Move the docs folder
This commit is contained in:
committed by
 LINxiansheng
LINxiansheng
parent
7c6dcc6712
commit
d42f317422
@ -0,0 +1,26 @@
|
||||
数据库基础组件介绍
|
||||
==============================
|
||||
|
||||
为了更好地管理 OceanBase 数据库,您需要了解 OceanBase 数据库的基础组件信息,包括 OceanBase 集群、Zone 、OBServer、资源池、租户、分区等。
|
||||
|
||||
OceanBase 数据库是由蚂蚁集团、阿里巴巴完全自主研发的金融级分布式关系数据库。OceanBase 数据库通过 OceanBase 集群来进行管理。一个 OceanBase 集群由多个 Zone 组成,Zone 的个数大于等于 3 个,每个 Zone 又包含了多个 OceanBase 服务器(observer 进程运行在这些服务器上),一般情况下各个 Zone 内的机器配置与数量保持一致,多台 OceanBase 服务器作为资源组成各个业务所需的资源池。管理员可以根据业务情况,将资源再划分成不同大小的资源池分配给租户使用,一般建议高性能要求的业务分配大资源池,低性能要求的业务分配小资源池。
|
||||
|
||||
租户拥有资源池后,可以创建数据库、表、分区等。
|
||||
|
||||
OceanBase 数据库基础组件之间的关系如下图所示。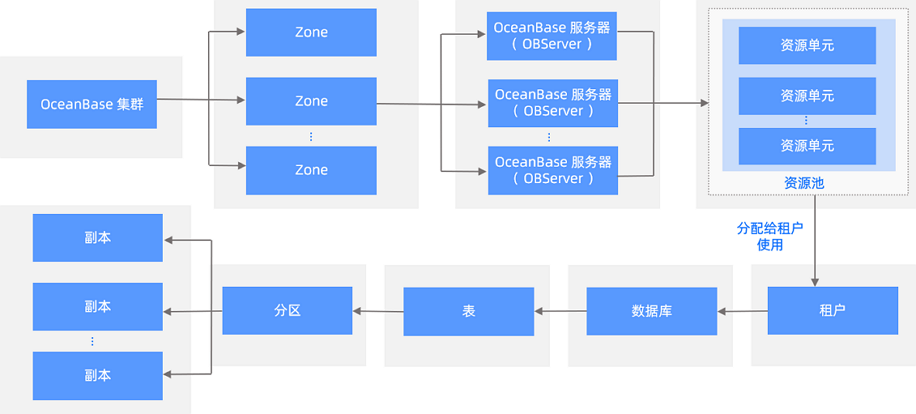
|
||||
|
||||
OceanBase 集群、Zone 和 OceanBase 服务器
|
||||
------------------------------------------------------
|
||||
|
||||
一个集群由多个 Zone 组成,每一份数据在各个 Zone 上都会有一份副本,并且只能有一份副本,这样一个 Zone 故障后不会影响业务正常运行和数据的完整性。从物理角度上来说,不同的 Zone 可以对应不同的城市;也可以对应一个城市的不同机房;还可以对应一个机房的不同机架,从而实现不同级别的容灾。
|
||||
|
||||
Zone 的个数大于等于 3 个,因为 OceanBase 数据库采用 Paxos 协议,多数派需要达成一致,3 个及以上的 Zone 可以保证当 1 个 Zone 故障后,剩下的 2 个 Zone 内的副本依然还可以构成多数派,不影响业务。
|
||||
OceanBase 服务器相对独立,拥有自己的计算引擎和存储引擎,也会有部分数据。对业务而言,每台 OceanBase 服务器均是一台传统的集中式数据库,业务访问到这台 OceanBase 服务器后,如果需要访
|
||||
问的数据在其它 OceanBase 服务器上,它们自己会自动协商调度,对业务无感知。
|
||||
|
||||
资源池和租户
|
||||
---------------------------
|
||||
|
||||
集群的多个服务器组成了一个大的资源池,管理员会根据各个租户的要求,创建与之对应的虚拟资源池给租户使用,资源池包括指定规格的 CPU、内存、存储、TPS、QPS 等。为了避免租户之间争抢资源,租户之间的资源相互隔离,内存是物理隔离、CPU 是逻辑隔离。
|
||||
|
||||
系统租户保存系统表,一般系统租户的 ID 为 1000 以内。剩下的是业务租户,创建租户时只支持 MySQL 模式的租户。
|
||||
@ -0,0 +1,29 @@
|
||||
OceanBase 客户端
|
||||
==================================
|
||||
|
||||
OceanBase 客户端(OBClient)兼容访问 OceanBase 数据库的 MySQL 租户,因此是推荐的黑屏客户端工具。点击 OBClient 的 [GitHub 地址](https://github.com/oceanbase/obclient) 获得该应用。
|
||||
|
||||
下载 OceanBase 客户端后,连接语句如下所示:
|
||||
|
||||
```sql
|
||||
obclient -u[用户名]@[租户名]#[集群名称] -P[端口号] -h[ip地址] -p[密码] -D[数据库名] -c
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
* 连接语句中不带 `-c ` 项的话,则连接至租户后 Hint 无法生效。
|
||||
|
||||
|
||||
|
||||
* 连接语句中不带 `-D[数据库名]` 项的话,则默认数据库同用户名一致。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,24 @@
|
||||
MySQL 客户端
|
||||
==============================
|
||||
|
||||
|
||||
|
||||
安装 MySQL 官方的 JDBC 驱动 mysql-connector-Java 时,推荐使用 5.1.30 和 5.1.40 版本,其他版本可能存在兼容问题。
|
||||
|
||||
因 OceanBase 数据库仅支持 MySQL 5.6.25 语法, 如果使用 MySQL 8.0 客户端, 可能会有语法兼容性问题, 推荐使用 OBClient 或 MySQL 5.6 版本客户端。
|
||||
|
||||
下述为在 MySQL 客户端中连接 OceanBase 数据库 MySQL 租户的示例语句:
|
||||
|
||||
```javascript
|
||||
mysql -u[用户名]@[租户名]#[集群名称] -P[端口号] -h[ip地址] -p[密码] -D[数据库名]] -c
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果连接语句中不带`-c`项,则连接至 MySQL 租户后 HINT 无法生效。
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,15 @@
|
||||
集群管理概述
|
||||
===========================
|
||||
|
||||
OceanBase 集群由多个 Zone 和多台 OBServer 构成。
|
||||
|
||||
OceanBase 集群的唯一标识是集群名称和集群 ID。集群管理实现了集群的创建、重启和下线等功能。同时可以通过增加或减少 Zone 以及 OBServer 来实现集群的扩容和缩容。
|
||||
|
||||
通过集群的扩容或缩容功能可以扩展 OceanBase 集群的弹性能力。在已经实现 3 副本同城机房级别容灾的情况下,可以扩展集群到 3 中心 5 副本的方式实现城市级别容灾。扩容和下线功能同样可以使用于机器的替换和维修。例如任意服务器硬件故障,可以通过集群扩容的方式添加新的服务器到集群,将硬件问题服务器下线。整个操作过程中集群的节点数量在前后保持一致,同时集群的 RootService 服务会自动探测新节点并自动进行补副本动作。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,20 @@
|
||||
集群参数管理概述
|
||||
=============================
|
||||
|
||||
OceanBase 集群配置可以通过集群参数和租户参数来设定。通过参数的设定可以使 OceanBase 数据库的行为符合您业务的要求。
|
||||
|
||||
OceanBase 数据库的集群参数分为集群级别和租户级别,同时参数分为动态生效和重启生效两类。通过集群参数的设置可以控制集群的负载均衡、合并时间、合并方式、资源分配和模块开关等功能。
|
||||
|
||||
系统租户可以查看和设置所有其他租户的参数(包括 sys 租户)。普通租户只能设置自己租户的参数。
|
||||
|
||||
不同租户对集群参数的查看和修改级别如下表所示。
|
||||
|
||||
|
||||
| 租户类型 | 参数查看 | 参数设置 |
|
||||
|------|---------------|------------------|
|
||||
| 系统租户 | 查看集群参数和其他租户参数 | 可以设置集群参数或指定租户的参数 |
|
||||
| 普通租户 | 只能查看本租户的参数 | 只能设置本租户的参数 |
|
||||
|
||||
|
||||
|
||||
当 OBServer 启动后,如果没有指定参数,则使用系统指定的参数 Default 值。在 observer 进程启动成功后,参数值持久化到 `/home/admin/oceanbase/etc/observer.config.bin` 文件中,您可以通过 `strings` 命令来查看内容。
|
||||
@ -0,0 +1,116 @@
|
||||
查询集群参数
|
||||
===========================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 查询集群参数。
|
||||
|
||||
通过 SQL 语句查询
|
||||
--------------------------------
|
||||
|
||||
系统租户和普通租户查询集群参数的语句如下所示:
|
||||
|
||||
* 系统租户查询集群参数的语法
|
||||
|
||||
```sql
|
||||
SHOW PARAMETERS [SHOW_PARAM_OPTS] [tenant='tenant'];
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 普通租户查询集群参数的语法
|
||||
|
||||
```sql
|
||||
SHOW PARAMETERS [SHOW_PARAM_OPTS]
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
其中各参数的含义如下:
|
||||
|
||||
* `[SHOW_PARAM_OPTS]` :值可指定为 `[LIKE 'pattern' | WHERE expr]`。
|
||||
|
||||
* ` [tenant='tenant']` :系统租户查看集群参数时需指定租户名。
|
||||
|
||||
|
||||
|
||||
|
||||
具体示例如下所示:
|
||||
|
||||
* 系统租户
|
||||
|
||||
```sql
|
||||
obclient> SHOW PARAMETERS LIKE 'sql_work_area' tenant=t1;obclient> SHOW PARAMETERS WHERE edit_level='static_effective' AND name='sql_work_area' tenant=t1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 普通租户
|
||||
|
||||
```sql
|
||||
obclient> SHOW PARAMETERS LIKE 'sql_work_area';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
`SHOW PARAMETERS` 返回结果中的列属性如下表所示。
|
||||
|
||||
|
||||
| 列名 | 含义 |
|
||||
|------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| zone | 所在的 Zone。 |
|
||||
| svr_ip | 机器 IP。 |
|
||||
| svr_port | 机器的端口。 |
|
||||
| name | 配置项名。 |
|
||||
| data_type | 配置项的数据类型,包括 `NUMBER`、`STRING`、`CAPACITY` 等。 |
|
||||
| value | 配置项的值。 |
|
||||
| info | 配置项的说明信息, |
|
||||
| section | 配置项所属的分类。 |
|
||||
| scope | 配置项范围属性: * `TENANT`:租户级别 * `CLUSTER`:集群级别 |
|
||||
| source | 当前值来源: * `TENANT` * `CLUSTER` * `CMDLINE` * `OBADMIN` * `FILE` * `DEFAULT` |
|
||||
| edit_level | 定义该配置项的修改行为: * `READONLY`:表示该参数不可修改。 * `STATIC_EFFECTIVE`:表示该参数可修改但需要重启 OBServer 才会⽣效。 * `DYNAMIC_EFFECTIVE`:表示该参数可修改且修改后动态⽣效。 |
|
||||
|
||||
|
||||
|
||||
通过 OCP 查询
|
||||
------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V3.1.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《 OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP 。默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在显示的页面的左侧导航栏上,单击 **参数管理** 。
|
||||
|
||||
|
||||
|
||||
4. 在 **参数列表** 页面,可以查看当前集群所有参数的信息,包括各参数的参数名称、取值类型、取值范围、默认值、当前值、参数说明和是否重启生效等信息。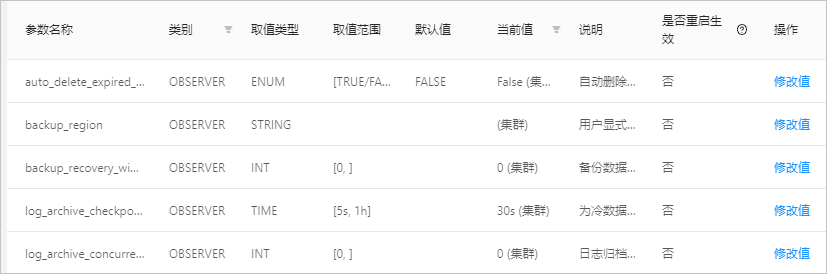
|
||||
|
||||
**说明**
|
||||
* 如果 **当前值** 是集群范围内统一,则如上图 **backup_region** 的参数值所示,表示 **0(集群)** 。
|
||||
|
||||
|
||||
|
||||
* 如果参数在 Zone 或者 Server 级别不一样,则会显示所有值的组合,例如, **12;10 自定义)**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,159 @@
|
||||
修改集群参数
|
||||
===========================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 修改集群参数。
|
||||
|
||||
通过 SQL 语句修改集群参数
|
||||
------------------------------------
|
||||
|
||||
集群参数即配置项,修改配置项的语法如下所示,同时修改多个系统配置项时,请用逗号(,)分隔。
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET param_name = expr
|
||||
[COMMENT 'text']
|
||||
[PARAM_OPTS]
|
||||
[TENANT = 'tenantname']
|
||||
|
||||
PARAM_OPTS:
|
||||
[ZONE='zone' | SERVER='server_ip:rpc_port']
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数修改语句说明如下:
|
||||
|
||||
* `PARAM_OPTS` 是修改配置项时所指定的其它限定条件,例如,指定 Zone、指定 Server 等。
|
||||
|
||||
|
||||
|
||||
* `ALTER SYSTEM` 语句不能同时指定 Zone 和 Server。并且在指定 Zone 时,仅支持指定一个 Zone;指定 Server 时,仅支持指定一个 Server。
|
||||
|
||||
|
||||
|
||||
* 集群级别的配置项(`Scope`) 不能通过普通租户设置,也不可以通过 sys 租户指定普通租户来设置。例如,`ALTER SYSTEM SET memory_limit='100G' TENANT='test_tenant'` 将导致报错,因为 `memory_limit` 是集群级别(`Scope`)的配置项。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
集群级别与租户级别的配置项设置会有所不同:
|
||||
|
||||
* 系统租户设置集群配置项的语法
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET mysql_port=8888 [PARAM_OPTS]
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 系统租户设置租户配置项的语法
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET clog_max_unconfirmed_log_count=1600 [PARAM_OPTS] TENANT=all|TENANT_NAME
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 租户设置租户配置项的语法
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET clog_max_unconfirmed_log_count=1600 [PARAM_OPTS]
|
||||
```
|
||||
|
||||
|
||||
|
||||
系统租户也可以使用该命令修改系统租户本身的租户配置项的值。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例如下:
|
||||
|
||||
* 系统租户设置集群配置项。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET mysql_port=8888;
|
||||
|
||||
obclient> ALTER SYSTEM SET mysql_port=8888 ZONE='z1';
|
||||
|
||||
obclient> ALTER SYSTEM SET mysql_port=8888 SERVER='192.168.100.1:2882';
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 系统租户设置租户配置项。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET clog_max_unconfirmed_log_count=1600 tenant='test_tenant';
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 租户设置租户配置项。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET clog_max_unconfirmed_log_count=1600;
|
||||
|
||||
obclient> ALTER SYSTEM SET memory_limit = '100G' SERVER='192.168.100.1:2882';
|
||||
|
||||
obclient> ALTER SYSTEM SET memory_limit = '100G' ZONE='z1';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
更多配置项信息,请参见《参考指南》文档中 [系统配置项](../../../../14.reference-guide-oracle-mode/3.system-configuration-items-1/1.system-configuration-items-overview-1.md) 章节。
|
||||
|
||||
更多配置项信息,请参见《参考指南》文档中 [系统配置项概述](../../../../14.reference-guide-oracle-mode/3.system-configuration-items-1/1.system-configuration-items-overview-1.md) 章节。
|
||||
|
||||
通过 OCP 修改集群参数
|
||||
----------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《 OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP 。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在显示的页面的左侧导航栏上,单击 **参数管理** 。
|
||||
|
||||
|
||||
|
||||
4. (可选)在 **参数列表** 页面上方的搜索框中,输入参数名相关信息进行模糊搜索。
|
||||
|
||||
|
||||
|
||||
|
||||
5. 找到待修改的参数,在对应的 **操作** 列中,单击 **修改值** 。
|
||||
|
||||
|
||||
|
||||
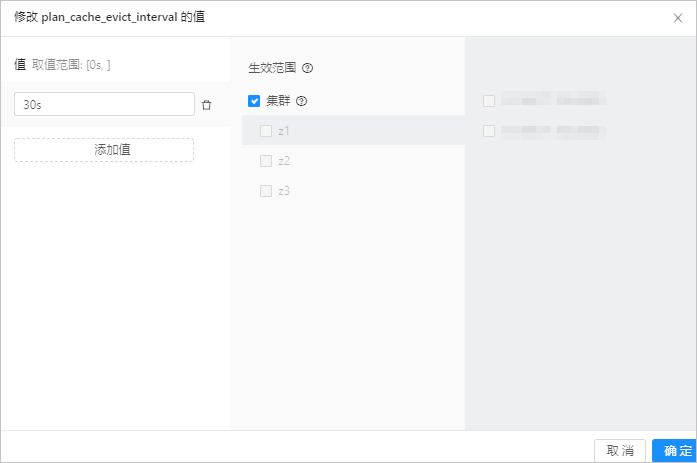
6. 在弹出的对话框中,修改参数的值及生效范围,单击 **确定** 。
|
||||
|
||||
|
||||
|
||||
由于 OceanBase 集群参数可以有全局(即 **集群** )、Zone 和 Server 三种生效范围,故在修改值时请根据业务需要选择生效范围。
|
||||
|
||||
默认生效范围是 **集群** 。如果需要调整到 Zone 或 Server 的生效范围,则可以在 **生效范围** 列取消选中 **集群** ,此时系统会显示集群下的 Zone 列表。根据提示选择 Zone 并选中,则选中了 Zone 的生效范围;如果选择 Zone 后,继续选择该 Zone 下的 Server 列表,则在 Server 范围生效。
|
||||
|
||||
如果需要修改参数的值同时在不同的范围生效,例如,修改 **backup_concurrency** 在 **Zone 1** 为 **10** ;在 **Zone 2** 为 **12** ;在 **Server 1** 上为 **20** ,则可以在 **值** 列单击 **添加值** 后出现 3 行记录。每行记录可以选中对应的生效范围。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果单击 **添加值** 后出现多行修改值时,对集群的参数修改顺序是从第一行往下依次执行,并且每次执行成功后,会在 OCP 的 **修改历史** 页签中产生一条历史记录。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,28 @@
|
||||
Zone 管理概述
|
||||
==============================
|
||||
|
||||
|
||||
|
||||
一个 OceanBase 集群,由若干个 Zone 组成。Zone 是可用区(Availability Zone)的简写。Zone 本身是一个逻辑概念,是对物理机进行管理的容器,一般是同一机房的一组机器的组合。物理层面来讲一个 Zone 通常等价于一个机房、一个数据中心或一个 IDC。为交付高级别的数据安全性和服务可用性能力,一个 OceanBase 集群通常会分布在同城的 3 个机房中,同一份数据的三个副本分别分布在 3 个机房中(即三个 Zone 中)。
|
||||
|
||||
OceanBase 数据库支持数据跨地域(Region)部署,且不同 Region 的距离通常较远,从而满足地域级容灾的需求。一个 Region 可以包含一个或者多个 Zone。例如,某 OceanBase 集群部署在某城市(某一 Region)且分布在三个 IDC 机房中,每个 IDC 机房中又有 3 台服务器,所以每个 IDC 机房的中的这 3 台服务器组合成一个 Zone。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
1. Region 并不是一个 OceanBase 的对象定义,而是 Zone 的关键属性之一。
|
||||
|
||||
|
||||
|
||||
2. 对于租户、数据库、数据分区(表和索引等)不同级别均有主可用区(Primary Zone)的属性配置,可用于支持高可用和负载均衡能力。
|
||||
|
||||
|
||||
|
||||
3. 对于租户级别有只读可用区(Read Zone 简称 RZone)的属性配置,用于交付高可用和负载均衡能力,也是针对读写分离场景的一种方案。相比主可用区属性配置,只读可用区需要在原有副本组(Paxos 组)的基础上追加 1 个或多个副本。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
@ -0,0 +1,111 @@
|
||||
增加或删除 Zone
|
||||
===============================
|
||||
|
||||
您可以通过命 SQL 语句或 OCP 来增加或删除 Zone。
|
||||
|
||||
通过 SQL 语句增加或删除 Zone
|
||||
----------------------------------------
|
||||
|
||||
在集群中增加或删除 Zone 的操作通常用于集群扩容或缩容等需求场景。
|
||||
|
||||
增加或删除 Zone 的命令如下所示,其中参数 `Zone_Name` 为目标 Zone 的名称。
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM {ADD|DELETE} ZONE Zone_Name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
**示例 1:** 下述示例语句展示了在集群中新增一个名为 `Zone1`的 Zone。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM ADD ZONE Zone1;
|
||||
```
|
||||
|
||||
**示例 2** :下述示语句展示了在集群中删除名为 `Zone1`的 Zone。
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM DELETE ZONE Zone1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 OCP 增加 Zone
|
||||
-----------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
在集群中,根据实际部署模式增加 Zone。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待增加 Zone 的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在 **总览** 页面右上角,单击 **新增 Zone** 。
|
||||
|
||||
|
||||
|
||||
4. 在弹出的对话框中,设置 Zone 信息。
|
||||
|
||||
默认是添加一个 Zone 信息,如果您需要添加多个 Zone ,可以在下方单击 **新增** 按钮,添加多个 Zone 信息。
|
||||
|
||||
需要配置的 Zone 信息如下表所示。
|
||||
|
||||
|
||||
| 配置 | 描述 |
|
||||
|-------------|-------------------------------------------------------------------------------------------------------------------|
|
||||
| **Zone 名称** | 自定义 Zone 名称。 |
|
||||
| **机房** | Zone 所在的机房。 |
|
||||
| **机型** | 可选项。如果选择了机型,后面主机列表会根据机型进行过滤。 |
|
||||
| **机器选择方式** | 可以选择自动分配或者手动选择。 |
|
||||
| **IP** | 您可以选择多个 IP。如果 **机器选择方式** 是 **自动分配** ,则只需要输入机器的数量,OCP 会自动选择相应数量的可用机器;如果 **机器选择方式** 是 **手动选择** ,则需要您手动从列表中选择若干个 IP。 |
|
||||
|
||||
|
||||
|
||||
5. 完成后,单击 **确定** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 删除 Zone
|
||||
-----------------------------------
|
||||
|
||||
在集群中,根据实际部署模式下线 Zone。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
相比停止和删除 Zone 命令,OCP 中提供的删除 Zone 功能是删除数据副本并下线 Zone 内所有 OceanBase 服务器节点操作的组合。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在 **总览** 页面的 **Zone 列表** 区域,选择待删除的 Zone,在对应的 **操作** 列中,单击 ... 图标,选择 **删除** 。
|
||||
|
||||
|
||||
|
||||
4. 在弹出的确认框中,单击 **删除** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,157 @@
|
||||
增加或删除加密 Zone
|
||||
=================================
|
||||
|
||||
OceanBase 数据库提供了 Zone 级别的日志传输和保存加密功能,您可以在集群中添加 Zone 时,指定 Zone 的加密属性,后续在向该加密 Zone 发送日志时,系统会对 Clog 进行加密,并且该 Zone 在持久化 Clog 时也会加密。
|
||||
|
||||
添加加密 Zone
|
||||
------------------------------
|
||||
|
||||
本节以下述集群为例,提供加密 Zone 的添加方法。
|
||||
|
||||
假设集群中已有 2个 Zone: `z1` 和 `z2`,需要添加一个Zone `z3`。其中,`z1` 和 `z2` 是常规读写 Zone,`z3` 是加密 Zone,`z3` 只包含加密的事务日志数据。
|
||||
|
||||
添加加密 Zone 的步骤如下:
|
||||
|
||||
1. 使用 root 用户登录数据库的 sys 租户。
|
||||
|
||||
|
||||
|
||||
2. 依次执行以下语句,生成主密钥。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM set tde_method = 'internal';
|
||||
|
||||
obclient>ALTER INSTANCE ROTATE INNODB MASTER KEY;
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 执行以下语句,检查上一步中生成的主密钥是否生效。
|
||||
|
||||
```sql
|
||||
obclient> SELECT min(max_active_version) FROM oceanbase.__all_virtual_master_key_version_info WHERE tenant_id = 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
当查询结果中 `min(max_active_version) `大于 `0` 时,则表示主密钥已生效,否则主密钥没有生效。
|
||||
|
||||
虚拟表 `__all_virtual_master_key_version_info` 用于记录每个 OBServer 上主密钥的版本信息,其表结构如下:
|
||||
|
||||
```unknow
|
||||
table_name = '__all_virtual_master_key_version_info',
|
||||
|
||||
rowkey_columns = [
|
||||
('svr_ip', 'varchar:MAX_IP_ADDR_LENGTH'),
|
||||
('svr_port', 'int'),
|
||||
('tenant_id', 'int'),
|
||||
],
|
||||
normal_columns = [
|
||||
('max_active_version', 'int'),
|
||||
('max_stored_version', 'int'),
|
||||
('expect_version', 'int'),
|
||||
]
|
||||
```
|
||||
|
||||
|
||||
|
||||
每个 OBServer 上的每一个租户的主密钥信息占据该虚拟表中的一行。其中:
|
||||
* `expect_version` 表示集群中该租户当前已生成的主密钥的最大版本。
|
||||
|
||||
|
||||
|
||||
* `max_stored_version` 表示对应 OBServer 在其本地持久化中,该租户的主密钥的最大版本。
|
||||
|
||||
|
||||
|
||||
* `max_active_version` 表示对应 OBServer 在进行加密时,该租户可以使用的主密钥的最大版本,`max_active_version` 等于 `0` 表示没有已经生效的主密钥。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
4. 执行以下命令,添加加密 Zone。
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
在添加加密 Zone 前,系统租户必须要有一个已生效的主密钥,如果系统租户没有一个生效的主密钥,则执行添加加密 zone 的语句会失败。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM ADD Zone 'z3' zone_type = 'encryption';
|
||||
```
|
||||
|
||||
|
||||
|
||||
5. 分别执行以下命令,调整系统租户的 Locality。
|
||||
|
||||
由于集群之前为 2 副本,为保证系统租户的高可用,在添加完加密 Zone 后,需要将系统租户补充为 3 副本。
|
||||
|
||||
```sql
|
||||
obclient> CREATE RESOURCE POOL sys_pool2 unit_num = 1, resource_pool_list=('z3'), unit='sys_unit_config';
|
||||
|
||||
obclient> ALTER TENANT sys resource_pool_list = ('sys_pool','sys_pool2');
|
||||
|
||||
obclient> ALTER TENANT sys LOCALITY = 'F@z1,F@z2,E@z3';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
轮转主密钥
|
||||
--------------------------
|
||||
|
||||
当用户希望更换主密钥时,管理员可以为加密 Zone 轮转主密钥。
|
||||
|
||||
1. 使用 root 用户登录数据库的 sys 租户。
|
||||
|
||||
|
||||
|
||||
2. 执行以下语句,为加密 Zone 轮转主密钥。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
obclient> ALTER INSTANCE ROTATE INNODB MASTER KEY;
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
在轮转主密钥时,如果出现了 OBServer 宕机,加密 Zone 上的 OBServer 宕机不会对主密钥生效产生影响,但常规 Zone 上的 OBServer 宕机对主密钥的生效可能产生影响,可能会导致轮转生成的新主密钥不能立即生效。
|
||||
|
||||
删除加密 Zone
|
||||
------------------------------
|
||||
|
||||
加密 Zone 添加成功后,如果需要删除加密 Zone,其操作与常规读写 Zone 的删除操作相同,您可以使用以下语句删除该加密 Zone:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM DELETE ZONE 'z3';
|
||||
```
|
||||
|
||||
|
||||
|
||||
加密 Zone 使用限制
|
||||
---------------------------------
|
||||
|
||||
加密 Zone 和加密投票型副本的使用有一定限制,具体限制如下:
|
||||
|
||||
* 加密 Zone 上仅支持部署加密投票型副本,不支持部署其他类型的副本,例如全功能副本、只读副本、普通日志副本等均不能部署在加密 Zone 上。
|
||||
|
||||
|
||||
|
||||
* 加密投票型副本仅支持部署在加密 Zone 上,不支持部署在常规读写 Zone上。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
启动或停止 Zone
|
||||
===============================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 来启动或停止 Zone。
|
||||
|
||||
通过 SQL 语句启动和停止
|
||||
-----------------------------------
|
||||
|
||||
在集群中启动或停止 Zone 的操作通常用于允许或禁止 Zone 内的所有物理服务器对外提供服务的需求场景。
|
||||
|
||||
启动或停止 Zone 的命令如下所示,其中参数 `zone_name` 为目标 Zone 的名称:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM {START|STOP|FORCE STOP} ZONE zone_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
**示例 1** :在集群中启动名为 `Zone1`的 Zone。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM START ZONE Zone1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
**示例 2** :在集群中停止运行名为 `Zone1`的 Zone。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM STOP ZONE Zone1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
**示例 3** :在集群中停止运行名为 `Zone1`的 Zone。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
`FORCE STOP ZONE` 不会检查 Zone 内的 clog 是否同步,而是直接停止 Zone。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM FORCE STOP ZONE Zone1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 OCP 启动和停止
|
||||
---------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《 OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在 **总览** 页面的 **Zone 列表** 区域,选择待操作的 Zone,在对应的 **操作** 列中,单击 ... 图标,选择 **启动** 或 **停止** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,25 @@
|
||||
修改 Zone
|
||||
============================
|
||||
|
||||
OceanBase 数据库提供了 SQL 语句来修改 Zone 的配置信息。
|
||||
|
||||
修改 Zone 的命令如下所示:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM {ALTER|CHANGE|MODIFY} ZONE Zone_Name SET [Zone_Option_List];
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中各参数的含义如下:
|
||||
|
||||
* `Zone_Name`:指定 Zone 的名称。
|
||||
|
||||
* `[Zone_Option_List]`:指定目标 Zone 要被修改的属性,同时修改多个属性时各属性之前用逗号(,)分隔。下述为 Zone 中的属性:
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
|
||||
@ -0,0 +1,6 @@
|
||||
OBServer 管理概述
|
||||
==================================
|
||||
|
||||
OceanBase Server(简称 OBServer) 是一个 OceanBase 数据库的节点(节点不完全等同于物理机器)。 observer 是节点上运行的分布式数据库内核进程的名字。
|
||||
|
||||
每一个 OceanBase 数据库的进程 observer 由 IP 和端口作为唯一标识。通常一台物理或者虚拟服务器运行一个 observer 进程。observer 进程作为 OceanBase 数据库最核心的进程负责几乎所有数据库内核功能,包括 SQL 引擎、存储引擎和事务引擎。分布式的功能也同样在这个进程中,包括 RPC 通信、负载均衡和分区管理等。
|
||||
@ -0,0 +1,47 @@
|
||||
查看 OBServer 状态
|
||||
===================================
|
||||
|
||||
您可以通过命令或 OCP 来查看 OBServer 的状态。
|
||||
|
||||
通过命令查看 observer 进程
|
||||
---------------------------------------
|
||||
|
||||
1. 登录 OBServer 所在的宿主机。
|
||||
|
||||
|
||||
|
||||
2. 在命令行工具中运行以下语句以查看 observer 进程。
|
||||
|
||||
```shell
|
||||
ps -ef |grep observer
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 查看 OBServer 状态
|
||||
------------------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在 **总览** 页面的 **OBServer 列表** 区域,查看集群中的 OBServer 状态。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
停止 OBServer
|
||||
================================
|
||||
|
||||
您可以通过命令或 OCP 来停止 OBServer 的运行。
|
||||
|
||||
通过命令停止 observer 进程
|
||||
---------------------------------------
|
||||
|
||||
登录 OBServer 所在的宿主机,在命令行工具中执行以下语句,停止 observer 进程。
|
||||
|
||||
```shell
|
||||
kill -15 `pgrep observer`
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果遇到无法正常退出的情况,可以执行以下语句。
|
||||
|
||||
```shell
|
||||
kill -9 `pgrep observer`
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 OCP 停止 OBServer
|
||||
---------------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
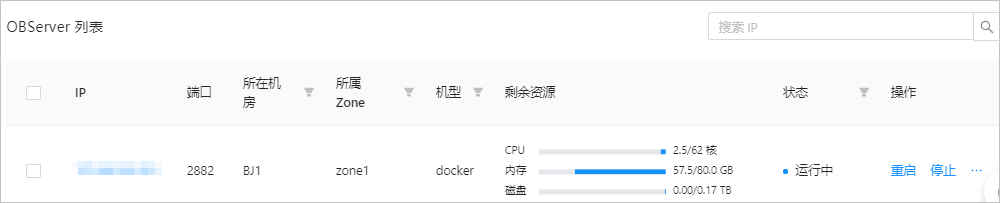
3. 在 **总览** 页面的 **OBServer 列表** 区域,找到待启动的 OBServer,在对应的 **操作** 列中,单击 **停止** 。
|
||||
|
||||
|
||||
|
||||
|
||||
4. 在弹出的确认框中,单击 **停止** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
启动 OBServer
|
||||
================================
|
||||
|
||||
您可以通过命令或 OCP 来启动 OBServer,使其处于运行状态。
|
||||
|
||||
通过命令启动 observer 进程
|
||||
---------------------------------------
|
||||
|
||||
登录 OBServer 所在的宿主机,通过命令行工具进入 `/home/admin/oceanbase/bin` 目录,运行下述命令启动 observer 进程。
|
||||
|
||||
```shell
|
||||
cd /home/admin/oceanbase/
|
||||
|
||||
./bin/observer [启动参数]
|
||||
```
|
||||
|
||||
|
||||
|
||||
同时,可以运行 `./bin/observer --help` 查看 observer 启动参数的详细信息。
|
||||
|
||||
启动 observer 进程的命令示例如下:
|
||||
|
||||
```shell
|
||||
cd /home/admin/oceanbase/bin
|
||||
|
||||
./observer -p 2881 -P 2882 -z 'zone_1' -d '/data/1/prod_data/' -r '192.168.1.1:2882:2881;192.168.1.2:2882:2881;192.168.1.3:2882:2881' -l WARN -d '/data/1/prod_data' -o 'memory_limit=100GB,datafile_disk_percentage=85'
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中:
|
||||
|
||||
* `2881`:表示 MySQL 的访问端口。
|
||||
|
||||
|
||||
|
||||
* `2882`:表示远程访问端口。
|
||||
|
||||
|
||||
|
||||
* `zone_1`:表示 Zone 名称。
|
||||
|
||||
|
||||
|
||||
* `/data/1/prod_data`:表示数据盘目录。
|
||||
|
||||
|
||||
|
||||
* `datafile_disk_percentage=85`:表示数据盘的占用比率为 85%。
|
||||
|
||||
|
||||
|
||||
* `192.168.1.1和``192.168.1.2` 和 `192.168.1.3`:表示 rs_list。
|
||||
|
||||
|
||||
|
||||
* `memory_limit=100GB`:表示进程启动内存上限为 100 GB。
|
||||
|
||||
|
||||
|
||||
* `WARN`:表示 log_level 为 WARNING 级别。
|
||||
|
||||
|
||||
|
||||
* 使用 `-o` 参数时,需满足以下条件:
|
||||
|
||||
* 不分大小写,但是推荐按照 `observer.config.bin` 中的变量名称来写。
|
||||
|
||||
|
||||
|
||||
* 参数不能包含以下特殊字符:
|
||||
|
||||
* 空格
|
||||
|
||||
|
||||
|
||||
* \\r
|
||||
|
||||
|
||||
|
||||
* \\n
|
||||
|
||||
|
||||
|
||||
* \\t
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 参数名和参数值中间必须有等号(=)。
|
||||
|
||||
|
||||
|
||||
* 参数之间使用逗号(,)进行分割。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 启动 OBServer
|
||||
---------------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在 **总览** 页面的 **OBServer 列表** 区域,找到待启动的 OBServer,在对应的 **操作** 列中,单击 **启动** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,146 @@
|
||||
管理 OBServer 节点状态
|
||||
=====================================
|
||||
|
||||
OceanBase 数据库提供了命令行方式来管理 OBServer 的节点状态
|
||||
|
||||
在运维操作中,如果需要替换节点、维修节点或者对节点进行诊断,可以通过 `STOP SERVER` 命令将该节点的分区 Leader 切到其他节点上。然后该 Server 状态将变为 `stopped` 并且不会对外提供服务。
|
||||
|
||||
节点的 `stopped` 状态并非等价于进程退出,进程可能仍然在运行,仅仅是集群的状态标志认为该节点为 `stopped` 状态。同理与之对应的是节点的 `started` 状态。
|
||||
|
||||
|
||||
|
||||
**Start Server 操作**
|
||||
----------------------------------------
|
||||
|
||||
