[refactor][doc] Added documentation for advanced usage section (#8826)
1.Materialized view 2.Schema Change 3.Dynamic Partition 4.Bucket Shuffle Join 5.Colocation Join 6.Runtime Filter 7.partition cache 8.Orthogonal BITMAP calculation 9.Variable 10.Time zone 11.File Manager
This commit is contained in:
@ -166,14 +166,12 @@ module.exports = [
|
||||
directoryPath: "cache/",
|
||||
initialOpenGroupIndex: -1,
|
||||
children: [
|
||||
"partition-cache",
|
||||
"query-cache"
|
||||
"partition-cache"
|
||||
],
|
||||
},
|
||||
"broker",
|
||||
"resource",
|
||||
"orthogonal-bitmap-manual",
|
||||
"orthogonal-hll-manual",
|
||||
"variables",
|
||||
"time-zone",
|
||||
"small-file-mgr"
|
||||
|
||||
@ -166,14 +166,12 @@ module.exports = [
|
||||
directoryPath: "cache/",
|
||||
initialOpenGroupIndex: -1,
|
||||
children: [
|
||||
"partition-cache",
|
||||
"query-cache"
|
||||
"partition-cache"
|
||||
],
|
||||
},
|
||||
"broker",
|
||||
"resource",
|
||||
"orthogonal-bitmap-manual",
|
||||
"orthogonal-hll-manual",
|
||||
"variables",
|
||||
"time-zone",
|
||||
"small-file-mgr"
|
||||
|
||||
@ -25,3 +25,466 @@ under the License.
|
||||
-->
|
||||
|
||||
# Materialized view
|
||||
A materialized view is a data set that is pre-calculated (according to a defined SELECT statement) and stored in a special table in Doris.
|
||||
|
||||
The emergence of materialized views is mainly to satisfy users. It can analyze any dimension of the original detailed data, but also can quickly analyze and query fixed dimensions.
|
||||
|
||||
## When to use materialized view
|
||||
|
||||
+ Analyze requirements to cover both detailed data query and fixed-dimensional query.
|
||||
+ The query only involves a small part of the columns or rows in the table.
|
||||
+ The query contains some time-consuming processing operations, such as long-time aggregation operations.
|
||||
+ The query needs to match different prefix indexes.
|
||||
|
||||
## Advantage
|
||||
|
||||
+ For those queries that frequently use the same sub-query results repeatedly, the performance is greatly improved
|
||||
+ Doris automatically maintains the data of the materialized view, whether it is a new import or delete operation, it can ensure the data consistency of the base table and the materialized view table. No need for any additional labor maintenance costs.
|
||||
+ When querying, it will automatically match the optimal materialized view and read data directly from the materialized view.
|
||||
|
||||
*Automatic maintenance of materialized view data will cause some maintenance overhead, which will be explained in the limitations of materialized views later.*
|
||||
|
||||
## Materialized View VS Rollup
|
||||
|
||||
Before the materialized view function, users generally used the Rollup function to improve query efficiency through pre-aggregation. However, Rollup has certain limitations. It cannot do pre-aggregation based on the detailed model.
|
||||
|
||||
Materialized views cover the functions of Rollup while also supporting richer aggregate functions. So the materialized view is actually a superset of Rollup.
|
||||
|
||||
In other words, the functions previously supported by the `ALTER TABLE ADD ROLLUP` syntax can now be implemented by `CREATE MATERIALIZED VIEW`.
|
||||
|
||||
## Use materialized views
|
||||
|
||||
The Doris system provides a complete set of DDL syntax for materialized views, including creating, viewing, and deleting. The syntax of DDL is consistent with PostgreSQL and Oracle.
|
||||
|
||||
### Create a materialized view
|
||||
|
||||
Here you must first decide what kind of materialized view to create based on the characteristics of your query statement. This is not to say that your materialized view definition is exactly the same as one of your query statements. There are two principles here:
|
||||
|
||||
1. **Abstract** from the query statement, the grouping and aggregation methods shared by multiple queries are used as the definition of the materialized view.
|
||||
2. It is not necessary to create materialized views for all dimension combinations.
|
||||
|
||||
First of all, the first point, if a materialized view is abstracted, and multiple queries can be matched to this materialized view. This materialized view works best. Because the maintenance of the materialized view itself also consumes resources.
|
||||
|
||||
If the materialized view only fits a particular query, and other queries do not use this materialized view. As a result, the materialized view is not cost-effective, which not only occupies the storage resources of the cluster, but cannot serve more queries.
|
||||
|
||||
Therefore, users need to combine their own query statements and data dimension information to abstract the definition of some materialized views.
|
||||
|
||||
The second point is that in the actual analysis query, not all dimensional analysis will be covered. Therefore, it is enough to create a materialized view for the commonly used combination of dimensions, so as to achieve a space and time balance.
|
||||
|
||||
Creating a materialized view is an asynchronous operation, which means that after the user successfully submits the creation task, Doris will calculate the existing data in the background until the creation is successful.
|
||||
|
||||
The specific syntax can be viewed through the following command:
|
||||
|
||||
```
|
||||
HELP CREATE MATERIALIZED VIEW
|
||||
```
|
||||
|
||||
### Support aggregate functions
|
||||
|
||||
The aggregate functions currently supported by the materialized view function are:
|
||||
|
||||
+ SUM, MIN, MAX (Version 0.12)
|
||||
+ COUNT, BITMAP\_UNION, HLL\_UNION (Version 0.13)
|
||||
|
||||
+ The form of BITMAP\_UNION must be: `BITMAP_UNION(TO_BITMAP(COLUMN))` The column type can only be an integer (largeint also does not support), or `BITMAP_UNION(COLUMN)` and the base table is an AGG model.
|
||||
+ The form of HLL\_UNION must be: `HLL_UNION(HLL_HASH(COLUMN))` The column type cannot be DECIMAL, or `HLL_UNION(COLUMN)` and the base table is an AGG model.
|
||||
|
||||
### Update strategy
|
||||
|
||||
In order to ensure the data consistency between the materialized view table and the Base table, Doris will import, delete and other operations on the Base table are synchronized to the materialized view table. And through incremental update to improve update efficiency. To ensure atomicity through transaction.
|
||||
|
||||
For example, if the user inserts data into the base table through the INSERT command, this data will be inserted into the materialized view synchronously. When both the base table and the materialized view table are written successfully, the INSERT command will return successfully.
|
||||
|
||||
### Query automatic matching
|
||||
|
||||
After the materialized view is successfully created, the user's query does not need to be changed, that is, it is still the base table of the query. Doris will automatically select an optimal materialized view based on the current query statement, read data from the materialized view and calculate it.
|
||||
|
||||
Users can use the EXPLAIN command to check whether the current query uses a materialized view.
|
||||
|
||||
The matching relationship between the aggregation in the materialized view and the aggregation in the query:
|
||||
|
||||
| Materialized View Aggregation | Query Aggregation |
|
||||
| ---------- | -------- |
|
||||
| sum | sum |
|
||||
| min | min |
|
||||
| max | max |
|
||||
| count | count |
|
||||
| bitmap\_union | bitmap\_union, bitmap\_union\_count, count(distinct) |
|
||||
| hll\_union | hll\_raw\_agg, hll\_union\_agg, ndv, approx\_count\_distinct |
|
||||
|
||||
After the aggregation functions of bitmap and hll match the materialized view in the query, the aggregation operator of the query will be rewritten according to the table structure of the materialized view. See example 2 for details.
