1.c1]), inner_get=false, self_join=false, batch_join=true
|
||||
1 - output([t1.c1]), filter(nil),
|
||||
access([t1.c1]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t1.c1]), range(MIN ; MAX)always true
|
||||
2 - output([t2.c1]), filter(nil),
|
||||
access([t2.c1]), partitions(p0),
|
||||
is_index_back=false,
|
||||
range_key([t2.c1]), range(MIN ; MAX),
|
||||
range_cond([? = t2.c1])
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 索引嵌套循环联接(Index Nested Loop Join)
|
||||
|
||||
Index Nested Loop Join 是基于索引进行联接的算法,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较,减少了对内层表的匹配次数。
|
||||
|
||||
如下示例中存在联接条件 `t1.c1 = t2.c1`,则在 `t2` 表的 `c1` 列上有索引或 `t1` 表的 `c1` 列上有索引的时候,会使用 Index Nested Loop Join 算法。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT ,c2 INT);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+ORDERED USE_NL(t2,t1)*/ * FROM t2,
|
||||
(SELECT /*+NO_MERGE*/ * FROM t1)t1
|
||||
WHERE t1.c1 = t2.c1 AND t2.c2 = 1\G;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
===========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-------------------------------------------
|
||||
|0 |NESTED-LOOP JOIN| |981 |117272|
|
||||
|1 | TABLE SCAN |t2 |990 |80811 |
|
||||
|2 | SUBPLAN SCAN |t1 |1 |37 |
|
||||
|3 | TABLE GET |t1 |1 |36 |
|
||||
===========================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t2.c1], [t2.c2], [t1.c1]), filter(nil), conds(nil), nl_params_([t2.c1])
|
||||
1 - output([t2.c1], [t2.c2]), filter([t2.c2 = 1]), access([t2.c1], [t2.c2]), partitions(p0)
|
||||
2 - output([t1.c1]), filter(nil), access([t1.c1])
|
||||
3 - output([t1.c1]), filter(nil), access([t1.c1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 `outputs & filters` 的输出结果中 `nl_param` 出现参数 `[t2.c1]`,说明执行了条件下压优化。详细信息请参考 [JOIN](../../../../12.sql-optimization-guide-1/2.sql-execution-plan-3/2.execution-plan-operator-2/3.JOIN-1-2.md)。
|
||||
|
||||
一般地,在进行查询优化时,OceanBase 数据库优化器会优先选择 Index Nested Loop Join,然后检查是否可以使用 Batch Nested Loop Join,这两种优化方式可以一起使用,最后才会选择 Nested Loop Join。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Merge Join
|
||||
-------------------
|
||||
|
||||
Merge Join 原理是首先会按照联接的字段对两个表进行排序(如果内存空间不够,就需要进行外排),然后开始扫描两张表进行合并。
|
||||
|
||||
合并的过程会从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将抛弃关联字段值较小的记录,从这条记录对应的表中获取下一条记录继续进行匹配,直到整个循环结束。
|
||||
|
||||
在多对多的两张表上进行合并时,通常需要使用临时空间进行操作。例如,当 A Join B 使用 Merge Join 时,如果对于关联字段的某一组值,在 A 和 B 中都存在多条记录 A1、A2...An 和 B1、B2...Bn,则为 A 中每一条记录 A1、A2...An,都必须对 B 中对所有相等的记录 B1、B2...Bn 进行一次匹配。这样,指针需要多次从 B1 移动到 Bn,每一次都需要读取相应的 B1...Bn 记录。将 B1...Bn 的记录预先读出来放入内存临时表中,比从原数据页或磁盘读取要快。在一些场景中,如果联接字段上有可用的索引,并且排序一致,那么可以直接跳过排序操作。
|
||||
|
||||
通常来说,Merge Join 比较适合两个输入表已经有序的情况,否则 Hash Join 会更加好。如下示例展示了两个 Merge Join 的计划,其中第一个是需要排序的,第二个是不需要排序的(因为两个表都选择了 `k1` 这两个索引访问路径,这两个索引本身就是按照 `b` 列排序的)。
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.24 sec)
|
||||
|
||||
obclient> CREATE TABLE t2(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient> EXPLAIN SELECT/*+USE_MERGE(t1 t2)*/ * FROM t1, t2 WHERE t1.c = t2.c;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |MERGE JOIN | |1980 |6011|
|
||||
|1 | SORT | |1000 |2198|
|
||||
|2 | TABLE SCAN|t1 |1000 |455 |
|
||||
|3 | SORT | |1000 |2198|
|
||||
|4 | TABLE SCAN|t2 |1000 |455 |
|
||||
=====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