Start Server 操作对应 Stop Server 操作。当集群中的 OBServer 启动后,默认状态是 `started`。在执行 Stop Server 操作后,需要通过 Start Server 操作将 Server 状态置为 `started`。Start Server 操作的命令如下所示:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM START SERVER 'ip:port' [,'ip:port'...] [ZONE='zone']
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例语句如下所示:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM START SERVER "10.10.10.1:2882"
|
||||
```
|
||||
|
||||
|
||||
|
||||
**Stop Server 操作**
|
||||
---------------------------------------
|
||||
|
||||
Stop Server 操作的目的是将该 Server 上的分区 Leader 切到其他节点。当该 Server 上没有分区 Leader 的情况下,系统将内部标记 Server 为 `stopped` 状态,客户端请求不会再次发送到该 Server,该 Server 也不会再对外提供服务。
|
||||
|
||||
Stop Server 操作通常是特殊运维操作时执行,比如机器硬件维修、替换和升级,或者对该 Server 进行诊断等而进行的动作。Stop Server 操作的命令如下所示:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM STOP SERVER 'ip:port' [,'ip:port'...] [ZONE='zone']
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例语句如下所示:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM STOP SERVER "10.10.10.1:2882" zone='z1'
|
||||
```
|
||||
|
||||
|
||||
|
||||
**Add Server 操作**
|
||||
--------------------------------------
|
||||
|
||||
Add Server 操作的目的是添加节点到集群,该操作是运维扩容的操作。被添加的新节点要求是空的,即 CLog 和 ILog 目录下为空。Add Server 操作的命令如下所示:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM ADD SERVER 'ip:port' [,'ip:port'...] [ZONE [=] 'zone']
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例语句如下所示:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM ADD SERVER "10.10.10.1:2882" zone='z1'
|
||||
```
|
||||
|
||||
|
||||
|
||||
**Delete Server 操作**
|
||||
-----------------------------------------
|
||||
|
||||
Delete Server 用于从集群中删除节点。Delete Server 操作的命令如下所示:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM DELETE SERVER 'ip:port' [,'ip:port'...] [ZONE [=] 'zone']
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例语句如下所示:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM DELETE SERVER "192.168.100.1:2882" zone='z1'
|
||||
```
|
||||
|
||||
|
||||
|
||||
**Cancel Delete Server 操作**
|
||||
------------------------------------------------
|
||||
|
||||
Delete Server 的动作会涉及到负载均衡。被删除的 Server 上的资源单元会在同一个 Zone 中进行资源单元(Unit)迁移。Unit 的迁移动作是 Unit 自动均衡过程由 RootService 控制。Unit 均衡过程中可能发生资源不足,其他同 Zone 的机器资源不足容纳这个新迁移的 Unit。这样将导致 Unit 迁移失败,通过 `/home/admin/oceanbase/log/rootservice.log` 可以看到迁移 Unit 失败的错误代码 -4624。如果希望取消 Delete Server 动作,可以通过 Cancel Delete Server 操作实现。 Cancel Delete Server 操作的命令如下所示:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM CANCEL DELETE SERVER 'ip:port' [,'ip:port'...] [ZONE [=] 'zone']
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例语句如下所示:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM CANCEL DELETE SERVER "10.10.10.1:2882" zone='z1'
|
||||
```
|
||||
|
||||
|
||||
|
||||
操作限制说明
|
||||
---------------------------
|
||||
|
||||
对节点执行操作时:
|
||||
|
||||
* 不能跨 Zone 执行 Stop Server 操作,同一个 Zone 可以同时 Stop 多个 Server。
|
||||
|
||||
|
||||
|
||||
* 一个 Stop 操作发起没有结束前,不能发起第二个操作。
|
||||
|
||||
|
||||
|
||||
* `enable_auto_leader_switch`参数必须设置为开启。
|
||||
|
||||
* 分区副本满足多数派。
|
||||
|
||||
|
||||
|
||||
* 如果分区数多,或者被 Stop Server 的节点分区的 Leader 数量多, Alter System Stop Server 操作时间会比较长,如果超时,可以加大 SQL 超时时间。
|
||||
|
||||
|
||||
|
||||
* 如果命令很快失败,那么可能是日志不同步。
|
||||
|
||||
|
||||
|
||||
* 检查 `__all_rootservice_event_history `可以确认是否有 Stop Server 动作。
|
||||
|
||||
|
||||
|
||||
* Stop Server 后该 Server 的状态仍为 `Active` ,但 `stop_service_time `的值由 0 变为 Stop Server 的时间点。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,26 @@
|
||||
资源管理概述
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库是多租户的分布式数据库,租户使用的资源建立在资源池上。资源池包含了资源单元,而资源单元则规定了具体资源的量化(如 CPU、Memory、Disk_Size 和 IOPS 等)。 创建租户前,必须规定租户使用的资源范围,资源池和资源单元就是为了满足租户资源隔离和负载均衡而存在的。
|
||||
|
||||
下述是一些资源管理中的概念:
|
||||
|
||||
* 资源单元(Resource Unit,Unit)
|
||||
|
||||
资源单元是一个容器。实际上,副本是存储在资源单元之中的,所以资源单元是副本的容器。资源单元包含了计算存储资源(Memory、CPU 和 IO 等)同时资源单元也是集群负载均衡的一个基本单位,在集群节点上下线,扩容缩容时会动态调整资源单元在节点上的分布进而达到资源的使用均衡。
|
||||
|
||||
|
||||
* 资源池 (Resource Pool)
|
||||
|
||||
一个租户拥有若干个资源池,这些资源池的集合描述了这个租户所能使用的所有资源。一个资源池由具有相同资源规格(Unit Config)的若干个资源单元组成。一个资源池只能属于一个租户。每个资源单元描述了位于一个 Server 上的一组计算和存储资源,可以视为一个轻量级虚拟机,包括若干 CPU 资源、内存资源、磁盘资源等。一个租户在同一个 Server 上最多有一个资源单元。
|
||||
|
||||
|
||||
* 资源配置(Resource Config)
|
||||
|
||||
资源配置是资源单元的具体配置,包含资源单元所属的资源池信息、使用资源的租户信息、资源单元的配置信息(如 CPU 核数和内存资源)等。修改资源配置可以动态调整资源单元的计算资源,进而调整对应租户的资源。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
创建资源单元
|
||||
===========================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 创建资源单元。
|
||||
|
||||
通过 SQL 语句创建
|
||||
--------------------------------
|
||||
|
||||
租户使用的资源被限制在资源单元的范围内,如果当前存在的资源单元配置无法满足新租户的需要,可以新建资源单元。
|
||||
|
||||
下述为创建资源单元语句的语法:
|
||||
|
||||
```sql
|
||||
CREATE RESOURCE UNIT unitname
|
||||
MAX_CPU [=] cpunum,
|
||||
MAX_MEMORY [=] memsize,
|
||||
MAX_IOPS [=] iopsnum,
|
||||
MAX_DISK_SIZE [=] disksize,
|
||||
MAX_SESSION_NUM [=] sessionnum,
|
||||
[MIN_CPU [=] cpunum,]
|
||||
[MIN_MEMORY [=] memsize,]
|
||||
[MIN_IOPS [=] iopsnum] ;
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数说明和取值范围:
|
||||
|
||||
* 语法中提及的参数不能省略,必须指定 CPU、Memory、IOPS、Disk Size 和 Session Num 的大小。
|
||||
|
||||
|
||||
|
||||
* 为参数指定值时,可以采用纯数字不带引号的方式,也可以使用带单位加引号的方式(例如:`'1T'`、`'1G'`、`'1M'`、`'1K'`)。
|
||||
|
||||
例如: `max_memory='10G'` 等效于 `max_memory=10737418240`
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
为参数指定值时,不建议使用纯数字带引号的方式。
|
||||
|
||||
|
||||
* `MAX_MEMORY` 的取值范围为 \[1073741824,+∞),单位为字节,即最小值为 1 G。
|
||||
|
||||
|
||||
|
||||
* `MAX_IOPS` 的取值范围为 \[128,+∞)。
|
||||
|
||||
|
||||
|
||||
* `MAX_DISK_SIZE` 的取值范围为 \[536870912,+∞\],单位为字节,即最小值为 512 M。
|
||||
|
||||
|
||||
|
||||
* `MAX_SESSION_NUM` 的取值范围为 \[64,+∞)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
```sql
|
||||
obclient> CREATE RESOURCE UNIT unit1 max_cpu 1, max_memory '1G', max_iops 128,max_disk_size '10G', max_session_num 64, MIN_CPU=1, MIN_MEMORY='1G', MIN_IOPS=128;
|
||||
|
||||
obclient> CREATE RESOURCE UNIT unit1 max_cpu 1, max_memory 1073741824, max_iops 128, max_disk_size 10737418240, max_session_num 64, MIN_CPU=1, MIN_MEMORY=1073741824, MIN_IOPS=128;
|
||||
```
|
||||
|
||||
|
||||
|
||||
创建的资源单元实际上是资源单元的模版。可以被其他多个不同的资源池使用。比如,资源单元 `unit1` 创建后,可以创建资源池 `pool1` 和 `pool2` 并且 `pool1` 和 `pool2` 均使用 `unit1` 资源单元的配置。
|
||||
|
||||
通过 OCP 创建
|
||||
------------------------------
|
||||
|
||||
OCP 支持在创建租户时,为租户创建新的资源单元。创建租户相关操作请参见 [创建租户](https://open.oceanbase.com/docs/community/oceanbase-database/V3.1.0/create-a-user-tenant )。
|
||||
@ -0,0 +1,14 @@
|
||||
查看资源单元
|
||||
===========================
|
||||
|
||||
您可以通过数据库表查看集群中已存在的资源单元。
|
||||
|
||||
通过查询内部表可以获知当前集群中已经存在的资源单元信息。资源单元可以理解为服务器资源的使用模版。
|
||||
|
||||
下述为资源单元的查看语句:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_unit_config;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,30 @@
|
||||
修改资源单元
|
||||
===========================
|
||||
|
||||
修改资源单元的配置可以动态调整租户的资源单元大小,实现租户节点内的动态扩容或缩容功能。
|
||||
|
||||
在增加资源的过程中必须保证 OBServer 有足够的剩余资源可用于分配。可以通过内部表 `_all_virtual_server_stat` 查询节点总资源和已经分配的资源,然后通过计算可知是否可以修改资源单元。
|
||||
|
||||
下述为修改资源单元语句的语法:
|
||||
|
||||
```sql
|
||||
ALTER RESOURCE UNIT unitname
|
||||
MAX_CPU [=] cpunum,
|
||||
MAX_MEMORY [=] memsize,
|
||||
MAX_IOPS [=] iopsnum,
|
||||
MAX_DISK_SIZE [=] disksize,
|
||||
MAX_SESSION_NUM [=] sessionnum,
|
||||
[MIN_CPU [=] cpunum,]
|
||||
[MIN_MEMORY [=] memsize,]
|
||||
[MIN_IOPS [=] iopsnum] ;
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
```sql
|
||||
obclient> ALTER RESOURCE UNIT unit1 max_cpu 15, max_memory '20G', max_iops 128,max_disk_size '100G', max_session_num 64, MIN_CPU=10, MIN_MEMORY='10G', MIN_IOPS=128;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,15 @@
|
||||
删除资源单元
|
||||
===========================
|
||||
|
||||
您可以通过 SQL 语句删除不需要使用的资源单元。
|
||||
|
||||
删除资源单元的前提是必须确保当前资源单元未被使用。因此,删除资源单元需要将资源单元从资源池中移除。
|
||||
|
||||
删除资源单元的示例语句如下:
|
||||
|
||||
```sql
|
||||
obclient> DROP RESOURCE UNIT unitname;
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,34 @@
|
||||
创建资源池
|
||||
==========================
|
||||
|
||||
在创建新租户时,如果当前的资源池均被使用(被其他租户使用),需要创建新的资源池。
|
||||
|
||||
下述为创建资源池语句的语法:
|
||||
|
||||
```sql
|
||||
CREATE RESOURCE POOL poolname
|
||||
UNIT [=] unitname,
|
||||
UNIT_NUM [=] unitnum,
|
||||
ZONE_LIST [=] ('zone' [, 'zone' ...]);
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 参数 `unit_num` 表示在集群的一个 Zone 里面包含的资源单元个数。该值小于等于一个 Zone 中的 OBServer 的个数。
|
||||
|
||||
|
||||
|
||||
* 参数 `zone_list` 表示资源池的 Zone 列表,显示该资源池的资源在哪些 Zone 中被使用。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
```sql
|
||||
obclient> CREATE RESOURCE POOL pool1 unit='unit1', unit_num=1, zone_list=('zone1','zone2','zone3');
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,40 @@
|
||||
查看资源配置
|
||||
===========================
|
||||
|
||||
OceanBase 数据库支持通过视图或 OCP 来查看租户的资源配置情况。
|
||||
|
||||
通过视图查看
|
||||
---------------------------
|
||||
|
||||
执行以下 SQL 语句,查看资源配置。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM oceanbase.gv$unit;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 OCP 查看
|
||||
------------------------------
|
||||
|
||||
通过 OCP 可以查看指定租户的资源配置。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** 。
|
||||
|
||||
|
||||
|
||||
3. 在 **租户列表** 中找到指定租户,并单击租户名称。
|
||||
|
||||
|
||||
|
||||
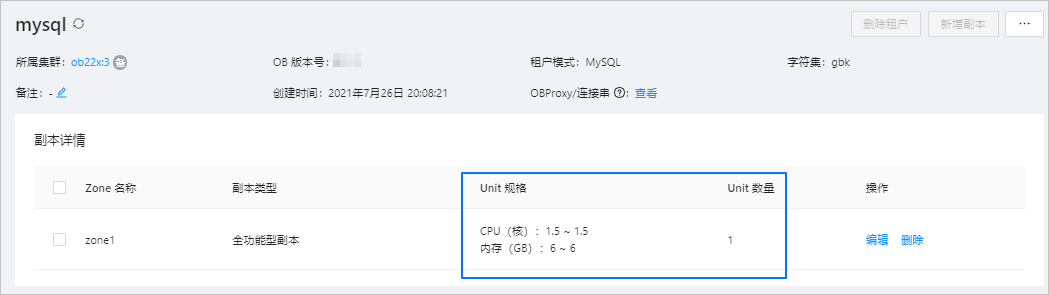
4. 在 **总览** 页面的 **副本详情** 区域,查看租户的资源配置,包括 Unit 规格和 Unit 数量。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
修改资源池
|
||||
==========================
|
||||
|
||||
资源池创建后,您可以根据业务需要修改资源池。
|
||||
|
||||
修改资源池可以实现租户的另一种扩容或缩容的方式。例如,在每个 Zone 中增加或减少节点数量,可以通过修改参数 `unit_num` 来实现。
|
||||
|
||||
通过 SQL 语句修改资源池
|
||||
-----------------------------------
|
||||
|
||||
下述为修改资源池语句的语法:
|
||||
|
||||
```sql
|
||||
ALTER RESOURCE POOL poolname
|
||||
UNIT [=] unitname,
|
||||
UNIT_NUM [=] unitnum,
|
||||
ZONE_LIST [=] ('zone' [, 'zone' ...]);
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改说明:
|
||||
|
||||
* 修改资源池的命令每次仅支持修改一个参数值。
|
||||
|
||||
|
||||
|
||||
* 被修改的资源池必须是没有被使用的或者不包含任何资源单元的空的资源池。
|
||||
|
||||
|
||||
|
||||
* 新创建的资源池不能更改 `zone_list`。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例如下:
|
||||
|
||||
* 修改资源池 `pool1` 的资源单元,修改后 `unit2` 替代 `unit1` 属于资源池` pool1`。
|
||||
|
||||
```sql
|
||||
obclient> ALTER RESOURCE POOL pool1 unit='unit2'
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 资源池 `pool1` 被使用中,尝试修改会报错。
|
||||
|
||||
```sql
|
||||
obclient> ALTER RESOURCE POOL pool1 zone_list=('HANGZHOU_1');
|
||||
ERROR 4179 (HY000): alter resource pool zone list with non-empty unit not allowed
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 同时修改资源池的两个参数时,会报错。
|
||||
|
||||
```sql
|
||||
obclient> ALTER RESOURCE POOL pool1 unit='unit1', zone_list=('HANGZHOU_1');
|
||||
ERROR 1235 (0A000): alter unit_num, resource_unit, zone_list in one cmd not supported
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 修改资源配置
|
||||
----------------------------------
|
||||
|
||||
OCP 内置了一套 Unit 规格,您可以根据需要修改指定租户的 Unit 规格和 Unit 数量。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
* 修改租户的 Unit 规格和 Unit 数量前,建议通过内部的 __all_virtual_server_stat 表对资源总体和已分配情况进行查询。
|
||||
|
||||
|
||||
|
||||
* Unit 数量不能超过该 Zone 下 Server 的个数。
|
||||
|
||||
|
||||
|
||||
* 不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** 。
|
||||
|
||||
|
||||
|
||||
3. 在 **租户列表** 中找到指定租户,并单击租户名称。
|
||||
|
||||
|
||||
|
||||
4. 在 **总览** 页面的 **副本详情** 区域,选择需要修改资源规格的 Zone,在对应的 **操作** 列中,单击 **编辑** **。**
|
||||
|
||||
|
||||
|
||||
5. 选择新的 Unit 规格以及 Unit 数量,单击 **确定** **。**
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,12 @@
|
||||
删除资源池
|
||||
==========================
|
||||
|
||||
OceanBase 数据库支持通过 SQL 语句删除不再使用的资源池。
|
||||
|
||||
下述为删除资源池的语句:
|
||||
|
||||
```sql
|
||||
obclient> DROP RESOURCE POOL poolname;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,8 @@
|
||||
租户管理概述
|
||||
===========================
|
||||
|
||||
OceanBase 数据库是支持多租户的,这里租户的概念类似于传统数据库的数据库实例。租户下可以建立数据库,在租户的数据库下可以建立表。
|
||||
|
||||
OceanBase 数据库目前仅支持 MySQL 租户。OceanBase 数据库支持租户隔离。每个租户可以被赋于一定的资源(比如 CPU、内存、IOPS 和磁盘空间)。OceanBase 集群初始内置了一个系统租户 sys,可以用来管理 OceanBase 集群。不同的租户可通过建立租户组的方式进行绑定。租户的资源是分配在资源池上的。通过资源配置和设定资源池可以实现对租户资源的控制。
|
||||
|
||||
租户支持租户级别的转储、租户级别的分区主切换和租户级别的扩容缩容。
|
||||
@ -0,0 +1,150 @@
|
||||
创建用户租户
|
||||
===========================
|
||||
|
||||
OceanBase 数据库面向多租户设计。 在一个大集群中,您可以创建很多租户,不同的部门使用不同的租户。租户和租户之间资源已经进行了隔离,保障了相互之间访问不受影响,类似于数据库中的实例。
|
||||
|
||||
背景
|
||||
-----------------------
|
||||
|
||||
MySQL 是一个单租户的模式 ,所有用户在一套资源池下进行使用,这可能会导致一种故障。当用户负载非常高时,应用将用尽数据库的所有资源,导致数据库管理员无法连接数据库,也无法执行一些高优先级的控制命令。例如无法执行 kill 命令杀死超时的查询,或者一些管理平台也无法连接到数据库等。
|
||||
|
||||
OceanBase 数据库默认会自动创建 sys 租户,sys 租户负责一部分 OceanBase 数据库的管理工作,并且能够访问系统元数据表,sys 自动预留了一定的资源。
|
||||
|
||||
创建租户
|
||||
-------------------------
|
||||
|
||||
1. 使用 `root` 账号登陆到 `sys` 租户中,使用 MySQL 或 OBClient 访问 OceanBase 数据库:
|
||||
|
||||
```unknow
|
||||
obclient -hxxxx -uroot@sys -P${port_num} -Doceanbase -A
|
||||
```
|
||||
|
||||
|
||||
|
||||
详细信息,参考 [OBClient 文档](https://github.com/oceanbase/obclient/blob/master/README.md)。
|
||||
|
||||
|
||||
2. 查询系统资源占用情况,例如:
|
||||
|
||||
```unknow
|
||||
mysql> SELECT svr_ip,svr_port, cpu_total, mem_total, disk_total, zone FROM __all_virtual_server_stat ;
|
||||
+--------------+----------+-----------+--------------+---------------+-------+
|
||||
| svr_ip | svr_port | cpu_total | mem_total | disk_total | zone |
|
||||
+--------------+----------+-----------+--------------+---------------+-------+
|
||||
| 172.31.122.2 | 33332 | 30 | 236223201280 | 1434105937920 | zone1 |
|
||||
| 172.31.122.3 | 33332 | 30 | 236223201280 | 1434105937920 | zone2 |
|
||||
| 172.31.122.1 | 33332 | 30 | 236223201280 | 1434105937920 | zone3 |
|
||||
+--------------+----------+-----------+--------------+---------------+-------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 查询系统资源分配:
|
||||
|
||||
```unknow
|
||||
mysql> SELECT sum(c.max_cpu), sum(c.max_memory) FROM __all_resource_pool as a, __all_unit_config AS c WHERE a.unit_config_id=c.unit_config_id;
|
||||
+----------------+-------------------+
|
||||
| sum(c.max_cpu) | sum(c.max_memory) |
|
||||
+----------------+-------------------+
|
||||
| 5 | 17179869184 |
|
||||
+----------------+-------------------+
|
||||
1 row in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. 创建资源单元。
|
||||
|
||||
如果想把剩下的所有资源全部使用掉,CPU 和内存分别为步骤 2 和步骤 3 得到的值, max_cpu值设置为第二步得到的cpu_total 减去第三步得到的sum(c.max_cpu), 在本例中为25; max_memory和min_memory 设置为第二步的到的mem_total 值 减去 第三步的到的sum(c.max_memory), 在本例中为219043332096。
|
||||
|
||||
```unknow
|
||||
mysql> CREATE RESOURCE UNIT unit1
|
||||
max_cpu = 25,
|
||||
max_memory = 219043332096,
|
||||
min_memory = 219043332096,
|
||||
max_iops = 10000,
|
||||
min_iops = 1280,
|
||||
max_session_num = 3000,
|
||||
max_disk_size = 214748364800 -- 200 GB
|
||||
;
|
||||
```
|
||||
|
||||
|
||||
|
||||
5. 创建资源池。
|
||||
|
||||
```unknow
|
||||
mysql> CREATE RESOURCE POOL pool1
|
||||
UNIT = 'unit1',
|
||||
UNIT_NUM = 1,
|
||||
ZONE_LIST = ('zone1', 'zone2', 'zone3')
|
||||
;
|
||||
```
|
||||
|
||||
|
||||
1. 每个资源池在每个 OBServer 上只能有一个资源单元。如果 `unit_num` 大于1,每个 zone 内都必须有和 `unit_num` 对应数目的机器。
|
||||
|
||||
|
||||
|
||||
2. ZoneList 一般与 zone 个数保持一致。
|
||||
|
||||
|
||||
|
||||
3. 如果在某个 zone 内找不到足够剩余资源的机器来创建资源单元,资源池会创建失败。
|
||||
|
||||
```unknow
|
||||
mysql> DROP RESOURCE POOL pool1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
详细信息,参考 [资源管理概述](../../../6.administrator-guide/3.basic-database-management/4.resource-management/1.resource-management-overview.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
6. 创建租户。
|
||||
|
||||
```unknow
|
||||
mysql> CREATE TENANT IF NOT EXISTS test_tenant
|
||||
charset='utf8mb4',
|
||||
replica_num=3,
|
||||
zone_list=('zone1','zone2','zone3'),
|
||||
primary_zone='RANDOM',
|
||||
resource_pool_list=('pool1')
|
||||
;
|
||||
```
|
||||
|
||||
|
||||
|
||||
PrimaryZone:指定主副本分配到 Zone 内的优先级,逗号两侧优先级相同分号,左侧优先级高于右侧。比如 zone1\>zone2=zone3,如果使用 RANDOM,则 Partition 的 Leader 随机分布。
|
||||
|
||||
详细信息,参考 [租户管理概述](../../../6.administrator-guide/3.basic-database-management/5.tenants/1.tenant-management-overview-1.md)。
|
||||
|
||||
|
||||
7. 登录租户之前,运行以下命令修改参数:
|
||||
|
||||
```unknow
|
||||
mysql> ALTER TENANT test_tenant SET VARIABLES ob_tcp_invited_nodes='%';
|
||||
```
|
||||
|
||||
|
||||
|
||||
8. 使用新的租户登录系统。
|
||||
|
||||
```unknow
|
||||
obclient -hxxxx -P${port_num} -uroot@test_tenant -A -c
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
创建用户
|
||||
-------------------------
|
||||
|
||||
首次使用新租户连接 OceanBase 数据库时,您必须使用 `root` 用户。成功连接后,您可以创建新用户连接 OceanBase 数据库。详细信息,参考 [创建用户](../../../6.administrator-guide/7.user-rights-management/2.create-user-3.md) 文档。
|
||||
|
||||
@ -0,0 +1,264 @@
|
||||
新建租户
|
||||
=========================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 来新建租户。
|
||||
|
||||
通过 SQL 语句新建
|
||||
--------------------------------
|
||||
|
||||
OceanBase 数据库仅支持 MySQL 类型的租户。只有用 root 用户连接到 sys 租户(`root@sys`)才能执行 `CREATE TENANT` 命令去创建租户。创建新租户后,可以指定创建租户的类型和白名单。
|
||||
|
||||
下述展示了创建租户命令的语法:
|
||||
|
||||
```sql
|
||||
CREATE TENANT [IF NOT EXISTS] tenantname
|
||||
[tenant_characteristic_list]
|
||||
[tenant_variables_list]
|
||||
|
||||
tenant_characteristic_list:
|
||||
tenant_characteristic [, tenant_characteristic...]
|
||||
|
||||
tenant_characteristic:
|
||||
COMMENT 'string'
|
||||
| {CHARACTER SET | CHARSET} [=] value
|
||||
| REPLICA_NUM [=] num
|
||||
| ZONE_LIST [=] (zone [, zone])
|
||||
| PRIMARY_ZONE [=] zone
|
||||
| RESOURCE_POOL_LIST [=] (poolname)
|
||||
| {READ ONLY | READ WRITE}
|
||||
|
||||
tenant_variables_list:
|
||||
SET sys_variables_list
|
||||
| SET VARIABLES sys_variables_list
|
||||
| VARIABLES sys_variables_list
|
||||
|
||||
sys_variables_list:
|
||||
sys_variables [, sys_variables...]
|
||||
|
||||
sys_variables:
|
||||
sys_variable_name = expr
|
||||
```
|
||||
|
||||
|
||||
|
||||
参数说明:
|
||||
|
||||
* 如果要创建的租户名已存在,并且没有指定 `IF NOT EXISTS`,则会出现错误。
|
||||
|
||||
|
||||
|
||||
* 租户名的合法性和变量名一致,最长 30 个字符,字符只能是大小写英文字母、数字和下划线,而且必须以字母或下划线开头,并且不能是 OceanBase 数据库的关键字。
|
||||
|
||||
|
||||
|
||||
* 在租户下可以指定资源池。
|
||||
|
||||
|
||||
|
||||
* `RESOURCE_POOL_LIST` 为创建租户时的必填项。
|
||||
|
||||
* `CREATE TENANT` 命令中的 `RESOURCE_POOL_LIST` 中,暂时仅支持一个资源池。
|
||||
|
||||
|
||||
|
||||
|
||||
**示例 1** :
|
||||
|
||||
下述语句展示了创建名为 `test_tenant` 的一个 3 副本的 MySQL 租户(创建新租户默认是 MySQL 租户)。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TENANT IF NOT EXISTS test_tenant charset='utf8mb4', replica_num=3, zone_list=('zone1','zone2','zone3'), primary_zone='zone1;zone2,zone3', resource_pool_list=('pool1')
|
||||
```
|
||||
|
||||
|
||||
|
||||
**示例 2** :
|
||||
|
||||
下述语句展示了创建租户后,直接通过修改变量 `ob_tcp_innvited_nodes` 的值为 `%` 以便允许任何客户端 IP 连接该租户。如果不调整,默认租户的连接方式为只允许本机的 IP 连接数据库。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TENANT IF NOT EXISTS test_tenant charset='utf8mb4', replica_num=3, zone_list=('zone1','zone2','zone3'), primary_zone='zone1;zone2,zone3', resource_pool_list=('pool1') SET ob_tcp_invited_nodes='%'
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例说明如下:
|
||||
|
||||
* `primary_zone` 指该租户的表的分区 Leader 所在的 Zone ,例如,`primary_ zone =' zone1; zone2, zone3'` 表示该租户的表的分区 Leader 在 `zone1` 上, 这时通过分号来分隔。
|
||||
|
||||
|
||||
|
||||
* `zone2` 和 `zone3` 通过逗号分割,表示 `zone2` 和 `zone3` 是同一优先级,但是比 `zone1` 优先级低。
|
||||
|
||||
|
||||
|
||||
* `primary_zone` 设置时,其值可以为 `RANDOM`(必须大写),表示随机。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
普通租户的内存最小规格必须大于等于 5 GB,否则创建租户失败。如果希望建立租户进行非常简单的功能测试,可以修改参数 `alter system __min_full_resource_pool_memory` 的值为 `1073741824` 来允许以最小 1 GB 内存的规格创建租户。
|
||||
|
||||
通过 OCP 新建
|
||||
------------------------------
|
||||
|
||||
可以通过 OCP 创建新的租户。
|
||||
**说明**
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在 **集群概览** 页面的 **集群列表** 区域,选择待操作的集群并单击其集群名。
|
||||
|
||||
|
||||
|
||||
3. 在显示的页面的左侧导航栏上,单击 **租户管理** 。
|
||||
|
||||
|
||||
|
||||
4. 在页面右上角单击 **新建租户** 。
|
||||
|
||||
|
||||
|
||||
|
||||
5. 填写基础信息。
|
||||
|
||||
1. 集群默认为当前集群。
|
||||
|
||||
|
||||
|
||||
2. 输入租户名称。
|
||||
|
||||
租户名称格式为英文大小写字母、数字和下划线的组合,长度为 2\~64 字符。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
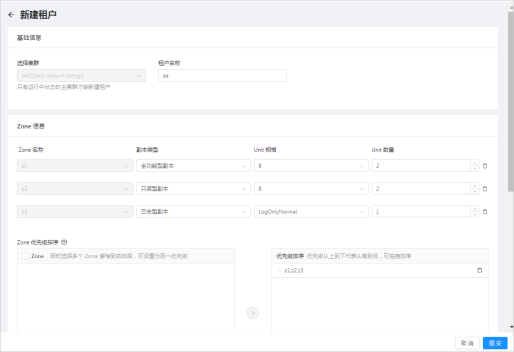
6. 填写 Zone 信息。
|
||||
|
||||
1. 为 z1、z2 和 z3 设置副本类型、Unit 规格和 Unit 数量。
|
||||
|
||||
集群选定后,页面会根据所选集群的 Zone 信息给出可配置的 Zone 列表;对于无需做副本分布的 Zone,可以通过最右侧的按钮删除该 Zone 条目。
|
||||
|
||||
其中:
|
||||
* 副本类型支持全功能型副本、只读型副本和日志型副本。
|
||||
|
||||
|
||||
|
||||
* OCP 内置了一套 Unit 规格;另外也可以在下拉列表的最下方单击 **新增规格** 按钮新增自定义规格。
|
||||
|
||||
|
||||
|
||||
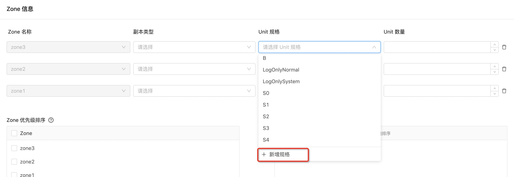
* 指定该 Zone 下的 Unit 数量。
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
Unit 数量不能超过该 Zone 下 Server个数。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
2. 对 Zone 优先级进行排序。
|
||||
|
||||
同时选择多个 Zone 添加到右侧后,可设置为同一优先级。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
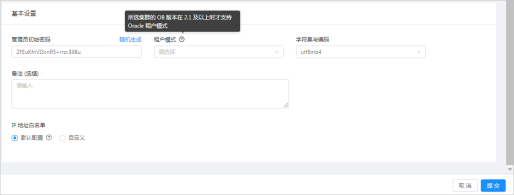
7. 填写基本设置信息。
|
||||
|
||||
1. 设置管理员初始密码,支持随机生成。
|
||||
|
||||
* 对于 MySQL 模式,其管理员账户为 **root** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
2. 设置租户模式。
|
||||
|
||||
* 仅支持 MySQL 租户模式。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
3. 设置字符集与编码。
|
||||
|
||||
* 对于 MySQL 模式,可选字符集有:utf8mb4、binary、gbk、gb18030。缺省为 utf8mb4。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
4. (可选)设置备注信息。
|
||||
|
||||
|
||||
|
||||
5. 设置 IP 地址白名单。
|
||||
|
||||
* 此处可以指定该租户允许登录的客户端列表。如果不指定,默认配置为 **%** ,表示允许所有的客户端。自定义白名单列表时需要注意,OCP 机器地址以及所依赖的 OBProxy 地址必须在此名单中,否则 OCP 将无法管理此租户。
|
||||
|
||||
* 默认配置:所有 IP 都可访问。
|
||||
|
||||
|
||||
|
||||
* 自定义:设置 IP 白名单,白名单中的 IP 才能访问。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 白名单格式说明:
|
||||
|
||||
* IP地址,示例:10.10.10.10,10.10.10.11
|
||||
|
||||
|
||||
|
||||
* 子网/掩码,示例:10.10.10.0/24
|
||||
|
||||
|
||||
|
||||
* 模糊匹配,示例:10.10.10.% 或 10.10.10._
|
||||
|
||||
|
||||
|
||||
* 多种格式混合,示例:10.10.10.10,10.10.10.11,10.10.10.%,10.10.10._,10.10.10.0/24
|
||||
|
||||
特殊说明: **%** 表示所有客户端都可以连接。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
8. 单击 **提交** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
查看租户
|
||||
=========================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 查看租户的信息。
|
||||
|
||||
通过 SQL 语句查看
|
||||
--------------------------------
|
||||
|
||||
在 OBClient 中登录集群的 sys 租户并执行以下语句,查看当前集群的租户信息。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM oceanbase.gv$tenant;
|
||||
```
|
||||
|
||||
|
||||
|
||||
普通租户还可以执行以下语句快速查看当前有哪些租户。
|
||||
|
||||
```sql
|
||||
obclient> SHOW TENANT;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 OCP 查看
|
||||
------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
您可以通过 OCP 查看指定租户的详细信息。
|
||||
|
||||
支持两种方法进行查看:
|
||||
|
||||
方法一:
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** **。**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
方法二:
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **集群** **。**
|
||||
|
||||
|
||||
|
||||
3. 在 **集群概览** 页面的 **集群列表** 区域中单击集群名,进入集群详情页。
|
||||
|
||||
|
||||
|
||||
4. 在左侧导航栏上,单击 **租户管理** ,查看租户的详细信息及监控数据。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
修改租户
|
||||
=========================
|
||||
|
||||
本节主要介绍如何修改租户的属性信息。
|
||||
|
||||
通过 SQL 语句修改租户
|
||||
----------------------------------
|
||||
|
||||
修改租户命令的语法如下:
|
||||
|
||||
```sql
|
||||
ALTER TENANT {tenant_name | ALL}
|
||||
[SET] [tenant_option_list] [opt_global_sys_vars_set]
|
||||
|
||||
tenant_option_list:
|
||||
tenant_option [, tenant_option ...]
|
||||
|
||||
tenant_option:
|
||||
COMMENT [=]'string'
|
||||
|{CHARACTER SET | CHARSET} [=] charsetname
|
||||
|COLLATE [=] collationname
|
||||
|REPLICA_NUM [=] num
|
||||
|ZONE_LIST [=] (zone [, zone...])
|
||||
|PRIMARY_ZONE [=] zone
|
||||
|RESOURCE_POOL_LIST [=](poolname [, poolname...])