|
||||
|
||||
### Query materialized views
|
||||
|
||||
Check what materialized views the current table has, and what their table structure is. Through the following command:
|
||||
|
||||
```
|
||||
MySQL [test]> desc mv_test all;
|
||||
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
|
||||
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
|
||||
| mv_test | DUP_KEYS | k1 | INT | Yes | true | NULL | |
|
||||
| | | k2 | BIGINT | Yes | true | NULL | |
|
||||
| | | k3 | LARGEINT | Yes | true | NULL | |
|
||||
| | | k4 | SMALLINT | Yes | false | NULL | NONE |
|
||||
| | | | | | | | |
|
||||
| mv_2 | AGG_KEYS | k2 | BIGINT | Yes | true | NULL | |
|
||||
| | | k4 | SMALLINT | Yes | false | NULL | MIN |
|
||||
| | | k1 | INT | Yes | false | NULL | MAX |
|
||||
| | | | | | | | |
|
||||
| mv_3 | AGG_KEYS | k1 | INT | Yes | true | NULL | |
|
||||
| | | to_bitmap(`k2`) | BITMAP | No | false | | BITMAP_UNION |
|
||||
| | | | | | | | |
|
||||
| mv_1 | AGG_KEYS | k4 | SMALLINT | Yes | true | NULL | |
|
||||
| | | k1 | BIGINT | Yes | false | NULL | SUM |
|
||||
| | | k3 | LARGEINT | Yes | false | NULL | SUM |
|
||||
| | | k2 | BIGINT | Yes | false | NULL | MIN |
|
||||
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
|
||||
```
|
||||
|
||||
You can see that the current `mv_test` table has three materialized views: mv\_1, mv\_2 and mv\_3, and their table structure.
|
||||
|
||||
### Delete materialized view
|
||||
|
||||
If the user no longer needs the materialized view, you can delete the materialized view by 'DROP' commen.
|
||||
|
||||
The specific syntax can be viewed through the following command:
|
||||
|
||||
```
|
||||
HELP DROP MATERIALIZED VIEW
|
||||
```
|
||||
|
||||
## Best Practice 1
|
||||
|
||||
The use of materialized views is generally divided into the following steps:
|
||||
|
||||
1. Create a materialized view
|
||||
2. Asynchronously check whether the materialized view has been constructed
|
||||
3. Query and automatically match materialized views
|
||||
|
||||
**First is the first step: Create a materialized view**
|
||||
|
||||
Assume that the user has a sales record list, which stores the transaction id, salesperson, sales store, sales time, and amount of each transaction. The table building statement is:
|
||||
|
||||
```
|
||||
create table sales_records(record_id int, seller_id int, store_id int, sale_date date, sale_amt bigint) distributed by hash(record_id) properties("replication_num" = "1");
|
||||
```
|
||||
The table structure of this `sales_records` is as follows:
|
||||
|
||||
```
|
||||
MySQL [test]> desc sales_records;
|
||||
+-----------+--------+------+-------+---------+--- ----+
|
||||
| Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+--------+------+-------+---------+--- ----+
|
||||
| record_id | INT | Yes | true | NULL | |
|
||||
| seller_id | INT | Yes | true | NULL | |
|
||||
| store_id | INT | Yes | true | NULL | |
|
||||
| sale_date | DATE | Yes | false | NULL | NONE |
|
||||
| sale_amt | BIGINT | Yes | false | NULL | NONE |
|
||||
+-----------+--------+------+-------+---------+--- ----+
|
||||
```
|
||||
|
||||
At this time, if the user often performs an analysis query on the sales volume of different stores, you can create a materialized view for the `sales_records` table to group the sales stores and sum the sales of the same sales stores. The creation statement is as follows:
|
||||
|
||||
```
|
||||
MySQL [test]> create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
|
||||
```
|
||||
|
||||
The backend returns to the following figure, indicating that the task of creating a materialized view is submitted successfully.
|
||||
|
||||
```
|
||||
Query OK, 0 rows affected (0.012 sec)
|
||||
```
|
||||
|
||||
**Step 2: Check whether the materialized view has been built**
|
||||
|
||||
Since the creation of a materialized view is an asynchronous operation, after the user submits the task of creating a materialized view, he needs to asynchronously check whether the materialized view has been constructed through a command. The command is as follows:
|
||||
|
||||
```
|
||||
SHOW ALTER TABLE ROLLUP FROM db_name; (Version 0.12)
|
||||
SHOW ALTER TABLE MATERIALIZED VIEW FROM db_name; (Version 0.13)
|
||||
```
|
||||
|
||||
In this command, `db_name` is a parameter, you need to replace it with your real db name. The result of the command is to display all the tasks of creating a materialized view of this db. The results are as follows:
|
||||
|
||||
```
|
||||
+-------+---------------+---------------------+--- ------------------+---------------+--------------- --+----------+---------------+-----------+-------- -------------------------------------------------- -------------------------------------------------- -------------+----------+---------+
|
||||
| JobId | TableName | CreateTime | FinishedTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
|
||||
+-------+---------------+---------------------+--- ------------------+---------------+--------------- --+----------+---------------+-----------+-------- -------------------------------------------------- -------------------------------------------------- -------------+----------+---------+
|
||||
| 22036 | sales_records | 2020-07-30 20:04:28 | 2020-07-30 20:04:57 | sales_records | store_amt | 22037 | 5008 | FINISHED | | NULL | 86400 |
|
||||
+-------+---------------+---------------------+--- ------------------+---------------+--------------- --+----------+---------------+-----------+-------- ----------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Among them, TableName refers to which table the data of the materialized view comes from, and RollupIndexName refers to the name of the materialized view. One of the more important indicators is State.
|
||||
|
||||
When the State of the task of creating a materialized view has become FINISHED, it means that the materialized view has been created successfully. This means that it is possible to automatically match this materialized view when querying.
|
||||
|
||||
**Step 3: Query**
|
||||
|
||||
After the materialized view is created, when users query the sales volume of different stores, they will directly read the aggregated data from the materialized view `store_amt` just created. To achieve the effect of improving query efficiency.
|
||||
|
||||
The user's query still specifies the query `sales_records` table, for example:
|
||||
|
||||
```
|
||||
SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
|
||||
```
|
||||
|
||||
The above query will automatically match `store_amt`. The user can use the following command to check whether the current query matches the appropriate materialized view.