equal_conds([t1.c = t2.c]), other_conds(nil)
|
||||
1 - output([t1.a], [t1.b], [t1.c]), filter(nil), sort_keys([t1.c, ASC])
|
||||
2 - output([t1.c], [t1.a], [t1.b]), filter(nil),
|
||||
access([t1.c], [t1.a], [t1.b]), partitions(p0)
|
||||
3 - output([t2.a], [t2.b], [t2.c]), filter(nil), sort_keys([t2.c, ASC])
|
||||
4 - output([t2.c], [t2.a], [t2.b]), filter(nil),
|
||||
access([t2.c], [t2.a], [t2.b]), partitions(p0)
|
||||
|
||||
|
||||
obclient>EXPLAIN SELECT/*+USE_MERGE(t1 t2),INDEX(t1 k1),INDEX(t2 k1)*/ *
|
||||
FROM t1, t2 WHERE t1.b = t2.b;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =======================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
---------------------------------------
|
||||
|0 |MERGE JOIN | |1980 |12748|
|
||||
|1 | TABLE SCAN|t1(k1)|1000 |5566 |
|
||||
|2 | TABLE SCAN|t2(k1)|1000 |5566 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
equal_conds([t1.b = t2.b]), other_conds(nil)
|
||||
1 - output([t1.b], [t1.a], [t1.c]), filter(nil),
|
||||
access([t1.b], [t1.a], [t1.c]), partitions(p0)
|
||||
2 - output([t2.b], [t2.a], [t2.c]), filter(nil),
|
||||
access([t2.b], [t2.a], [t2.c]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
同时,OceanBase 数据库也提供了 Hint 机制 `/*+ USE_MERGE(table_name_list) */` 去控制多表联接时选择 Merge Join 联接算法。例如下述场景中联接算法选择的是 Hash Join,而用户希望使用 Merge Join,则可以使用上述 Hint 进行控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.97 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT);
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |HASH JOIN | |98010000 |66774608|
|
||||
|1 | TABLE SCAN|T1 |100000 |68478 |
|
||||
|2 | TABLE SCAN|T2 |100000 |68478 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_MERGE(t1,t2)*/* FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| =========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
-----------------------------------------
|
||||
|0 |MERGE JOIN | |98010000 |67488837|
|
||||
|1 | SORT | |100000 |563680 |
|
||||
|2 | TABLE SCAN|T1 |100000 |68478 |
|
||||
|3 | SORT | |100000 |563680 |
|
||||
|4 | TABLE SCAN|T2 |100000 |68478 |
|
||||
=========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C1, ASC])
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
3 - output([T2.C1], [T2.C2]), filter(nil), sort_keys([T2.C1, ASC])
|
||||
4 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
Hash Join
|
||||
------------------
|
||||
|
||||
Hash Join 原理是用两个表中相对较小的表(通常称为 Build Table)根据联接条件创建 Hash Table,然后逐行扫描较大的表(通常称为 Probe Table)并通过探测 Hash Table 找到匹配的行。如果 Build Table 非常大,构建的 Hash Table 无法在内存中容纳时,Oceanbase 数据库会分别将 Build Table 和 Probe Table 按照联接条件切分成多个分区(Partition),每个 Partition 都包括一个独立的、成对匹配的 Build Table 和 Probe Table,这样就将一个大的 Hash Join 切分成多个独立、互相不影响的 Hash Join,每一个分区的 Hash Join 都能够在内存中完成。在绝大多数情况下,Hash Join 效率比其他联接方式效率更高。
|
||||
|
||||
如下是 Hash Join 计划的示例。
|
||||
|
||||
```javascript
|
||||
obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.24 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(a INT PRIMARY KEY, b INT, c INT, KEY k1(b));
|
||||
Query OK, 0 rows affected (0.29 sec)
|
||||
|
||||
obclient> EXPLAIN SELECT/*+USE_HASH(t1 t2)*/ * FROM t1, t2 WHERE t1.c = t2.c;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ====================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
------------------------------------