|
||||
|DEFAULT TABLEGROUP [=] {NULL | tablegroupname}
|
||||
|{READ ONLY | READ WRITE}
|
||||
|LOGONLY_REPLICA_NUM [=] num
|
||||
|LOCALITY [=] 'locality description'
|
||||
|LOCK|UNLOCK;
|
||||
|
||||
opt_global_sys_vars_set:
|
||||
VARIABLES system_var_name = expr [,system_var_name = expr] ...
|
||||
```
|
||||
|
||||
|
||||
|
||||
锁定租户 `TENANT1` 的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TENANT TENANT1 LOCK;
|
||||
```
|
||||
|
||||
|
||||
|
||||
更多 `ALTER TENANT` 语句的信息请参见 [ALTER TENANT](../../../10.sql-reference/5.sql-statement/9.alter-tenant.md)。
|
||||
|
||||
通过 OCP 修改租户的白名单、密码和资源规格
|
||||
--------------------------------------------
|
||||
|
||||
通过 OCP 可以修改租户的白名单、密码、资源规格。同时租户的扩容和缩容也可以通过修改租户来实现。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
**扩容缩容说明**
|
||||
租户级别的扩容和缩容是通过修改租户的资源规格来实现的。 租户扩容常用于租户资源无法满足当前租户的需求,比如 CPU、内存资源紧张的情况。通过对租户的扩容可以整体动态的调整租户对集群资源的占用。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
* 对租户进行扩容的情况需要保证整体资源占用不操作上限。如果集群和节点的 CPU、内存资源已经完全分配给所有的租户。
|
||||
|
||||
|
||||
|
||||
* 此时无法对任何租户进行扩容。需要进行对某些租户的缩容,释放资源后在对目标租户进行扩容。
|
||||
|
||||
|
||||
|
||||
* 如果所有租户不能缩容,并且资源非配已满,此时不能进行租户扩容,必须进行集群级别的扩容(添加节点)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**修改租户操作步骤** :
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** 。
|
||||
|
||||
|
||||
|
||||
3. 在 **租户列表** 中找到指定租户,并单击租户名称。
|
||||
|
||||
|
||||
|
||||
4. 进行以下操作:
|
||||
|
||||
* 在页面右上角展开隐藏菜单,并单击 **修改密码** ,在弹出的对话框中,输入 2 次新密码后,单击 **确定** 。
|
||||
|
||||
|
||||
|
||||
* 在 **白名单** 区域右上角单击 **修改** ,然后在弹出的对话框中,请根据页面说明和配置说明,重新设置白名单,白名单设置的字符数不超 128 个字符,完成后单击 **确定** 。
|
||||
|
||||
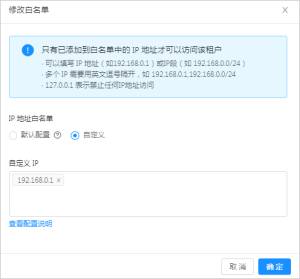
|
||||
|
||||
|
||||
* 在 **副本详情** 区域,选择需要修改资源规格的副本,在对应的 **操作** 列中,单击 **编辑** 后,修改副本的类型、Unit 规格以及 Unit 数量,单击 **确定** **。**
|
||||
|
||||
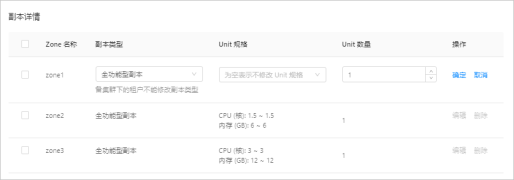
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
Unit 数量不能超过该 Zone 下 Server 的个数。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 锁定租户
|
||||
--------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
默认进入 **集群概览** 页面。
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** 。
|
||||
|
||||
|
||||
|
||||
3. 在 **租户列表** 中找到待锁定的租户,在对应的 **操作** 列中单击 **锁定** **。**
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
锁定租户操作会禁止新用户连接到该租户,请谨慎操作。
|
||||
|
||||
|
||||
|
||||
|
||||
4. 在弹出的确认框中,单击 **锁定** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
删除租户
|
||||
=========================
|
||||
|
||||
您可以通过 SQL 语句或 OCP 删除租户。
|
||||
|
||||
删除租户后,租户下的数据库和表也同时被删除。但是租户使用的资源配置不会被删除。资源配置可以继续给其他租户使用。
|
||||
|
||||
删除租户命令的语法:
|
||||
|
||||
```sql
|
||||
DROP TENANT | FORCE
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者
|
||||
|
||||
```sql
|
||||
DROP TENANT $tenant_name PURGE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中:
|
||||
|
||||
* 对于`DROP TENANT`操作:
|
||||
|
||||
* 当租户开启回收站功能时,`DROP TENANT`操作表示删除的租户会进入回收站。对于回收站中的租户,后续您可以通过租户级回收站功能进一步删除或恢复该租户,租户级回收站相关操作请参见 [租户级回收站](../../../6.administrator-guide/8.high-data-availability/1.recycle-bin-management/3.tenant-level-recycle-bin.md)。
|
||||
|
||||
|
||||
|
||||
* 当租户关闭回收站功能时,`DROP TENANT`操作表示延迟删除租户,后台线程会进行 GC 动作,租户的信息仍然可以通过内部表查询。租户具体延迟删除的时间由配置项`schema_history_expire_time`控制,默认为 7 天,`schema_history_expire_time`配置项更多信息请参见 [schema_history_expire_time](../../../14.reference-guide-oracle-mode/3.system-configuration-items-1/167.schema_history_expire_time.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* `DROP TENANT PURGE`操作表示仅延迟删除租户,且无论回收站功能是否开启,删除的租户均不进入回收站。
|
||||
|
||||
|
||||
|
||||
* `FORCE`参数表示无论回收站功能是否开启,均可以立刻删除租户。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例语句如下所示:
|
||||
|
||||
* 延迟删除租户 t1,删除的租户可进入回收站
|
||||
|
||||
```sql
|
||||
obclient> DROP TENANT t1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 延迟删除租户 t1,删除的租户不进入回收站
|
||||
|
||||
```sql
|
||||
obclient> DROP TENANT t1 PURGE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 立刻删除租户 t1
|
||||
|
||||
```sql
|
||||
obclient> DROP TENANT t1 FORCE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,91 @@
|
||||
查看租户会话
|
||||
===========================
|
||||
|
||||
您可以通过 SQL 语句和 OCP 来查看租户会话。
|
||||
|
||||
通过 SQL 语句查看
|
||||
--------------------------------
|
||||
|
||||
执行以下命令,查看租户当前会话。
|
||||
|
||||
```sql
|
||||
obclient> SHOW PROCESSLIST;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 OCP 查看会话
|
||||
--------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** **。**
|
||||
|
||||
默认进入租户 **总览** 页面。
|
||||
|
||||
|
||||
3. 在左侧导航栏上,单击 **会话管理** 。
|
||||
|
||||
**租户会话** 页签展示了租户当前的所有会话信息。包括会话 ID、SQL、用户、来源、数据库名、命令、执行时间(S)、状态和 OBProxy。
|
||||
|
||||
|
||||
4. 可以在 **租户会话** 页签进行进一步的查看:
|
||||
|
||||
* 在用户、来源、数据库名三列右侧,单击放大镜按钮,输入搜索关键字,搜索会话。
|
||||
|
||||
|
||||
|
||||
|
||||
* 勾选会话列表右上角的 **仅查看活跃会话** 按钮,会话列表会按照会话状态进行过滤,仅展示状态为 **ACTIVE** 的会话。
|
||||
|
||||
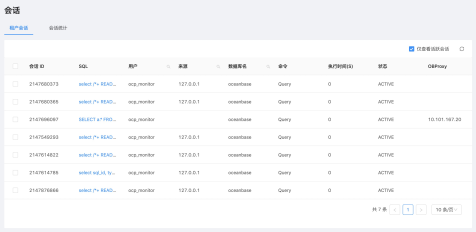
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 查看会话统计
|
||||
----------------------------------
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏中单击 **租户** **。**
|
||||
|
||||
默认进入租户 **总览** 页面。
|
||||
|
||||
|
||||
3. 在左侧导航栏上,单击 **会话管理** 。
|
||||
|
||||
|
||||
|
||||
4. 单击 **会话统计** 页签,进入 **会话统计** 页签。
|
||||
|
||||
**会话统计** 页签中展示租户当前的所有会话的统计信息,包括会话总数、活跃会话数、活跃会话最长时间等。支持按照用户、访问来源和数据库来统计用户的活跃会话数和会话总数。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
按访问来源统计功能仅支持 OceanBase 数据库 V2.2.30 及以上版本。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,20 @@
|
||||
终止租户会话
|
||||
===========================
|
||||
|
||||
OceanBase 数据库支持通过 `KILL` 语句终止租户会话。
|
||||
|
||||
执行以下命令,终止会话:
|
||||
|
||||
```sql
|
||||
obclient> KILL session_id;
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者
|
||||
|
||||
```sql
|
||||
obclient> KILL CONNECTION session_id;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,75 @@
|
||||
租户管理变量
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
租户的变量分为 Global 级别和 Session 级别。Session 级别的变量继承自 Global 级别的变量。同时,Session 建立后可以设定 Session 级别的变量。Session 级别的变量在 Session 中覆盖 Global 级别的变量。
|
||||
|
||||
查询变量
|
||||
-------------
|
||||
|
||||
下述展示查询 Session/Global 级别变量语句的语法:
|
||||
|
||||
```sql
|
||||
SHOW [GLOBAL] VARIABLES [SHOW_VARIABLES_OPTS]
|
||||
SHOW_VARIABLES_OPTS:
|
||||
[LIKE 'pattern' | WHERE expr]
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
```sql
|
||||
obclient> SHOW VARIABLES LIKE 'ob_query_timeout';
|
||||
|
||||
obclient> SHOW GLOBAL VARIABLES WHERE variable_name LIKE 'ob_query_timeout';
|
||||
```
|
||||
|
||||
|
||||
|
||||
sys 租户可以通过内部表 `__all_virtual_sys_variable` 查询其他所有普通租户的 Global 变量。
|
||||
|
||||
如果连接 sys 租户后再切换到普通租户,此时查询的 Session 级别变量仍然是 sys 租户的 Session 级别的变量。查询的 Global 级别的变量是切换后普通租户的 Global 级别变量。
|
||||
|
||||
设置变量
|
||||
-------------
|
||||
|
||||
设置 Session 级别的变量仅对当前 Session 有效,对其他 Session 无效。设置 Global 级别的变量对当前 Session 无效,需要重新登录建立新的 Session 才会生效。
|
||||
|
||||
下述展示设置 Session/Global 级别变量语句的语法:
|
||||
|
||||
```sql
|
||||
SET [GLOBAL] VARIABLE_NAME = 'VALUE'
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
```sql
|
||||
obclient> SET ob_query_timeout = 20000000;
|
||||
|
||||
obclient> SET GLOBAL ob_query_timeout = 20000000;
|
||||
```
|
||||
|
||||
|
||||
|
||||
变量中类型为 `INT`,并且在 `SHOW VARIABLE` 命令中显示 `ON/OFF` 或者 `True/False` 的变量,可以通过如下任意方法设置值:
|
||||
|
||||
```sql
|
||||
SET @@foreign_key_checks = ON
|
||||
|
||||
SET @@foreign_key_checks = 1
|
||||
|
||||
SET @@foreign_key
|
||||
```
|
||||
|
||||
|
||||
|
||||
以上三种方式的 Session 级别变量的设置是等效的。
|
||||
|
||||
更多变量参考信息,请参见 [系统变量参考](../../../14.reference-guide-oracle-mode/2.system-variable-1/2.auto_increment_increment-2.md)。
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,35 @@
|
||||
内存管理概述
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库是一个支持多租户架构的准内存级的分布式数据库,这对大容量内存的管理和使用提出了很高的要求。OceanBase 数据库采取占据服务器的大部分内存并进行统一管理的方式来管理内存。当有新业务需要上线时为其创建一个新租户,其中内存是从租户可分配内存中划分资源,租户 CPU 和内存的大小取决于业务规模。当可分配的 CPU 和内存资源不足时,应水平扩展 OceanBase 集群,为不断扩展的业务规模提供可持续的服务能力。
|
||||
|
||||
本章节将分篇介绍内存管理相关的以下内容:
|
||||
|
||||
* [OceanBase 内存结构](../../../6.administrator-guide/3.basic-database-management/6.memory-management/2.memory-structure-of-oceanbase.md)
|
||||
|
||||
|
||||
|
||||
* [OceanBase 内存上限](../../../6.administrator-guide/3.basic-database-management/6.memory-management/3.maximum-memory-for-oceanbase-databases.md)
|
||||
|
||||
|
||||
|
||||
* [系统内部内存管理](../../../6.administrator-guide/3.basic-database-management/6.memory-management/4.system-internal-memory-management.md)
|
||||
|
||||
|
||||
|
||||
* [租户内部内存管理](../../../6.administrator-guide/3.basic-database-management/6.memory-management/5.memory-management-within-a-tenant.md)
|
||||
|
||||
|
||||
|
||||
* [执行计划缓存](../../../6.administrator-guide/3.basic-database-management/6.memory-management/6.execution-plan-cache-1.md)
|
||||
|
||||
|
||||
|
||||
* [常见内存问题](../../../6.administrator-guide/3.basic-database-management/6.memory-management/7.common-memory-problems.md)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,10 @@
|
||||
OceanBase 内存结构
|
||||
===================================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库内存结构如下图所示:
|
||||
|
||||
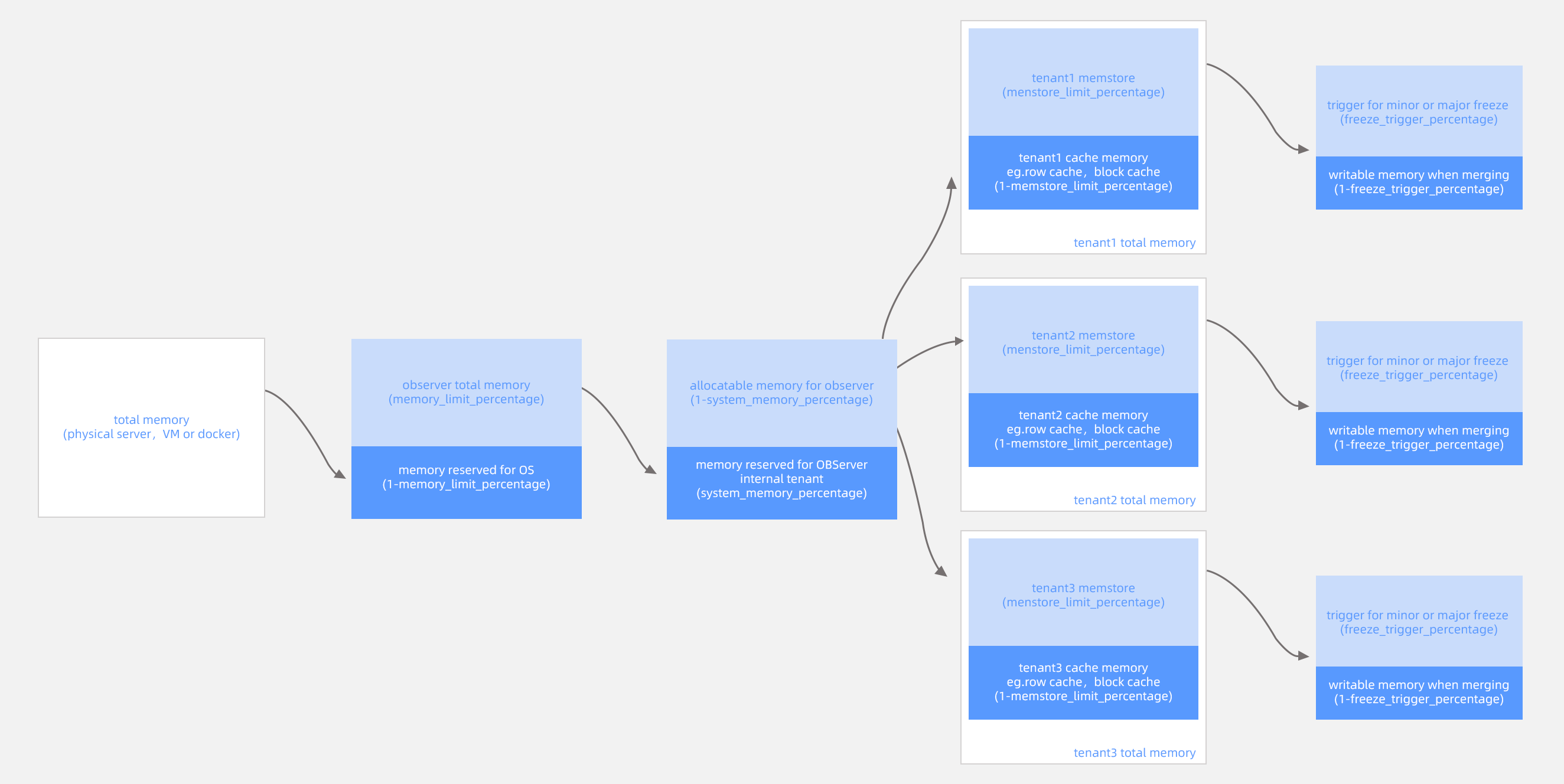
|
||||
|
||||
从上图可以看到,OceanBase 数据库占用了服务器的大量内存 (OBServer Total Memory),然后一部分用于自身系统运行(Memory Reserved For OBServer),一部分用于划分给创建的租户(Allocatable Memory For OBServer)。每个租户等同于传统数据库的一个实例,不同租户的内存模块组成是一样的,其内存又分为装载增量数据的 MemStore(Tenant MemStore)以及 KVCache 缓存(Tenant Cache Memory)。
|
||||
@ -0,0 +1,37 @@
|
||||
OceanBase 数据库内存上限
|
||||
======================================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库提供两种方式以设置自身内存的上限:
|
||||
|
||||
* 按照计算机器总内存上限的百分比计算自身可以使用的总内存,由 `memory_limit_percentage `参数配置。
|
||||
|
||||
|
||||
|
||||
* 直接设置 OceanBase 数据库可用内存的上限,由`memory_limit` 参数配置。其中`memory_limit` 参数值为 0 时,使用百分比的配置方式,否则使用绝对值的配置方式。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
下述表格示例了当在一台 100 GB 的机器上启动一个 OceanBase 数据库实例时,`memory_limit_percentage ` 和 `memory_limit` 参数的值是如何影响 OceanBase 数据库的内存上限的。
|
||||
|
||||
|
||||
| 示例 | **memory_limit_percentage** | **memory_limit** | **OceanBase 数据库内存上限** |
|
||||
|----------|-----------------------------|------------------|-----------------------|
|
||||
| **示例 1** | 80 | 0 | 80 GB |
|
||||
| **示例 2** | 80 | 90 GB | 90 GB |
|
||||
|
||||
|
||||
|
||||
示例 1 中由于 `memory_limit` 为 0,故以 `memory_limit_percentage` 为准,OceanBase 数据库内存上限为 100GB\*80%=80 GB。
|
||||
|
||||
示例2 中由于 `memory_limit` 为 90 GB,故以 `memory_limit` 为准,OceanBase 数据库内存上限为 90 GB。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
目前主流的 OceanBase 数据库服务器一般内存为 384 GB 或 512 GB,384 GB 内存建议配置为使用机器内存的 80%,512 GB 内存建议配置为使用机器内存的 90%。
|
||||
|
||||
@ -0,0 +1,8 @@
|
||||
系统内部内存管理
|
||||
=============================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库支持多租户架构,但是 OceanBase 数据库内存上限中配置的内容并不能全部分配给租户使用,因为每一个 OBServer 上租户都会共享部分资源或功能。由于这些共享的资源或功能所使用的内存并不属于任何一个普通租户,故这类内存被归结为系统内部内存。系统内部可使用的内存上限可通过`system_memory` 参数来配置,该参数表示系统内部可使用 OceanBase 数据库内存的上限。
|
||||
|
||||
例如,假设 OceanBase 数据库内存上限为 80 GB,`system_memory` 的值为 20 GB,那么可用于租户分配的内存就是剩下的 60 GB。
|
||||
@ -0,0 +1,91 @@
|
||||
租户内部内存管理
|
||||
=============================
|
||||
|
||||
|
||||
|
||||
租户内存默认占到 OceanBase 数据库内存上限的 80%,OceanBase 数据库把租户内部的内存总体上分为两个部分:
|
||||
|
||||
* 不可动态伸缩的内存 MemStore
|
||||
|
||||
|
||||
|
||||
* 可动态伸缩的内存 KVCache
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
其中,不可动态伸缩的内存主要给保存数据库增量更新的 MemStore 使用,可动态伸缩的内存主要由 KVCache 进行管理。可动态伸缩的 KVCache 会尽量使用除去不可动态伸缩后租户的全部内存。
|
||||
|
||||
除此之外,还有很多内存组件,包括 Plan Cache(执行计划缓存)、SQL Arena(SQL 执行期内存)、选举动作等,都要占用一定量的内存。您可以通过查询 `__all_virtual_memory_info `来获取所有内存组件的使用情况。
|
||||
|
||||
不可动态伸缩的内存管理
|
||||
--------------------
|
||||
|
||||
目前与不可动态伸缩内存相关的配置只有 `memstore_limit_percentage` ,它表示租户的 MemStore 部分最多占租户总内存上限的百分比,默认值为租户 MinMemory 的 50%。租户的写入或者更新会增加 MemStore 的内存使用,当租户的 MemStore 部分内存到达上限以后,后续的写入或者更新操作将会被拒绝。OceanBase 数据库会根据 MemStore 的内存使用比例决定何时进行转储或者合并释放 MemStore 的内存,该比例由配置项 `freeze_trigger_percentage` 控制,表示当 MemStore 内存占用到达其上限的百分比后就进行冻结(转储和合并的前置动作),默认值为租户 MemStore 内存上限的 70%,即租户 MinMemory 的 35%。
|
||||
|
||||
可动态伸缩的内存管理
|
||||
-------------------
|
||||
|
||||
可动态伸缩的内存主要部分是 KVCache。OceanBase 数据库将绝大多数的 KV 格式的缓存统一在了 KVCache 中进行管理,KVCache 支持动态伸缩、不同 KV 的优先级控制以及智能的淘汰机制。
|
||||
|
||||
KVCache 一般不需要配置,特殊场景下可以通过参数控制各种 KV 的优先级,优先级高的 KV 类比优先级低的 KV 类更容易被保留在 Cache 中。
|
||||
|
||||
用于控制 KV 优先级的参数如下表所示。参数值越大表示优先级越高。
|
||||
|
||||
|
||||
| 参数 | 含义 |
|
||||
|----------------------------------|----------------------|
|
||||
| fuse_row_cache_priority | 融合行缓存在缓存系统中的优先级。 |
|
||||
| location_cache_priority | 位置缓存在系统缓存服务中的优先级。 |
|
||||
| clog_cache_priority | 事务日志占用缓存的优先级。 |
|
||||
| index_clog_cache_priority | 事务日志索引在缓存系统中的优先级。 |
|
||||
| user_tab_col_stat_cache_priority | 统计数据缓存在缓存系统中的优先级。 |
|
||||
| index_cache_priority | 索引在缓存系统中的优先级。 |
|
||||
| index_info_block_cache_priority | 块索引在缓存系统中的优先级。 |
|
||||
| user_block_cache_priority | 数据块缓存在缓存系统中的优先级。 |
|
||||
| user_row_cache_priority | 基线数据行缓存在缓存系统中的优先级。 |
|
||||
| bf_cache_priority | Bloom Filter 的缓存优先级。 |
|
||||
|
||||
|
||||
|
||||
KVCache 中子 Cache 的信息可以通过查询 `__all_virtual_kvcache_info` 参数获得。其中 sys 和普通租户的重要组成部分略有不同:
|
||||
|
||||
* sys 租户上的 Cache 种类如下:
|
||||
|
||||
|
||||
|
||||
| 类别 | 说明 |
|
||||
|-------------------------|-----------------------------------------------------------|
|
||||
| schema_cache | 存放用户的 Schema 信息,用于提供 SQL 及系统正常运行所依赖的数据库对象的元信息。 |
|
||||
| location_cache | 存放分区的 location 信息,通过查询它可以知道一个 Partition 分布在哪些 OBServer 上。 |
|
||||
| block_index_cache | 缓存微块的 Index,加速微块数据的访问。 |
|
||||
| user_block_cache | 缓存微块数据,由于微块可能通过压缩算法进行压缩,为了提升查询性能,缓存的是解压后的微块数据。 |
|
||||
| fuse_row_cache | 缓存行的快照点数据,用于提高点查询性能,并且可以避免因转储、合并导致的缓存失效问题。 |
|
||||
| index_clog_cache | 缓存 ilog 文件的内容,用于减小读取 ilog 文件的开销。 |
|
||||
| user_tab_col_stat_cache | 用户表列统计信息缓存,用于 SQL 计算代价。 |
|
||||
| user_table_stat_cache | 用户表统计信息缓存,用于 SQL 计算代价。 |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 普通租户上的 Cache 种类如下:
|
||||
|
||||
|
||||
|
||||
| 类别 | 说明 |
|
||||
|-------------------|------------------------------------------------|
|
||||
| user_block_cache | 缓存微块数据,由于微块可能通过压缩算法进行压缩,为了提升查询性能,缓存的是解压后的微块数据。 |
|
||||
| block_index_cache | 缓存微块的 Index,加速微块数据的访问。 |
|
||||
| fuse_row_cache | 缓存行的快照点数据,用于提高点查询性能,并且可以避免因转储、合并导致的缓存失效问题。 |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
执行计划缓存
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
执行 `EXPLAIN` 语句看到的执行计划是预估的,在 Plan Cache 中缓存的执行计划才是真实的。Plan Cache 可以避免硬解析 SQL 语句,当同样的 SQL 请求到 OceanBase 数据库时,会从 Cache 中获得语句的已分析版本以加速语句执行。
|
||||
|
||||
与 Plan Cache 相关的配置项
|
||||
----------------------------
|
||||
|
||||
|
||||
|
||||
| 配置项 | 说明 |
|
||||
|---------------------------|-------------------------------------|
|
||||
| plan_cache_evict_interval | 该配置项用于设置检查执行计划是否需要淘汰的间隔时间,默认值为 30s。 |
|
||||
|
||||
|
||||
|
||||
与 Plan Cache 相关的系统变量
|
||||
-----------------------------
|
||||
|
||||
|
||||
|
||||
| 系统变量 | 说明 |
|
||||
|-------------------------------------|----------------------------------------------------------------------------------------------------------------------------|
|
||||
| ob_plan_cache_percentage | 该系统变量用于设置计划缓存可使用内存占租户内存的百分比。计划缓存最多可使用内存(内存上限绝对值)= 租户内存上限 \* ob_plan_cache_percentage/100,默认值为 5。 |
|
||||
| ob_plan_cache_evict_high_percentage | 该系统变量用于设置触发计划缓存淘汰的内存大小在内存上限绝对值的百分比。触发计划缓存淘汰的内存大小(淘汰计划的高水位线) = 内存上限绝对值 \* ob_plan_cache_evict_high_percentage/100,默认值为 90。 |
|
||||
| ob_plan_cache_evict_low_percentage | 该系统变量设置停止淘汰计划的内存。停止淘汰计划的内存(淘汰计划的低水位线) =内存上限绝对值 \* ob_plan_cache_evict_low_percentage/100,默认值为 50。 |
|
||||
|
||||
|
||||
|
||||
举例来讲,假如一个租户内存大小为 10 G, `ob_plan_cache_percentage` 的值为 10, `ob_plan_cache_evict_high_percentage` 的值为 90, `ob_plan_cache_evict_low_percentage` 的值为 50。则:
|
||||
|
||||
* 计划缓存内存上限绝对值 = 10 G \* 10 / 100 = 1 G
|
||||
|
||||
|
||||
|
||||
* 淘汰计划的高水位线 = 1 G \* 90 / 100 = 0.9 G
|
||||
|
||||
|
||||
|
||||
* 淘汰计划的低水位线 = 1 G \* 50 / 100 = 0.5 G
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当该租户在某个 OBServer 上的计划缓存使用超过 0.9 G 时,会触发淘汰,且优先淘汰最久未执行的计划。当淘汰到使用内存只有 0.5 G 时,则停止淘汰。如果淘汰速度没有新计划生成的速度快,则当计划缓存使用内存达到内存上限绝对值 1 G 时,将不再往计划缓存中添加新计划,直到淘汰后使用的内存小于 1 G 时才会再次添加新计划到计划缓存中。
|
||||
@ -0,0 +1,72 @@
|
||||
常见内存问题
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
1. `ERROR 4030 (HY000): OB-4030:Over tenant memory limits`。
|
||||
|
||||
当您看到上述错误信息时,首先需判断是不是 MemStore 内存超限,当 MemStore 内存超限时,需要检查数据写入是否过量或未做限流。当遇到大量写入且数据转储跟不上写入速度的时候就会报这种错误。运行下述语句查看内存状态:
|
||||
|
||||
```sql
|
||||
obclient> SELECT /*+ READ_CONSISTENCY(WEAK),query_timeout(100000000) */ TENANT_ID,IP,
|
||||
round(ACTIVE/1024/1024/1024,2)ACTIVE_GB,
|
||||
round(TOTAL/1024/1024/1024,2) TOTAL_GB,
|
||||
round(FREEZE_TRIGGER/1024/1024/1024,2) FREEZE_TRIGGER_GB,
|
||||
round(TOTAL/FREEZE_TRIGGER*100,2) percent_trigger,
|
||||
round(MEM_LIMIT/1024/1024/1024,2) MEM_LIMIT_GB
|
||||
FROM gv$memstore
|
||||
WHERE tenant_id >1000 OR TENANT_ID=1
|
||||
ORDER BY tenant_id,TOTAL_GB DESC;
|
||||
```
|
||||
|
||||
|
||||
|
||||
该问题的紧急应对措施是增加租户内存。问题解决之后需要分析原因,如果是因为未做限流引起,需要加上相应措施,然后回滚之前加上的租户内存动作。如果确实因为业务规模增长导致租户内存不足以支撑业务时,需要根据转储的频度设置合理的租户内存大小。如果 MemStore 内存未超限,运行下述语句判断是哪个内存模块超限:
|
||||
|
||||
```sql
|
||||
obclient> SELECT tenant_id,svr_ip,sum(hold) module_sum
|
||||
FROM __all_virtual_memory_info
|
||||
WHERE tenant_id>1000 AND hold<>0 AND
|
||||
mod_name NOT IN ( 'OB_KVSTORE_CACHE','OB_MEMSTORE')
|
||||
GROUP BY tenant_id,svr_ip;
|
||||
```
|
||||
|
||||
|
||||
|
||||
内存模块超限的判断标准是: `module_sum` \> 租户 `min_memory` \> 租户 MemStore。模块内存超限,可能需要先调整单独模块的内存,例如,调整 `ob_sql_work_area_percentage` 的值,如果租户内存过小,也需要增加租户内存。
|
||||
|
||||
|
||||
2. PLANCACHE 命中率低于 90%。
|
||||
|
||||
如果是 OLTP 系统 PLANCACHE 命中率应不低于 90%,运行下述语句查看 PLANCACHE 命中率:
|
||||
|
||||
```sql
|
||||
obclient> SELECT hit_count,executions,(hit_count/executions) as hit_ratio
|
||||
FROM v$plan_cache_plan_stat
|
||||
where (hit_count/executions) < 0.9;
|
||||
|
||||
SELECT hit_count,executions,(hit_count/executions) AS hit_ratio
|
||||
FROM v$plan_cache_plan_stat
|
||||
WHERE (hit_count/executions) < 0.9 AND executions > 1000;
|
||||
```
|
||||
|
||||
|
||||
|
||||
寻找是否有相似语句,例如 `in` 或 `not in` 后面的参数个数随机,导致大量浪费;如果不是上述情况,可能业务量或会话激增导致内存不足,需要调整租户内存大小。
|
||||
|
||||
|
||||
3. 日志中有 `fail to alloc memory` 或 `allocate memory fail` 等错误信息。
|
||||
|
||||
日志中会包含 `tenant_id` (租户编号)及 `mod_id` (内存模块编号)信息,可以通过以下语句查询具体的内存模块信息:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_virtual_memory_info WHERE mod_id=xxx AND tenant_id = xxx
|
||||
```
|
||||
|
||||
|
||||
|
||||
从第一个常见内存问题中可知,如果模块内存超限,可能需要先调整单独模块的内存。如果租户内存过小,还需要增加租户内存。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,24 @@
|
||||
关于表
|
||||
========================
|
||||
|
||||
本节主要介绍表的定义及设计原则。
|
||||
|
||||
在 OceanBase 数据库中,表是最基础的数据存储单元。表包含了所有用户可以访问的数据,每个表包含多行记录,每个记录由多个列组成。
|
||||
|
||||
在创建和使用表之前,管理员可以根据业务需求进行规划,主要需要遵循以下原则:
|
||||
|
||||
* 应规范化使用表,合理估算表结构,使数据冗余达到最小。
|
||||
|
||||
|
||||
|
||||
* 为表的每个列选择合适的 SQL 数据类型。
|
||||
|
||||
有关 SQL 数据类型的详细描述,请参见 《SQL 参考》。
|
||||
|
||||
|
||||
* 根据实际需求,创建合适类型的表,OceanBase 数据库当前支持非分区表和分区表。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,128 @@
|
||||
创建表
|
||||
========================
|
||||
|
||||
您可以使用 `CREATE TABLE` 语句来创建表。
|
||||
|
||||
本节主要介绍非分区表的创建,分区表的创建及使用请参见 [创建分区表](../../../6.administrator-guide/5.data-distribution-and-link-management/1.partition-table-and-partitioned-index-management/3.create-a-partition-table/1.level-1-partition-table-2.md) 章节。
|
||||
|
||||
创建非分区表
|
||||
---------------------------
|
||||
|
||||
创建非分区表是指创建只有一个分区的表。
|
||||
|
||||
创建非分区表的示例语句如下:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE table_name1(w_id int
|
||||
, w_ytd decimal(12,2)
|
||||
, w_tax decimal(4,4)
|
||||
, w_name varchar(10)
|
||||
, w_street_1 varchar(20)
|
||||
, w_street_2 varchar(20)
|
||||
, w_city varchar(20)
|
||||
, w_state char(2)
|
||||
, w_zip char(9)
|
||||
, unique(w_name, w_city)
|
||||
, primary key(w_id)
|
||||
);
|
||||
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE TABLE table_name2 (c_w_id int NOT NULL
|
||||
, c_d_id int NOT null
|
||||
, c_id int NOT null
|
||||
, c_discount decimal(4, 4)
|
||||
, c_credit char(2)
|
||||
, c_last varchar(16)
|
||||
, c_first varchar(16)
|
||||
, c_middle char(2)
|
||||
, c_balance decimal(12, 2)
|
||||
, c_ytd_payment decimal(12, 2)
|
||||
, c_payment_cnt int
|
||||
, c_credit_lim decimal(12, 2)
|
||||
, c_street_1 varchar(20)
|
||||
, c_street_2 varchar(20)
|
||||
, c_city varchar(20)
|
||||
, c_state char(2)
|
||||
, c_zip char(9)
|
||||
, c_phone char(16)
|
||||
, c_since date
|
||||
, c_delivery_cnt int
|
||||
, c_data varchar(500)
|
||||
, index icust(c_last, c_d_id, c_w_id, c_first, c_id)
|
||||
, FOREIGN KEY (c_w_id) REFERENCES table_name1(w_id)
|
||||
, primary key (c_w_id, c_d_id, c_id)
|
||||
);
|
||||
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例中创建了 2 个表,并同时对表中的列定义了一些约束信息,包括在不同列上创建的主键和外键等。更多主键、外键等的介绍,请参见 [定义列的约束类型](../../../6.administrator-guide/4.database-object-management-1/1.manage-tables/4.define-the-constraint-type-for-a-column.md) 章节。
|
||||
|
||||
有关 SQL 数据类型的详细描述,请参见《OceanBase 数据库 SQL参考》。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
* 基于性能和后期维护的需要,建议建表时为表设计主键或者唯一键。如果没有合适的字段作为主键,MySQL 模式中可以在创建表时不指定主键,待表创建成功后系统会为无主键表指定自增列作为隐藏主键。
|
||||
|
||||
|
||||
|
||||
* 由于 `ALTER TABLE` 语句不支持在后期增加主键,故在创建表时就需要设置主键。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
复制已有表的数据创建新表
|
||||
---------------------------------
|
||||
|
||||
在 OceanBase 数据库的 MySQL 模式下,可以使用 `CREATE TABLE AS SELECT` 语句复制表的数据,但是结构并不完全一致,并且会丢失约束、索引、默认值、分区等信息。
|
||||
|
||||
示例语句如下:
|
||||
|
||||
```unknow
|
||||
obclient>CREATE TABLE t1_copy AS SELECT * FROM t1;
|
||||
Query OK, 3 rows affected (0.12 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
还可以使用 `CREATE TABLE LIKE` 语句复制表结构,但是不能复制表数据。
|
||||
|
||||
示例语句如下:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t1_like like t1;
|
||||
Query OK, 0 rows affected (0.11 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
创建复制表
|
||||
--------------------------
|
||||
|
||||
复制表是 OceanBase 数据库的高级优化手段。
|
||||
|
||||
通常 OceanBase 集群是三副本架构,默认每个表的每个分区在 OceanBase 数据库中会有三个副本数据,在角色上分为一个主副本(Leader 副本)和两个备副本(Follower 副本),默认由主副本提供读写服务。
|
||||
|
||||
复制表可以在指定租户的每台机器上都有一个备副本,并且主副本与所有备份的数据使用全同步策略保持强同步。这样做的目的是为了让业务有些 SQL 关联查询时能在同一节点内部执行,以获取更好的性能。
|
||||
|
||||
复制表的语法是在 `CREATE TABLE` 语句后增加 `DUPLICATE_SCOPE` 选项。
|
||||
|
||||
示例语句如下:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE table_name (i_id int
|
||||
, i_name varchar(24)
|
||||
, i_price decimal(5,2)
|
||||
, i_data varchar(50)
|
||||
, i_im_id int
|
||||
, primary key(i_id)) COMPRESS FOR QUERY pctfree=0 BLOCK_SIZE=16384
|
||||
duplicate_scope='cluster' locality='F,R{all_server}@doc_1, F,R{all_server}@doc_2,F,R{all_server}@doc_3' primary_zone='doc_1';
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
定义自增列
|
||||
==========================
|
||||
|
||||
|
||||
|
||||
描述
|
||||
-----------------------
|
||||
|
||||
如果创建表时需要某个数值列的值不重复并且保持递增,这就是自增列。在 MySQL 租户里,列的类型可以定义为`AUTO_INCREMENT`,即 MySQL 租户的自增列。
|
||||
|
||||
自增列有三个重要属性,包括自增起始值、自增步长和自增列缓存大小,通过以下三个租户变量参数来控制。
|
||||
|
||||
|
||||
| 系统变量 | 说明 |
|
||||
|---------------------------|------------------------------------------------------|
|
||||
| auto_increment_cache_size | 用于设置自增的缓存个数,取值范围为 \[1, 100000000\],默认值为 1000000。 |
|
||||
| auto_increment_increment | 用于设置自增步长,取值范围为 \[1, 65535\],默认值为 1。 |
|
||||
| auto_increment_offset | 用于确定`AUTO_INCREMENT`列值的起点,取值范围为 \[1, 65535\],默认值为 1。 |
|
||||
|
||||
|
||||
|
||||
示例
|
||||
-----------------------
|
||||
|
||||
下面创建了一个自增列,在使用`INSERT`语句插入记录时不需要指定自增列,OceanBase 数据库会自动为该列填充值。
|
||||
|
||||
如果在`INSERT`时指定了自增列的值,且这个值为 0,则 OceanBase 数据库会用自增列的下一个值填充列的值;如果这个值比当前最大值小,则不影响自增列的下一个值的计算;如果这个值比当前值最大值大,则自增列会把插入值和自增列缓存值的和作为下次自增的起始值。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1(id bigint not null auto_increment primary key, name varchar(50), gmt_create timestamp not null default current_timestamp);
|
||||
Query OK, 0 rows affected (0.08 sec)
|
||||
|
||||
obclient> INSERT INTO t1(name) VALUES('A'),('B'),('C');
|
||||
Query OK, 3 rows affected (0.01 sec)
|
||||
Records: 3 Duplicates: 0 Warnings: 0
|
||||
|
||||
obclient> SELECT * FROM t1;
|
||||
+----+------+---------------------+
|
||||
| id | name | gmt_create |
|
||||
+----+------+---------------------+
|
||||
| 1 | A | 2020-04-03 17:09:55 |
|
||||
| 2 | B | 2020-04-03 17:09:55 |
|
||||
| 3 | C | 2020-04-03 17:09:55 |
|
||||
+----+------+---------------------+
|
||||
3 rows in set (0.01 sec)
|
||||
|
||||
obclient> INSERT INTO t1(id, name) VALUES(0, 'D');
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t1(id, name) VALUES(-1,'E');
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t1(id, name) VALUES(10,'F');
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient> INSERT INTO t1(name) VALUES('G');
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> SELECT * FROM t1;
|
||||
+---------+------+---------------------+
|
||||
| id | name | gmt_create |
|
||||
+---------+------+---------------------+
|
||||
| -1 | E | 2020-04-03 17:10:24 |
|
||||
| 1 | A | 2020-04-03 17:09:55 |
|
||||
| 2 | B | 2020-04-03 17:09:55 |
|
||||
| 3 | C | 2020-04-03 17:09:55 |
|
||||
| 4 | D | 2020-04-03 17:10:19 |
|
||||
| 10 | F | 2020-04-03 17:10:29 |
|
||||
| 1000011 | G | 2020-04-03 17:10:34 |
|
||||
+---------+------+---------------------+
|
||||
7 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,156 @@
|
||||
定义列的约束类型
|
||||
=============================
|
||||
|
||||
|
||||
|
||||
为了确保表里的数据符合业务规则,您可以在列上定义约束。
|
||||
|
||||
约束定义在列上,可以限制列里存储的值。当尝试在该列上写入或更新为违反约束定义的值时,会触发一个错误并回滚这个操作;当尝试在已有的表的列上加上一个跟现有数据相冲突的约束时,也会触发一个错误并回滚这个操作。
|
||||
|
||||
约束类型
|
||||
-------------------------
|
||||
|
||||
下面以 `ware` 表和 `cut` 表为例,介绍 OceanBase 数据库的约束类型。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE ware (w_id int