|
||||
|
||||
```
|
||||
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+-----------------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:<slot 2> `store_id` | <slot 3> sum(`sale_amt`) |
|
||||
| PARTITION: UNPARTITIONED |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 4:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: <slot 2> `store_id` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 04 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 3:AGGREGATE (merge finalize) |
|
||||
| | output: sum(<slot 3> sum(`sale_amt`)) |
|
||||
| | group by: <slot 2> `store_id` |
|
||||
| | |
|
||||
| 2:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 02 |
|
||||
| HASH_PARTITIONED: <slot 2> `store_id` |
|
||||
| |
|
||||
| 1:AGGREGATE (update serialize) |
|
||||
| | STREAMING |
|
||||
| | output: sum(`sale_amt`) |
|
||||
| | group by: `store_id` |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: sales_records |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: store_amt |
|
||||
| tabletRatio=10/10 |
|
||||
| tabletList=22038,22040,22042,22044,22046,22048,22050,22052,22054,22056 |
|
||||
| cardinality=0 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=1 |
|
||||
+-----------------------------------------------------------------------------+
|
||||
45 rows in set (0.006 sec)
|
||||
```
|
||||
The final thing is the rollup attribute in OlapScanNode. You can see that the rollup of the current query shows `store_amt`. That is to say, the query has been correctly matched to the materialized view `store_amt`, and data is read directly from the materialized view.
|
||||
|
||||
## Best Practice 2 PV,UV
|
||||
|
||||
Business scenario: Calculate the UV and PV of advertising
|
||||
|
||||
Assuming that the user's original ad click data is stored in Doris, then for ad PV and UV queries, the query speed can be improved by creating a materialized view of `bitmap_union`.
|
||||
|
||||
Use the following statement to first create a table that stores the details of the advertisement click data, including the click event of each click, what advertisement was clicked, what channel clicked, and who was the user who clicked.
|
||||
|
||||
```
|
||||
MySQL [test]> create table advertiser_view_record(time date, advertiser varchar(10), channel varchar(10), user_id int) distributed by hash(time) properties("replication_num" = "1");
|
||||
Query OK, 0 rows affected (0.014 sec)
|
||||
```
|
||||
The original ad click data table structure is:
|
||||
|
||||
```
|
||||
MySQL [test]> desc advertiser_view_record;
|
||||
+------------+-------------+------+-------+---------+-------+
|
||||
| Field | Type | Null | Key | Default | Extra |
|
||||
+------------+-------------+------+-------+---------+-------+
|
||||
| time | DATE | Yes | true | NULL | |
|
||||
| advertiser | VARCHAR(10) | Yes | true | NULL | |
|
||||
| channel | VARCHAR(10) | Yes | false | NULL | NONE |
|
||||
| user_id | INT | Yes | false | NULL | NONE |
|
||||
+------------+-------------+------+-------+---------+-------+
|
||||
4 rows in set (0.001 sec)
|
||||
```
|
||||
|
||||
1. Create a materialized view
|
||||
|
||||
Since the user wants to query the UV value of the advertisement, that is, a precise de-duplication of users of the same advertisement is required, the user's query is generally:
|
||||
|
||||
```
|
||||
SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
|
||||
```
|
||||
|
||||
For this kind of UV-seeking scene, we can create a materialized view with `bitmap_union` to achieve a precise deduplication effect in advance.
|
||||
|
||||
In Doris, the result of `count(distinct)` aggregation is exactly the same as the result of `bitmap_union_count` aggregation. And `bitmap_union_count` is equal to the result of `bitmap_union` to calculate count, so if the query ** involves `count(distinct)`, you can speed up the query by creating a materialized view with `bitmap_union` aggregation.**
|
||||
|
||||
For this case, you can create a materialized view that accurately deduplicate `user_id` based on advertising and channel grouping.
|
||||
|
||||
```
|
||||
MySQL [test]> create materialized view advertiser_uv as select advertiser, channel, bitmap_union(to_bitmap(user_id)) from advertiser_view_record group by advertiser, channel;
|
||||
Query OK, 0 rows affected (0.012 sec)
|
||||
```
|
||||
|
||||
*Note: Because the user\_id itself is an INT type, it is called `bitmap_union` directly in Doris. The fields need to be converted to bitmap type through the function `to_bitmap` first, and then `bitmap_union` can be aggregated. *
|
||||
|
||||
After the creation is complete, the table structure of the advertisement click schedule and the materialized view table is as follows:
|
||||
|
||||
```
|
||||
MySQL [test]> desc advertiser_view_record all;
|
||||
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
|
||||
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
|
||||
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
|
||||
| advertiser_view_record | DUP_KEYS | time | DATE | Yes | true | NULL | |
|
||||
| | | advertiser | VARCHAR(10) | Yes | true | NULL | |
|
||||
| | | channel | VARCHAR(10) | Yes | false | NULL | NONE |
|
||||
| | | user_id | INT | Yes | false | NULL | NONE |
|
||||
| | | | | | | | |
|
||||
| advertiser_uv | AGG_KEYS | advertiser | VARCHAR(10) | Yes | true | NULL | |
|
||||
| | | channel | VARCHAR(10) | Yes | true | NULL | |
|
||||
| | | to_bitmap(`user_id`) | BITMAP | No | false | | BITMAP_UNION |
|
||||
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
|
||||
```
|
||||
|
||||
2. Automatic query matching
|
||||
|
||||
When the materialized view table is created, when querying the advertisement UV, Doris will automatically query the data from the materialized view `advertiser_uv` just created. For example, the original query statement is as follows:
|
||||
|
||||
```
|
||||
SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
|
||||
```
|
||||
|
||||
After the materialized view is selected, the actual query will be transformed into:
|
||||
|
||||
```
|
||||
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id)) FROM advertiser_uv GROUP BY advertiser, channel;
|
||||
```
|
||||
|
||||
Through the EXPLAIN command, you can check whether Doris matches the materialized view:
|
||||
|
||||
```
|
||||
MySQL [test]> explain SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
|
||||
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:<slot 7> `advertiser` | <slot 8> `channel` | <slot 9> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`) |
|
||||
| PARTITION: UNPARTITIONED |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 4:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: <slot 4> `advertiser`, <slot 5> `channel` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 04 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 3:AGGREGATE (merge finalize) |
|
||||
| | output: bitmap_union_count(<slot 6> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`)) |
|
||||
| | group by: <slot 4> `advertiser`, <slot 5> `channel` |
|
||||
| | |
|
||||
| 2:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 02 |
|
||||
| HASH_PARTITIONED: <slot 4> `advertiser`, <slot 5> `channel` |
|
||||
| |
|
||||
| 1:AGGREGATE (update serialize) |
|
||||
| | STREAMING |
|
||||
| | output: bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`) |
|
||||
| | group by: `advertiser`, `channel` |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: advertiser_view_record |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: advertiser_uv |
|
||||
| tabletRatio=10/10 |
|
||||
| tabletList=22084,22086,22088,22090,22092,22094,22096,22098,22100,22102 |
|
||||
| cardinality=0 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=1 |
|
||||
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
45 rows in set (0.030 sec)
|
||||
```
|
||||
|
||||
In the result of EXPLAIN, you can first see that the rollup attribute value of OlapScanNode is advertiser_uv. In other words, the query directly scans the data of the materialized view. The match is successful.
|
||||
|
||||
Secondly, the calculation of `count(distinct)` for the `user_id` field is rewritten as `bitmap_union_count`. That is to achieve the effect of precise deduplication through bitmap.
|
||||
|
||||
|
||||
## Best Practice 3
|
||||
|
||||
Business scenario: matching a richer prefix index
|
||||
|
||||
The user's original table has three columns (k1, k2, k3). Among them, k1, k2 are prefix index columns. At this time, if the user query condition contains `where k1=a and k2=b`, the query can be accelerated through the index.