|
||||
|0 |HASH JOIN | |1980 |4093|
|
||||
|1 | TABLE SCAN|t1 |1000 |455 |
|
||||
|2 | TABLE SCAN|t2 |1000 |455 |
|
||||
====================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.a], [t1.b], [t1.c], [t2.a], [t2.b], [t2.c]), filter(nil),
|
||||
equal_conds([t1.c = t2.c]), other_conds(nil)
|
||||
1 - output([t1.c], [t1.a], [t1.b]), filter(nil),
|
||||
access([t1.c], [t1.a], [t1.b]), partitions(p0)
|
||||
2 - output([t2.c], [t2.a], [t2.b]), filter(nil),
|
||||
access([t2.c], [t2.a], [t2.b]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
同时,OceanBase 数据库也提供了 Hint 机制 `/*+ USE_HASH(table_name_list) */` 去控制多表联接时选择 Hash Join 联接算法。例如下述场景中联接算法选择的是 Merge Join,而用户希望使用 Hash Join,则可以使用上述 Hint 进行控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.31 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.33 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |MERGE JOIN | |100001 |219005|
|
||||
|1 | TABLE SCAN|T1 |100000 |61860 |
|
||||
|2 | TABLE SCAN|T2 |100000 |61860 |
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+USE_HASH(t1, t2)*/ * FROM t1, t2 WHERE t1.c1 = t2.c1;
|
||||
*************************** 1. row ***************************
|
||||
Query Plan:
|
||||
| ======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
--------------------------------------
|
||||
|0 |HASH JOIN | |100001 |495180|
|
||||
|1 | TABLE SCAN|T1 |100000 |61860 |
|
||||
|2 | TABLE SCAN|T2 |100000 |61860 |
|
||||
======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C1]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
2 - output([T2.C1], [T2.C2]), filter(nil),
|
||||
access([T2.C1], [T2.C2]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
联接顺序
|
||||
=========================
|
||||
|
||||
在多表联接的场景中,优化器的一个很重要的任务是决定各个表之间的联接顺序(Join Order),因为不同的联接顺序会影响中间结果集的大小,进而影响到计划整体的执行代价。
|
||||
|
||||
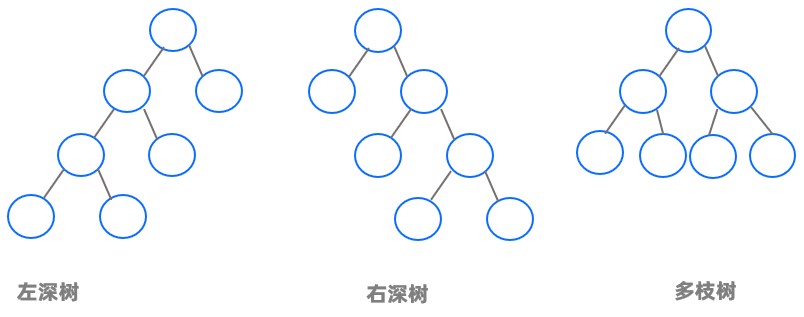
为了减少执行计划的搜索空间和计划执行的内存占用,OceanBase 数据库优化器在生成联接顺序时主要考虑左深树的联接形式。下图展示了左深树、右深树和多支树的计划形状。
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库在生成联接顺序时采用 System-R 的动态规划算法,考虑的因素包括每一个表可能的访问路径、Interesting Order、联接算法(Nested Loop Join、Block Based Nested Loop Join 或者 Sort Merge Join 等)以及不同表之间的联接选择率等。
|
||||
|
||||
如果给定 N 个表的联接,OceanBase 数据库生成联接顺序的方法如下:
|
||||
|
||||
1. 为每一个基表生成访问路径,保留代价最小的访问路径以及有所有具有 Interesting Order 的路径。如果一个路径具有 Interesting Order,它的序能够被后续的算子使用。
|
||||
|
||||
|
||||
|
||||
2. 生成所有表集合的大小为 `i (1 < i <= N)` 的计划。 OceanBase 数据库一般只考虑左深树,表集合大小为 `i` 的计划可以由其本身的计划和一个基表的计划组成。OceanBase 数据库按照这种策略,考虑了所有的联接算法以及 Interesting Order 的继承等因素生成所有表集合大小为 `i` 的计划。这里也只是保留代价最小的计划以及所有具有 Interesting Order 的计划。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
同时,OceanBase 数据库提供了 Hint 机制 `/*+LEADING(table_name_list)*/` 去控制多表联接的顺序。
|
||||
|
||||
如下例所示,开始选择的联接顺序是先做 `t1` 表、`t2` 表的 `JOIN` 联接,然后再和 `t3` 表做 `JOIN` 联接;如果用户希望先做 `t2` 表、`t3` 表的 `JOIN` 联接,然后再和 `t1` 表做 `JOIN` 联接,则可以使用 Hint `/*+LEADING(t2,t3,t1)*/` 去控制;如果用户希望先做 `t1` 表、`t3` 表的 `JOIN` 联接,然后再和 `t2` 表做 `JOIN` 联接,则可以使用 Hint `/*+LEADING(t1,t3,t2)*/` 去控制。
|
||||
|
||||
```javascript
|
||||
obclient>CREATE TABLE t1(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.31 sec)
|
||||
|
||||
obclient>CREATE TABLE t2(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.33 sec)
|
||||
|
||||
obclient>CREATE TABLE t3(c1 INT, c2 INT, PRIMARY KEY(c1));
|
||||
Query OK, 0 rows affected (0.44 sec)