|
||||
, w_ytd decimal(12,2)
|
||||
, w_tax decimal(4,4)
|
||||
, w_name varchar(10)
|
||||
, w_street_1 varchar(20)
|
||||
, w_street_2 varchar(20)
|
||||
, w_city varchar(20)
|
||||
, w_state char(2)
|
||||
, w_zip char(9)
|
||||
, unique(w_name, w_city)
|
||||
, primary key(w_id)
|
||||
);
|
||||
|
||||
Query OK, 0 rows affected (0.09 sec)
|
||||
|
||||
obclient>CREATE TABLE cust (c_w_id int NOT NULL
|
||||
, c_d_id int NOT NULL
|
||||
, c_id int NOT NULL
|
||||
, c_discount decimal(4, 4)
|
||||
, c_credit char(2)
|
||||
, c_last varchar(16)
|
||||
, c_first varchar(16)
|
||||
, c_middle char(2)
|
||||
, c_balance decimal(12, 2)
|
||||
, c_ytd_payment decimal(12, 2)
|
||||
, c_payment_cnt int
|
||||
, c_credit_lim decimal(12, 2)
|
||||
, c_street_1 varchar(20)
|
||||
, c_street_2 varchar(20)
|
||||
, c_city varchar(20)
|
||||
, c_state char(2)
|
||||
, c_zip char(9)
|
||||
, c_phone char(16)
|
||||
, c_since date
|
||||
, c_delivery_cnt int
|
||||
, c_data varchar(500)
|
||||
, index icust(c_last, c_d_id, c_w_id, c_first, c_id)
|
||||
, FOREIGN KEY (c_w_id) REFERENCES table_name1(w_id)
|
||||
, primary key (c_w_id, c_d_id, c_id)
|
||||
);
|
||||
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 非空约束(`NOT NULL`):不允许约束包含的列的值为 `NULL`。
|
||||
|
||||
例如,`ware` 表的 `w_name` 列类型后面有 `NOT NULL` 约束,表示业务约束每个仓库必须有个名称。
|
||||
|
||||
有非空约束的列,在 `INSERT` 语句中必须指明该列的值,除非该列还定义了默认值。例如,`cust` 表的列 `c_discount` 定义了默认值 `0.99`,即业务上每个人默认折扣是 `0.99`。
|
||||
|
||||
|
||||
* 唯一约束(`UNIQUE`):不允许约束包含的列的值有重复值,但是可以有多个 `NULL` 值。
|
||||
|
||||
例如,`ware` 表的 `(w_name, w_city)` 列上有个唯一约束,表示每个城市里仓库的名称必须是不重复的。
|
||||
|
||||
|
||||
* 主键约束(`PRIMARY KEY`): `NOT NULL` 约束和唯一约束的组合。
|
||||
|
||||
例如,`ware` 表和 `cust` 表都有个主键 `w_id` 和 `c_id`,这两列不允许为 `NULL` 并且必须是不重复的。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE cust (c_w_id int NOT NULL,
|
||||
c_d_id int NOT NULL, c_id int NOT NULL,
|
||||
c_discount decimal(4, 4),
|
||||
c_credit char(2),
|
||||
c_last varchar(16),
|
||||
c_first varchar(16),
|
||||
c_middle char(2),
|
||||
c_balance decimal(12, 2),
|
||||
c_ytd_payment decimal(12, 2),
|
||||
c_payment_cnt int,
|
||||
c_credit_lim decimal(12, 2),
|
||||
c_street_1 varchar(20),
|
||||
c_street_2 varchar(20),
|
||||
c_city varchar(20),
|
||||
c_state char(2),
|
||||
c_zip char(9),
|
||||
c_phone char(16),
|
||||
c_since date,
|
||||
c_delivery_cnt int,
|
||||
c_data varchar(500),
|
||||
index icust(c_last, c_d_id, c_w_id, c_first, c_id),
|
||||
FOREIGN KEY (c_w_id) REFERENCES table_name1(w_id),
|
||||
primary key (c_w_id, c_d_id, c_id)
|
||||
);
|
||||
|
||||
Query OK, 0 rows affected (0.10 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 外键约束(`FOREIGN KEY`):要求约束的列的值取自于另外一个表的主键列。
|
||||
|
||||
例如,`cust` 表的 `c_w_id `上有个外键约束引用了 `ware` 表的 `w_id` 列,表示业务上顾客归属的仓库必须是属于仓库表里的仓库。
|
||||
|
||||
OceanBase 数据库默认开启了外键约束检查,外键约束检查开关由租户变量 `foreign_key_checks` 来控制。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
默认情况下,约束创建后为启用状态。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
目前 OceanBase 数据库不支持通过 `ALTER TABLE` 语句增加或修改约束,因此您需要在创建表时即确定好表的约束。
|
||||
|
||||
关于时间列的默认时间设置
|
||||
------------------------------
|
||||
|
||||
当列上有 `NOT NULL` 约束时,通常建议设置为默认值。当列类型是日期或时间类型时,可以设置默认值为数据库当前时间。
|
||||
|
||||
示例:为表的时间列设置默认值,可以使用 `sysdate` 或 `systimestamp` 函数。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1(
|
||||
id bigint not null primary KEY
|
||||
, gmt_create datetime not null default current_timestamp
|
||||
, gmt_modified datetime not null default current_timestamp
|
||||
);
|
||||
Query OK, 0 rows affected (0.07 sec)
|
||||
|
||||
obclient> INSERT INTO t1(id) VALUES(1),(2),(3);
|
||||
Query OK, 3 rows affected (0.01 sec)
|
||||
Records: 3 Duplicates: 0 Warnings: 0
|
||||
|
||||
obclient> SELECT * FROM t1;
|
||||
+----+---------------------+---------------------+
|
||||
| id | gmt_create | gmt_modified |
|
||||
+----+---------------------+---------------------+
|
||||
| 1 | 2020-02-27 17:09:23 | 2020-02-27 17:09:23 |
|
||||
| 2 | 2020-02-27 17:09:23 | 2020-02-27 17:09:23 |
|
||||
| 3 | 2020-02-27 17:09:23 | 2020-02-27 17:09:23 |
|
||||
+----+---------------------+---------------------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,14 @@
|
||||
查看表的定义
|
||||
===========================
|
||||
|
||||
表创建成功后,您可以通过 SQL 语句来查看表的定义。
|
||||
|
||||
MySQL 模式下,您可以使用 `SHOW CREATE TABLE` 语句查看表的定义。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> SHOW CREATE TABLE test;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,104 @@
|
||||
更改表
|
||||
========================
|
||||
|
||||
表创建成功后,您可以使用 `ALTER TABLE` 语句对表进行修改。
|
||||
|
||||
修改索引
|
||||
-------------------------
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
OceanBase 数据库的 MySQL 模式支持增加唯一索引和普通索引,同时还支持修改索引的属性。
|
||||
* 增加唯一索引
|
||||
|
||||
OceanBase 数据库支持在创建表后为表增加唯一索引。如果创建表时同时设置了主键,OceanBase 数据库会默认为主键列创建一个唯一索引。
|
||||
|
||||
增加唯一索引的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE test (c1 int PRIMARY KEY, c2 VARCHAR(50));
|
||||
Query OK, 0 rows affected (0.04 sec)
|
||||
|
||||
obclient> ALTER TABLE test ADD UNIQUE INDEX index_name(c2);
|
||||
Query OK, 0 rows affected (0.53 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 增加普通索引
|
||||
|
||||
OceanBase 数据库的 MySQL 模式支持一次增加多个索引,索引关键字用 `INDEX` 或 `KEY` 均可以。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE test (c1 int PRIMARY KEY, c2 VARCHAR(50));
|
||||
Query OK, 0 rows affected (0.04 sec)
|
||||
|
||||
obclient> ALTER TABLE test ADD INDEX myidx(c1,c2);
|
||||
Query OK, 0 rows affected (0.55 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 修改索引属性
|
||||
|
||||
OceanBase 数据库的 MySQL 模式支持将索引修改为可见或不可见,默认索引均可见,您可以将索引修改为不可见。
|
||||
|
||||
语法如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE test ALTER INDEX myidx INVISIBLE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
重命名表
|
||||
-------------------------
|
||||
|
||||
表创建成功后,您可以更改表名。
|
||||
|
||||
OceanBase 数据库的 MySQL 模式支持重命名表。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE test RENAME TO t1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
删除表组
|
||||
-------------------------
|
||||
|
||||
OceanBase 数据库的 MySQL 模式支持删除表所属的表组。
|
||||
|
||||
MySQL 模式下删除表组的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE test DROP TABLEGROUP grp1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
更多表组相关信息,请参见 [管理表组](../../../6.administrator-guide/4.database-object-management-1/2.manage-a-table-group/1.about-table-groups.md) 章节。
|
||||
|
||||
删除外键
|
||||
-------------------------
|
||||
|
||||
OceanBase 数据库的 MySQL 模式支持删除表的外键。
|
||||
|
||||
* MySQL 模式下删除表的外键示例
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE test DROP FOREIGN KEY fk_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
清空表
|
||||
========================
|
||||
|
||||
当表中的数据不再使用时,可以删除表中的所有行,即清空该表。
|
||||
|
||||
OceanBase 数据库支持使用 `TRUNCATE TABLE` 和 `DELETE FROM` 语句清空指定表,但是保留表结构,包括表中定义的分区信息。从逻辑上说,`TRUNCATE TABLE` 语句与用于删除所有行的 `DELETE FROM` 语句的执行结果相同。
|
||||
|
||||
使用 TRUNCATE TABLE 语句
|
||||
-----------------------------------------
|
||||
|
||||
`TRUNCATE TABLE` 语句提供了一种快速、有效删除表中所有行的方法,同时 `TRUNCATE TABLE` 语句是一个 DDL 语句,不会产生任何回滚信息。
|
||||
|
||||
执行 `TRUNCATE TABLE` 语句需要具备该表的删除和创建权限。
|
||||
|
||||
```sql
|
||||
obclient>TRUNCATE TABLE table_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
使用 DELETE FROM 语句
|
||||
--------------------------------------
|
||||
|
||||
也可以使用 `DELETE FROM` 语句删除表中的行。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient>DELETE FROM table_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
使用 `DELETE FROM` 语句清空表时,如果表有很多行,会消耗较多系统资源。
|
||||
|
||||
TRUNCATE TABLE 语句与 DELETE FROM语句的差异
|
||||
--------------------------------------------------------
|
||||
|
||||
`TRUNCATE TABLE` 语句与 `DELETE FROM` 语句的差异如下:
|
||||
|
||||
* `TRUNCATE TABLE` 操作会删除并重新创建表,比一行一行地删除行要快很多。
|
||||
|
||||
|
||||
|
||||
* `TRUNCATE TABLE` 语句的执行结果显示影响行数始终为 0 行。
|
||||
|
||||
|
||||
|
||||
* 使用 `TRUNCATE TABLE` 语句时,表管理程序不会记录最后被使用的 `AUTO_INCREMENT` 值,但是会从头开始计数。
|
||||
|
||||
|
||||
|
||||
* 不支持在进行事务处理和表锁定的过程中执行 `TRUNCATE TABLE` 操作。
|
||||
|
||||
|
||||
|
||||
* 只要表定义文件合法,就可以使用 `TRUNCATE TABLE` 语句将表重新创建为一个空表,即使数据或索引文件已经被破坏。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,42 @@
|
||||
删除表
|
||||
========================
|
||||
|
||||
当一个表不再使用时,可以使用 `DROP TABLE` 语句将其删除。
|
||||
|
||||
MySQL 模式
|
||||
-----------------------------
|
||||
|
||||
删除表的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> DROP TABLE test;
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者
|
||||
|
||||
```sql
|
||||
obclient> DROP TABLE IF EXISTS test;
|
||||
```
|
||||
|
||||
|
||||
|
||||
在删除表时,如果指定了 ` EXISTS`,即使要删除的表不存在也不会报错;如果不指定 `IF EXISTS`,则会报错。
|
||||
|
||||
操作说明
|
||||
-------------------------
|
||||
|
||||
对于 `DROP TABLE` 操作:
|
||||
|
||||
* 当租户关闭回收站功能时,`DROP TABLE` 操作表示删除表。回收站开关由系统变量 `recyclebin` 控制,默认为关闭状态。
|
||||
|
||||
|
||||
|
||||
* 当租户开启回收站功能时,`DROP TABLE` 操作表示删除的表会进入回收站。对于回收站中的表,后续您可以通过回收站功能进一步删除或恢复该表,回收站相关操作请参见 [数据库、表和索引级回收站](../../../6.administrator-guide/8.high-data-availability/1.recycle-bin-management/2.database-table-and-index-level-recycle-bin-1.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
关于表组
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
表组(Table Group)不是一个的物理对象,它是一个逻辑概念,表示一组表或者表的集合。属于这样一个集合的表需要满足一定的约束,即所有表必须拥有相同的 Locality(副本类型、个数及位置)、相同的 Primary Zone(Leader 位置及其优先级)以及相同的分区方式。
|
||||
|
||||
通过定义表组,您可以控制一组表在物理存储上的临近关系。对于包含分区表的表组,它由若干个分区组(Partition Group) 组成,每一个 Partition Group 包含每个分区表的一个分区。属于同一个 Partition Group 的所有 Partition 系统会通过自动调度使得它们位于同一台 OBServer 服务器上,且这些分区副本的 Leader 也位于一台 OBServer 上。
|
||||
|
||||
表组中所有表的限制说明:
|
||||
|
||||
* 分区类型需相同。
|
||||
|
||||
|
||||
|
||||
* 如果是 Key 分区,要求引用的列数相同,且分区个数相同(不要求列名相同)。
|
||||
|
||||
|
||||
|
||||
* 如果是 Hash 分区,要求分区个数相同。
|
||||
|
||||
|
||||
|
||||
* 如果是 Range Columns分区,要求引用的列数相同和分区数相同,且 Range 分割点相同(各 value 的规则相同)。
|
||||
|
||||
|
||||
|
||||
* 如果是 Range 分区,要求分区数相同,且 Range 分割点相同(各 value 的规则相同)。
|
||||
|
||||
|
||||
|
||||
* 对于二级分区,根据分区类型,限制如下:
|
||||
|
||||
* 如果是 Key 分区,要求引用的列数相同,且分区个数相同(不要求列名相同)。
|
||||
|
||||
|
||||
|
||||
* 如果是 Hash 分区,要求分区个数相同。
|
||||
|
||||
|
||||
|
||||
* 如果是 Range Columns分区,要求引用的列数相同和分区数相同,且 Range 分割点相同(各 value 的规则相同)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 分区增减只支持 Range 分区的表组。
|
||||
|
||||
|
||||
|
||||
* 无法通过 `ALTER TABLE SET table group `或 `ALTER TABLE GROUP add table` 语句表迁入到 OceanBase 数据库 V2.x.x 之前创建的表组中。
|
||||
|
||||
|
||||
|
||||
* 任何时候,将表加入 OceanBase 数据库 V2.x.x 之后创建的表组时,都会进行校验。如检查分区方式、Primary Zone 和 Locality 是否匹配。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
表组管理命令
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
通过修改表的 `TABLEGROUP` 属性,可以把一个表加入或移出一个表组,或者改变其 `TABLEGROUP` 属性。修改了表的 `TABLEGROUP` 属性以后,RootService 会在后台执行副本的迁移,把属于同一个分组组的副本调度到同一台机器上,并发起命令把这些分区并入一个复制组(Replication Group)中。
|
||||
|
||||
创建表组
|
||||
-------------------------
|
||||
|
||||
创建表组 `grp1` 的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLEGROUP grp1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
移出表组
|
||||
-------------
|
||||
|
||||
将表 `t1` 移出表组的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE t1 SET TABLEGROUP '';
|
||||
```
|
||||
|
||||
|
||||
|
||||
迁入表组
|
||||
-------------
|
||||
|
||||
将表 `t1` 加入表组 `grp1` 的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE t1 SET TABLEGROUP grp1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
迁移表组
|
||||
-------------
|
||||
|
||||
将表 `t1`(原先在表组 `grp1` 中) 迁移进表组 `grp2` 的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE t1 SET TABLEGROUP grp2;
|
||||
```
|
||||
|
||||
|
||||
|
||||
删除表组
|
||||
-------------
|
||||
|
||||
下述为删除表组语句的语法,但是如果有任何表的 `TABLE GROUP` 属性引用了目标表组,则该表组不允许被删除。
|
||||
|
||||
```sql
|
||||
obclient> DROP TABLEGROUP grp1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改分区方式
|
||||
---------------
|
||||
|
||||
对于属于某一个表组的表,不允许使用 `ALTER TABLE` 直接修改该表的分区方式、Locality 和 Primary Zone 属性。必须使用 `ALTER TABLEGROUP` 语句来进行操作。
|
||||
|
||||
修改一个表组的分区方式、Locality 和 Primary Zone 属性时,实际上会同时原子地修改属于这个表组中所有表的对应属性。
|
||||
|
||||
修改 Locality
|
||||
--------------------
|
||||
|
||||
将表组 `grp1` 中所有表的 Locality 都修改为 `F@z1,F@z3` 的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLEGROUP grp1 SET locality = 'F@z1,F@z3';
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改 Primary Zone
|
||||
------------------------
|
||||
|
||||
将表组 `grp1` 中所有表的 Primary Zone 都修改为 `z1,z2` 的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLEGROUP grp1 SET primary_zone = 'z1,z2';
|
||||
```
|
||||
|
||||
|
||||
|
||||
删除分区
|
||||
-------------
|
||||
|
||||
将表组 `grp1` 中所有表的 `p0` 和 `p1`分区都删除的示例如下,该操作仅支持 Range 分区。
|
||||
|
||||
其中,`p0` 和 `p1` 是创建表组时为 Range 分区指定的分区名,而不是每个表上的分区名,系统根据 Range 分割点能够找到每个表对应的分区。
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLEGROUP grp1 DROP PARTITION (p0,p1);
|
||||
```
|
||||
|
||||
|
||||
|
||||
增加分区
|
||||
-------------
|
||||
|
||||
为表组 `grp1` 中所有表都增加一个 `p4` 分区的示例如下,该操作仅支持 Range 分区。
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLEGROUP grp1 ADD PARTITION (PARTITION p4 VALUES LESS THAN (200));
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,8 @@
|
||||
关于索引
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
表创建成功后,可以在表的一个或多个列上创建索引以加速表上的 SQL 语句执行速度。索引使用正确的话,可以减少物理 IO 或者逻辑 IO。
|
||||
|
||||
OceanBase 数据库的表存储模型为索引聚集表模型,如果用户未指定主键,系统会自动生成一个隐藏主键。
|
||||
@ -0,0 +1,49 @@
|
||||
创建索引
|
||||
=========================
|
||||
|
||||
本节主要介绍如何通过 `CREATE INDEX` 语句在非分区表上创建索引,分区表上索引的创建请参见 [局部索引](../../../6.administrator-guide/5.data-distribution-and-link-management/1.partition-table-and-partitioned-index-management/6.create-an-index-on-a-partition-table/1.local-index.md)章节。
|
||||
|
||||
OceanBase 数据库支持在非分区表和分区表上创建索引,索引可以是局部索引或全局索引,也可以是唯一索引或普通索引。如果是分区表的唯一索引,则唯一索引必须包含表分区的拆分键。
|
||||
|
||||
MySQL 模式下,创建索引的 SQL 语法格式如下:
|
||||
|
||||
```sql
|
||||
CREATE [UNIQUE] INDEX index_name ON table_name ( column_list ) [LOCAL | GLOBAL] [ PARTITION BY column_list PARTITIONS N ] ;
|
||||
```
|
||||
|
||||
|
||||
|
||||
MySQL 租户里,索引名称在表范围内不能重复,查看索引可以通过命令 `SHOW INDEX`。
|
||||
|
||||
在 MySQL 租户里,新增索引还有一种方法,其 SQL 语法格式如下:
|
||||
|
||||
```sql
|
||||
ALTER TABLE table_name
|
||||
ADD INDEX|KEY index_name ( column_list ) ;
|
||||
```
|
||||
|
||||
|
||||
|
||||
该语句可以一次增加多个索引,索引关键字用 `INDEX` 或 `KEY` 都可以。
|
||||
|
||||
示例:为非分区表创建普通索引。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE test (c1 int primary key, c2 VARCHAR(10));
|
||||
Query OK, 0 rows affected (0.20 sec)
|
||||
|
||||
obclient> CREATE INDEX idx ON test (c1, c2);
|
||||
Query OK, 0 rows affected (0.59 sec)
|
||||
|
||||
obclient> SHOW INDEX FROM test;
|
||||
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+
|
||||
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible |
|
||||
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+
|
||||
| test | 0 | PRIMARY | 1 | c1 | A | NULL | NULL | NULL | | BTREE | available | | YES |
|
||||
| test | 1 | idx | 1 | c1 | A | NULL | NULL | NULL | | BTREE | available | | YES |
|
||||
| test | 1 | idx | 2 | c2 | A | NULL | NULL | NULL | YES | BTREE | available | | YES |
|
||||
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,14 @@
|
||||
查看索引
|
||||
=========================
|
||||
|
||||
本节主要介绍索引的查看方法。
|
||||
|
||||
MySQL 模式下,可以使用 `SHOW INDEX `语句查看表的索引。
|
||||
|
||||
示例:查看表 test 的索引。
|
||||
|
||||
```sql
|
||||
obclient> SHOW INDEX FROM test;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,29 @@
|
||||
删除索引
|
||||
=========================
|
||||
|
||||
当索引过多时,维护开销会增大,您可以根据需要删除不必要的索引。
|
||||
|
||||
MySQL 模式下,删除索引的语法格式如下:
|
||||
|
||||
```sql
|
||||
ALTER TABLE table_name DROP key|index index_name ;
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者
|
||||
|
||||
```sql
|
||||
DROP INDEX index_name ON table_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
删除表的索引的示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE t3 DROP KEY t3_uk, DROP KEY t3_ind3;
|
||||
Query OK, 0 rows affected (0.07 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
管理视图
|
||||
=========================
|
||||
|
||||
本节主要介绍如何创建、修改和删除视图。
|
||||
|
||||
视图用来展示表的查询结果。大部分能使用表的地方,都可以使用视图。如果经常访问的数据分布在多个表里时,使用视图是最好的方法。
|
||||
|
||||
创建视图
|
||||
-------------------------
|
||||
|
||||
您可以使用 `CREATE VIEW` 语句来创建视图。
|
||||
|
||||
示例:创建视图 stock_item。该视图内容取自 stock 和 item 两张表,两张表做表连接即可得到该视图。
|
||||
|
||||
```sql
|
||||
obclient> CREATE VIEW stock_item
|
||||
AS
|
||||
SELECT /*+ leading(s) use_merge(i) */
|
||||
i_price, i_name, i_data, s_i_id, s_w_id, s_order_cnt, s_ytd, s_remote_cnt, s_quantity, s_data, s_dist_01, s_dist_02, s_dist_03, s_dist_04, s_dist_05, s_dist_06, s_dist_07, s_dist_08, s_dist_09, s_dist_10
|
||||
FROM stok s, item i
|
||||
WHERE s.s_i_id = i.i_id;
|
||||
Query OK, 0 rows affected (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改视图
|
||||
-------------------------
|
||||
|
||||
您可以使用 `CREATE OR REPLACE VIEW` 语句来对视图进行修改。
|
||||
|
||||
示例:修改视图 stock_item。
|
||||
|
||||
```sql
|
||||
obclient> CREATE OR REPLACE VIEW stock_item
|
||||
AS
|
||||
SELECT /*+ leading(s) use_merge(i) */
|
||||
i_price, i_name, i_data, s_i_id, s_w_id, s_order_cnt, s_ytd, s_remote_cnt, s_quantity, s_data, s_dist_01, s_dist_02, s_dist_03, s_dist_04, s_dist_05, s_dist_06, s_dist_07, s_dist_08, s_dist_09, s_dist_10
|
||||
FROM stok s, item i
|
||||
WHERE s.s_i_id = i.i_id;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
删除视图
|
||||
-------------------------
|
||||
|
||||
您可以使用 `DROP VIEW` 语句删除一个或多个视图,删除视图并不会删除视图引用的表。
|
||||
|
||||
如果当前视图被其他视图所引用,则视图删除后将会导致依赖当前视图的其他视图的查询失败。
|
||||
|
||||
删除视图时,需确保当前用户具备该视图的 DROP 权限。
|
||||
|
||||
示例:删除视图 V1。
|
||||
|
||||
```sql
|
||||
obclient> DROP VIEW V1;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
管理同义词
|
||||
==========================
|
||||
|
||||
本节主要介绍如何创建和删除同义词。
|
||||
|
||||
在 OceanBase 数据库中,同义词是一个租户数据库对象的别名。使用同义词通常是为了管理权限方便,因为同义词可以隐藏另外一个数据对象的所有者权限。
|
||||
|
||||
创建同义词
|
||||
--------------------------
|
||||
|
||||
您可以使用 `CREATE SYNONYM` 语句来创建同义词。
|
||||
|
||||
创建同义词时:
|
||||
|
||||
* 如果在当前数据库创建私有同义词,则当前用户需要具备 `CREATE SYNONYM` 权限。
|
||||
|
||||
|
||||
|
||||
* 如果在非当前数据库创建私有同义词,则当前用户需要具备以下权限:
|
||||
|
||||
* MySQL 模式:`CREATE SYNONYM` 权限
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 如果创建公共同义词,则当前用户需要具备以下权限:
|
||||
|
||||
* MySQL 模式:`CREATE SYNONYM` 权限
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 创建同义词的对象可以不存在,当前用户也不需要具有该对象的访问权限。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
创建同义词的语法格式如下:
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
```sql
|
||||
CREATE [ OR REPLACE ] [ PUBLIC ] SYNONYM [ DATABASE. ]synonym FOR [ DATABASE. ]object;
|
||||
```
|
||||
|
||||
|
||||
|
||||
MySQL 模式下 `CREATE SYNONYM` 语句的更多信息,请参见《SQL 参考》文档中的 [CREATE SYNONYM](../../../10.sql-reference/5.sql-statement/17.create-synonym.md) 章节。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
* 创建一个私有同义词。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE test(c1 int);
|
||||
Query OK, 0 rows affected (0.18 sec)
|
||||
|
||||
obclient> CREATE SYNONYM s1 for test;
|
||||
Query OK, 0 rows affected (0.05 sec)
|
||||
|
||||
obclient> INSERT INTO s1 VALUES(1);
|
||||
Query OK, 1 row affected (0.02 sec)
|
||||
|
||||
obclient> SELECT * FROM s1;
|
||||
+------+
|
||||
| c1 |
|
||||
+------+
|
||||
| 1 |
|
||||
+------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 创建一个公共同义词。
|
||||
|
||||
```sql
|
||||
obclient> CREATE PUBLIC SYNONYM syn_pub FOR test;
|
||||
Query OK, 0 rows affected (0.03 sec)
|
||||
|
||||
obclient> SELECT * FROM syn_pub;
|
||||
+------+
|
||||
| c1 |
|
||||
+------+
|
||||
| 1 |
|
||||
+------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
删除同义词
|
||||
--------------------------
|
||||
|
||||
您可以使用 `DROP SYNONYM` 语句来删除不需要使用的同义词。
|
||||
|
||||
删除同义词时:
|
||||
|
||||
* 如果删除的是私有同义词,则需要保证待删除的同义词在对应的数据库下,且当前用户需要具备以下权限:
|
||||
|
||||
* MySQL 模式的租户:`CREATE SYNONYM` 权限
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 如果删除的是公共同义词,则当前用户需要具备以下权限:
|
||||
|
||||
* MySQL 模式的租户:`CREATE SYNONYM` 权限
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
同时,在删除时,必须指定 `PUBLIC` 关键字,并且不能指定数据库。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
删除同义词的语法格式如下:
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
```sql
|
||||
DROP [PUBLIC] SYNONYM [ DATABASE. ]synonym;
|
||||
```
|
||||
|
||||
|
||||
|
||||
MySQL 模式下 `DROP SYNONYM` 语句的更多信息,请参见《SQL 参考》文档中的 [DROP SYNONYM](../../../10.sql-reference/5.sql-statement/33.drop-synonym.md) 章节。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
* 删除一个私有同义词。
|
||||
|
||||
```sql
|
||||
obclient> DROP SYNONYM test.s1;
|
||||
Query OK, 0 rows affected (0.03 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 删除一个公共同义词。
|
||||
|
||||
```sql
|
||||
obclient> DROP PUBLIC SYNONYM syn_pub;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,15 @@
|
||||
关于分区
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库可以把普通的表的数据按照一定的规则划分到不同的区块内,同一区块的数据物理上存储在一起。这种划分区块的表叫做分区表,其中的每一个区块称作分区。
|
||||
|
||||
如下图所示,一张表被划分成了 5 个分区,分布在 2 台机器上:
|
||||
|
||||

|
||||
|
||||
上图分区表的每个分区还能按照一定的规则再拆分成多个分区,这种分区表叫做二级分区表。
|
||||
|
||||
数据表中每一行中用于计算这一行属于哪一个分区的列的集合叫做分区键,分区键必须是主键或唯一键的子集。由分区键构成的用于计算这一行属于哪一个分区的表达式叫做分区表达式。
|
||||
|
||||
@ -0,0 +1,155 @@
|
||||
分区策略
|
||||
=========================
|
||||
|
||||
本节主要介绍 OceanBase 数据库的分区策略。
|
||||
|
||||
OceanBase 数据库目前支持的分区策略如下:
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
* Range 分区
|
||||
|
||||
|
||||
|
||||
* Range Columns 分区
|
||||
|
||||
|
||||
|
||||
* List 分区
|
||||
|
||||
|
||||
|
||||
* List Columns 分区
|
||||
|
||||
|
||||
|
||||
* Hash 分区
|
||||
|
||||
|
||||
|
||||
* Key 分区
|
||||
|
||||
|
||||
|
||||
* 组合分区
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Range 分区
|
||||
-----------------------------
|
||||
|
||||
Range 分区根据分区表定义时为每个分区建立的分区键值范围,将数据映射到相应的分区中。它是常见的分区类型,经常跟日期类型一起使用。例如,可以将业务日志表按日/周/月分区。
|
||||
|
||||
Range Columns 分区
|
||||
-------------------------------------
|
||||
|
||||
Range Columns 分区与 Range 分区的作用基本类似,不同之处在于:
|
||||
|
||||
* Range Columns 分区的分区键的结果不要求是整型,可以是任意类型。
|
||||
|
||||
|
||||
|
||||
* Range Columns 分区的分区键不能使用表达式。
|
||||
|
||||
|
||||
|
||||
* Range Columns 分区的分区键可以写多个列(即列向量)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
List 分区
|
||||
----------------------------
|
||||
|
||||
List 分区使得您可以显式的控制记录行如何映射到分区,具体方法是为每个分区的分区键指定一组离散值列表,这点跟 Range 分区和 Hash 分区都不同。List 分区的优点是可以方便的对无序或无关的数据集进行分区。
|
||||
|
||||
List Columns 分区
|
||||
------------------------------------
|
||||
|
||||
List Columns 分区与 List 分区的作用基本相同,不同之处在于:
|
||||
|
||||
* List Columns 分区的分区键不要求是整型,可以是任意类型。
|
||||
|
||||
|
||||
|
||||
* List Columns 分区的分区键可以是多列(即列向量)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Hash 分区
|
||||
----------------------------
|
||||
|
||||
Hash 分区适合于对不能用 Range 分区、List 分区方法的场景,它的实现方法简单,通过对分区键上的 Hash 函数值来散列记录到不同分区中。如果您的数据符合下列特点,使用 Hash 分区是个很好的选择:
|
||||
|
||||
* 不能指定数据的分区键的列表特征。
|
||||
|
||||
|
||||
|
||||
* 不同范围内的数据大小相差非常大,并且很难手动调整均衡。
|
||||
|
||||
|
||||
|
||||
* 使用 Range 分区后数据聚集严重。
|
||||
|
||||
|
||||
|
||||
* 并行 DML、分区剪枝和分区连接等性能非常重要。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Key 分区
|
||||
---------------------------
|
||||
|
||||
Key 分区与 Hash 分区类似,也是通过对分区个数取模的方式来确定数据属于哪个分区,不同的是系统会对 Key 分区键做一个内部默认的 Hash 函数后再取模。
|
||||
|
||||
Key 分区有如下特点:
|
||||
|
||||
* Key 分区的分区键不要求为整型,可以为任意类型
|
||||
|
||||
|
||||
|
||||
* Key 分区的分区键不能使用表达式
|
||||
|
||||
|
||||
|
||||
* Key 分区的分区键支持向量
|
||||
|
||||
|
||||
|
||||
* Key 分区的分区键中不指定任何列时,表示 Key 分区的分区键是主键。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t1 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 INT)
|
||||
PARTITION BY KEY()
|
||||
PARTITIONS 5;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
组合分区
|
||||
-------------------------
|
||||
|
||||
组合分区通常是先使用一种分区策略,然后在子分区再使用另外一种分区策略,适合于业务表的数据量非常大时。使用组合分区能发挥多种分区策略的优点。
|
||||
|
||||
在指定二级分区分区策略细节时,可以使用 `SUBPARTITION TEMPLATE` 子句。
|
||||
@ -0,0 +1,260 @@
|
||||
一级分区表
|
||||
==========================
|
||||
|
||||
|
||||
|
||||
创建 Range 分区表
|
||||
---------------------------------
|
||||
|
||||
Range 分区简单的语法格式如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 column_type
|
||||
[, column_nameN column_type]
|
||||
) PARTITION BY RANGE ( expr(column_name1) | column_name1)
|
||||
(
|
||||
PARTITION p0 VALUES LESS THAN ( expr )
|
||||
[, PARTITION pN VALUES LESS THAN (expr ) ]
|
||||
[, PARTITION pX VALUES LESS THAN (MAXVALUE) ]
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
在创建 Range 分区时,需要遵循以下规则:
|
||||
|
||||
* `PARTITION BY RANGE ( expr )` 里的 `expr` 表达式的结果必须为整型。
|
||||
|
||||
|
||||
|
||||
* 每个分区都有一个 `VALUES LESS THAN` 子句,它为分区指定一个非包含的上限值。分区键的任何值等于或大于这个值时将被映射到下一个分区中。
|
||||
|
||||
|
||||
|
||||
* 除第一个分区外,所有分区都隐含一个下限值,即上一个分区的上限值。
|
||||
|
||||
|
||||
|
||||
* 仅允许最后一个分区的上限定义为 `MAXVALUE`,这个值没有具体的数值,并且比其他所有分区的上限都要大,也包含空值。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
* MySQL 模式下,创建一个 Range 分区表。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t_log_part_by_range (
|
||||
log_id bigint NOT NULL
|
||||
, log_value varchar(50)
|
||||
, log_date timestamp NOT NULL
|
||||
) PARTITION BY RANGE(UNIX_TIMESTAMP(log_date))
|
||||
(
|
||||
PARTITION M202001 VALUES LESS THAN(UNIX_TIMESTAMP('2020/02/01'))
|
||||
, PARTITION M202002 VALUES LESS THAN(UNIX_TIMESTAMP('2020/03/01'))
|
||||
, PARTITION M202003 VALUES LESS THAN(UNIX_TIMESTAMP('2020/04/01'))
|
||||
, PARTITION M202004 VALUES LESS THAN(UNIX_TIMESTAMP('2020/05/01'))
|
||||
, PARTITION M202005 VALUES LESS THAN(UNIX_TIMESTAMP('2020/06/01'))
|
||||
, PARTITION M202006 VALUES LESS THAN(UNIX_TIMESTAMP('2020/07/01'))
|
||||
, PARTITION M202007 VALUES LESS THAN(UNIX_TIMESTAMP('2020/08/01'))
|
||||
, PARTITION M202008 VALUES LESS THAN(UNIX_TIMESTAMP('2020/09/01'))
|