|
||||
|
||||
But in some cases, the user's filter conditions cannot match the prefix index, such as `where k3=c`. Then the query speed cannot be improved through the index.
|
||||
|
||||
This problem can be solved by creating a materialized view with k3 as the first column.
|
||||
|
||||
1. Create a materialized view
|
||||
|
||||
```
|
||||
CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;
|
||||
```
|
||||
|
||||
After the creation of the above grammar is completed, the complete detail data is retained in the materialized view, and the prefix index of the materialized view is the k3 column. The table structure is as follows:
|
||||
|
||||
```
|
||||
MySQL [test]> desc tableA all;
|
||||
+-----------+---------------+-------+------+------+-------+---------+-------+
|
||||
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+---------------+-------+------+------+-------+---------+-------+
|
||||
| tableA | DUP_KEYS | k1 | INT | Yes | true | NULL | |
|
||||
| | | k2 | INT | Yes | true | NULL | |
|
||||
| | | k3 | INT | Yes | true | NULL | |
|
||||
| | | | | | | | |
|
||||
| mv_1 | DUP_KEYS | k3 | INT | Yes | true | NULL | |
|
||||
| | | k2 | INT | Yes | false | NULL | NONE |
|
||||
| | | k1 | INT | Yes | false | NULL | NONE |
|
||||
+-----------+---------------+-------+------+------+-------+---------+-------+
|
||||
```
|
||||
|
||||
2. Query matching
|
||||
|
||||
At this time, if the user's query has k3 column, the filter condition is, for example:
|
||||
|
||||
```
|
||||
select k1, k2, k3 from table A where k3=1;
|
||||
```
|
||||
|
||||
At this time, the query will read data directly from the mv_1 materialized view just created. The materialized view has a prefix index on k3, and query efficiency will also be improved.
|
||||
|
||||
|
||||
## Limitations
|
||||
|
||||
1. The parameter of the aggregate function of the materialized view does not support the expression only supports a single column, for example: sum(a+b) does not support.
|
||||
2. If the conditional column of the delete statement does not exist in the materialized view, the delete operation cannot be performed. If you must delete data, you need to delete the materialized view before deleting the data.
|
||||
3. Too many materialized views on a single table will affect the efficiency of importing: When importing data, the materialized view and base table data are updated synchronously. If a table has more than 10 materialized view tables, it may cause the import speed to be very high. slow. This is the same as a single import needs to import 10 tables at the same time.
|
||||
4. The same column with different aggregate functions cannot appear in a materialized view at the same time. For example, select sum(a), min(a) from table are not supported.
|
||||
5. For the Unique Key data model, the materialized view can only change the column order and cannot play the role of aggregation. Therefore, in the Unique Key model, it is not possible to perform coarse-grained aggregation operations on the data by creating a materialized view.
|
||||
|
||||
## Error
|
||||
1. DATA_QUALITY_ERR: "The data quality does not satisfy, please check your data"
|
||||
Materialized view creation failed due to data quality issues.
|
||||
Note: The bitmap type only supports positive integers. If there are negative Numbers in the original data, the materialized view will fail to be created
|
||||
|
||||
## More Help
|
||||
|
||||
For more detailed syntax and best practices for using materialized views, see [CREATE MATERIALIZED VIEW](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-MATERIALIZED- VIEW.html) and [DROP MATERIALIZED VIEW](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-MATERIALIZED-VIEW.html) command manual, you can also Enter `HELP CREATE MATERIALIZED VIEW` and `HELP DROP MATERIALIZED VIEW` at the command line of the MySql client for more help information.
|
||||
|
||||
@ -26,3 +26,443 @@ under the License.
|
||||
|
||||
# Dynamic Partition
|
||||
|
||||
Dynamic partition is a new feature introduced in Doris version 0.12. It's designed to manage partition's Time-to-Life (TTL), reducing the burden on users.
|
||||
|
||||
At present, the functions of dynamically adding partitions and dynamically deleting partitions are realized.
|
||||
|
||||
Dynamic partitioning is only supported for Range partitions.
|
||||
|
||||
## Noun Interpretation
|
||||
|
||||
* FE: Frontend, the front-end node of Doris. Responsible for metadata management and request access.
|
||||
* BE: Backend, Doris's back-end node. Responsible for query execution and data storage.
|
||||
|
||||
## Principle
|
||||
|
||||
In some usage scenarios, the user will partition the table according to the day and perform routine tasks regularly every day. At this time, the user needs to manually manage the partition. Otherwise, the data load may fail because the user does not create a partition. This brings additional maintenance costs to the user.
|
||||
|
||||
Through the dynamic partitioning feature, users can set the rules of dynamic partitioning when building tables. FE will start a background thread to create or delete partitions according to the rules specified by the user. Users can also change existing rules at runtime.
|
||||
|
||||
## Usage
|
||||
|
||||
### Establishment of tables
|
||||
|
||||
The rules for dynamic partitioning can be specified when the table is created or modified at runtime. Currently,dynamic partition rules can only be set for partition tables with single partition columns.
|
||||
|
||||
* Specified when creating table
|
||||
|
||||
```
|
||||
CREATE TABLE tbl1
|
||||
(...)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.prop1" = "value1",
|
||||
"dynamic_partition.prop2" = "value2",
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
* Modify at runtime
|
||||
|
||||
```
|
||||
ALTER TABLE tbl1 SET
|
||||
(
|
||||
"dynamic_partition.prop1" = "value1",
|
||||
"dynamic_partition.prop2" = "value2",
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
### Dynamic partition rule parameters
|
||||
|
||||
The rules of dynamic partition are prefixed with `dynamic_partition.`:
|
||||
|
||||
* `dynamic_partition.enable`
|
||||
|
||||
Whether to enable the dynamic partition feature. Can be specified as `TRUE` or` FALSE`. If not filled, the default is `TRUE`. If it is `FALSE`, Doris will ignore the dynamic partitioning rules of the table.
|
||||
|
||||
* `dynamic_partition.time_unit`
|
||||
|
||||
The unit for dynamic partition scheduling. Can be specified as `HOUR`,`DAY`,` WEEK`, and `MONTH`, means to create or delete partitions by hour, day, week, and month, respectively.
|
||||
|
||||
When specified as `HOUR`, the suffix format of the dynamically created partition name is `yyyyMMddHH`, for example, `2020032501`. *When the time unit is HOUR, the data type of partition column cannot be DATE.*
|
||||
|
||||
When specified as `DAY`, the suffix format of the dynamically created partition name is `yyyyMMdd`, for example, `20200325`.
|
||||
|
||||
When specified as `WEEK`, the suffix format of the dynamically created partition name is `yyyy_ww`. That is, the week of the year of current date. For example, the suffix of the partition created for `2020-03-25` is `2020_13`, indicating that it is currently the 13th week of 2020.
|
||||
|
||||
When specified as `MONTH`, the suffix format of the dynamically created partition name is `yyyyMM`, for example, `202003`.
|
||||
|
||||
* `dynamic_partition.time_zone`
|
||||
|
||||
The time zone of the dynamic partition, if not filled in, defaults to the time zone of the current machine's system, such as `Asia/Shanghai`, if you want to know the supported TimeZone, you can found in `https://en.wikipedia.org/wiki/List_of_tz_database_time_zones`.