|
||||
|
||||
obclient>EXPLAIN SELECT * FROM t1,t2,t3 WHERE t1.c1 = t2.c2 AND t2.c1 = t3.c2;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| =======================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
---------------------------------------
|
||||
|0 |HASH JOIN | |98010 |926122|
|
||||
|1 | TABLE SCAN |T3 |100000 |61860 |
|
||||
|2 | HASH JOIN | |99000 |494503|
|
||||
|3 | TABLE SCAN|T1 |100000 |61860 |
|
||||
|4 | TABLE SCAN|T2 |100000 |61860 |
|
||||
=======================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T2.C1 = T3.C2]), other_conds(nil)
|
||||
1 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
2 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C2]), other_conds(nil)
|
||||
3 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
4 - output([T2.C2], [T2.C1]), filter(nil),
|
||||
access([T2.C2], [T2.C1]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+LEADING(t2,t3,t1)*/* FROM t1,t2,t3 WHERE t1.c1 = t2.c2
|
||||
AND t2.c1 = t3.c2;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| ========================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST |
|
||||
----------------------------------------
|
||||
|0 |HASH JOIN | |98010 |1096613|
|
||||
|1 | HASH JOIN | |99000 |494503 |
|
||||
|2 | TABLE SCAN|T2 |100000 |61860 |
|
||||
|3 | TABLE SCAN|T3 |100000 |61860 |
|
||||
|4 | TABLE SCAN |T1 |100000 |61860 |
|
||||
========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C2]), other_conds(nil)
|
||||
1 - output([T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T2.C1 = T3.C2]), other_conds(nil)
|
||||
2 - output([T2.C2], [T2.C1]), filter(nil),
|
||||
access([T2.C2], [T2.C1]), partitions(p0)
|
||||
3 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
4 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
|
||||
obclient>EXPLAIN SELECT /*+LEADING(t1,t3,t2)*/* FROM t1,t2,t3 WHERE t1.c1 = t2.c2
|
||||
AND t2.c1 = t3.c2;
|
||||
+-----------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+-----------------------------------------------------------------+
|
||||
| =============================================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS |COST |
|
||||
-------------------------------------------------------------
|
||||
|0 |HASH JOIN | |98010 |53098071243|
|
||||
|1 | NESTED-LOOP JOIN CARTESIAN| |10000000000|7964490204 |
|
||||
|2 | TABLE SCAN |T1 |100000 |61860 |
|
||||
|3 | MATERIAL | |100000 |236426 |
|
||||
|4 | TABLE SCAN |T3 |100000 |61860 |
|
||||
|5 | TABLE SCAN |T2 |100000 |61860 |
|
||||
=============================================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.C1], [T1.C2], [T2.C1], [T2.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
equal_conds([T1.C1 = T2.C2], [T2.C1 = T3.C2]), other_conds(nil)
|
||||
1 - output([T1.C1], [T1.C2], [T3.C1], [T3.C2]), filter(nil),
|
||||
conds(nil), nl_params_(nil)
|
||||
2 - output([T1.C1], [T1.C2]), filter(nil),
|
||||
access([T1.C1], [T1.C2]), partitions(p0)
|
||||
3 - output([T3.C1], [T3.C2]), filter(nil)
|
||||
4 - output([T3.C2], [T3.C1]), filter(nil),
|
||||
access([T3.C2], [T3.C1]), partitions(p0)
|
||||
5 - output([T2.C2], [T2.C1]), filter(nil),
|
||||
access([T2.C2], [T2.C1]), partitions(p0)
|
||||
```
|
||||
|
||||
|
||||
Reference in New Issue
Block a user