||||
, PARTITION M202009 VALUES LESS THAN(UNIX_TIMESTAMP('2020/10/01'))
|
||||
, PARTITION M202010 VALUES LESS THAN(UNIX_TIMESTAMP('2020/11/01'))
|
||||
, PARTITION M202011 VALUES LESS THAN(UNIX_TIMESTAMP('2020/12/01'))
|
||||
, PARTITION M202012 VALUES LESS THAN(UNIX_TIMESTAMP('2021/01/01'))
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Range 分区可以新增和删除分区。如果最后一个 Range 分区指定了 `MAXVALUE` ,则不能新增分区。
|
||||
|
||||
MySQL 模式下,Range 分区要求表分区键表达式的结果必须为整型,如果要按时间类型列做 Range 分区,则必须使用 Timestamp 类型,并且使用函数 UNIX_TIMESTAMP 将时间类型转换为数值。这个需求也可以使用 Range Columns 分区实现,并且不需要表拆分键表达式的结果为整型。
|
||||
|
||||
创建 Range Columns 分区表
|
||||
-----------------------------------------
|
||||
|
||||
在 OceanBase 数据库中,仅 MySQL 模式支持 Range Columns 分区。
|
||||
|
||||
Range Columns 分区的简单语法格式如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 column_type
|
||||
[, column_nameN column_type]
|
||||
) PARTITION BY RANGE ( column_name1 [, column_name2] )
|
||||
(
|
||||
PARTITION p0 VALUES LESS THAN ( expr )
|
||||
[, PARTITION pN VALUES LESS THAN (expr ) ]
|
||||
[, PARTITION pX VALUES LESS THAN (maxvalue) ]
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例:创建一个 Range Columns 分区。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t_log_part_by_range_columns (
|
||||
log_id bigint NOT NULL
|
||||
, log_value varchar(50)
|
||||
, log_date date NOT NULL
|
||||
) PARTITION BY RANGE COLUMNS(log_date)
|
||||
(
|
||||
PARTITION M202001 VALUES LESS THAN('2020/02/01')
|
||||
, PARTITION M202002 VALUES LESS THAN('2020/03/01')
|
||||
, PARTITION M202003 VALUES LESS THAN('2020/04/01')
|
||||
, PARTITION M202004 VALUES LESS THAN('2020/05/01')
|
||||
, PARTITION M202005 VALUES LESS THAN('2020/06/01')
|
||||
, PARTITION M202006 VALUES LESS THAN('2020/07/01')
|
||||
, PARTITION M202007 VALUES LESS THAN('2020/08/01')
|
||||
, PARTITION M202008 VALUES LESS THAN('2020/09/01')
|
||||
, PARTITION M202009 VALUES LESS THAN('2020/10/01')
|
||||
, PARTITION M202010 VALUES LESS THAN('2020/11/01')
|
||||
, PARTITION M202011 VALUES LESS THAN('2020/12/01')
|
||||
, PARTITION M202012 VALUES LESS THAN('2021/01/01')
|
||||
, PARTITION MMAX VALUES LESS THAN MAXVALUE
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
创建 List 分区表
|
||||
--------------------------------
|
||||
|
||||
List 分区的简单语法格式如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 column_type
|
||||
[, column_nameN column_type]
|
||||
) PARTITION BY LIST ( expr(column_name1) | column_name1)
|
||||
(
|
||||
PARTITION p0 VALUES IN ( v01 [, v0N] )
|
||||
[, PARTITION pN VALUES IN ( vN1 [, vNN] ) ]
|
||||
[, PARTITION pX VALUES IN (default) ]
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
当使用 List 分区时,需要遵循以下规则:
|
||||
|
||||
* 分区表达式的结果必须是整型。
|
||||
|
||||
|
||||
|
||||
* 分区表达式只能引用一列,不能有多列(即列向量)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
* MySQL 模式下创建一个 List 分区表。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t_part_by_list (
|
||||
c1 BIGINT PRIMARY Key
|
||||
, c2 VARCHAR(50)
|
||||
) PARTITION BY list(c1)
|
||||
(
|
||||
PARTITION p0 VALUES IN (1, 2, 3)
|
||||
, PARTITION p1 VALUES IN (5, 6)
|
||||
, PARTITION p2 VALUES IN (DEFAULT)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
创建 List Columns 分区表
|
||||
----------------------------------------
|
||||
|
||||
在 OceanBase 数据库中,仅 MySQL 模式支持 List Columns 分区。
|
||||
|
||||
List Columns 分区简单的语法格式如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 column_type
|
||||
[, column_nameN column_type]
|
||||
) PARTITION BY LIST COLUMNS ( column_name1 [, column_nameN ] )
|
||||
(
|
||||
PARTITION p0 VALUES IN ( v01 [, v0N] )
|
||||
[, PARTITION pN VALUES IN ( vN1 [, vNN] ) ]
|
||||
[, PARTITION pX VALUES IN (default) ]
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例:创建一个 LIST Columns 分区表。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t2 (
|
||||
id varchar(64),
|
||||
type varchar(16),
|
||||
info varchar(512),
|
||||
gmt_create datetime(6),
|
||||
gmt_modified datetime(6),
|
||||
partition_id varchar(2) GENERATED ALWAYS AS (substr(`id`,19,20)) VIRTUAL,
|
||||
PRIMARY KEY (id)
|
||||
) partition by list columns(partition_id)
|
||||
(partition p0 values in ('00','01'),
|
||||
partition p1 values in ('02','03'),
|
||||
partition p2 values in (default));
|
||||
```
|
||||
|
||||
|
||||
|
||||
创建 Hash 分区表
|
||||
--------------------------------
|
||||
|
||||
示例:在 MySQL 模式下,创建一个 Hash 分区表。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE ware(
|
||||
w_id int
|
||||
, w_ytd number(12,2)
|
||||
, w_tax number(4,4)
|
||||
, w_name varchar(10)
|
||||
, w_street_1 varchar(20)
|
||||
, w_street_2 varchar(20)
|
||||
, w_city varchar(20)
|
||||
, w_state char(2)
|
||||
, w_zip char(9)
|
||||
, primary key(w_id)
|
||||
) PARTITION by hash(w_id) partitions 60;
|
||||
```
|
||||
|
||||
|
||||
|
||||
创建 Key 分区表
|
||||
-------------------------------
|
||||
|
||||
在 OceanBase 数据库中,仅 MySQL 模式支持 Key 分区。
|
||||
|
||||
示例:创建表 `t_log_part_by_Key`,将 `id`、`gmt_create` 键作为分区键,按 Key 分区划分为 3 个分区。
|
||||
|
||||
```sql
|
||||
obclient>CREATE TABLE t_log_part_by_key(
|
||||
id INT,
|
||||
gmt_create DATETIME,
|
||||
info VARCHAR(20))
|
||||
PARTITION BY KEY(id, gmt_create)
|
||||
PARTITIONS 3;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,243 @@
|
||||
二级分区表
|
||||
==========================
|
||||
|
||||
二级分区是按照两个维度来把数据拆分成分区的操作。最常用的地方是类似用户账单的场景。
|
||||
|
||||
OceanBase 数据库目前支持 Hash、Range 和 List 三种分区⽅式,MySQL 模式下还支持 Key、Range Columns 和 List Columns 三种分区方式,并且支持任意两种分区方式的组合。
|
||||
|
||||
当前 MySQL 模式和 支持的二级分区如下:
|
||||
|
||||
* Hash + Hash 分区
|
||||
|
||||
|
||||
|
||||
* Hash + Range 分区
|
||||
|
||||
|
||||
|
||||
* Hash+ List 分区
|
||||
|
||||
|
||||
|
||||
* Range + Hash 分区
|
||||
|
||||
|
||||
|
||||
* Range +Range 分区
|
||||
|
||||
|
||||
|
||||
* Range +List 分区
|
||||
|
||||
|
||||
|
||||
* List+ Hash 分区
|
||||
|
||||
|
||||
|
||||
* List+Range 分区
|
||||
|
||||
|
||||
|
||||
* List+List 分区
|
||||
|
||||
|
||||
|
||||
* Hash +Key 分区
|
||||
|
||||
|
||||
|
||||
* Hash +Range Columns 分区
|
||||
|
||||
|
||||
|
||||
* Hash +List Columns 分区
|
||||
|
||||
|
||||
|
||||
* Range +Key 分区
|
||||
|
||||
|
||||
|
||||
* Range +Range Columns 分区
|
||||
|
||||
|
||||
|
||||
* Range +List Columns 分区
|
||||
|
||||
|
||||
|
||||
* List+Key 分区
|
||||
|
||||
|
||||
|
||||
* List+Range Columns 分区
|
||||
|
||||
|
||||
|
||||
* List+List Columns 分区
|
||||
|
||||
|
||||
|
||||
* Key +Hash 分区
|
||||
|
||||
|
||||
|
||||
* Key +Range 分区
|
||||
|
||||
|
||||
|
||||
* Key+List 分区
|
||||
|
||||
|
||||
|
||||
* Key +Range Columns 分区
|
||||
|
||||
|
||||
|
||||
* Key +List Columns 分区
|
||||
|
||||
|
||||
|
||||
* Range Columns+Hash分区
|
||||
|
||||
|
||||
|
||||
* Range Columns+Range 分区
|
||||
|
||||
|
||||
|
||||
* Range Columns+List 分区
|
||||
|
||||
|
||||
|
||||
* Range Columns+Key 分区
|
||||
|
||||
|
||||
|
||||
* Range Columns+List Columns 分区
|
||||
|
||||
|
||||
|
||||
* List Columns +Hash 分区
|
||||
|
||||
|
||||
|
||||
* List Columns +Range 分区
|
||||
|
||||
|
||||
|
||||
* List Columns +List 分区
|
||||
|
||||
|
||||
|
||||
* List Columns +Key 分区
|
||||
|
||||
|
||||
|
||||
* List Columns +Range Columns 分区
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当前,⼆级分区表可分为模板化二级分区表和非模板化二级分区表。
|
||||
|
||||
创建模板化二级分区表
|
||||
-------------------------------
|
||||
|
||||
模板化⼆级分区表的每个⼀级分区下的⼆级分区都按照模板中的⼆级分区定义,即每个⼀级分区下的⼆级分区定义均相同。
|
||||
|
||||
语法如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE ....
|
||||
partition BY [hash|range|list] (column_list)
|
||||
subpartition BY [hash|range|list] (column_list)
|
||||
subpartition template
|
||||
(
|
||||
subpartition subpart_name subpartition_define
|
||||
, ...
|
||||
)
|
||||
(
|
||||
partition part_name partition_define
|
||||
, ...
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于模板化⼆级分区表来说,⼆级分区的命名规则为 ($part_name)s($subpart_name) 。
|
||||
|
||||
例如,对于下⾯的 `t_range_range` 表,`p0` 下的 3 个⼆级分区的分区名分别为 `p0srp1`、`p0srp2`、`p0srp3`。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t_range_range (c1 int, c2 int, c3 int) partition BY range(c1)
|
||||
subpartition BY range (c2)
|
||||
subpartition template
|
||||
(
|
||||
subpartition rp1 VALUES less than (100),
|
||||
subpartition rp2 VALUES less than (200),
|
||||
subpartition rp3 VALUES less than (300)
|
||||
)
|
||||
(
|
||||
partition p0 VALUES less than (100),
|
||||
partition p1 VALUES less than (200),
|
||||
partition p2 VALUES less than (300)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
创建非模板化二级分区表
|
||||
--------------------------------
|
||||
|
||||
⾮模板化⼆级分区表的每个⼀级分区下的⼆级分区均可以⾃由定义,即每个⼀级分区下的⼆级分区的定义可以相同也可以不同。
|
||||
|
||||
```sql
|
||||
CREATE TABLE ....
|
||||
partition BY [hash|range|list] (column_list)
|
||||
subpartition BY [hash|range|list] (column_list)
|
||||
(
|
||||
partition part_name partition_define
|
||||
(
|
||||
subpartition subpart_name subpartition_define
|
||||
, ...
|
||||
)
|
||||
, ...
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于⾮模板化⼆级分区表来说,⼆级分区的分区名即为⾃定义的分区名。
|
||||
|
||||
例如,对于下⾯的 `t_range_range1` 表,p0 下的 3个⼆级分区的分区名分别是 `p0_r1`、`p0_r2`、`p0_r3`。
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t_range_range1 (c1 int, c2 int, c3 int) partition BY range(c1)
|
||||
subpartition BY range (c2)
|
||||
(
|
||||
partition p0 VALUES less than (100)
|
||||
(
|
||||
subpartition p0_r1 VALUES less than (100),
|
||||
subpartition p0_r2 VALUES less than (200),
|
||||
subpartition p0_r3 VALUES less than (300)
|
||||
),
|
||||
partition p1 VALUES less than (200)
|
||||
(
|
||||
subpartition p1_r1 VALUES less than (100),
|
||||
subpartition p1_r2 VALUES less than (200),
|
||||
subpartition p1_r3 VALUES less than (300)
|
||||
),
|
||||
partition p2 VALUES less than (300)
|
||||
(
|
||||
subpartition p2_r1 VALUES less than (100),
|
||||
subpartition p2_r2 VALUES less than (200),
|
||||
subpartition p2_r3 VALUES less than (300)
|
||||
)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,179 @@
|
||||
分区裁剪
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
当用户访问分区表时,往往只需要访问其中部分的分区,所以通过优化器避免访问无关分区的优化过程我们称之为分区裁剪((Partition Pruning)。分区裁剪是分区表提供的重要优化手段,通过分区的裁剪,SQL 的执行效率可以得到大幅度的提升。您可以利用分区裁剪的特性,在访问中加入定位分区的条件,避免访问无关数据,优化查询性能。
|
||||
|
||||
分区裁剪本身是一个比较复杂的过程,优化器需要根据用户表的分区信息和 SQL 中给定的条件,抽取出相关的分区信息。由于 SQL 中的条件往往比较复杂,整个抽取逻辑的复杂性也随之增加,这一过程由 OceanBase 数据库中的 Query Range 子模块完成。
|
||||
|
||||
以下示例中当用户使用如下 SQL 访问分区表时,由于 c1 为 1 的数据全部处于第 1 号分区(p1),实际上我们只需要访问该分区即可(避免访问第 0、2、3、4 号分区):
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1
|
||||
(
|
||||
c1 INT,
|
||||
c2 INT
|
||||
)
|
||||
PARTITION BY HASH(c1) partitions 5;
|
||||
|
||||
obclient> SELECT * FROM t1 WHERE c1 = 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过 `EXPLAIN` 查看执行计划可以看到分区裁剪的结果:
|
||||
|
||||
```sql
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 = 1 \G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1 |1303|
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter([t1.c1 = 1]),
|
||||
access([t1.c1], [t1.c2]), partitions(p1)
|
||||
```
|
||||
|
||||
|
||||
|
||||
一级分区裁剪的基本原理
|
||||
--------------------
|
||||
|
||||
**Hash/List 分区**
|
||||
|
||||
分区裁剪就是根据 `where` 子句里面的条件并且计算得到分区列的值,然后通过结果判断需要访问哪些分区。如果分区函数为表达式,且该表达式作为一个整体出现在等值条件里,也可以做分区裁剪。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1
|
||||
(
|
||||
c1 INT,
|
||||
c2 INT
|
||||
)
|
||||
PARTITION BY HASH(c1 + c2) partitions 5;
|
||||
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 + c2 = 1 \G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |5 |1303|
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter([t1.c1 + t1.c2 = 1]),
|
||||
access([t1.c1], [t1.c2]), partitions(p1)
|
||||
```
|
||||
|
||||
|
||||
|
||||
**Range 分区**
|
||||
|
||||
通过 `where` 子句的分区键的范围跟表定义的分区范围的交集来确定需要访问的分区。对于 Range 分区,因为考虑到函数的单调性,如果分区表达式是一个函数并且查询条件是一个范围,则不支持分区裁剪。
|
||||
|
||||
下述示例中,分区条件为表达式,而查询条件为非等值条件(c1 \< 150 and c1 \> 100),则无法进行分区裁剪:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1
|
||||
(
|
||||
c1 INT,
|
||||
c2 INT
|
||||
)
|
||||
PARTITION BY RANGE(c1 + 1)
|
||||
(
|
||||
PARTITION p0 VALUES less than (100),
|
||||
PARTITION p1 VALUES less than (200)
|
||||
);
|
||||
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 < 150 and c1 > 110 \G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
--------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |19 |1410|
|
||||
|1 | EXCHANGE OUT DISTR| |19 |1303|
|
||||
|2 | TABLE SCAN |t1 |19 |1303|
|
||||
============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil)
|
||||
1 - output([t1.c1], [t1.c2]), filter(nil)
|
||||
2 - output([t1.c1], [t1.c2]), filter([t1.c1 < 150], [t1.c1 > 110]),
|
||||
access([t1.c1], [t1.c2]), partitions(p[0-1])
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果查询条件是等值条件,则可以进行分区裁剪。示例如下:
|
||||
|
||||
```sql
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 = 150 \G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ===================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
-----------------------------------
|
||||
|0 |TABLE SCAN|t1 |1 |1303|
|
||||
===================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter([t1.c1 = 150]),
|
||||
access([t1.c1], [t1.c2]), partitions(p1)
|
||||
```
|
||||
|
||||
|
||||
|
||||
二级分区裁剪的基本原理
|
||||
--------------------
|
||||
|
||||
对于二级分区,先按照一级分区键确定一级需要访问的分区,然后在通过二级分区键确定二级分区需要访问的分区。然后做一个乘积确定二级分区访问的所有物理分区。
|
||||
|
||||
以下示例中,经过计算得到一级分区裁剪结果是 p1、p2,而二级分区裁剪的结果是 sp1,所以访问的物理分区为 p1sp1 和 p2sp1:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1
|
||||
(
|
||||
c1 INT ,
|
||||
c2 INT
|
||||
)
|
||||
PARTITION BY hash(c1)
|
||||
SUBPARTITION BY RANGE(c2)
|
||||
SUBPARTITION template
|
||||
(
|
||||
SUBPARTITION sp0 VALUES less than(100),
|
||||
SUBPARTITION sp1 VALUES less than(200)
|
||||
) partitions 5
|
||||
SELECT * FROM t1
|
||||
WHERE
|
||||
(c1 = 1 OR c1 = 2) AND
|
||||
(c2 > 101 AND c2 < 150)
|
||||
|
||||
obclient> EXPLAIN SELECT * FROM t1 WHERE (c1 = 1 or c1 = 2) and (c2 > 101 and c2 < 150) \G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ============================================
|
||||
|ID|OPERATOR |NAME|EST. ROWS|COST|
|
||||
--------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |1 |1403|
|
||||
|1 |EXCHANGE OUT DISTR| |1 |1303|
|
||||
|2 | TABLE SCAN |t1 |1 |1303|
|
||||
============================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.c1], [t1.c2]), filter(nil)
|
||||
1 - output([t1.c1], [t1.c2]), filter(nil)
|
||||
2 - output([t1.c1], [t1.c2]), filter([t1.c1 = 1 OR t1.c1 = 2], [t1.c2 > 101], [t1.c2 < 150]),
|
||||
access([t1.c1], [t1.c2]), partitions(p1sp1, p2sp1)
|
||||
```
|
||||
|
||||
|
||||
|
||||
某些场景下,分区裁剪可能会存在一定程度的放大,但优化器可以确保裁剪的结果是所需访问数据的超集,不会存在丢失数据的情况。
|
||||
@ -0,0 +1,70 @@
|
||||
分区命名与查询
|
||||
============================
|
||||
|
||||
|
||||
|
||||
指定分区的查询
|
||||
----------------
|
||||
|
||||
除了根据 SQL 的查询条件进行分区裁剪以外,OceanBase 数据库也支持用户通过 SQL 语法指定需要访问的分区。下述示例语句中 `partition(p0)` 指定了只访问 p0 分区:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM t1 partition (p0);
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果 SQL 中指定了分区,系统会将查询的范围限定在所指定的分区集合内,同时根据 SQL 的查询条件进行分区裁剪。最终访问的分区为指定分区和分区裁剪二者的交集。
|
||||
|
||||
分区名字规则
|
||||
---------------
|
||||
|
||||
对于 List 和 Range 分区,因为在创建表的过程中就指定了分区的名字,所以名字就是当时指定的名字。对于 Hash/Key 分区,创建时如果没有指定分区的名字,分区的命名由系统根据命名规则完成。具体表现为,如果 Hash/Key 出现在一级分区里面,那么每个分区分别命名为 p0、p1、...、pn。如果出现在二级分区里面,那么就是 sp0、sp1、 ...、spn。
|
||||
|
||||
二级分区的名字由 **一级分区+二级分区** 的方式构成。例如 p0sp0,其中 p0 是一级分区的名字,sp0 是二级分区的名字。
|
||||
|
||||
获取二级分区的各级分区 ID
|
||||
-----------------------
|
||||
|
||||
对于二级分区,可以在日志里面看到的分区 ID 数字很大。
|
||||
|
||||
下述示例展示了 t1 的实际分区 ID:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1
|
||||
(
|
||||
c1 INT,
|
||||
c2 INT
|
||||
)
|
||||
PARTITION BY hash(c1)
|
||||
SUBPARTITION BY RANGE(c2)
|
||||
SUBPARTITION template
|
||||
(
|
||||
SUBPARTITION sp0 VALUES less than(100),
|
||||
SUBPARTITION sp1 VALUES less than(200)
|
||||
) partitions 5
|
||||
|
||||
obclient> SELECT partition_id FROM __all_meta_table JOIN __all_table using(table_id)
|
||||
WHERE table_name = 't1';
|
||||
+---------------------+
|
||||
| partition_id |
|
||||
+---------------------+
|
||||
| 1152921504875282432 |
|
||||
| 1152921504875282433 |
|
||||
| 1152921509170249728 |
|
||||
| 1152921509170249729 |
|
||||
| 1152921513465217024 |
|
||||
| 1152921513465217025 |
|
||||
| 1152921517760184320 |
|
||||
| 1152921517760184321 |
|
||||
| 1152921522055151616 |
|
||||
| 1152921522055151617 |
|
||||
+---------------------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
Partition-Wise 联接
|
||||
--------------------------
|
||||
|
||||
Partition-Wise 联接(Partition-Wise Join)是指当需要联接的表是按照联接条件进行分区的时候,联接只需对联接表对应分区进行联接操作,能极大提高联接的性能。您可以在我们的 《SQL 调优》手册中查看更多关于 Partition-Wise 联接的信息。
|
||||
@ -0,0 +1,74 @@
|
||||
局部索引
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
局部索引又名分区索引,创建索引的分区关键字是 LOCAL。局部索引的分区键等同于表的分区键,局部索引的分区数等同于表的分区数,所以局部索引的分区机制和表的分区机制一样。
|
||||
|
||||
下述示例语句为给分区表 t1 创建一个局部索引 idx:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1(a int primary key, b int) PARTITION BY hash(a) partitions 5;
|
||||
|
||||
obclient> CREATE INDEX idx ON t1(b) local;
|
||||
```
|
||||
|
||||
|
||||
|
||||
局部索引是针对单个分区上的数据创建的索引,因此局部索引的索引键值跟表中的数据是一一对应的关系,即局部索引上的一个分区一定对应到一个表分区,它们具有相同的分区规则,因此对于局部唯一索引而言,它只能保证分区内部的唯一性,而无法保证表数据的全局唯一性。如果要使用局部唯一索引去对数据唯一性做约束,那么局部唯一索引中必须包含表分区键。
|
||||
|
||||
下述示例语句为给分区表 t2 创建局部唯一索引 uk:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t2(a int primary key, b int) PARTITION BY hash(a) partitions 5;
|
||||
obclient> CREATE UNIQUE INDEX uk ON t2(b) LOCAL;
|
||||
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function
|
||||
obclient> CREATE UNIQUE INDEX uk2 on t2(b, a) local;
|
||||
Query OK, 0 rows affected (5.32 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 OceanBase 中,局部索引同样支持分区裁剪。使用分区裁剪的前提条件是查询条件中能够指定分区键,可以减少在查询过程中读取的分区个数,从而能够提高查询检索的效率。下述示例语句为查询条件中指定分区键:
|
||||
|
||||
```sql
|
||||
obclient> EXPLAIN SELECT /*+index(t1 idx)*/ b FROM t1 WHERE b=1 AND a=1\G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: =====================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-------------------------------------
|
||||
|0 |TABLE GET|t1(idx)|1 |52 |
|
||||
=====================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.b]), filter(nil),
|
||||
access([t1.b]), partitions(p1)
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果在查询中,没有指定分区键,那么局部索引将无法进行分区裁剪,这时会扫描所有分区,增加额外的扫描代价。下述示例语句为查询条件中不指定分区键:
|
||||
|
||||
```sql
|
||||
obclient> EXPLAIN SELECT /*+index(t1 idx)*/ b FROM t1 WHERE b=1\G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ====================================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
----------------------------------------------------
|
||||
|0 |EXCHANGE IN DISTR | |4950 |3551|
|
||||
|1 | EXCHANGE OUT DISTR |:EX10000|4950 |3083|
|
||||
|2 | PX PARTITION ITERATOR| |4950 |3083|
|
||||
|3 | TABLE SCAN |t1(idx) |4950 |3083|
|
||||
====================================================
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([t1.b]), filter(nil)
|
||||
1 - output([t1.b]), filter(nil), dop=1
|
||||
2 - output([t1.b]), filter(nil)
|
||||
3 - output([t1.b]), filter(nil),
|
||||
access([t1.b]), partitions(p[0-4])
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
全局索引
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
全局索引的创建规则是在索引属性中指定 GLOBAL 关键字。与局部索引相比,全局索引最大的特点是全局索引的分区规则跟表分区是相互独立的,全局索引允许指定自己的分区规则和分区个数,不一定需要跟表分区规则保持一致。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE t1(a int PRIMARY KEY, b int, c int) PARTITION BY hash(a) partitions 5;
|
||||
|
||||
obclient> CREATE INDEX gkey ON t1(b) GLOBAL PARTITION BY range(b) (
|
||||
partition p0 VALUES less than (1),
|
||||
partition p1 VALUES less than (2),
|
||||
partition p2 VALUES less than (3)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
全局索引的分区键一定是索引键本身,因此在使用全局索引的过程中就会指定索引分区键的查询条件,我们可以针对索引的分区规则进行分区裁剪,在查询到索引键值后可以利用索引表中存储的主键信息计算出主表的分区位置,进而对主表也能进行快速的分区定位,避免扫描主表的所有分区,因此对于无法指定主表分区键的查询而言,全局索引在一定条件下能够加速查询的检索效率。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> EXPLAIN SELECT /*+index(t1 gkey)*/ * FROM t1 WHERE b=1\G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: ==========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST |
|
||||
------------------------------------------
|
||||
|0 |TABLE LOOKUP|T1 |4950 |38645|
|
||||
|1 | TABLE SCAN |T1(GKEY)|4950 |1115 |
|
||||
==========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([T1.A], [T1.B], [T1.C]), filter(nil),
|
||||
partitions(p[0-4])
|
||||
1 - output([T1.A]), filter(nil),
|
||||
access([T1.A]), partitions(p1)
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于上述查询,首先通过 `where` 条件中的 `b=1` 条件裁剪出全局索引的分区 p1,然后对全局索引进行 `table scan` 操作以得到对应的主键。利用 `table lookup` 算子对主表进行精确的分区扫描以避免扫描主表的所有分区。
|
||||
|
||||
在 OceanBase 数据库中,如果索引属性关键字没有指定,那么默认的索引属性是 GLOBAL 属性,即创建的索引是全局索引,并且索引表只有一个分区。
|
||||
|
||||
如果主表没有指定分区键或者指定的分区数为 1,那么主表也只有一个分区,这个时候,全局索引的数据和主表数据的物理位置是相互绑定在一起的,无论是迁移还是副本 Leader 发生切换,它们都是作为一个整体进行变换,不会存在中间状态。如果全局索引的分区规则和主表的分区规则相同并且分区数相同,这时推荐创建一个局部索引。 一方面是因为全局索引的维护代价更大;另一方面是因为全局索引无法保证和主表分区的物理位置相同,除非将其和主表指定在一个表组中。
|
||||
@ -0,0 +1,49 @@
|
||||
使用索引
|
||||
=========================
|
||||
|
||||
|
||||
|
||||
局部索引与全局索引对比
|
||||
--------------------
|
||||
|
||||
与局部索引相比,由于全局索引有独立的分区规则,因此索引表中一个分区的索引值可能对应着主表的多个分区内的数据。由于索引的分区规则和主表的分区规则不一定相同,因此在分布式环境中,索引数据和主表数据存储的位置也无法保证始终在一起,这不可避免的会引入读写的 RPC 代价和分布式事务的代价。例如,当主表的分区和全局索引的分区不在同一个物理位置上,`TABLE LOOKUP`算子中就会包含一次 RPC 操作到远端机器上去获取主表数据。因此全局索引相比局部索引有更高的维护代价,您应当充分评估主表的分区规则,合理的选择分区键,尽量使更多的查询条件能够覆盖主表的分区键,从而尽可能的避免使用全局索引。
|
||||
|
||||
使用限制
|
||||
-------------
|
||||
|
||||
在分布式环境中,全局索引不可避免的会涉及到分布式事务和跨机的查询,因此全局索引依赖 GTS 维护全局的一致性快照,所以全局索引只能在 GTS 开启的时候使用。如果没有开启 GTS,则创建全局索引失败。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> SET GLOBAL ob_timestamp_service=LTS;
|
||||
Query OK, 0 rows affected (0.06 sec)
|
||||
|
||||
obclient> CREATE TABLE t1(a int, b int, PRIMARY KEY(a));
|
||||
Query OK, 0 rows affected (0.17 sec)
|
||||
|
||||
obclient> CREATE INDEX gkey ON t1(b) PARTITION BY range(b) (PARTITION p0 VALUES LESS THAN (1), PARTITION p1 VALUES LESS THAN (2), PARTITION p2 VALUES LESS THAN(3));
|
||||
ERROR 1235 (0A000): create global index when GTS is off not supported
|
||||
```
|
||||
|
||||
|
||||
|
||||
由于 OceanBase 数据库的表是索引组织表(IOT),对于分区表而言,为了保证指定主键的查询能很快定位到表所在的分区,所以分区键必须是主键的子集。如果需要在分区表上创建局部分区唯一索引(Local Partitioned Unique Index),则该索引键需要包含主表的分区键,而对于全局分区唯一索引(Global Partitioned Unique Index)并没有这个限制。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE test(pk int,c2 int ,c3 int, PRIMARY KEY(pk)) PARTITION BY hash(pk) partitions 5;
|
||||
Query OK, 0 rows affected (0.20 sec)
|
||||
obclient> CREATE UNIQUE INDEX idx ON test(c2) LOCAL;
|
||||
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function
|
||||
|
||||
obclient> CREATE UNIQUE INDEX idx ON test(c2, pk) LOCAL;
|
||||
Query OK, 0 rows affected (5.34 sec)
|
||||
obclient> DROP INDEX idx ON test;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
obclient> CREATE UNIQUE INDEX idx ON test(c2) GLOBAL;
|
||||
Query OK, 0 rows affected (17.47 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
一级分区表
|
||||
==========================
|
||||
|
||||
分区表创建成功后,您可以对一级分区表进行添加、删除或 Truncate 操作。
|
||||
|
||||
添加一级分区
|
||||
---------------------------
|
||||
|
||||
* Range/List 分区
|
||||
|
||||
对于 Range 分区,只能在最大的分区之后添加一个分区,不可以在中间某个或者开始的地方添加。如果当前的分区中有 `MAXVALUE` 的分区,则不能继续添加分区。
|
||||
|
||||
List 分区添加一级分区时,要求添加的分区不与之前的分区冲突即可。如果一个 List 分区有默认分区即 `Default Partition`,则不能添加任何分区。
|
||||
|
||||
MySQL 模式下,在 Range/List 分区中添加一级分区的语法格式如下:
|
||||
|
||||
```sql
|
||||
ALTER TABLE table_name
|
||||
ADD PARTITION
|
||||
(
|
||||
partition_defines
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 Range/List 分区中添加一级分区不会影响全局索引和局部索引的使用。
|
||||
|
||||
|
||||
* Hash/Key 分区
|
||||
|
||||
对于 Hash/Key 分区,目前 OceanBase 数据库暂不支持添加一级分区。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
删除一级分区
|
||||
---------------------------
|
||||
|
||||
删除一级分区时,可以删除一个或多个分区,但不能删除全部分区。
|
||||
|
||||
* Range/List 分区
|
||||
|
||||
对于 Range/List 分区,删除分区时,同时会删除分区中的数据。
|
||||
|
||||
MySQL 模式下,删除一级分区的语法格式如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE table_name DROP PARTITION p1;
|
||||
|
||||
obclient> ALTER TABLE table_name DROP PARTITION p1,p2;
|
||||
```
|
||||
|
||||
|
||||
|
||||
删除分区时,会同时删除分区中的数据,如果只需要删除数据,则可以使用 `TRUNCATE` 语句。
|
||||
|
||||
|
||||
* Hash/Key 分区
|
||||
|
||||
对于 Hash/Key 分区,目前 OceanBase 数据库暂不支持删除一级分区。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Truncate 一级分区
|
||||
----------------------------------
|
||||
|
||||
OceanBase 数据库支持对一级分区表中的 Range/List 分区执行 Truncate 操作,将一个或多个分区中的数据全部移除。
|
||||
|
||||
MySQL 模式下,Truncate 一级分区的语法格式如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE table_name TRUNCATE PARTITION p1;
|
||||
|
||||
obclient> ALTER TABLE table_name TRUNCATE PARTITION p1,p2;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,141 @@
|
||||
二级分区表
|
||||
==========================
|
||||
|
||||
二级分区表创建成功后,您可以对二级分区表进行添加、删除或 Truncate 操作。
|
||||
|
||||
添加一级分区
|
||||
---------------------------
|
||||
|
||||
主要有以下两种场景:
|
||||
|
||||
* 模板化二级分区表
|
||||
|
||||
对于模板化⼆级分区表,添加⼀级分区时只需要指定⼀级分区的定义即可,⼆级分区的定义会⾃动按照模板填充。
|
||||
|
||||
语法如下:
|
||||
|
||||
```sql
|
||||
ALTER TABLE table_name add partition part_name partition_define
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE t_range_range add partition p3 VALUES less than (400);
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 非模板化二级分区表
|
||||
|
||||
对于⾮模板化⼆级分区表,添加⼀级分区时,需要同时指定⼀级分区的定义和该⼀级分区下的⼆级分区定义。
|
||||
|
||||
语法如下:
|
||||
|
||||
```sql
|
||||
ALTER TABLE table_name add partition part_name partition_define
|
||||
(
|
||||
subpartition subpart_name subpartition_define
|
||||
, ...