|
||||
|
||||
* `dynamic_partition.start`
|
||||
|
||||
The starting offset of the dynamic partition, usually a negative number. Depending on the `time_unit` attribute, based on the current day (week / month), the partitions with a partition range before this offset will be deleted. If not filled, the default is `-2147483648`, that is, the history partition will not be deleted.
|
||||
|
||||
* `dynamic_partition.end`
|
||||
|
||||
The end offset of the dynamic partition, usually a positive number. According to the difference of the `time_unit` attribute, the partition of the corresponding range is created in advance based on the current day (week / month).
|
||||
|
||||
* `dynamic_partition.prefix`
|
||||
|
||||
The dynamically created partition name prefix.
|
||||
|
||||
* `dynamic_partition.buckets`
|
||||
|
||||
The number of buckets corresponding to the dynamically created partitions.
|
||||
|
||||
* `dynamic_partition.replication_num`
|
||||
|
||||
The replication number of dynamic partition.If not filled in, defaults to the number of table's replication number.
|
||||
|
||||
* `dynamic_partition.start_day_of_week`
|
||||
|
||||
When `time_unit` is` WEEK`, this parameter is used to specify the starting point of the week. The value ranges from 1 to 7. Where 1 is Monday and 7 is Sunday. The default is 1, which means that every week starts on Monday.
|
||||
|
||||
* `dynamic_partition.start_day_of_month`
|
||||
|
||||
When `time_unit` is` MONTH`, this parameter is used to specify the start date of each month. The value ranges from 1 to 28. 1 means the 1st of every month, and 28 means the 28th of every month. The default is 1, which means that every month starts at 1st. The 29, 30 and 31 are not supported at the moment to avoid ambiguity caused by lunar years or months.
|
||||
|
||||
* `dynamic_partition.create_history_partition`
|
||||
|
||||
The default is false. When set to true, Doris will automatically create all partitions, as described in the creation rules below. At the same time, the parameter `max_dynamic_partition_num` of FE will limit the total number of partitions to avoid creating too many partitions at once. When the number of partitions expected to be created is greater than `max_dynamic_partition_num`, the operation will fail.
|
||||
|
||||
When the `start` attribute is not specified, this parameter has no effect.
|
||||
|
||||
* `dynamic_partition.history_partition_num`
|
||||
|
||||
When `create_history_partition` is `true`, this parameter is used to specify the number of history partitions. The default value is -1, which means it is not set.
|
||||
|
||||
* `dynamic_partition.hot_partition_num`
|
||||
|
||||
Specify how many of the latest partitions are hot partitions. For hot partition, the system will automatically set its `storage_medium` parameter to SSD, and set `storage_cooldown_time`.
|
||||
|
||||
`hot_partition_num` is all partitions in the previous n days and in the future.
|
||||
|
||||
|
||||
Let us give an example. Suppose today is 2021-05-20, partition by day, and the properties of dynamic partition are set to: hot_partition_num=2, end=3, start=-3. Then the system will automatically create the following partitions, and set the `storage_medium` and `storage_cooldown_time` properties:
|
||||
|
||||
```
|
||||
p20210517: ["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
|
||||
p20210518: ["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
|
||||
p20210519: ["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
|
||||
p20210520: ["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
|
||||
p20210521: ["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
|
||||
p20210522: ["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
|
||||
p20210523: ["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
|
||||
```
|
||||
|
||||
|
||||
* `dynamic_partition.reserved_history_periods`
|
||||
|
||||
The range of reserved history periods. It should be in the form of `[yyyy-MM-dd,yyyy-MM-dd],[...,...]` while the `dynamic_partition.time_unit` is "DAY, WEEK, and MONTH". And it should be in the form of `[yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...]` while the dynamic_partition.time_unit` is "HOUR". And no more spaces expected. The default value is `"NULL"`, which means it is not set.
|
||||
|
||||
Let us give an example. Suppose today is 2021-09-06,partitioned by day, and the properties of dynamic partition are set to:
|
||||
|
||||
```time_unit="DAY/WEEK/MONTH", end=3, start=-3, reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"```.
|
||||
|
||||
The the system will automatically reserve following partitions in following period :
|
||||
|
||||
```
|
||||
["2020-06-01","2020-06-20"],
|
||||
["2020-10-31","2020-11-15"]
|
||||
```
|
||||
or
|
||||
|
||||
```time_unit="HOUR", end=3, start=-3, reserved_history_periods="[2020-06-01 00:00:00,2020-06-01 03:00:00]"```.
|
||||
|
||||
The the system will automatically reserve following partitions in following period :
|
||||
|
||||
```
|
||||
["2020-06-01 00:00:00","2020-06-01 03:00:00"]
|
||||
```
|
||||
|
||||
Otherwise, every `[...,...]` in `reserved_history_periods` is a couple of properties, and they should be set at the same time. And the first date can't be larger than the second one.
|
||||
|
||||
|
||||
#### Create History Partition Rules
|
||||
|
||||
When `create_history_partition` is `true`, i.e. history partition creation is enabled, Doris determines the number of history partitions to be created based on `dynamic_partition.start` and `dynamic_partition.history_partition_num`.
|
||||
|
||||
Assuming the number of history partitions to be created is `expect_create_partition_num`, the number is as follows according to different settings.
|
||||
|
||||
1. `create_history_partition` = `true`
|
||||
- `dynamic_partition.history_partition_num` is not set, i.e. -1.
|
||||
`expect_create_partition_num` = `end` - `start`;
|
||||
|
||||
- `dynamic_partition.history_partition_num` is set
|
||||
`expect_create_partition_num` = `end` - max(`start`, `-histoty_partition_num`);
|
||||
|
||||
2. `create_history_partition` = `false`
|
||||
No history partition will be created, `expect_create_partition_num` = `end` - 0;
|
||||
|
||||
When `expect_create_partition_num` is greater than `max_dynamic_partition_num` (default 500), creating too many partitions is prohibited.
|
||||
|
||||
**Examples:**
|
||||
|
||||
1. Suppose today is 2021-05-20, partition by day, and the attributes of dynamic partition are set to `create_history_partition=true, end=3, start=-3, history_partition_num=1`, then the system will automatically create the following partitions.
|
||||
|
||||
```
|
||||
p20210519
|
||||
p20210520
|
||||
p20210521
|
||||
p20210522
|
||||
p20210523
|
||||
```
|
||||
|
||||
2. `history_partition_num=5` and keep the rest attributes as in 1, then the system will automatically create the following partitions.
|
||||
|
||||
```
|
||||
p20210517
|
||||
p20210518
|
||||
p20210519
|
||||
p20210520
|
||||
p20210521
|
||||
p20210522
|
||||
p20210523
|
||||
```
|
||||
|
||||
3. `history_partition_num=-1` i.e., if you do not set the number of history partitions and keep the rest of the attributes as in 1, the system will automatically create the following partitions.
|
||||
|
||||
```
|
||||
p20210517
|
||||
p20210518
|
||||
p20210519
|
||||
p20210520
|
||||
p20210521
|
||||
p20210522
|
||||
p20210523
|
||||
```
|
||||
|
||||
### Notice
|
||||
|
||||
If some partitions between `dynamic_partition.start` and `dynamic_partition.end` are lost due to some unexpected circumstances when using dynamic partition, the lost partitions between the current time and `dynamic_partition.end` will be recreated, but the lost partitions between `dynamic_partition.start` and the current time will not be recreated.
|
||||
|
||||
### Example
|
||||
|
||||
1. Table `tbl1` partition column k1, type is DATE, create a dynamic partition rule. By day partition, only the partitions of the last 7 days are kept, and the partitions of the next 3 days are created in advance.
|
||||
|
||||
```
|
||||
CREATE TABLE tbl1
|
||||
(
|
||||
k1 DATE,
|
||||
...
|
||||
)
|
||||
PARTITION BY RANGE(k1) ()
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "DAY",
|
||||
"dynamic_partition.start" = "-7",
|
||||
"dynamic_partition.end" = "3",
|
||||
"dynamic_partition.prefix" = "p",
|
||||
"dynamic_partition.buckets" = "32"
|
||||
);
|
||||
```
|
||||
|
||||
Suppose the current date is 2020-05-29. According to the above rules, tbl1 will produce the following partitions:
|
||||
|
||||
```
|
||||
p20200529: ["2020-05-29", "2020-05-30")
|
||||
p20200530: ["2020-05-30", "2020-05-31")
|
||||
p20200531: ["2020-05-31", "2020-06-01")
|
||||
p20200601: ["2020-06-01", "2020-06-02")
|
||||
```
|
||||
|
||||
On the next day, 2020-05-30, a new partition will be created `p20200602: [" 2020-06-02 "," 2020-06-03 ")`
|
||||
|
||||
On 2020-06-06, because `dynamic_partition.start` is set to 7, the partition 7 days ago will be deleted, that is, the partition `p20200529` will be deleted.
|
||||
|
||||
2. Table tbl1 partition column k1, type is DATETIME, create a dynamic partition rule. Partition by week, only keep the partition of the last 2 weeks, and create the partition of the next 2 weeks in advance.
|
||||
|
||||
```
|
||||
CREATE TABLE tbl1
|
||||
(
|
||||
k1 DATETIME,
|
||||
...
|
||||
)
|
||||
PARTITION BY RANGE(k1) ()
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "WEEK",
|
||||
"dynamic_partition.start" = "-2",
|
||||
"dynamic_partition.end" = "2",
|
||||
"dynamic_partition.prefix" = "p",
|
||||
"dynamic_partition.buckets" = "8"
|
||||
);
|
||||
```
|
||||
|
||||
Suppose the current date is 2020-05-29, which is the 22nd week of 2020. The default week starts on Monday. Based on the above rules, tbl1 will produce the following partitions:
|
||||
|
||||
```
|
||||
p2020_22: ["2020-05-25 00:00:00", "2020-06-01 00:00:00")
|
||||
p2020_23: ["2020-06-01 00:00:00", "2020-06-08 00:00:00")
|
||||
p2020_24: ["2020-06-08 00:00:00", "2020-06-15 00:00:00")
|
||||
```
|
||||
|
||||
The start date of each partition is Monday of the week. At the same time, because the type of the partition column k1 is DATETIME, the partition value will fill the hour, minute and second fields, and all are 0.
|
||||
|
||||
On 2020-06-15, the 25th week, the partition 2 weeks ago will be deleted, ie `p2020_22` will be deleted.
|
||||
|
||||
In the above example, suppose the user specified the start day of the week as `"dynamic_partition.start_day_of_week" = "3"`, that is, set Wednesday as the start of week. The partition is as follows:
|
||||
|
||||
```
|
||||
p2020_22: ["2020-05-27 00:00:00", "2020-06-03 00:00:00")
|
||||
p2020_23: ["2020-06-03 00:00:00", "2020-06-10 00:00:00")
|
||||
p2020_24: ["2020-06-10 00:00:00", "2020-06-17 00:00:00")
|
||||
```
|
||||
|
||||
That is, the partition ranges from Wednesday of the current week to Tuesday of the next week.
|
||||
|
||||
* Note: 2019-12-31 and 2020-01-01 are in same week, if the starting date of the partition is 2019-12-31, the partition name is `p2019_53`, if the starting date of the partition is 2020-01 -01, the partition name is `p2020_01`.
|
||||
|
||||
3. Table tbl1 partition column k1, type is DATE, create a dynamic partition rule. Partition by month without deleting historical partitions, and create partitions for the next 2 months in advance. At the same time, set the starting date on the 3rd of each month.
|
||||
|
||||
```
|
||||
CREATE TABLE tbl1
|
||||
(
|
||||
k1 DATE,
|
||||
...
|
||||
)
|
||||
PARTITION BY RANGE(k1) ()
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "MONTH",
|
||||
"dynamic_partition.end" = "2",
|
||||
"dynamic_partition.prefix" = "p",
|
||||
"dynamic_partition.buckets" = "8",
|
||||
"dynamic_partition.start_day_of_month" = "3"
|
||||
);
|
||||
```
|
||||
|
||||
Suppose the current date is 2020-05-29. Based on the above rules, tbl1 will produce the following partitions:
|
||||
|
||||
```
|
||||
p202005: ["2020-05-03", "2020-06-03")
|
||||
p202006: ["2020-06-03", "2020-07-03")
|
||||
p202007: ["2020-07-03", "2020-08-03")
|
||||
```
|
||||
|
||||
Because `dynamic_partition.start` is not set, the historical partition will not be deleted.
|
||||
|
||||
Assuming that today is 2020-05-20, and set 28th as the start of each month, the partition range is:
|
||||
|
||||
```
|
||||
p202004: ["2020-04-28", "2020-05-28")
|
||||
p202005: ["2020-05-28", "2020-06-28")
|
||||
p202006: ["2020-06-28", "2020-07-28")
|
||||
```
|
||||
|
||||
### Modify Dynamic Partition Properties
|
||||
|
||||
You can modify the properties of the dynamic partition with the following command
|
||||
|
||||
```
|
||||
ALTER TABLE tbl1 SET
|
||||
(
|
||||
"dynamic_partition.prop1" = "value1",
|
||||
...
|
||||
);
|
||||
```
|
||||
|
||||
The modification of certain attributes may cause conflicts. Assume that the partition granularity was DAY and the following partitions have been created:
|
||||
|
||||
```
|
||||
p20200519: ["2020-05-19", "2020-05-20")
|
||||
p20200520: ["2020-05-20", "2020-05-21")
|
||||
p20200521: ["2020-05-21", "2020-05-22")
|
||||
```
|
||||
|
||||
If the partition granularity is changed to MONTH at this time, the system will try to create a partition with the range `["2020-05-01", "2020-06-01")`, and this range conflicts with the existing partition. So it cannot be created. And the partition with the range `["2020-06-01", "2020-07-01")` can be created normally. Therefore, the partition between 2020-05-22 and 2020-05-30 needs to be filled manually.