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE t_range_range1 add partition p4 VALUES less than (500)
|
||||
(
|
||||
subpartition p4_r1 VALUES less than (100),
|
||||
subpartition p4_r2 VALUES less than (200),
|
||||
subpartition p5_r3 VALUES less than (300)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
删除一级分区
|
||||
---------------------------
|
||||
|
||||
OceanBase 数据库支持删除 Range/List 类型的二级分区表中的一级分区,将一个或多个分区从表中移除。删除一级分区同时会删除该一级分区的定义和其对应的二级分区中的数据。
|
||||
|
||||
MySQL 模式下,删除一级分区的语法如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE table_name DROP PARTITION p1;
|
||||
|
||||
obclient> ALTER TABLE table_name DROP PARTITION p1,p2;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
删除二级分区表中的一级分区时,请尽量避免该分区上存在活动的事务或查询,否则可能会导致 SQL 语句报错,或者出现一些异常情况。
|
||||
|
||||
删除二级分区
|
||||
---------------------------
|
||||
|
||||
OceanBase 数据库支持删除⾮模板化⼆级分区表及 Range/List 类型的二级分区表的⼆级分区,将一个或多个分区从表中移除。删除二级分区同时会删除该分区的定义和其中的数据。
|
||||
|
||||
MySQL 模式下,删除二级分区的语法如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE table_name DROP SUBPARTITION p1;
|
||||
|
||||
obclient> ALTER TABLE table_name DROP SUBPARTITION p1,p2;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
删除二级分区表中的二级分区时,请尽量避免该分区上存在活动的事务或查询,否则可能会导致 SQL 语句报错,或者出现一些异常情况。
|
||||
|
||||
Truncate 一级分区
|
||||
----------------------------------
|
||||
|
||||
OceanBase 数据库当前支持对 Range/List 类型的二级分区表中的一级分区执行 Truncate 操作,将一个或多个一级分区中对应的二级分区的数据全部移除。
|
||||
|
||||
MySQL 模式下,Truncate 一级分区的语法如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE table_name TRUNCATE PARTITION p1;
|
||||
|
||||
obclient> ALTER TABLE table_name TRUNCATE PARTITION p1,p2;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
Truncate 二级分区表中的一级分区时,请尽量避免该分区上存在活动的事务或查询,否则可能会导致 SQL 语句报错,或者出现一些异常情况。
|
||||
|
||||
Truncate 二级分区
|
||||
----------------------------------
|
||||
|
||||
OceanBase 数据库支持对 Range/List 类型的二级分区表的⼆级分区执行 Truncate 操作,将一个或多个分区中的数据全部移除。
|
||||
|
||||
MySQL 模式下,删除二级分区的语法如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TABLE table_name TRUNCATE SUBPARTITION p1;
|
||||
|
||||
obclient> ALTER TABLE table_name TRUNCATE SUBPARTITION p1,p2;
|
||||
```
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
Truncate 二级分区表中的二级分区时,请尽量避免该分区上存在活动的事务或查询,否则可能会导致 SQL 语句报错,或者出现一些异常情况。
|
||||
@ -0,0 +1,70 @@
|
||||
副本概述
|
||||
=========================
|
||||
|
||||
本节主要介绍副本相关的基础知识及 OceanBase 数据库支持的副本类型。
|
||||
|
||||
副本相关知识
|
||||
---------------------------
|
||||
|
||||
在介绍副本前,需要了解以下信息:
|
||||
|
||||
* Log:本文中主要指与事务相关的 Clog 日志。
|
||||
|
||||
|
||||
|
||||
* MemTable:表示目前内存中已经被读写更改过的数据,也可称之为内存表。
|
||||
|
||||
|
||||
|
||||
* SSTable:表示存储在磁盘中的基线数据,当数据被事务读取或修改时,会暂存在 MemTable 中。合并发生时 MemTable 中的数据会和 SSTable 中的数据进行合并形成更新版本的 SSTable。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库是以表分区(partition)为原子粒度进行管理的,为了数据安全和提供高可用的数据服务,每个分区数据在物理上存储多份,每一份叫做分区的一个副本。每个副本,包括存储在磁盘上的静态数据(SSTable)、存储在内存的增量数据(MemTable)以及记录事务的日志三类主要的数据。根据存储数据种类的不同,副本有几种不同的类型,以支持不同业务在在数据安全,性能伸缩性,可用性,成本等之间的选择。
|
||||
|
||||
副本类型
|
||||
-------------------------
|
||||
|
||||
OceanBase 数据库中有多种副本类型。
|
||||
|
||||
OceanBase 数据库中副本类型也有以下几种:
|
||||
|
||||
* 全能型副本:目前支持的普通副本,拥有事务日志、MemTable 和 SSTable 等全部完整的数据和功能。它可以随时快速切换为 Leader 以对外提供服务。
|
||||
|
||||
|
||||
|
||||
* 日志型副本:只包含日志的副本,没有 MemTable 和 SSTable。它参与日志投票并对外提供日志服务,可以参与其他副本的恢复,但自己不能变为主提供数据库服务。
|
||||
|
||||
|
||||
|
||||
* 加密投票型副本:包含加密日志的副本,没有 MemTable 和 SSTable。它参与日志投票并对外提供日志服务,可以参与其他副本的恢复,但自己不能变为主提供数据库服务。
|
||||
|
||||
加密投票型副本仅支持部署在加密 Zone 上,不支持部署在常规读写 Zone上。
|
||||
|
||||
|
||||
* 只读型副本:包含完整的日志、MemTable 和 SSTable 等。但是它的日志比较特殊,它不作为 Paxos 成员参与日志的投票,而是作为一个观察者实时追赶 Paxos 成员的日志,并在本地回放。这种副本可以在业务对读取数据的一致性要求不高的时候提供只读服务。因其不加入 Paxos 成员组,又不会造成投票成员增加导致事务提交延时的增加。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
以下表格展示了上述副本的特性差异。
|
||||
|
||||
|
||||
| 特性 | 全能型 | 日志型 | 加密投票型 | 只读型 |
|
||||
|----------------|------------------------------|---------------------|---------------------|----------------------------------------|
|
||||
| LOG | 有,参与投票(STNC_CLOG) | 有,参与投票(STNC_CLOG) | 有,参与投票(STNC_CLOG) | 有,但不属于 Paxos 组,只是 listener(ASYNC_CLOG) |
|
||||
| MemTable | 有(WITH_MEMSTORE) | 无(WITHOUT_MEMSTORE) | 无(WITHOUT_MEMSTORE) | 有(WITH_MEMSTORE) |
|
||||
| SSTable | 有(WITH_MEMSTORE) | 无(WITHOUT_MEMSTORE) | 无(WITHOUT_MEMSTORE) | 有(WITH_MEMSTORE) |
|
||||
| 数据安全 | 高 | 低 | 高 | 中 |
|
||||
| 恢复为 Leader 的时间 | 快 | 不支持 | 不支持 | 不支持 |
|
||||
| 资源成本 | 高 | 低 | 低 | 高 |
|
||||
| 服务 | Leader 提供读写, Follower 可非一致性读 | 不可读写 | 不可读写 | 非一致性读 |
|
||||
| 名称(缩写) | FULL(F) | LOGON(L) | EncryptVote(E) | READONLY(R) |
|
||||
| 副本类型值 | 0 | 5 | 216 | 16 |
|
||||
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
表级副本的使用
|
||||
============================
|
||||
|
||||
本节主要介绍常用的一些表级副本变更操作。
|
||||
|
||||
租户级副本变更操作,请参见 [Locality 管理](../../../6.administrator-guide/5.data-distribution-and-link-management/3.locality-management/1.locality-management-overview.md) 章节。
|
||||
|
||||
表级副本主要通过建表时指定 Locality 属性或者 `ALTER TABLE` 语句指定 Locality 属性,示例语句如下所示:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (...) locality='XXX,XXX,XXX';
|
||||
ALTER TABLE table_name SET locality='XXX,XXX,XXX';
|
||||
```
|
||||
|
||||
|
||||
|
||||
表级 Locality 操作范围
|
||||
-------------------------
|
||||
|
||||
默认表级 Locality 为空的表,通过变更租户 Locality 可批量调整租户下所有表的副本分布。Locality 不为空的表,可通过表级 Locality 变更来调整目标表的副本分布,即表级 Locality 的变更对象为表 Locality 不为空的表。
|
||||
|
||||
操作方式和变更进度查询
|
||||
--------------------
|
||||
|
||||
表级 Locality 的操作方式与租户级 Locality 相同,仅支持每次一个 Zone 上的 Locality 变更。并且变更后的表 Locality 仍然要满足与当前租户 Locality 的匹配限制。表级 Locality 的变更流程也与租户级 Locality 相同,但变更对象仅限于对单个目标表。变更执行后,可登录系统租户运行下述 SQL 语句以查询变更进度:
|
||||
|
||||
```sql
|
||||
obclient> SELECt gmt_create, gmt_modified, tenant_id, table_name, job_type, job_status FROM __all_rootservice_job WHERE job_type LIKE '%LOCALITY%' ORDER BY job_id DESC;
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
租户级 Locality 变更也可使用上述语句进行查询,返回结果中的 `tenant id` 和 `table_name` 列中会显示变更对象的具体值。对于表级 Locality 的变更,返回结果中的 `tenant_id` 为 NULL。
|
||||
|
||||
操作注意事项
|
||||
---------------
|
||||
|
||||
* 对表级 Locality 非空的不同目标表,Locality 变更操作可以同时进行。
|
||||
|
||||
|
||||
|
||||
* 对表级 Locality 非空的表执行 Locality 变更后,在变更未完成时不允许该表所属的租户发生 Locality 变更,即此时通过 `ALTER TENANT` 语句发起的租户 Locality 变更会失败。
|
||||
|
||||
|
||||
|
||||
* 对表级 Locality 非空的表,如果需要在 Zone 或 Region 中调整 `readonly` 或 `memonly` 等 `non_paxos` 类型副本(即不参与投票的副本)的数量时,需要直接修改租户的 Locality 属性列来实现。增减 `non_paxos` 副本的任务会直接交由 RootService 的负载均衡线程完成。
|
||||
|
||||
|
||||
|
||||
* 对表级 Locality 为空的表,如果需要在 Zone 和 Region 内增加 `non_paxos` 类型副本时,可通过 `ALTER TABLE` 修改此表。例如,`tenant Locality=F@z1,F@z2,F@z3` 中有一个 Locality 为空的表,通过 `ALTER TABLE` 修改为 `Locality=F@z1,F@z2,R@z3` 后该表的 Locality 不再为空。同样增减 `non_paxos` 副本的任务也是直接交由 RootService 的负载均衡线程完成。
|
||||
|
||||
|
||||
|
||||
* 不支持将 Locality 非空的表修改为空。
|
||||
|
||||
|
||||
|
||||
* sys 租户系统表的 Locality 必须与 sys 租户的 Locality 保持一致,即系统表的 Locality 始终为空,不支持修改系统表中表级 Locality 的修改。
|
||||
|
||||
|
||||
|
||||
* 在为整个租户的所有表增加、减少或修改 Locality 时,需要执行如下两步操作:
|
||||
|
||||
1. 对租户 Locality 做变更。
|
||||
|
||||
|
||||
|
||||
2. 对租户下所有不为空的表 Locality 做变更。
|
||||
|
||||
在完成第一步租户 Locality 的变更后必须人工进行第二步表 Locality 的变更,如果越过第二步进行下一轮的租户 Locality 变更,将产生不可预知的错误。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例
|
||||
-----------
|
||||
|
||||
假设集群在杭州有三个机房分别为 `hz1@Hangzhou`、`hz2@Hangzhou` 和 `hz3@Hangzhou`。且租户的默认三个全功能 Locality 分别设定为 `F@hz1`、`F@hz2` 和 `F@hz3`。
|
||||
|
||||
当需要定义一个表,且要求其只读副本部署在集群中所有 OBServer 节点上时,可以通过以下 SQL 语句进行创建:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (...) locality = 'F@hz1, F@hz2, F@hz3, R{all_server}@hz1, R{all_server}@hz2, R{all_server}@hz3';
|
||||
```
|
||||
|
||||
|
||||
|
||||
也可通过以下的 `ALTER TABLE` 语句进行修改:
|
||||
|
||||
```sql
|
||||
ALTER TABLE table_name set locality = 'F@hz1, F@hz2, F@hz3, R{all_server}@hz1, R{all_server}@hz2, R{all_server}@hz3';
|
||||
```
|
||||
|
||||
|
||||
|
||||
执行后等待 `__all_rootservice_job` 表中对应任务记录的状态变为 `SUCCESS`,即表示创建或修改完成。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
表级 Locality 的变更与租户级 Locality 变更具有如下制约关系:
|
||||
|
||||
* 在旧的一轮租户级 Locality 没有完成变更时,新一轮的租户级 Locality 变更不允许被执行。
|
||||
|
||||
|
||||
|
||||
* 当租户下 Locality 不为空的表的变更没有完成时,租户级 Locality 变更不允许执行。
|
||||
|
||||
|
||||
|
||||
* 当租户在目标 Zone 的 Locality 变更没有发起时,Locality 不为空的表在目标 Zone 的 Locality 变更不允许执行。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
综上所述,租户级 Locality 变更不允许同时发起多轮变更,租户和表的 Locality 变更前需要先完成未完成的变更。
|
||||
@ -0,0 +1,129 @@
|
||||
Locality 管理概述
|
||||
==================================
|
||||
|
||||
Locality 描述了表、表组或租户下副本的分布情况。这里的副本分布情况指在 Zone 或 Region 上包含的副本的数量以及副本的类型,不同的租户在同一个集群内可以配置不同的 Locality 并且彼此之间相互独立不受影响。
|
||||
|
||||
Locality 语义
|
||||
--------------------
|
||||
|
||||
Locality 基本语法结构型为如下所示:
|
||||
|
||||
```sql
|
||||
replicas{量词}@location
|
||||
```
|
||||
|
||||
|
||||
|
||||
下述表格展示了语法中各元素的意义:
|
||||
|
||||
|
||||
| **元素** | **说明** |
|
||||
|----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| replicas | 表示副本类型,副本类型相关说明请参见[副本概述](../../../6.administrator-guide/5.data-distribution-and-link-management/2.replica-management/1.replica-overview.md)章节。 `replicas`的值为副本名称,您可以在副本类型说明表中的 **名称** 列获得支持的值(支持全名和简写)。 |
|
||||
| location | 表示位置。它是系统已知的一组枚举值。 `location`的值为 Zone 的名称。 |
|
||||
| 量词 | 不指定量词的时候,表示一个副本。用 `{n}`表示 n 个副本。 有一种特殊的量词 `{all_server}`表示副本数和可用的 Server 的数量相同。一个分区在一个 Zone 中最多有一个全功能或日志型副本(这些类型的副本是 Paxos 复制组的成员),只读型副本在同一个 Zone 中可以有多个。 |
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
* 表和表组的 Locality 可以为空,表示继承自所属租户。租户的 Locality 不可以为空。
|
||||
|
||||
|
||||
|
||||
* 当租户的 Locality 发生变更时,在该租户下,所有 Locality 为空的表的副本的分布情况也会随之变化。Locality 不为空的表在租户的 Locality 变更时,其对应副本的分布情况不会改变。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**示例:**
|
||||
|
||||
下述示例展示了在一个拥有五个 Zone(z1\~z5)的 OceanBase 集群中,可以容纳不同 Locality 的多个租户和它们的 Locality 情况:
|
||||
|
||||
* sys tenant 的 Locality: `F@z1,F@z2,F@z3,F@z4,F@z5`
|
||||
|
||||
|
||||
|
||||
* tenant1 的 Locality: `F@z1,F@z2,F,R{ALL_SERVER}@z3`
|
||||
|
||||
|
||||
|
||||
* tenant2 的 Locality: `F@z1`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Locality 变更规则
|
||||
----------------------
|
||||
|
||||
Locality 的变更需要遵循以下规则:
|
||||
|
||||
* 变更进度与 tenant/table 级变更限制
|
||||
|
||||
* 在旧的一轮租户 Locality 没有完成变更时,新一轮的租户 Locality 变更不允许被执行。
|
||||
|
||||
|
||||
|
||||
* 表级 Locality Zone List 必须是租户级 Locality Zone List 的子集。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* Paxos 副本数变更规则
|
||||
|
||||
* Locality 变更的类型转换目前仅支持 F-\>R、R-\>F 和 F-\>L 三种:
|
||||
|
||||
* F-\>R 从 full 副本转换为 readonly 副本,是减 Paxos 副本操作,每次减的 Paxos 副本数需小于变更后 Paxos 的副本数。
|
||||
|
||||
|
||||
|
||||
* R-\>F 从 readonly 副本转换为 full 副本,是加 Paxos 副本操作,每次加的 paxos 副本数需小于变更前 Paxos 的副本数。
|
||||
|
||||
|
||||
|
||||
* F-\>L 从 full 副本转换为 logonly 副本,不涉及 Paxos 副本数量的变化。F-\>L 的变更不能与任何加或减 Paxos 副本的操作同时发生。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 非 Paxos 副本的变化可以和上述任何变更同时发生,没有数量限制。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Locality 应用场景
|
||||
----------------------
|
||||
|
||||
Locality 的设置通常用于集群的副本数升级、降级或集群的搬迁:
|
||||
|
||||
* 集群副本数升级
|
||||
|
||||
以租户为粒度,对集群中的每一个租户,增加租户下 Partition 的副本数。例如,将 Locality 由 `F@z1,F@z2,F@z3`变更为 `F@z1,F@z2,F@z3,F@z4,F@z5`,租户从 3 副本变为 5 副本。
|
||||
|
||||
|
||||
* 集群副本数降级
|
||||
|
||||
以租户为粒度,对集群内的每一个租户减少其中 Partition 的副本数。例如,将 Locality 由 `F@z1,F@z2,F@z3,F@z4,F@z5 `变更为 `F@z1,F@z2,F@z3,F@z4`,租户从 5 副本变为 4 副本。
|
||||
|
||||
|
||||
* 集群搬迁
|
||||
|
||||
以租户为粒度,对集群内的每一个租户通过若干次 Locality 变更。比如,将 Locality 从 `F@hz1,F@hz2,F@hz3`变更为 `F@hz1,F@sh1,F@sh2`即代表将原集群中属于杭州的两个 Zone 迁到上海。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,22 @@
|
||||
修改租户的 Locality
|
||||
===================================
|
||||
|
||||
|
||||
|
||||
修改租户的 Locality 的语法如下:
|
||||
|
||||
```sql
|
||||
ALTER TENANT 'TENANT_NAME' SET LOCALITY = locality
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例:将租户 test_tenant 的 Locality 修改为 `F{1}@z1,F{1}@z2,F{1}@z3,F{1}@z4 `:
|
||||
|
||||
```sql
|
||||
obclient> ALTER TENANT test_tenant set locality = 'F{1}@z1,F{1}@z2,F{1}@z3,F{1}@z4';
|
||||
```
|
||||
|
||||
|
||||
|
||||
变更 Locality 之前,需要确认待变更的 Zone 上资源单元和资源池的状态。如果 Zone 上的 OBServer 资源不足导致无法存放租户需要的资源单元,则将导致无法进行 Locality 变更。
|
||||
@ -0,0 +1,38 @@
|
||||
事务概述
|
||||
=========================
|
||||
|
||||
本节主要介绍事务的定义以及基本的事务控制语句。
|
||||
|
||||
事务指的是一序列 SQL 语句,OceanBase 数据库将这组 SQL 语句当作一个整体,要么全部执行成功,要么全部不成功;不会出现部分 SQL 语句执行成功,或者部分 SQL 未执行成功的场景。
|
||||
|
||||
通常事务中的 SQL 会包含 DML 语句,也会包含查询语句。如果一个事务中的 SQL 只有查询语句,这个事务通常称为只读事务。
|
||||
|
||||
基本的事务控制语句有:
|
||||
|
||||
* BEGIN:显式开启一个事务。该命令为可选,如果租户会话的参数 `autocommit` 的值为 `off` ,即关闭自动提交事务功能,则不需要显式发出这个命令;如果参数 `autocommit` 的值为 `on` ,即开启自动提交事务功能,则每条 SQL 就是一个独立的事务;如果要多个 SQL 组成一个事务,需要显式发起 BEGIN 命令。
|
||||
|
||||
|
||||
|
||||
* SAVEPOINT:在事务过程中标记一个"保存点",事务可以事后选择回滚到这个点。保存点是可选的,一个事务过程中也可以有多个保存点。
|
||||
|
||||
|
||||
|
||||
* COMMIT:结束当前事务,让事务所有修改持久化并生效,清除所有保存点和释放事务持有的锁。
|
||||
|
||||
|
||||
|
||||
* ROLLBACK:回滚整个事务已做的修改或者只回滚某个保存点之后事务已做的修改,清除回滚部分包含的所有保存点和释放事务持有的锁。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
如果您使用的是 OBClient 工具,您可以在 SQL 提示符后发起事务控制命令,也可以通过修改会话级别的 `autocommit` 参数设置是否自动提交事务。如果修改的是租户级别的 `autocommit` 参数,则需要断开会话重新连接才会生效。
|
||||
|
||||
如果您使用的是图形化客户端工具,例如 DBeaver,您可以在 SQL 编辑窗口里发起事务控制命令,或者在工具栏上单击提交和回滚的图标。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果会话级的 `autocommit` 变量的值为 `off`,并且没有显式地提交事务,则当程序异常中断时,OceanBase 数据库会自动回滚最后一个未提交的事务。建议显式地提交事务或者回滚事务。
|
||||
@ -0,0 +1,81 @@
|
||||
提交事务
|
||||
=========================
|
||||
|
||||
提交一个事务会让事务的修改持久化生效,清除保存点并释放事务所持有的所有锁。
|
||||
|
||||
要显式地提交事务,则需要使用 `COMMIT` 语句。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库会在 DDL 语句前和后隐式的发起一个 `COMMIT` 语句,这个也会提交事务。
|
||||
|
||||
MySQL 模式
|
||||
-----------------------------
|
||||
|
||||
MySQL 模式下:
|
||||
|
||||
* 如果使用 `BEGIN` 开启一个事务,执行 DML 语句后需要使用 `COMMIT` 提交事务。
|
||||
|
||||
在您提交事务之前:
|
||||
* 您的修改只对当前会话可见,对其他数据库会话不可见。
|
||||
|
||||
|
||||
|
||||
* 您的修改没有持久化,所以不是最终的修改,可以使用 `ROLLBACK` 语句回滚这些修改。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
在您提交事务之后:
|
||||
* 您的修改对所有数据库会话可见。
|
||||
|
||||
|
||||
|
||||
* 您的修改持久化成功,不可以使用 `ROLLBACK` 语句回滚这些修改。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 如果不使用 `BEGIN` 开启事务,则一条 SQL 就是一个事务,不再需要提交事务。SQL 执行后您的修改即持久化成功,不可以使用 `ROLLBACK` 语句回滚这些修改。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> BEGIN;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t_insert(id,name) VALUES(4,'JP');
|
||||
Query OK, 1 row affected (0.01 sec)
|
||||
|
||||
obclient> COMMIT;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> ^Bye
|
||||
|
||||
[qing.meiq@h07g12088.sqa.eu95 /home/qing.meiq/bmsql]
|
||||
$obclient -h192.168.1.101 -utpcc@obbmsql#obdemo -P2883 -p123456 TPCC
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| ID | NAME | VALUE | GMT_CREATE |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-02 17:52:31 |
|
||||
| 2 | US | 10002 | 2020-04-02 17:52:38 |
|
||||
| 3 | EN | 10003 | 2020-04-02 17:52:38 |
|
||||
| 4 | JP | NULL | 2020-04-02 17:53:34 |
|
||||
+----+------+-------+---------------------+
|
||||
4 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,226 @@
|
||||
回滚事务
|
||||
=========================
|
||||
|
||||
回滚一个事务指将事务的修改全部撤销。可以回滚当前整个未提交事务,也可以回滚到事务中任意一个保存点。如果要回滚到某个保存点,必须将 `ROLLBACK` 和 `TO SAVEPOINT` 语句结合使用。
|
||||
|
||||
回滚整个事务:
|
||||
|
||||
* 事务会结束。
|
||||
|
||||
|
||||
|
||||
* 所有的修改会被丢弃。
|
||||
|
||||
|
||||
|
||||
* 清除所有保存点。
|
||||
|
||||
|
||||
|
||||
* 释放事务持有的所有锁。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
回滚到某个保存点:
|
||||
|
||||
* 事务不会结束。
|
||||
|
||||
|
||||
|
||||
* 保存点之前的修改被保留,保存点之后的修改被丢弃。
|
||||
|
||||
|
||||
|
||||
* 清除保存点之后的保存点(不包括保存点自身)。
|
||||
|
||||
|
||||
|
||||
* 释放保存点之后事务持有的所有锁。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
回滚整个事务
|
||||
---------------------------
|
||||
|
||||
回滚整个事务的示例如下:
|
||||
|
||||
* MySQL 模式下,回滚事务的全部修改。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| ID | NAME | VALUE | GMT_CREATE |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-02 17:52:31 |
|
||||
| 2 | US | 10002 | 2020-04-02 17:52:38 |
|
||||
| 3 | EN | 10003 | 2020-04-02 17:52:38 |
|
||||
+----+------+-------+---------------------+
|
||||
3 rows in set (0.00 sec)
|
||||
|
||||
obclient> BEGIN;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t_insert(id, name, value) VALUES(4,'JP',10004);
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t_insert(id, name, value) VALUES(5,'FR',10005),(6,'RU',10006);
|
||||
Query OK, 2 rows affected (0.00 sec)
|
||||
Records: 2 Duplicates: 0 Warnings: 0
|
||||
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| ID | NAME | VALUE | GMT_CREATE |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-02 17:52:31 |
|
||||
| 2 | US | 10002 | 2020-04-02 17:52:38 |
|
||||
| 3 | EN | 10003 | 2020-04-02 17:52:38 |
|
||||
| 4 | JP | NULL | 2020-04-02 17:53:34 |
|
||||
| 5 | FR | 10005 | 2020-04-02 17:54:53 |
|
||||
| 6 | RU | 10006 | 2020-04-02 17:54:53 |
|
||||
+----+------+-------+---------------------+
|
||||
6 rows in set (0.00 sec)
|
||||
|
||||
obclient> ROLLBACK;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| ID | NAME | VALUE | GMT_CREATE |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-02 17:52:31 |
|
||||
| 2 | US | 10002 | 2020-04-02 17:52:38 |
|
||||
| 3 | EN | 10003 | 2020-04-02 17:52:38 |
|
||||
+----+------+-------+---------------------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
回滚到某个保存点
|
||||
-----------------------------
|
||||
|
||||
以下示例展示了一个事务中包含多个 DML 语句和多个保存点,当回滚到其中一个保存点后,仅丢弃了保存点后面的那部份修改。
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
1. 查看表当前记录。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| id | name | value | gmt_create |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-03 16:05:45 |
|
||||
| 2 | US | 10002 | 2020-04-03 16:05:54 |
|
||||
| 3 | UK | 10003 | 2020-04-03 16:05:54 |
|
||||
+----+------+-------+---------------------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 开启一个事务,设置多个保存点信息。
|
||||
|
||||
```sql
|
||||
obclient> SET SESSION autocommit=off;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> BEGIN;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t_insert(id, name) VALUES(6,'FR');
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> SAVEPOINT fr;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t_insert(id, name) VALUES(7,'RU');
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> SAVEPOINT ru;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> INSERT INTO t_insert(id, name) VALUES(8,'CA');
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
obclient> SAVEPOINT ca;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 查看当前会话中,事务未提交的所有修改。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| id | name | value | gmt_create |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-03 16:05:45 |
|
||||
| 2 | US | 10002 | 2020-04-03 16:05:54 |
|
||||
| 3 | UK | 10003 | 2020-04-03 16:05:54 |
|
||||
| 6 | FR | NULL | 2020-04-03 16:26:22 |
|
||||
| 7 | RU | NULL | 2020-04-03 16:26:32 |
|
||||
| 8 | CA | NULL | 2020-04-03 16:26:42 |
|
||||
+----+------+-------+---------------------+
|
||||
6 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. 回滚事务到其中一个保存点。
|
||||
|
||||
```sql
|
||||
obclient> ROLLBACK TO SAVEPOINT ru;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| id | name | value | gmt_create |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-03 16:05:45 |
|
||||
| 2 | US | 10002 | 2020-04-03 16:05:54 |
|
||||
| 3 | UK | 10003 | 2020-04-03 16:05:54 |
|
||||
| 6 | FR | NULL | 2020-04-03 16:26:22 |
|
||||
| 7 | RU | NULL | 2020-04-03 16:26:32 |
|
||||
+----+------+-------+---------------------+
|
||||
5 rows in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
5. 提交事务,确认表最新修改包含保存点之前的修改。
|
||||
|
||||
```sql
|
||||
obclient> COMMIT;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
obclient> SELECT * FROM t_insert;
|
||||
+----+------+-------+---------------------+
|
||||
| id | name | value | gmt_create |
|
||||
+----+------+-------+---------------------+
|
||||
| 1 | CN | 10001 | 2020-04-03 16:05:45 |
|
||||
| 2 | US | 10002 | 2020-04-03 16:05:54 |
|
||||
| 3 | UK | 10003 | 2020-04-03 16:05:54 |
|
||||
| 6 | FR | NULL | 2020-04-03 16:26:22 |
|
||||
| 7 | RU | NULL | 2020-04-03 16:26:32 |
|
||||
+----+------+-------+---------------------+
|
||||
5 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,88 @@
|
||||
事务隔离级别
|
||||
===========================
|
||||
|
||||
本节主要介绍 OceanBase 数据库的隔离级别及其设置方法。
|
||||
|
||||
ANSI 和 ISO/IEC 基于 SQL 标准定义了四种隔离级别,OceanBase 数据库目前支持了以下几种隔离级别:
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
* 读已提交(Read Committed)
|
||||
|
||||
|
||||
|
||||
* 可重复读(Repeatable Read)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库默认的隔离级别为读已提交(Read Committed)。
|
||||
|
||||
设置隔离级别
|
||||
---------------------------
|
||||
|
||||
设置隔离级别的方式有两种,分别为事务级别及 Session 级别:
|
||||
|
||||
* 事务级别
|
||||
|
||||
```sql
|
||||
obclient> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
*
|
||||
Session 级别
|
||||
|
||||
```sql
|
||||
obclient> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
设置事务的隔离级别时,应注意以下事项:
|
||||
|
||||
* 不能在事务的执行过程中设置事务的隔离级别,否则会报以下错误。
|
||||
|
||||
```sql
|
||||
ERROR:ORA-01453: SET TRANSACTION must be first statement of transaction
|
||||
```
|
||||
|
||||
|
||||
|
||||
* Session 需要维护 Session 级别的事务隔离级别,在开启事务时需要获取 Session 级别的事务隔离级别。该隔离级别可以被事务级别的隔离级别覆盖。
|
||||
|
||||
查看当前事务隔离级别的语句如下:
|
||||
|
||||
```sql
|
||||
obclient> SHOW VARIABLES LIKE 'tx_isolation';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
使用限制
|
||||
-------------------------
|
||||
|
||||
* 内部事务
|
||||
|
||||
由用户事务触发的内部事务,以及维护内部表信息的事务都称为内部事务,内部事务采用 Read Committed 隔离级别。
|
||||
|
||||
|
||||
* 跨租户事务
|
||||
|
||||
由于当前有一些内部表尚未拆分到普通租户下,有可能存在跨租户的事务。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,140 @@
|
||||
创建用户
|
||||
=========================
|
||||
|
||||
本节主要介绍 OceanBase 数据库用户创建的命令示例及操作方式。
|
||||
|
||||
通过 SQL 语句创建 MySQL 模式的用户
|
||||
--------------------------------------------
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
MySQL 模式的用户管理语法树如下所示:
|
||||
|
||||
```sql
|
||||
create_user_stmt:
|
||||
CREATE USER [IF NOT EXISTS] user_name [IDENTIFIED BY 'password'];
|
||||
|
||||
alter_user_stmt:
|
||||
ALTER USER user_name ACCOUNT {LOCK | UNLOCK};
|
||||
| ALTER USER user_name IDENTIFIED BY 'password';
|
||||
| SET PASSWORD [FOR user_name] = PASSWORD('password');
|
||||
| RENAME USER rename_user_action_list;
|
||||
|
||||
drop_user_stmt:
|
||||
DROP USER user_name_list;
|
||||
|
||||
rename_user_action_list:
|
||||
rename_user_action [, rename_user_action ...]
|
||||
|
||||
rename_user_action:
|
||||
user_name TO user_name
|
||||
|
||||
user_name_list:
|
||||
user_name [, user_name ...]