|
||||
|
||||
### Check Dynamic Partition Table Scheduling Status
|
||||
|
||||
You can further view the scheduling of dynamic partitioned tables by using the following command:
|
||||
|
||||
```
|
||||
mysql> SHOW DYNAMIC PARTITION TABLES;
|
||||
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
|
||||
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
|
||||
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
|
||||
| d3 | true | WEEK | -3 | 3 | p | 1 | MONDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | [2021-12-01,2021-12-31] |
|
||||
| d5 | true | DAY | -7 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d4 | true | WEEK | -3 | 3 | p | 1 | WEDNESDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d6 | true | MONTH | -2147483648 | 2 | p | 8 | 3rd | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d2 | true | DAY | -3 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d7 | true | MONTH | -2147483648 | 5 | p | 8 | 24th | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
|
||||
7 rows in set (0.02 sec)
|
||||
```
|
||||
|
||||
* LastUpdateTime: The last time of modifying dynamic partition properties
|
||||
* LastSchedulerTime: The last time of performing dynamic partition scheduling
|
||||
* State: The state of the last execution of dynamic partition scheduling
|
||||
* LastCreatePartitionMsg: Error message of the last time to dynamically add partition scheduling
|
||||
* LastDropPartitionMsg: Error message of the last execution of dynamic deletion partition scheduling
|
||||
|
||||
## Advanced Operation
|
||||
|
||||
### FE Configuration Item
|
||||
|
||||
* dynamic\_partition\_enable
|
||||
|
||||
Whether to enable Doris's dynamic partition feature. The default value is false, which is off. This parameter only affects the partitioning operation of dynamic partition tables, not normal tables. You can modify the parameters in `fe.conf` and restart FE to take effect. You can also execute the following commands at runtime to take effect:
|
||||
|
||||
MySQL protocol:
|
||||
|
||||
`ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true")`
|
||||
|
||||
HTTP protocol:
|
||||
|
||||
`curl --location-trusted -u username:password -XGET http://fe_host:fe_http_port/api/_set_config?dynamic_partition_enable=true`
|
||||
|
||||
To turn off dynamic partitioning globally, set this parameter to false.
|
||||
|
||||
* dynamic\_partition\_check\_interval\_seconds
|
||||
|
||||
The execution frequency of dynamic partition threads defaults to 3600 (1 hour), that is, scheduling is performed every 1 hour. You can modify the parameters in `fe.conf` and restart FE to take effect. You can also modify the following commands at runtime:
|
||||
|
||||
MySQL protocol:
|
||||
|
||||
`ADMIN SET FRONTEND CONFIG ("dynamic_partition_check_interval_seconds" = "7200")`
|
||||
|
||||
HTTP protocol:
|
||||
|
||||
`curl --location-trusted -u username:password -XGET http://fe_host:fe_http_port/api/_set_config?dynamic_partition_check_interval_seconds=432000`
|
||||
|
||||
### Converting dynamic and manual partition tables to each other
|
||||
|
||||
For a table, dynamic and manual partitioning can be freely converted, but they cannot exist at the same time, there is and only one state.
|
||||
|
||||
#### Converting Manual Partitioning to Dynamic Partitioning
|
||||
|
||||
If a table is not dynamically partitioned when it is created, it can be converted to dynamic partitioning at runtime by modifying the dynamic partitioning properties with `ALTER TABLE`, an example of which can be seen with `HELP ALTER TABLE`.
|
||||
|
||||
When dynamic partitioning feature is enabled, Doris will no longer allow users to manage partitions manually, but will automatically manage partitions based on dynamic partition properties.
|
||||
|
||||
**NOTICE**: If `dynamic_partition.start` is set, historical partitions with a partition range before the start offset of the dynamic partition will be deleted.
|
||||
|
||||
#### Converting Dynamic Partitioning to Manual Partitioning
|
||||
|
||||
The dynamic partitioning feature can be disabled by executing `ALTER TABLE tbl_name SET ("dynamic_partition.enable" = "false") ` and converting it to a manual partition table.
|
||||
|
||||
When dynamic partitioning feature is disabled, Doris will no longer manage partitions automatically, and users will have to create or delete partitions manually by using `ALTER TABLE`.
|
||||
|
||||
## Common problem
|
||||
|
||||
1. After creating the dynamic partition table, it prompts ```Could not create table with dynamic partition when fe config dynamic_partition_enable is false```
|
||||
|
||||
Because the main switch of dynamic partition, that is, the configuration of FE ```dynamic_partition_enable``` is false, the dynamic partition table cannot be created.
|
||||
|
||||
At this time, please modify the FE configuration file, add a line ```dynamic_partition_enable=true```, and restart FE. Or execute the command ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true") to turn on the dynamic partition switch.
|
||||
|
||||
## More Help
|
||||
|
||||
For more detailed syntax and best practices for using dynamic partitions, see [SHOW DYNAMIC PARTITION](../../sql-manual/sql-reference-v2/Show-Statements/SHOW-DYNAMIC-PARTITION.md) Command manual, you can also enter `HELP ALTER TABLE` in the MySql client command line for more help information.
|
||||
|
||||
@ -25,3 +25,258 @@ under the License.
|
||||
-->
|
||||
|
||||
# Runtime Filter
|
||||
|
||||
Runtime Filter is a new feature officially added in Doris 0.15. It is designed to dynamically generate filter conditions for certain Join queries at runtime to reduce the amount of scanned data, avoid unnecessary I/O and network transmission, and speed up the query.
|
||||
|
||||
It's design, implementation and effects, please refer to [ISSUE 6116](https://github.com/apache/incubator-doris/issues/6116).
|
||||
|
||||
## Noun Interpretation
|
||||
|
||||
* Left table: the table on the left during Join query. Perform Probe operation. The order can be adjusted by Join Reorder.
|
||||
* Right table: the table on the right during Join query. Perform the Build operation. The order can be adjusted by Join Reorder.
|
||||
* Fragment: FE will convert the execution of specific SQL statements into corresponding fragments and send them to BE for execution. The corresponding Fragment is executed on the BE, and the results are aggregated and returned to the FE.
|
||||
* Join on clause: `Aa=Bb` in `A join B on Aa=Bb`, based on this to generate join conjuncts during query planning, including expr used by join Build and Probe, where Build expr is called in Runtime Filter src expr, Probe expr are called target expr in Runtime Filter.
|
||||
|
||||
## Principle
|
||||
|
||||
Runtime Filter is generated during query planning, constructed in HashJoinNode, and applied in ScanNode.