|
||||
|
||||
password:
|
||||
STR_VALUE
|
||||
```
|
||||
|
||||
|
||||
|
||||
MySQL 模式下,创建名为 `sqluser01` 和 `sqluser02` 的用户,且密码均为 `123456`,示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE USER 'sqluser01' IDENTIFIED BY '123456', 'sqluser02' IDENTIFIED BY '123456';
|
||||
```
|
||||
|
||||
|
||||
|
||||
更多 MySQL 模式下 `CREATE USER` 语句的信息,请参见 [CREATE USER](../../10.sql-reference/5.sql-statement/21.create-user-1.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 创建 MySQL 模式的用户
|
||||
------------------------------------------
|
||||
|
||||
OCP 从 V2.5.0 版本开始支持创建 MySQL 兼容模式的用户。
|
||||
|
||||
**前提条件**
|
||||
|
||||
创建用户前,需要确认以下信息:
|
||||
|
||||
* 当前 OCP 用户需要具有租户修改权限,OCP 用户权限相关信息请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
* 当前 OCP 用户的密码箱中具有该租户的 root 密码,OCP 用户的密码箱相关操作请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**操作步骤**
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左导航栏上单击 **租户** ,进入租户概览页面。
|
||||
|
||||
|
||||
|
||||
3. 在租户列表中,选择 **租户模式** 为 **MySQL** 的租户,进入 **总览** 页面。
|
||||
|
||||
|
||||
|
||||
4. 在左侧导航栏上,单击 **用户管理** 。
|
||||
|
||||
|
||||
|
||||
5. 在页面右上角单击 **新建用户** 。
|
||||
|
||||
|
||||
|
||||
6. 在弹出的 **新建数据库用户** 对话框中,配置用户信息。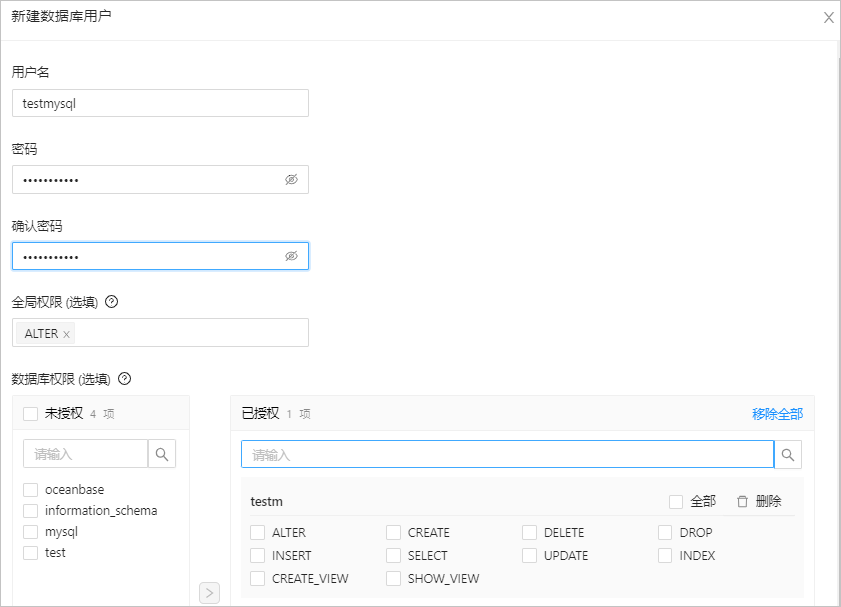
|
||||
|
||||
用户配置相关说明如下表所示。
|
||||
|
||||
|
||||
| 配置 | 描述 |
|
||||
|-----------|---------------------------------------------------------------------|
|
||||
| **用户名** | 待创建的数据库用户的名称。 |
|
||||
| **密码** | 长度为 8 \~32 个字符,包含至少 2 个数字、2 个大写字母、2 个小写字母和 2 个特殊字符,支持的特殊字符为 ._+@#$% |
|
||||
| **确认密码** | 与新密码保持一致。 |
|
||||
| **全局权限** | 选填,该权限适用于所有数据库。 |
|
||||
| **数据库权限** | 选填,对新用户进行授权。选中新用户可访问的数据库,单击 **\>** 图标,将目标数据库移动至右侧区域,并选中需要添加的权限。 |
|
||||
|
||||
|
||||
|
||||
**全局权限** 和 **数据库库权限** 中涉及的权限类型说明如下表所示。
|
||||
|
||||
|
||||
| 权限 | 说明 |
|
||||
|----------------|-------------------------------------------------------------|
|
||||
| ALTER | ALTER TABLE 的权限 |
|
||||
| CREATE | CREATE TABLE 的权限 |
|
||||
| DELETE | DELETE 的权限 |
|
||||
| DROP | DROP 的权限 |
|
||||
| INSERT | INSERT 的权限 |
|
||||
| SELECT | SELECT 的权限 |
|
||||
| UPDATE | UPDATE 的权限 |
|
||||
| INDEX | CREATE INDEX、DROP INDEX 的权限 |
|
||||
| CREATE VIEW | 创建、删除视图的权限 |
|
||||
| SHOW VIEW | SHOW CREATE VIEW 的权限 |
|
||||
| CREATE USER | CREATE USER、DROPUSER、RENAME USER 和 REVOKE ALLPRIVILEGES 的权限 |
|
||||
| PROCESS | PROCESS 权限 |
|
||||
| SUPER | SET GLOBAL 修改全局系统参数的权限 |
|
||||
| SHOW DATABASES | 全局 SHOW DATABASES 的权限 |
|
||||
| GRANT OPTION | GRANT OPTION 的权限 |
|
||||
|
||||
|
||||
|
||||
7. 完成后,单击 **提交** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
管理角色
|
||||
=========================
|
||||
|
||||
本节主要介绍 Oracle 模式中角色的管理命令。
|
||||
|
||||
在 Oracle 模式中,角色是一组系统权限、对象权限的组合,角色中也可以包含其他角色。
|
||||
|
||||
一个用户可以被授予多个角色,同时还可以设置这些角色是否生效。用户将拥有生效角色的所有权限,用户不拥有失效的角色中包含的权限。
|
||||
|
||||
OceanBase 数据库支持对 Oracle 模式中的角色进行以下操作:
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
授予系统权限或角色时,当前用户必须拥有被授予的权限或角色,并且拥有 `GRANT OPTION` 权限,才能操作成功。
|
||||
|
||||
* 角色之间相互授权
|
||||
|
||||
角色相互授权的语法如下:
|
||||
|
||||
```sql
|
||||
GRANT <role_name_list> TO role_name WITH ADMIN OPTION;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 向 `PUBLIC` 角色中添加权限或将 `PUBLIC` 角色添加给用户
|
||||
|
||||
支持整个租户内的 `PUBLIC` 角色,可以向 `PUBLIC` 角色中添加权限,也可以将 `PUBLIC` 角色添加给某一个用户。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> GRANT [privilege_list] TO PUBLIC;
|
||||
|
||||
obclient> GRANT PUBLIC TO user_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 指定用户在登录时生效或失效的角色
|
||||
|
||||
支持通过 `DEFAULT ROLE` 子句,指定一个或者多个角色名称,生效一个或多个角色;也可以通过 `ALL`,生效所有被授予的角色。同时,还可以通过 `EXCEPT`,指定失效的角色;通过 `NONE`,失效所有被授予的角色。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER USER user_name DEFAULT ROLE role_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 指定当前会话中,用户生效或失效的角色
|
||||
|
||||
支持在当前会话中通过 `SET ROLE` 语句设置用户被授予的角色哪些生效或失效。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
设置后,仅影响当前 Session,不影响之后的 Session。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,178 @@
|
||||
修改用户权限
|
||||
===========================
|
||||
|
||||
本节主要介绍 OceanBase 数据库用户权限修改的命令示例及操作方法。
|
||||
|
||||
注意事项
|
||||
-------------------------
|
||||
|
||||
对于授予权限操作:
|
||||
|
||||
* 进行用户授权操作前,请确保当前用户拥有被授予的权限,并且拥有 `GRANT OPTION` 权限。
|
||||
|
||||
|
||||
|
||||
* 授权后,被授权的用户需要重新连接 OceanBase 数据库,权限才会生效。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
对于移除权限操作:
|
||||
|
||||
* 当前用户必须拥有被移除的权限,并且拥有 `GRANT OPTION` 权限。
|
||||
|
||||
|
||||
|
||||
* 移除 `ALL PRIVILEGES` 和 `GRANT OPTION` 权限时,当前用户必须拥有全局 `GRANT OPTION` 权限,或者对权限表的 `UPDATE` 及 `DELETE` 权限。
|
||||
|
||||
|
||||
|
||||
* 权限移除操作不会级联。例如,用户 `user1` 为 `user2` 授予了某些权限,移除 `user1` 的权限并不会同时也移除 `user2` 的相应权限。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 SQL 语句授予或移除权限
|
||||
-------------------------------------
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
MySQL 模式下用户权限管理语句的语法如下:
|
||||
|
||||
```sql
|
||||
grant_stmt:
|
||||
GRANT privilege_type_list ON privilege_level TO user_option_list [WITH GRANT OPTION];
|
||||
|
||||
revoke_stmt:
|
||||
REVOKE privilege_type_list ON privilege_level FROM user_name_list;
|
||||
|
||||
show_grants_stmt:
|
||||
SHOW GRANTS [FOR user_name];
|
||||
|
||||
privilege_type_list:
|
||||
{ALL [PRIVILEGES] | privilege_type [, privilege_type ...]}
|
||||
|
||||
privilege_type:
|
||||
ALTER
|
||||
| CREATE
|
||||
| CREATE USER
|
||||
| CREATE VIEW
|
||||
| DELETE
|
||||
| DROP
|
||||
| GRANT OPTION
|
||||
| INDEX
|
||||
| INSERT
|
||||
| PROCESS
|
||||
| SELECT
|
||||
| SHOW DATABASES
|
||||
| SHOW VIEW
|
||||
| SUPER
|
||||
| UPDATE
|
||||
| USAGE
|
||||
|
||||
privilege_level:
|
||||
*
|
||||
| *.*
|
||||
| database_name.*
|
||||
| database_name.table_name
|
||||
| table_name
|
||||
|
||||
user_option_list:
|
||||
user_option [, user_option ...]
|
||||
|
||||
user_option:
|
||||
user_name [IDENTIFIED BY 'password']
|
||||
|
||||
password:
|
||||
STR_VALUE
|
||||
|
||||
user_name_list:
|
||||
user_name [, user_name ...]
|
||||
```
|
||||
|
||||
|
||||
|
||||
相关示例如下:
|
||||
* 授予权限
|
||||
|
||||
```sql
|
||||
obclient> GRANT ALL PRIVILEGES ON *.* TO demo WITH GRANT OPTION;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 移除权限
|
||||
|
||||
```sql
|
||||
obclient> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'demo';
|
||||
Query OK, 0 rows affected (0.03 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 修改 MySQL 模式的用户权限
|
||||
--------------------------------------------
|
||||
|
||||
OCP 从 V2.5.0 版本开始支持修改 MySQL 兼容模式的用户权限。
|
||||
|
||||
**前提条件**
|
||||
|
||||
修改用户权限前,需要确认以下信息:
|
||||
|
||||
* 当前 OCP 用户需要具有租户修改权限,OCP 用户权限相关信息请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
* 当前 OCP 用户的密码箱中具有该租户的 root 密码,OCP 用户的密码箱相关操作请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**操作步骤**
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左导航栏上单击 **租户** ,进入租户概览页面。
|
||||
|
||||
|
||||
|
||||
3. 在租户列表中,筛选 **租户模式** 为 **MySQL** 的租户,单击其租户名,进入 **总览** 页面。
|
||||
|
||||
|
||||
|
||||
4. 在左侧导航栏上,单击 **用户管理** 。
|
||||
|
||||
|
||||
|
||||
5. 在用户列表中,找到待修改权限的用户,在对应的 **操作** 列中,单击 **修改权限** 。
|
||||
|
||||

|
||||
|
||||
|
||||
6. 在弹出的对话框中,修改全局权限和数据库权限。
|
||||
|
||||
**全局权限** 和 **数据库库权限** 中涉及的权限类型说明如下表所示。
|
||||
|
||||
|
||||
|
||||
|
||||
7. 单击 **提交** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,21 @@
|
||||
查看白名单
|
||||
==========================
|
||||
|
||||
您可以通过 ob_tcp_invited_nodes 参数来查看白名单的设置情况。
|
||||
|
||||
`ob_tcp_invited_nodes` 参数是租户全局的白名单限制参数。
|
||||
|
||||
执行以下语句,查看该变量以确认白名单设置:
|
||||
|
||||
```sql
|
||||
obclient> SHOW VARIABLES LIKE 'ob_tcp_invited_nodes';
|
||||
+----------------------+-------+
|
||||
| Variable_name | Value |
|
||||
+----------------------+-------+
|
||||
| ob_tcp_invited_nodes | % |
|
||||
+----------------------+-------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
更多 `ob_tcp_invited_nodes` 的信息,请参见 [ob_tcp_invited_nodes](../../14.reference-guide-oracle-mode/2.system-variable-1/83.ob_tcp_invited_nodes-1.md)。
|
||||
@ -0,0 +1,114 @@
|
||||
锁定和解锁用户
|
||||
============================
|
||||
|
||||
本节主要介绍 OceanBase 数据库锁定和解锁用户的命令示例及操作方法。
|
||||
|
||||
通过 SQL 语句锁定和解锁用户
|
||||
-------------------------------------
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
MySQL 模式的锁定和解锁用户示例如下:
|
||||
|
||||
|
||||
* 锁定用户
|
||||
|
||||
```sql
|
||||
obclient> ALTER USER demo ACCOUNT LOCK;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
|
||||
obclient -udemo@demo0_111 -P2881 -h10.10.10.1 -pttt
|
||||
obclient: [Warning] Using a password on the command line interface can be insecure.
|
||||
ERROR 3118 (HY000): User locked
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 解锁用户
|
||||
|
||||
```sql
|
||||
obclient> ALTER USER demo ACCOUNT UNLOCK;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
|
||||
obclient -udemo@demo0_111 -P2881 -h10.10.10.1 -pttt
|
||||
obclient: [Warning] Using a password on the command line interface can be insecure.
|
||||
Welcome to the OceanBase monitor. Commands end with ; or \g.
|
||||
Your OceanBase connection id is 3222145887
|
||||
Server version: 5.7.25 OceanBase 2.2.74 (...) (Built Jul 15 2020 21:30:23)
|
||||
|
||||
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
|
||||
|
||||
Oracle is a registered trademark of Oracle Corporation and/or its
|
||||
affiliates. Other names may be trademarks of their respective
|
||||
owners.
|
||||
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
|
||||
obclient>
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 锁定和解锁用户
|
||||
-----------------------------------
|
||||
|
||||
OCP 从 V2.5.0 版本开始支持锁定和解锁 MySQL 兼容模式的用户。
|
||||
|
||||
**前提条件**
|
||||
|
||||
锁定和解锁用户前,需要确认以下信息:
|
||||
|
||||
* 当前 OCP 用户需要具有租户修改权限,OCP 用户权限相关信息请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
* 当前 OCP 用户的密码箱中具有该租户的 root 密码,OCP 用户的密码箱相关操作请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**操作步骤**
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左导航栏上单击 **租户** ,进入租户概览页面。
|
||||
|
||||
|
||||
|
||||
3. 在租户列表中,筛选 **租户模式** 为 **MySQL** 的租户,单击其租户名,进入 **总览** 页面。
|
||||
|
||||
|
||||
|
||||
4. 在左侧导航栏上,单击 **用户管理** 。
|
||||
|
||||
|
||||
|
||||
5. 在用户列表中,找到待操作的用户,在对应的 **锁定** 列中,选择开启或关闭锁定开关。
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
开启锁定开关后,将导致该用户不允许登录,请谨慎操作。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
删除用户
|
||||
=========================
|
||||
|
||||
本节主要介绍 OceanBase 数据库删除用户的命令示例及操作方法。
|
||||
|
||||
通过 SQL 语句删除 MySQL 的用户
|
||||
------------------------------------------
|
||||
|
||||
* MySQL 模式
|
||||
|
||||
MySQL 模式下删除名为 `sqluser02` 用户的示例如下:
|
||||
|
||||
```sql
|
||||
obclient>DROP USER sqluser02;
|
||||
Query OK, 0 rows affected (0.02 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
更多 MySQL 模式下`DROP USER` 语句的信息请参见 [DROP USER](../../10.sql-reference/5.sql-statement/34.drop-user.md)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 删除 MySQL 模式的用户
|
||||
------------------------------------------
|
||||
|
||||
OCP 从 V2.5.0 版本开始支持删除 MySQL 兼容模式的用户。
|
||||
|
||||
**前提条件**
|
||||
|
||||
删除用户前,需要确认以下信息:
|
||||
|
||||
* 当前 OCP 用户需要具有租户修改权限,OCP 用户权限相关信息请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
* 当前 OCP 用户的密码箱中具有该租户的 root 密码,OCP 用户的密码箱相关操作请参见对应版本的《OCP 用户指南》文档。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**操作步骤**
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左导航栏上单击 **租户** ,进入租户概览页面。
|
||||
|
||||
|
||||
|
||||
3. 在租户列表中,筛选 **租户模式** 为 **MySQL** 的租户,单击其租户名,进入 **总览** 页面。
|
||||
|
||||
|
||||
|
||||
4. 在左侧导航栏上,单击 **用户管理** 。
|
||||
|
||||
|
||||
|
||||
5. 在用户列表中,找到待操作的用户,在对应的 **操作** 列中,单击 **删除** 。
|
||||
|
||||
|
||||
|
||||
6. 在弹出的确认框中,单击 **删除** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
回收站支持的对象
|
||||
=============================
|
||||
|
||||
|
||||
|
||||
回收站用来存储用户删除的数据库和表等信息。回收站在原理上说就是一个数据字典表,放置用户删除的数据库对象信息。用户删除的东西被放入回收站后,其实仍然占据着物理空间,除非您手动进行清除( `PURGE` )或者对象定期被数据库系统删除。
|
||||
|
||||
OceanBase 数据库 V1.0.0 时就实现了回收站功能。
|
||||
|
||||
可以进入回收站的对象有索引、表、库和租户。
|
||||
|
||||
|
||||
| **模式** | **索引(Index)** | **表(Table)** | **数据库(Database)** | **租户(Tenant)** |
|
||||
|-----------|---------------|--------------|-------------------|----------------|
|
||||
| **MySQL** | √ | √ | √ | √ |
|
||||
|
||||
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
* `TRUNCATE `或 `DROP `系统表不会进入回收站。
|
||||
|
||||
|
||||
|
||||
* 直接`TRUNCATE`或 `DROP`索引不会进入回收站。
|
||||
|
||||
|
||||
|
||||
* 不能对回收站的对象做任何写操作(DML或 DDL 操作),只能进行只读操作(`SELECT`)。
|
||||
|
||||
|
||||
|
||||
* 操作时需要使用租户管理账号进行操作。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,178 @@
|
||||
数据库、表和索引级回收站
|
||||
=================================
|
||||
|
||||
|
||||
|
||||
查看回收站
|
||||
--------------------------
|
||||
|
||||
租户管理员可以通过如下命令,查看回收站中的对象。
|
||||
|
||||
```sql
|
||||
obclient> SHOW RECYCLEBIN;
|
||||
```
|
||||
|
||||
|
||||
|
||||
开启和关闭回收站
|
||||
-----------------------------
|
||||
|
||||
租户创建之后,默认是开启回收站的 **,** 此时对数据库对象进行 `Truncate` / `Drop` 操作后,对象会进入到回收站。
|
||||
|
||||
控制回收站开启关闭的命令分为租户级别和 Session 级别:
|
||||
|
||||
* 租户级别的开启关闭语句
|
||||
|
||||
```sql
|
||||
obclient> SET GLOBAL `recyclebin` = on /off;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* Session 级别的开启关闭语句
|
||||
|
||||
```sql
|
||||
obclient> SET @@recyclebin = on/off
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
恢复回收站对象
|
||||
----------------------------
|
||||
|
||||
使用 `FLASHBACK`` `命令可恢复回收站中的数据库和表对象,只有租户的管理员用户才可以使用该命令。恢复时可对修改对象的名称,但是不要和已有对象重名。
|
||||
|
||||
示例如下:
|
||||
|
||||
* 恢复对象数据库
|
||||
|
||||
```sql
|
||||
obclient> FLASHBACK DATABASE object_name TO BEFORE DROP [RENAME TO database_name];
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 恢复对象表
|
||||
|
||||
```sql
|
||||
obclient> FLASHBACK TABLE object_name TO BEFORE DROP [RENAME to table_name];
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
限制:
|
||||
|
||||
* `FLASHBACK`数据库对象的顺序需要符合从属关系,即:Database-\>Table-\> Index。
|
||||
|
||||
|
||||
|
||||
* MySQL 模式下恢复表会连同索引一并恢复。
|
||||
|
||||
|
||||
|
||||
* 通过 `PURGE` 命令可以删除表的索引,但是 `FLASHBACK` 命令不支持恢复索引。
|
||||
|
||||
|
||||
|
||||
* 如果一张表在进入回收站前属于某个表组,那么删除该表组后再恢复该表会导致它不属于任何一个表组。如果表组未删除,则恢复后该表还在原表组中。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
手动清理回收站
|
||||
----------------------------
|
||||
|
||||
频繁删除数据库对象并重建,会在回收站产生大量数据,这些数据可以通过`PURGE` 命令清理。
|
||||
**注意**
|
||||
|
||||
|
||||
|
||||
`PURGE` 操作会删除对象和从属于该对象的对象(Database-\>Table-\>Index)。
|
||||
|
||||
`PURGE` 操作会删除对象的元数据信息和 `__all_recyclebin` 中的记录。 执行 `PURGE` 后,在 OceanBase 数据库中将再也查不到对象的信息,真实数据也最终会被作为垃圾回收。
|
||||
|
||||
当一个对象的上层对象被`PURGE` ,那么当前回收站中关联的下一层对象也会被`PURGE`。
|
||||
|
||||
示例:
|
||||
|
||||
* 从回收站中物理删除指定的数据库
|
||||
|
||||
```sql
|
||||
obclient> PURGE DATABASE object_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 从回收站中物理删除指定表
|
||||
|
||||
```sql
|
||||
obclient> PURGE TABLE object_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 从回收站中物理删除指定索引表
|
||||
|
||||
```sql
|
||||
obclient> PURGE INDEX object_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 清空整个回收站
|
||||
|
||||
```sql
|
||||
obclient> PURGE RECYCLEBIN;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
自动清理回收站
|
||||
----------------------------
|
||||
|
||||
OceanBase 数据库当前支持通过 `recyclebin_object_expire_time`` `配置项自动 `PURGE`` `回收站中过期的 Schema 对象,其默认值为 0s。其中:
|
||||
|
||||
* 值为 0s 时表示关闭自动 `PURGE `回收站功能。
|
||||
|
||||
|
||||
|
||||
* 值为非 0s 时,表示回收一段时间前进入回收站的 Schema 对象。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
开启自动`PURGE`回收站功能,并回收 7 天前进入回收站的 Schema 对象,示例语句如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET recyclebin_object_expire_time = "7d";
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,161 @@
|
||||
租户级回收站
|
||||
===========================
|
||||
|
||||
|
||||
|
||||
除了支持 `DATABASE`、`TABLE`、`INDEX` 等类型的回收站对象外,当前 OceanBase 数据库还支持租户级的回收站对象。
|
||||
|
||||
系统租户不会被执行 DROP 操作,租户级回收站的管理主要由系统租户来完成,系统租户通过执行各类回收站相关的命令来完成对租户级回收站的管理。
|
||||
|
||||
租户级的回收站对象仅可能出现在系统租户下。
|
||||
|
||||
对于租户级的回收站对象:
|
||||
|
||||
* `DROP TENANT` 是将租户名称变更为统一的回收站中的格式,租户实际占用的空间并没有释放,只是不能再向该租户建立新的连接。
|
||||
|
||||
|
||||
|
||||
* 执行 `FLASHBACK` 时,可以使用租户原始的名称,也可以使用回收站中的名称,回收站中的名称全局唯一,因此使用回收站中的名称,可以明确恢复的是哪个租户。当多个租户存在相同的原始名称时,此时恢复的租户是这些租户中最后进入回收站中的租户。
|
||||
|
||||
|
||||
|
||||
* 执行 `PURGE TENANT` 时,同样可以使用原始名称和回收站中的名称。与 `FLASHBACK` 不同,`PURGE TENANT` 时,如果多个原始名称相同,则删除的是最早进入回收站中的租户。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
查看回收站功能
|
||||
----------------------------
|
||||
|
||||
在系统租户下使用 `SHOW RECYCLEBIN` 语句,可以查看当前系统租户 Recyclebin 中的回收站功能。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> SHOW RECYCLEBIN;
|
||||
+--------------------------------+----------------+----------+----------------------------+
|
||||
| OBJECT_NAME | ORIGINAL_NAME | TYPE | CREATETIME |
|
||||
+--------------------------------+----------------+----------+----------------------------+
|
||||
| __recycle_$_1_1600136460199936 | wendo_table | TABLE | 2020-09-15 10:21:00.207886 |
|
||||
| __recycle_$_1_1600136479664128 | wendo_database | DATABASE | 2020-09-15 10:21:19.664534 |
|
||||
| __recycle_$_1_1600135793000960 | mysql | TENANT | 2020-09-15 10:23:25.773877 |
|
||||
+--------------------------------+----------------+----------+----------------------------+
|
||||
3 rows in set (0.21 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,`OBJECT_NAME` 是在回收站中的名称;`ORIGINAL_NAME` 是原始名称。
|
||||
|
||||
示例中,`mysql` 即为一个租户类型的回收站对象。
|
||||
|
||||
开启和关闭回收站
|
||||
-----------------------------
|
||||
|
||||
在系统租户下使用 `SET` 语句,可以开启和关闭系统租户的 Recyclebin 功能。
|
||||
|
||||
示例如下:
|
||||
|
||||
* 开启回收站功能
|
||||
|
||||
```sql
|
||||
obclient> SET GLOBAL recyclebin=true;
|
||||
Query OK, 0 rows affected (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 关闭回收站功能
|
||||
|
||||
```sql
|
||||
obclient> SET GLOBAL recyclebin=true;
|
||||
Query OK, 0 rows affected (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
恢复回收站对象
|
||||
----------------------------
|
||||
|
||||
当系统租户的回收站功能开启时,执行 `DROP TENANT` 操作后,相应的租户默认会进入回收站。您可以使用 `FLASHBACK` 语句将回收站内的租户恢复为正常租户。
|
||||
|
||||
示例如下:
|
||||
|
||||
* 将系统租户回收站中的 `tenant_name` 闪回为正常租户。
|
||||
|
||||
```sql
|
||||
obclient> FLASHBACK TENANT <tenant_name> TO BEFORE DROP;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 将系统租户回收站中的 `tenant_name` 闪回为正常租户,并重命名 `new_tenant_name`。
|
||||
|
||||
```sql
|
||||
obclient> FLASHBACK TENANT <tenant_name> TO BEFORE DROP RENAME TO <new_tenant_name>;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
清理回收站
|
||||
--------------------------
|
||||
|
||||
系统租户执行 Purge 操作,可以将回收站中的对象彻底删除。
|
||||
|
||||
* 将租户 `tenant_name` 从回收站中彻底清除。
|
||||
|
||||
```sql
|
||||
obclient> PURGE TENANT tenant_name;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 将回收站中的全部对象全部彻底清除。
|
||||
|
||||
```sql
|
||||
obclient> PURGE RECYCLEBIN;
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
对于主备库场景:
|
||||
* 备库中禁止自动发起 `DROP TENANT`、`DROP TENANT FORCE`、`DROP TENANT PURGE`、`FLASHBACK TENANT`、`PURGE TENANT` 等操作,所有这些操作都需要从主库中同步。
|
||||
|
||||
|
||||
|
||||
* 支持对备库执行 `PURGE RECYCLEBIN` 操作,但不支持其将回收站中的 `TENANT` 类型删除。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,123 @@
|
||||
物理备份与恢复概述
|
||||
==============================
|
||||
|
||||
|
||||
|
||||
概述
|
||||
-----------------------
|
||||
|
||||
备份恢复是 OceanBase 数据库高可用特性的核心组件,主要用于保障数据的安全,包括预防存储介质损坏和用户的错误操作等。如果存储介质损坏或者用户误操作而导致了数据丢失,可以通过恢复的方式恢复用户的数据。
|
||||
|
||||
目前 OceanBase 数据库支持 OSS、NFS 和 COS 三种备份介质,提供了备份、恢复、管理三大功能。
|
||||
|
||||
OceanBase 数据库从 V2.2.52 版本开始支持集群级别的物理备份。物理备份由基线数据、日志归档数据两种数据组成,因此物理备份由日志归档和数据备份两个功能组合而成:
|
||||
|
||||
* 日志归档是指日志数据的自动归档功能,OBServer 会定期将日志数据归档到指定的备份路径。这个动作是全自动的,不需要外部定期触发。
|
||||
|
||||
|
||||
|
||||
* 数据备份指的是备份基线数据的功能,该功能分为全量备份和增量备份两种:
|
||||
|
||||
* 全量备份是指备份所有的需要基线的宏块。
|
||||
|
||||
|
||||
|
||||
* 增量备份是指备份上一次备份以后新增和修改过的宏块。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
OceanBase 数据库支持租户级别的恢复,恢复是基于已有数据的备份重建新租户的过程。用户只需要一个 `alter system restore tenant` 命令,就可以完成整个恢复过程。恢复过程包括租户系统表和用户表的 Restore 和 Recover 过程。Restore 是将恢复需要的基线数据恢复到目标租户的 OBServer,Recover 是将基线对应的日志恢复到对应 OBServer。
|
||||
|
||||
OceanBase 数据库目前支持手动删除指定的备份和自动过期备份的功能。
|
||||
|
||||
物理备份架构
|
||||
---------------------------
|
||||
|
||||
OceanBase 数据库物理备份的架构如下图所示。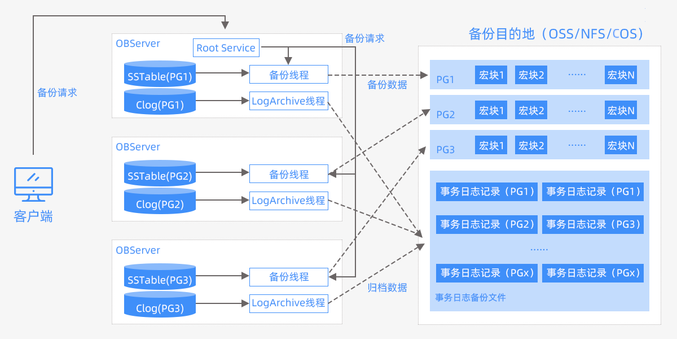当用户用系统租户登录到备份集群以后,需要先用 SQL 发起日志归档,等日志归档发起完成启动阶段以后,才可以发起基线备份。
|
||||
|
||||
日志归档是定期备份到备份目的端的,只需要用户发起一次 `alter system archivelog`,日志备份就会在后台持续进行。日志归档是由每个 PG(PartitionGroup)的 Leader 负责定期将该 PG 的日志归档到备份介质指定的路径,RS(RootService)负责定期统计日志归档的进度,并更新到内部表。
|
||||
|
||||
数据备份是需要用户触发的,比较常见的场景是周六触发一次全量备份,周二和周四触发一次增量备份。当用户发起数据备份请求时,该请求会首先被转发到 RS 所在的节点上;RS 会根据当前的租户和租户包含的 PG 生成备份数据的任务,然后把备份任务分发到 OBServer 上并行地执行备份任务;OBServer 负责备份 PG 的元信息和宏块到指定的备份目录,宏块按照 PG 为单位进行管理。
|
||||
|
||||
OceanBase 数据库目前支持使用 OSS、NFS 和 COS 三种文件系统作为备份的目的地。以下是备份功能在备份目的地创建的目录结构以及每个目录下保存的文件类型。
|
||||
|
||||
```unknow
|
||||
backup/ # 备份的根目录
|
||||
└── ob1 # cluster_name
|
||||
└── 1 # cluster_id
|
||||
└── incarnation_1 #分身 ID
|
||||
├── 1001 # 租户id
|
||||
│ ├── clog # Clog 的根目录
|
||||
│ │ ├── 1 # Clog 备份的 Round ID
|
||||
│ │ │ ├── data # 日志的数据目录
|
||||
│ │ │ └── index # 日志的索引目录
|
||||
│ │ └── tenant_clog_backup_info # 日志备份的元信息,按照 Round ID 分段记录
|
||||
│ └── data # 数据的根目录
|
||||
│ ├── backup_set_1 # 全量备份的目录
|
||||
│ │ ├── backup_1 # 差异备份的目录,第一个差异备份目录是全量的 Meta
|
||||
│ │ ├── backup_2 # 差异备份的目录。第二个差异备份的目录,Meta 也是全量备份的。
|
||||
│ │ ├── backup_set_info # 记录了 backup_set 目录内的多次差异备份的信息
|
||||
│ │ └── data #宏块数据的目录,包含了所有的全量和差异的宏块
|
||||
│ └── tenant_data_backup_info # 记录了租户全部的数据备份信息
|
||||
├── clog_info # server启动日志备份的信息
|
||||
│ └── 1_10.10.10.1_12533 # 一个 Server 一个启动日志备份信息
|
||||
├── cluster_clog_backup_info # 集群级别的日志备份信息
|
||||
├── cluster_data_backup_info # 集群级别的数据备份信息
|
||||
├── tenant_info # 租户的信息
|
||||
└── tenant_name_info #租户 Name 和 ID 的影射关系
|
||||
```
|
||||
|
||||
|
||||
|
||||
物理恢复架构
|
||||
---------------------------
|
||||
|
||||
OceanBase 数据库的物理恢复架构如下图所示。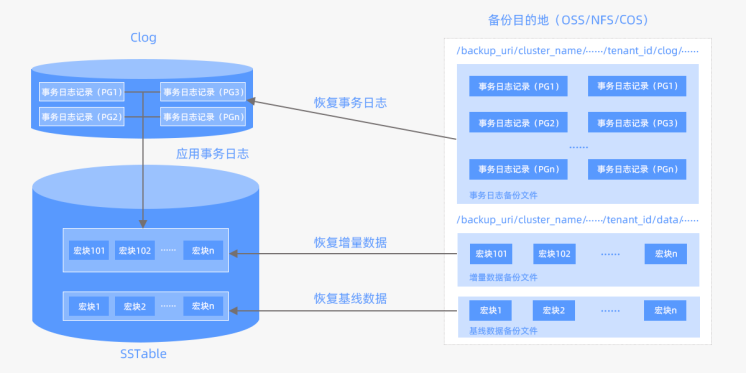对于用户可见的流程主要有两步:
|
||||
|
||||
1. 在目的集群上用 `CREATE RESOURCE POOL `命令建立恢复租户需要的资源池。
|
||||
|
||||
|
||||
|
||||
2. 通过 `ALTER SYSTEM RESTORE TENANT` 命令调度租户恢复任务。
|
||||
|
||||
对于备份恢复来说,`RESTORE TENANT` 命令的内部流程如下:
|
||||
1. 创建恢复用的租户。
|
||||
|
||||
|
||||
|
||||
2. 恢复租户的系统表数据。
|
||||
|
||||
|
||||
|
||||
3. 恢复租户的系统表日志。
|
||||
|
||||
|
||||
|
||||
4. 调整恢复租户的元信息。
|
||||
|
||||
|
||||
|
||||
5. 恢复租户的用户表数据。
|
||||
|
||||
|
||||
|
||||
6. 恢复租户的用户表日志。
|
||||
|
||||
|
||||
|
||||
7. 恢复扫尾工作。
|
||||
|
||||
对于单个 PG 来说,恢复的流程就是将 PG 的元信息和宏块数据拷贝到指定的 OBServer,构建出一个只有基线数据的 PG;然后再把 PG 的日志拷贝到指定的 OBServer,回放到该 PG 的 MemTable 中。这个流程中如果日志的量比较大,可能会触发转储操作。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,176 @@
|
||||
部署 NFS
|
||||
===========================
|
||||
|
||||
在执行备份操作前,如果需要使用 NFS 软件作为备份目的地,可参考本节内容部署 NFS。
|
||||
|
||||
背景信息
|
||||
-------------------------
|
||||
|
||||
一般建议使用 OSS 或者专用的 NFS 硬件设备,可以考虑使用阿里云的 NFS 硬件设备。
|
||||
|
||||
部署NFS 服务器端
|
||||
-------------------------------
|
||||
|
||||
1. 登录 NFS 服务器。
|
||||
|
||||
|
||||
|
||||
2. 执行以下命令,通过 YUM 包管理器安装 NFS。
|
||||
|
||||
```shell
|
||||
sudo yum install nfs-utils
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 设置 Exports。
|
||||
|
||||
1. 使用 `sudo vim /``etc/exports` 命令打开配置文件,设置以下信息:
|
||||
|
||||
```shell
|
||||
/data/nfs_server/ 100.xx.xx.xx/16(rw,sync,all_squash)
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,`100.``xx.xx.xx` 表示允许访问的网段。
|
||||
|
||||
|
||||
2. 执行以下命令,为 `nfsnobody` 赋权,确保 `nfsnobody` 有权限访问 `exports` 中指定的目录。
|
||||
|
||||
```shell
|
||||
sudo chown nfsnobody:nfsnobody -R /data/nfs_server
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
4. 配置 NFS 参数。
|
||||
|
||||
1. 执行 `sudo vim /etc/sysconfig/nfs` 命令,打开配置文件。
|
||||
|
||||
|
||||
|
||||
2. 调整如下所示参数:
|
||||
|
||||
```unknow
|
||||
RPCNFSDCOUNT=8
|
||||
RPCNFSDARGS="-N 2 -N 3 -U"
|
||||
NFSD_V4_GRACE=90
|
||||
NFSD_V4_LEASE=90
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 执行以下命令,重新启动 NFS。
|
||||
|
||||
```shell
|
||||
sudo systemctl restart nfs-config
|
||||
|
||||
sudo systemctl restart nfs-server
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
5. 设置 Slot Table。
|
||||
|
||||
1. 执行 `sudo vim /etc/sysctl.conf` 命令,打开 `sysctl.conf `配置文件,在文件中添加一行如下信息:
|
||||
|
||||
```xml
|
||||
sunrpc.tcp_max_slot_table_entries=128
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 重启机器,使配置生效。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
部署 NFS 客户端
|
||||
--------------------------------
|
||||
|
||||
部署 NFS 客户端时,需要在所有 OBServer 机器上进行操作。
|
||||
|
||||
以下以在某一台 OBServer 上的操作为例,提供操作指导。
|
||||
|
||||
1. 登录 OBServer。
|
||||
|
||||
|
||||
|
||||
2. 执行以下命令,通过 YUM 包管理器安装 NFS。
|
||||
|
||||
```shell
|
||||
sudo yum install nfs-utils
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 设置 Slot Table。
|
||||
|
||||
1. 执行 `sudo vim /etc/sysctl.conf `命令,打开` sysctl.conf` 配置文件,在文件中添加一行如下信息:
|
||||
|
||||
```xml
|
||||
sunrpc.tcp_max_slot_table_entries=128
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 重启机器,使配置生效。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
4. 执行以下命令,挂载 NFS。
|
||||
|
||||
```shell
|
||||
sudo mount -tnfs4 -o rw,timeo=30,wsize=1048576,rsize=1048576,namlen=512,sync,lookupcache=positive 100.xx.xx.xx:/data/nfs_server /data/nfs
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
* 在设置 `timeo` 时,建议不要设置的过大。
|
||||
|
||||
|
||||
|
||||
* 命令中`100.xx.xx.xx`表示 NFS 服务器的 IP 地址。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
5. 挂载完成后,可执行以下命令,验证 NFS 的性能。
|
||||
|
||||
```shell
|
||||
fio -filename=/data/nfs/fio_test -direct=1 -rw=randwrite -bs=2048K -size=100G -runtime=300 -group_reporting -name=mytest -ioengine=libaio -numjobs=1 -iodepth=64 -iodepth_batch=8 -iodepth_low=8 -iodepth_batch_complete=8
|
||||
```
|
||||
|
||||
|
||||
|
||||
例如,执行结果如下:
|
||||
|
||||
```shell
|
||||
Run status group 0 (all jobs):
|
||||
WRITE: io=322240MB, aggrb=1074.2MB/s, minb=1074.2MB/s, maxb=1074.2MB/s, mint=300006msec, maxt=300006msec
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,269 @@
|
||||
通过命令行备份
|
||||
============================
|
||||
|
||||
本节主要介绍如何使用 OceanBase 数据库的备份功能进行备份。
|
||||
|
||||
备份前准备
|
||||
--------------------------
|
||||
|
||||
1. 使用 sys 租户的 root 用户登录数据库。
|
||||
|
||||
|
||||
|
||||
2. 根据业务需要,配置 backup_region 配置项。
|
||||
|
||||
该配置项用于控制数据备份的 Region。配置后,系统会优先执行指定 Region 的调度备份任务;如果不配置,则会执行所有 Region 的调度备份任务。
|
||||
|
||||
|
||||
3. 配置备份目的地。
|
||||
|
||||
在进行备份前,需要执行 `ALTER SYSTEM` 语句配置备份的目的地。目前,OceanBase 数据库支持 NFS 、 OSS 文件系统和腾讯云 COS 作为备份目的地 。
|
||||
|
||||
例如:
|
||||
* NFS
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_dest='file:///data/nfs/backup';
|
||||
```
|
||||
|
||||
|
||||
|
||||
* OSS
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_dest='oss://antsys-oceanbasebackup/backup_rd/?host=cn-hangzhou-alipay-b.oss-cdn.aliyun-inc.com&access_id=xxx&access_key=xxx';
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 腾讯云 COS
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_dest='cos://backup-1304745170/backup_rd/20210127?host=cos.ap-nanjing.myqcloud.com&access_id=xxx&access_key=xxx&appid=xxx';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
4. (可选)开启归档日志压缩功能。
|
||||
|
||||
执行以下语句开启归档日志压缩,默认使用压缩算法 lz4_1.0。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_log_archive_option='compression= enable';
|
||||
```
|
||||
|
||||
|
||||
|
||||
日志压缩支持动态修改压缩算法,目前支持的压缩算法有:zstd_1.3.8 和 lz4_1.0。如果需要使用其他压缩算法,则可以执行以下命令:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_log_archive_option='compression= zstd_1.3.8';
|
||||
|
||||
obclient> ALTER SYSTEM SET backup_log_archive_option='compression= lz4_1.0';
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
开启后,后续如果需要关闭归档日志压缩功能,可执行 `ALTER SYSTEM SET backup_log_archive_option='compression= disable'; `语句关闭。
|
||||
|
||||
|
||||
5. (可选)配置备份模式。
|
||||
|
||||
备份支持 optional 模式和 mandatory 模式:
|
||||
* optional 模式表示以用户业务优先。在该模式下,当备份(日志归档)来不及的情况下,日志可能来不及备份就回收了,可能会发生备份断流。
|
||||
|
||||
|
||||
|
||||
* mandatory 模式表示以备份优先。在该模式下如果备份跟不上用户数据的写入,可能会导致用户无法写入。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
默认为 optional 模式,两种模式之间可以切换。切换配置模式的示例命令如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_log_archive_option = 'optional';
|
||||
|
||||
obclient> ALTER SYSTEM SET backup_log_archive_option = 'mandatory';
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
您也可以使用 `ALTER SYSTEM SET backup_log_archive_option = 'optional compression= enable'; `命令同时配置备份模式并开启归档日志压缩功能。
|
||||
|
||||
|
||||
6. 执行以下语句,启动 OceanBase 数据库的归档功能。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM ARCHIVELOG;
|
||||
```
|
||||
|
||||
|
||||
|
||||
启动成功后,OceanBase 数据库会自动将集群产生的事务日志定期备份到之前指定的备份目的地。
|
||||
|
||||
|
||||
7. 执行以下语句,确认日志备份任务是否已开始。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_ARCHIVELOG_SUMMARY;
|
||||
```
|
||||
|
||||
|
||||
|
||||
当 `STATUS`为 `DOING`时,表示日志备份任务已开始。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
全量备份
|
||||
-------------------------
|
||||
|
||||
1. 使用 sys 租户的 root 用户登录数据库。
|
||||
|
||||
|
||||
|
||||
2. 在执行全量备份前,执行以下语句,对集群进行一次合并。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM MAJOR FREEZE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 执行以下语句,查看合并进度。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_zone WHERE name='merge_status';
|
||||
```
|
||||
|
||||
|
||||
|
||||
结果如下所示:
|
||||
|
||||
```sql
|
||||
+----------------------------+----------------------------+-------+--------------+-------+------+
|
||||
| gmt_create | gmt_modified | zone | name | value | info |
|
||||
+----------------------------+----------------------------+-------+--------------+-------+------+
|
||||
| 2020-05-26 17:50:11.107352 | 2020-05-26 17:50:45.871523 | | merge_status | 0 | IDLE |
|
||||
| 2020-05-26 17:50::11.109678 | 2020-05-26 17:50:55.780264 | zone1 | merge_status | 0 | IDLE |
|
||||
+----------------------------+----------------------------+-------+--------------+-------+------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
当 `info`为 `IDLE`时,则表示合并结束。
|
||||
|
||||
|
||||
4. 执行以下语句,进行集群的全量备份。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM BACKUP DATABASE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
备份过程中,您可以通过执行以下语句,在视图中查看备份任务的状态和详细信息:
|
||||
* 查看正在备份的任务
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_PROGRESS;
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例结果如下:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_PROGRESS;
|
||||
+-------------+--------+-------------+-----------+-----------------+-------------------+------------------------+--------------------------+-------------+--------------+----------------------------+----------------------------+---------+
|
||||
| INCARNATION | BS_KEY | BACKUP_TYPE | TENANT_ID | PARTITION_COUNT | MACRO_BLOCK_COUNT | FINISH_PARTITION_COUNT | FINISH_MACRO_BLOCK_COUNT | INPUT_BYTES | OUTPUT_BYTES | START_TIME | COMPLETION_TIME | STATUS |
|
||||
+-------------+--------+-------------+-----------+-----------------+-------------------+------------------------+--------------------------+-------------+--------------+----------------------------+----------------------------+---------+
|
||||
| 1 | 3 | I | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2020-09-16 11:51:21.743752 | 2020-09-16 11:51:22.624217 | RUNNING |
|
||||
| 1 | 3 | I | 1001 | 119 | 0 | 0 | 0 | 0 | 0 | 2020-09-16 11:51:21.743752 | 2020-09-16 11:51:22.281717 | RUNNING |
|
||||
| 1 | 3 | I | 1002 | 5317 | 0 | 0 | 0 | 0 | 0 | 2020-09-16 11:51:21.743752 | 2020-09-16 11:51:22.064521 | RUNNING |
|
||||
+-------------+--------+-------------+-----------+-----------------+-------------------+------------------------+--------------------------+-------------+--------------+----------------------------+----------------------------+---------+
|
||||
3 rows in set (0.01 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 查看备份任务的历史
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_SET_DETAILS;
|
||||
```
|
||||
|
||||
|
||||
|
||||
示例结果如下:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_SET_DETAILS;
|
||||
+-------------+-----------+--------+-------------+-----------------+----------------------------+----------------------------+------------------+------+------------+-------------+------------+--------------+-------------------+-------------------+----------------------+---------------------------+--------------------+
|
||||
| INCARNATION | TENANT_ID | BS_KEY | BACKUP_TYPE | ENCRYPTION_MODE | START_TIME | COMPLETION_TIME | ELAPSED_SECONDES | KEEP | KEEP_UNTIL | DEVICE_TYPE | COMPRESSED | OUTPUT_BYTES | OUTPUT_RATE_BYTES | COMPRESSION_RATIO | OUTPUT_BYTES_DISPLAY | OUTPUT_RATE_BYTES_DISPLAY | TIME_TAKEN_DISPLAY |
|
||||
+-------------+-----------+--------+-------------+-----------------+----------------------------+----------------------------+------------------+------+------------+-------------+------------+--------------+-------------------+-------------------+----------------------+---------------------------+--------------------+
|
||||
| 1 | 1 | 2 | D | NONE | 2020-09-16 08:12:15.982675 | 2020-09-16 08:17:19.874385 | 0 | NO | | FILE | NO | 0 | 0.0000 | NULL | 0.00MB | 0.00MB/S | 00:05:03.891710 |
|
||||
| 1 | 1 | 3 | I | NONE | 2020-09-16 11:51:21.743752 | 2020-09-16 12:00:06.640995 | 0 | NO | | FILE | NO | 0 | 0.0000 | NULL | 0.00MB | 0.00MB/S | 00:08:44.897243 |
|
||||
| 1 | 1001 | 2 | D | NONE | 2020-09-16 08:12:15.982675 | 2020-09-16 08:12:22.288826 | 0 | NO | | FILE | NO | 0 | 0.0000 | NULL | 0.00MB | 0.00MB/S | 00:00:06.306151 |
|
||||
| 1 | 1001 | 3 | I | NONE | 2020-09-16 11:51:21.743752 | 2020-09-16 11:51:34.535564 | 0 | NO | | FILE | NO | 0 | 0.0000 | NULL | 0.00MB | 0.00MB/S | 00:00:12.791812 |
|
||||
| 1 | 1002 | 2 | D | NONE | 2020-09-16 08:12:15.982675 | 2020-09-16 08:17:18.426037 | 0 | NO | | FILE | NO | 0 | 0.0000 | NULL | 0.00MB | 0.00MB/S | 00:05:02.443362 |
|
||||
| 1 | 1002 | 3 | I | NONE | 2020-09-16 11:51:21.743752 | 2020-09-16 12:00:05.837062 | 0 | NO | | FILE | NO | 0 | 0.0000 | NULL | 0.00MB | 0.00MB/S | 00:08:44.093310 |
|
||||
+-------------+-----------+--------+-------------+-----------------+----------------------------+----------------------------+------------------+------+------------+-------------+------------+--------------+-------------------+-------------------+----------------------+---------------------------+--------------------+
|
||||
6 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
|
||||
|
||||
`CDB_OB_BACKUP_SET_DETAILS` 中,部分字段的说明如下表所示。
|
||||
|
||||
|
||||
| 字段 | 说明 |
|
||||
|---------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| OUTPUT_BYTES | 表示写在外部存储介质的数据量,单位为 Bytes |
|
||||
| OUTPUT_RATE_BYTES | 表示 1 秒内上传的数据量,单位为 Bytes |
|
||||
| COMPRESSION_RATIO | 表示压缩比例,计算公式:`COMPRESSION_RATIO = OUTPUT_BYTES / INPUT_BYTES` 其中,`INPUT_BYTES` 是 OBServer 本次需要备份的数据的大小,故可以通过 `COMPRESSION_RATIO` 的值计算出 INPUT_BYTES 的值,即 `INPUT_BYTES = OUTPUT_BYTES / COMPRESSION_RATIO` |
|
||||
| OUTPUT_BYTES_DISPLAY | 对于 `OUTPUT_BYTES` 单位转换之后的展示,单位为 MB 、GB、TB 和 PB 中的一种 |
|
||||
| OUTPUT_RATE_BYTES_DISPLAY | 对于 `OUTPUT_RATE_BYTES` 单位转换之后的展示,单位为 MB 、GB、TB 和 PB 中的一种 |
|
||||
| TIME_TAKEN_DISPLAY | 以 `TIMESTAMP` 的方式展示 COMPLETION_TIME - START_TIME |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
增量备份
|
||||
-------------------------
|
||||
|
||||
增量备份是从上一个全量备份开始,备份所有修改过的宏块。建议在执行增量备份前确保已经有全量备份存在。
|
||||
|
||||
1. 使用 sys 租户的 root 用户登录数据库。
|
||||
|
||||
|
||||
|
||||
2. 执行以下语句,启动增量备份。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM BACKUP INCREMENTAL DATABASE;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
查看备份进度
|
||||
===========================
|
||||
|
||||
执行备份后,您可以查看备份进度。
|
||||
|
||||
查看数据备份进度以及备份任务历史
|
||||
-------------------------------------
|
||||
|
||||
1. 使用 `root` 用户登录数据库的 `sys` 租户。
|
||||
|
||||
|
||||
|
||||
2. 进入 `oceanbase` 数据库。
|
||||
|
||||
```sql
|
||||
obclient> use oceanbase;
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 进行以下操作:
|
||||
|
||||
* 查看备份进度
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_PROGRESS;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 查看备份历史
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM CDB_OB_BACKUP_SET_DETAILS;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
查看分区的备份进度
|
||||
------------------------------
|
||||
|
||||
1. 使用 `root` 用户登录数据库的 `sys` 租户。
|
||||
|
||||
|
||||
|
||||
2. 进入 `oceanbase` 数据库。
|
||||
|
||||
```sql
|
||||
obclient> use oceanbase;
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 执行以下语句,查看分区的备份进度。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_virtual_pg_backup_log_archive_status WHERE table_id=xxx AND partition_id = xxx;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,30 @@
|
||||
停止备份
|
||||
=========================
|
||||
|
||||
本节主要介绍如何停止正在运行的备份任务。
|
||||
|
||||
您可以使用以下语句,终止正在运行的数据库备份任务和日志备份任务。
|
||||
|
||||
* 停止数据库备份任务
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM CANCEL BACKUP;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 停止日志备份任务
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM NOARCHIVELOG;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,12 @@
|
||||
删除过期的备份
|
||||
============================
|
||||
|
||||
本节主要介绍如何手动删除过期的备份。
|
||||
|
||||
如果您设置了自动删除过期备份参数`auto_delete_expired_backup=true`,则备份恢复功能会根据 recovery_window 的设置判断备份集是否过期,并自动删除过期的备份。或者,您也可以使用下面的命令删除备份集。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM DELETE BACKUPSET backupset_id;
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,151 @@
|
||||
清理备份数据
|
||||
===========================
|
||||
|
||||
数据备份成功后,您可以根据业务需要,参考本节选择合适的操作进行备份数据的清理。
|
||||
|
||||
当前 OceanBase 数据库提供了以下三种方式清理备份数据:
|
||||
|
||||
* 指定某一个备份的 `backup_set_id` 进行清理
|
||||
|
||||
|
||||
|
||||
* 手动触发过期数据的清理
|
||||
|
||||
|
||||
|
||||
* 自动进行过期数据的清理
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
清理指定备份
|
||||
---------------------------
|
||||
|
||||
1. 查询 `CDB_BACKUP_SET_DETAILS` 表,找到待删除的备份数据的 `backup_set_id`。
|
||||
|
||||
`CDB_BACKUP_SET_DETAILS` 表展示了历史上备份的 `backup_set` 信息,包括 `backup_set_id` 和 `status`。
|
||||
|
||||
其中,`status` 对应的状态目前有三种:
|
||||
* `COMPELETED`:表示备份数据清理完成
|
||||
|
||||
|
||||
|
||||
* `FAILED`:表示备份数据清理失败
|
||||
|
||||
|
||||
|
||||
* `DELETING`:表示某个 `backup_set_id` 的备份数据正在删除
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
2. 执行以下命令,清理备份数据。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM DELETE BACKUPSET backup_set_id;
|
||||
```
|
||||
|
||||
|
||||
|
||||
例如,执行以下命令,表示删除 `backup_set_id` 为 `1` 的备份数据。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM DELETE BACKUPSET 1;
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果出现了 `9044` 的报错,则表示数据清理任务已开始,不允许再次发起清理任务。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
手动清理过期数据
|
||||
-----------------------------
|
||||
|
||||
1. 根据以下命令,设置备份数据的过期时间。
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET backup_recovery_window = <过期时间>;
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,`backup_recovery_window` 是一个配置项,用于表示成功备份的数据可以提供恢复的时间窗口,默认值为 `0`,表示永久保留;建议设置为 `'7d'`,表示备份数据保留一周后过期。对于手动清理的场景,备份数据过期后,您可以手动清理过期的备份数据。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_recovery_window = '7d';
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 执行以下命令,立即清理过期的备份数据。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET DELETE OBSOLETE;
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果出现了 `9044` 的报错,则表示数据清理任务已开始,不允许再次发起清理任务。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
自动清理过期数据
|
||||
-----------------------------
|
||||
|
||||
**方法一** :通过配置项开启自动清理功能
|
||||
|
||||
1. 根据以下命令,设置备份数据的过期时间。
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET backup_recovery_window = <过期时间>;
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,`backup_recovery_window` 是一个配置项,用于表示成功备份的数据可以提供恢复的时间窗口,默认值为 `0`,表示永久保留;建议设置为 `'7d'`,表示备份数据保留一周后过期。对于自动清理场景,备份数据过期后系统会自动清理备份的数据。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET backup_recovery_window = '7d';
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 执行以下命令,开启备份数据的自动清理功能。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET auto_delete_expired_backup = 'True';
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果出现了 `9044` 的报错,则表示数据清理任务已开始,不允许再次发起清理任务。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**方法二** :通过 OCP 开启自动过期备份清理开关
|
||||
|
||||
在 OCP 上创建备份策略时,您可以开启 **过期备份清理调度配置** 开关,待备份数据过期后系统会自动清理过期的数据。
|
||||
@ -0,0 +1,39 @@
|
||||
取消清理备份数据
|
||||
=============================
|
||||
|
||||
备份数据的清理任务开始执行后,您可以根据清理场景选择合适的方式来取消清理。
|
||||
|
||||
手动清理场景
|
||||
---------------------------
|
||||
|
||||
对于手动清理场景,只需要执行以下命令,即可取消正在执行的清理任务。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM CANCEL DELETE BACKUP;
|
||||
```
|
||||
|
||||
|
||||
|
||||
自动清理场景
|
||||
---------------------------
|
||||
|
||||
对于自动清理场景,为了防止取消清理的任务被再次调度执行,需要先关闭自动清理备份数据功能后,再取消正在执行的清理任务。
|
||||
|
||||
1. 执行以下命令,关闭自动清理备份数据功能。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET auto_delete_expired_backup = 'False';
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 执行以下命令,取消正在执行的清理任务。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM CANCEL DELETE BACKUP;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,313 @@
|
||||
执行恢复
|
||||
=========================
|
||||
|
||||
本节主要介绍如何通过命令和 OCP 的方式进行物理恢复,目前 OceanBase 数据库支持租户级别的基于时间点的恢复。
|
||||
|
||||
通过命令进行恢复
|
||||
-----------------------------
|
||||
|
||||
恢复会先根据用户输入的命令,从备份的目的地将全量备份恢复回来。之后,再将增量备份恢复到全量备份上面。最后,应用备份出去的事务日志。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
本节中的操作需要使用 root 用户在 sys 租户上执行。
|
||||
|
||||
1. 执行以下语句,停止日志备份。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM NOARCHIVELOG;
|
||||
```
|
||||
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
由于当前版本暂不支持日志备份在集群上发起恢复,如果发起恢复,则会导致日志备份断流,故建议在执行恢复前先停止日志备份。
|
||||
|
||||
|
||||
2. 创建 Unit(资源单元)。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE RESOURCE UNIT box_16c96g max_cpu 16, max_memory 103079215104, max_iops 10240, max_disk_size 53687091200, max_session_num 64, MIN_CPU=16, MIN_MEMORY=103079215104, MIN_IOPS=10240;
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. 创建 Resource Pool(资源池)。
|
||||
|
||||
示例如下:
|
||||
|
||||
```sql
|
||||
obclient> CREATE RESOURCE POOL restore_pool unit = 'box_16c96g', unit_num = 1, zone_list = ('z1','z2','z3');
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. 执行以下语句,设置加密信息。
|
||||
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
如果未加密或恢复时可以访问原来的 KMS,则跳过本步骤。
|
||||
|
||||
```sql
|
||||
obclient> SET @kms_encrypt_info = '<加密string>';
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,`<加密string>` 为 `EXTERNAL_KMS_INFO` 的值,`EXTERNAL_KMS_INFO` 为租户级配置项。
|
||||
|
||||
|
||||
5. 打开恢复配置。
|
||||
|
||||
检查 `restore_concurrency` 是否为 `0`,如果为 `0` ,则需要执行以下语句:
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET restore_concurrency = 50;
|
||||
```
|
||||
|
||||
|
||||
|
||||
6. (可选)修改恢复的等待时间。
|
||||
|
||||
默认恢复等待时间 `_restore_idle_time` 为 1 分钟,整个恢复期间会有 3 次等待,即 3 分钟的等待时间。对于测试恢复性能的场景,为了减少恢复的空闲时间,您可以执行以下语句将等待时间调整为 `10s`。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM SET _restore_idle_time = '10s';
|
||||
```
|
||||
|
||||
|
||||
|
||||
7. 根据现场需要,设置恢复的密码。
|
||||
|
||||
```sql
|
||||
obclient> SET DECRYPTION IDENTIFIED BY 'password';
|
||||
```
|
||||
|
||||
|
||||
|
||||
只有在备份时添加了密码的场景下才需要设置恢复的密码。同时如果全量备份+增量备份设置的密码不一样,则需要输入多个密码,密码之间使用逗号分隔。示例如下:
|
||||
|
||||
```sql
|
||||
obclient> SET DECRYPTION IDENTIFIED BY 'password1','password2';
|
||||
```
|
||||
|
||||
|
||||
|
||||
8. 执行以下语句,开始执行恢复任务。
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM RESTORE <dest_tenantname> FROM <source_tenantname> at 'uri' UNTIL 'timestamp' WITH 'restore_option';
|
||||
```
|
||||
|
||||
|
||||
|
||||
部分参数说明如下表所示。
|
||||
|
||||
|
||||
| 参数 | 描述 |
|
||||
|-------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| dest_tenantname | 指恢复的新租户的名称。 |
|
||||
| source_tenantname | 指原集群的租户。 |
|
||||
| uri | 指备份时设置的 `backup_dest`。 |
|
||||
| timestamp | 指恢复的时间戳,需要大于等于最早备份的数据备份的 `CDB_OB_BACKUP_SET_DETAILS `的`START_TIME`,小于等于日志备份 `CDB_OB_BACKUP_ARCHIVELOG_SUMMARY` 的 `MAX_NEXT_TIME`。 |
|
||||
| restore_option | 支持 `backup_cluster_name`、`backup_cluster_id`、`pool_list`、`locality`、`kms_encrypt`: * `backup_cluster_name` 为必选项,填写源集群的名称。 * `backup_cluster_id` 为必选项,填写源集群的 `cluster_id`。 * `pool_list` 为必选项,填写用户的资源池。 * `locality` 为可选项,填写租户的 Locality 信息。 * `kms_encrypt` 为可选项,为 `true` 则表示在恢复时需要使用步骤 4 指定的 `kms_encrypt_info`。 |
|
||||
|
||||
|
||||
|
||||
恢复示例:
|
||||
* NFS
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM RESTORE restored_trade FROM trade at 'file:///data/nfs/backup' until '2020-05-21 09:39:54.071670' with 'backup_cluster_name=ob20daily.backup&backup_cluster_id=1&pool_list=restore_pool;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* OSS
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM RESTORE restored_trade FROM trade at 'oss://antsys-oceanbasebackup/backup_rd/?host=cn-hangzhou-alipay-b.oss-cdn.aliyun-inc.com&access_id=xxx&access_key=xxx' until ' 2020-03-23 08:59:45' with 'backup_cluster_name=ob20daily.backup&backup_cluster_id=1&pool_list=restore_pool';
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 腾讯云 COS
|
||||
|
||||
```sql
|
||||
obclient> ALTER SYSTEM RESTORE restored_trade from trade at 'cos://backup-1304745170/backup_rd/20210127?host=cos.ap-nanjing.myqcloud.com&access_id=xxx&access_key=xxx&appid=xxx' until ' 2020-03-23 08:59:45' with 'backup_cluster_name=ob20daily.backup&backup_cluster_id=1&pool_list=restore_pool';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
9. 执行以下语句,查看恢复进度。
|
||||
|
||||
* 查看系统表 Root Table:
|
||||
|
||||
```sql
|
||||
obclient> SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_root_table AS a, (SELECT value FROM __all_restore_info WHERE name='tenant_id') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore;
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中,`is_restore` 的取值含义如下:
|
||||
* 0:表示正常副本
|
||||
|
||||
|
||||
|
||||
* 1:表示逻辑恢复的副本
|
||||
|
||||
|
||||
|
||||
* 2:表示物理恢复需要恢复基线的副本
|
||||
|
||||
|
||||
|
||||
* 3:表示物理恢复需要恢复转储的副本
|
||||
|
||||
|
||||
|
||||
* 4:物理恢复需要恢复 clog 的副本
|
||||
|
||||
|
||||
|
||||
* 5:物理恢复需要转储的副本
|
||||
|
||||
|
||||
|
||||
* 6:物理恢复等待所有副本转储完成的副本
|
||||
|
||||
|
||||
|
||||
* 7:物理恢复设置 member list 的副本
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
`role` 的取值含义如下:
|
||||
* 1:表示 Leader
|
||||
|
||||
|
||||
|
||||
* 2:表示 Follower
|
||||
|
||||
|
||||
|
||||
* 3:表示恢复中的 Leader
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 查看用户表 Meta Table:
|
||||
|
||||
```sql
|
||||
obclient> SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_virtual_meta_table AS a, (SELECT value FROM __all_restore_info WHERE name='tenant_id') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore;
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者
|
||||
|
||||
```sql
|
||||
obclient> SELECT svr_ip ,is_restore, COUNT(*) FROM __all_virtual_partition_store_info WHERE tenant_id>1002 group by svr_ip,is_restore order by svr_ip, is_restore;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
10. 执行以下语句,查看恢复结果。
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_restore_info;
|
||||
```
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_restore_history;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 进行恢复
|
||||
--------------------------------
|
||||
|
||||
您也可以在 OCP 上对已备份的集群发起恢复操作。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏上,单击 **备份恢复** \> **恢复** 。
|
||||
|
||||
|
||||
|
||||
3. 在页面右上角单击 **发起恢复** 。
|
||||
|
||||
|
||||
|
||||
4. 设置存储配置。
|
||||
|
||||
存储配置相关说明如下表所示。
|
||||
|
||||
|
||||
| 配置 | 描述 |
|
||||
|--------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **存储类型** | 支持 **OSS** 和 **File** 两种类型 |
|
||||
| **存储目录** | 存储目录: * **存储类型** 为 **OSS** 时,示例如下: ```html oss://antsys-oceanbasebackup/backup_rd/ ``` * **存储类型** 为 **File** 时,示例如下: ```html file:///data/nfs/backup ``` |
|
||||
| **访问域名** 、 **访问用户** 、 **访问秘钥** | 如果选择的 **存储类型** 为 **OSS** ,则需要输入访问域名、访问用户和访问密钥后,然后单击 **测试** ,确认可访问。 |
|
||||
|
||||
|
||||
|
||||
如果已经有可用的配置,可以直接在 **存储配置** 区域的右上角单击 **选择已有配置** ,并选择对应的配置后,系统会自动解析存储配置。
|
||||
|
||||
|
||||
5. 选择 **恢复源与时间** 。
|
||||
|
||||
在列表中选择 **源集群** **、** **源租户** 和 **恢复的时间点** 。
|
||||
|
||||
|
||||
|
||||
|
||||
6. 选择恢复的目标租户。
|
||||
|
||||
在列表中选择运行状态的集群,并在 **租户名称** 文本框中输入新的租户名称。
|
||||
|
||||
|
||||
|
||||
|
||||
7. 对恢复的租户进行 Zone 配置,选择 **副本类型** **、** **Unit 规格** 和 **Unit 数量** ,并对 Zone 进行优先级排序。
|
||||
|
||||
|
||||
|
||||
8. 单击 **发起恢复** 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
查看恢复进度和结果
|
||||
==============================
|
||||
|
||||
执行恢复后,可以通过数据库表或 OCP 来查看恢复进度和结果。
|
||||
|
||||
通过数据库表查看恢复进度和结果
|
||||
------------------------------------
|
||||
|
||||
1. 执行恢复操作后,您可以通过以下方式查看恢复进度:
|
||||
|
||||
* 查看系统表的恢复进度
|
||||
|
||||
```sql
|
||||
obclient> SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_root_table as a, (SELECT value FROM __all_restore_info WHERE name='<目标租户名>') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 查看用户表的恢复进度
|
||||
|
||||
```sql
|
||||
obclient> SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_virtual_meta_table AS a, (SELECT value FROM __all_restore_info WHERE name='<目标租户名>') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore;
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者
|
||||
|
||||
```sql
|
||||
obclient> SELECT svr_ip, is_restore, COUNT(*) FROM __all_virtual_partition_store_info WHERE tenant_id=<目标租户id> GROUP BY svr_ip,is_restore ORDER BY svr_ip, is_restore;
|
||||
```
|
||||
|
||||
|
||||
|
||||
其中:
|
||||
* `is_restore` 列显示了一个分区在恢复中所处的状态,当该列值为 `0`时表示这个分区的数据已经完成了恢复。
|
||||
|
||||
|
||||
|
||||
* `role` 列表示被恢复的副本的角色:
|
||||
|
||||
* 1:表示 Leader
|
||||
|
||||
|
||||
|
||||
* 2:表示 Follower
|
||||
|
||||
|
||||
|
||||
* 3:表示恢复中的 Leader
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
2. 待恢复完成后,您可以执行以下语句,查看集群的恢复任务结果和恢复历史:
|
||||
|
||||
* 查看恢复任务结果
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_restore_info;
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 查看恢复历史
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_restore_history;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
通过 OCP 查看恢复进度及结果
|
||||
-------------------------------------
|
||||
|
||||
执行恢复操作后,也可以通过 OCP 来查看恢复进度和结果。
|
||||
**说明**
|
||||
|
||||
|
||||
|
||||
不同 OCP 版本的操作界面可能不同,本节以 OCP V2.5.0 版本为例提供操作指导,OCP 其他版本的操作请参考对应版本的《OCP 用户指南》文档。
|
||||
|
||||
1. 登录 OCP。
|
||||
|
||||
|
||||
|
||||
2. 在左侧导航栏上,单击 **备份恢复** \> **恢复** 。
|
||||
|
||||
|
||||
|
||||
3. 在 **恢复任务** 页签中,查看恢复任务的进度及结果。
|
||||
|
||||
可查看恢复任务的 **ID** **、** **备份集群** **、** **备份方式** **、** **目标集群** **、** **目标租户** **、** **恢复时间** 、 **存储目录** **、** **开始时间** **、** **结束时间** 和 **状态** 。
|
||||
|
||||
如果有失败的恢复任务,可在对应的 **操作** 列后单击 **查看原因** ,查看恢复任务不成功的原因。
|
||||
|
||||
还可以通过右上方的时间选项 **近 24 小时** **、** **近 7 天** **、** **近 30 天** 或 **自定义** 时间来筛选符合条件的恢复任务。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,88 @@
|
||||
备份相关
|
||||
=========================
|
||||
|
||||
执行备份操作后,您可以登录 sys 租户,查看备份相关的信息。
|
||||
|
||||
查看备份文件
|
||||
---------------------------
|
||||
|
||||
通过以下视图,查看已经执行的备份操作:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM oceanbase.CDB_OB_BACKUP_SET_DETAILS;
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过以下语句,查看根据现有的 Recovery Window 计算出的过期备份:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM oceanbase.CDB_OB_BACKUP_SET_EXPIRED;
|
||||
```
|
||||
|
||||
|
||||
|
||||
查看备份的配置信息
|
||||
------------------------------
|
||||
|
||||
您可以通过以下语句,获取与备份恢复相关的配置参数信息。
|
||||
|
||||
* 获取备份目的地
|
||||
|
||||
```sql
|
||||
obclient> SHOW PARAMETERS LIKE '%backup_dest%';
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -->
|
||||
|
||||
* 获取备份的恢复窗口
|
||||
|
||||
```sql
|
||||
obclient> SHOW PARAMETERS LIKE '%recovery_window%';
|
||||
```
|
||||
|
||||
|
||||
|
||||
恢复的窗口期可设置为 xd,表示 x 天。例如,如果该参数设置为 7d,则表示 OceanBase 数据库会保存相应的集群全备、增量备份 、事务日志备份,以确保集群可以被恢复到从当前时间开始计算的 7 天之内的任意时间点。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
查看与备份相关的 RootService 事件
|
||||
--------------------------------------------
|
||||
|
||||
执行以下命令:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM oceanbase.__all_rootservice_event_history WHERE module LIKE '%backup' OR module LIKE '%archive%' ORDER BY gmt_create DESC LIMIT 30;
|
||||
```
|
||||
|
||||
|
||||
|
||||
查看单个 OBServer 上所有分区归档落后的日志总条数
|
||||
--------------------------------------------------
|
||||
|
||||
执行以下命令:
|
||||
|
||||
```sql
|
||||
obclient> SELECT sum(max_log_id-log_archive_cur_log_id) FROM __all_virtual_pg_backup_log_archive_status WHERE svr_ip="" AND svr_port=xxx;
|
||||
```
|
||||
|
||||
|
||||
|
||||
查看单个 PG 的备份情况
|
||||
----------------------------------
|
||||
|
||||
执行以下命令:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM __all_rootservice_event_history WHERE event LIKE '%backup%' AND value1 LIKE '%1100611139404014%';
|
||||
```
|
||||
|
||||
|
||||
Reference in New Issue
Block a user