|
||||
|
||||
For example, there is currently a Join query between the T1 table and the T2 table. Its Join mode is HashJoin. T1 is a fact table with 100,000 rows of data. T2 is a dimension table with 2000 rows of data. Doris join The actual situation is:
|
||||
```
|
||||
| > HashJoinNode <
|
||||
| | |
|
||||
| | 100000 | 2000
|
||||
| | |
|
||||
| OlapScanNode OlapScanNode
|
||||
| ^ ^
|
||||
| | 100000 | 2000
|
||||
| T1 T2
|
||||
|
|
||||
```
|
||||
Obviously, scanning data for T2 is much faster than T1. If we take the initiative to wait for a while and then scan T1, after T2 sends the scanned data record to HashJoinNode, HashJoinNode calculates a filter condition based on the data of T2, such as the maximum value of T2 data And the minimum value, or build a Bloom Filter, and then send this filter condition to ScanNode waiting to scan T1, the latter applies this filter condition and delivers the filtered data to HashJoinNode, thereby reducing the number of probe hash tables and network overhead. This filter condition is Runtime Filter, and the effect is as follows:
|
||||
```
|
||||
| > HashJoinNode <
|
||||
| | |
|
||||
| | 6000 | 2000
|
||||
| | |
|
||||
| OlapScanNode OlapScanNode
|
||||
| ^ ^
|
||||
| | 100000 | 2000
|
||||
| T1 T2
|
||||
|
|
||||
```
|
||||
If the filter condition (Runtime Filter) can be pushed down to the storage engine, in some cases, the index can be used to directly reduce the amount of scanned data, thereby greatly reducing the scanning time. The effect is as follows:
|
||||
```
|
||||
| > HashJoinNode <
|
||||
| | |
|
||||
| | 6000 | 2000
|
||||
| | |
|
||||
| OlapScanNode OlapScanNode
|
||||
| ^ ^
|
||||
| | 6000 | 2000
|
||||
| T1 T2
|
||||
|
|
||||
```
|
||||
It can be seen that, unlike predicate push-down and partition cutting, Runtime Filter is a filter condition dynamically generated at runtime, that is, when the query is run, the join on clause is parsed to determine the filter expression, and the expression is broadcast to ScanNode that is reading the left table , Thereby reducing the amount of scanned data, thereby reducing the number of probe hash table, avoiding unnecessary I/O and network transmission.
|
||||
|
||||
Runtime Filter is mainly used to optimize joins for large tables. If the amount of data in the left table is too small, or the amount of data in the right table is too large, the Runtime Filter may not achieve the expected effect.
|
||||
|
||||
## Usage
|
||||
|
||||
### Runtime Filter query options
|
||||
|
||||
For query options related to Runtime Filter, please refer to the following sections:
|
||||
|
||||
- The first query option is to adjust the type of Runtime Filter used. In most cases, you only need to adjust this option, and keep the other options as default.
|
||||
|
||||
- `runtime_filter_type`: Including Bloom Filter, MinMax Filter, IN predicate and IN_OR_BLOOM Filter. By default, only IN_OR_BLOOM Filter will be used. In some cases, the performance will be higher when both Bloom Filter, MinMax Filter and IN predicate are used at the same time.
|
||||
|
||||
- Other query options usually only need to be further adjusted in certain specific scenarios to achieve the best results. Usually only after performance testing, optimize for resource-intensive, long enough running time and high enough frequency queries.
|
||||
|
||||
- `runtime_filter_mode`: Used to adjust the push-down strategy of Runtime Filter, including three strategies of OFF, LOCAL, and GLOBAL. The default setting is the GLOBAL strategy
|
||||
|
||||
- `runtime_filter_wait_time_ms`: the time that ScanNode in the left table waits for each Runtime Filter, the default is 1000ms
|
||||
|
||||
- `runtime_filters_max_num`: The maximum number of Bloom Filters in the Runtime Filter that can be applied to each query, the default is 10
|
||||
|
||||
- `runtime_bloom_filter_min_size`: the minimum length of Bloom Filter in Runtime Filter, default 1048576 (1M)
|
||||
|
||||
- `runtime_bloom_filter_max_size`: the maximum length of Bloom Filter in Runtime Filter, the default is 16777216 (16M)
|
||||
|
||||
- `runtime_bloom_filter_size`: The default length of Bloom Filter in Runtime Filter, the default is 2097152 (2M)
|
||||
|
||||
- `runtime_filter_max_in_num`: If the number of rows in the right table of the join is greater than this value, we will not generate an IN predicate, the default is 1024
|
||||
|
||||
The query options are further explained below.
|
||||
|
||||
#### 1.runtime_filter_type
|
||||
Type of Runtime Filter used.
|
||||
|
||||
**Type**: Number (1, 2, 4, 8) or the corresponding mnemonic string (IN, BLOOM_FILTER, MIN_MAX, IN_OR_BLOOM_FILTER), the default is 8 (IN_OR_BLOOM FILTER), use multiple commas to separate, pay attention to the need to add quotation marks , Or add any number of types, for example:
|
||||
```
|
||||
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
|
||||
```
|
||||
Equivalent to:
|
||||
```
|
||||
set runtime_filter_type=7;
|
||||
```
|
||||
|
||||
**Precautions for use**
|
||||
|
||||
- **IN or Bloom Filter**: According to the actual number of rows in the right table during execution, the system automatically determines whether to use IN predicate or Bloom Filter.
|
||||
- By default, IN Predicate will be used when the number of data rows in the right table is less than 1024 (which can be adjusted by ` runtime_filter_max_in_num 'in the session variable). Otherwise, use bloom filter.
|
||||
- **Bloom Filter**: There is a certain misjudgment rate, which results in the filtered data being a little less than expected, but it will not cause the final result to be inaccurate. In most cases, Bloom Filter can improve performance or has no significant impact on performance, but in some cases Under circumstances will cause performance degradation.
|
||||
- Bloom Filter construction and application overhead is high, so when the filtering rate is low, or the amount of data in the left table is small, Bloom Filter may cause performance degradation.
|
||||
- At present, only the Key column of the left table can be pushed down to the storage engine if the Bloom Filter is applied, and the test results show that the performance of the Bloom Filter is often reduced when the Bloom Filter is not pushed down to the storage engine.
|
||||
- Currently Bloom Filter only has short-circuit logic when using expression filtering on ScanNode, that is, when the false positive rate is too high, the Bloom Filter will not continue to be used, but there is no short-circuit logic when the Bloom Filter is pushed down to the storage engine , So when the filtration rate is low, it may cause performance degradation.
|
||||
|
||||
- **MinMax Filter**: Contains the maximum value and the minimum value, thereby filtering data smaller than the minimum value and greater than the maximum value. The filtering effect of the MinMax Filter is related to the type of the Key column in the join on clause and the data distribution of the left and right tables.
|
||||
- When the type of the Key column in the join on clause is int/bigint/double, etc., in extreme cases, if the maximum and minimum values of the left and right tables are the same, there is no effect, otherwise the maximum value of the right table is less than the minimum value of the left table, or the minimum of the right table The value is greater than the maximum value in the left table, the effect is best.
|
||||
- When the type of the Key column in the join on clause is varchar, etc., applying the MinMax Filter will often cause performance degradation.
|
||||
|
||||
- **IN predicate**: Construct IN predicate based on all the values of Key listed in the join on clause on the right table, and use the constructed IN predicate to filter on the left table. Compared with Bloom Filter, the cost of construction and application is lower. The amount of data in the right table is lower. When it is less, it tends to perform better.
|
||||
- By default, only the number of data rows in the right table is less than 1024 will be pushed down (can be adjusted by `runtime_filter_max_in_num` in the session variable).
|
||||
- Currently IN predicate already implement a merge method.
|
||||
- When IN predicate and other filters are specified at the same time, and the filtering value of IN predicate does not reach runtime_filter_max_in_num will try to remove other filters. The reason is that IN predicate is an accurate filtering condition. Even if there is no other filter, it can filter efficiently. If it is used at the same time, other filters will do useless work. Currently, only when the producer and consumer of the runtime filter are in the same fragment can there be logic to remove the Non-IN predicate.
|
||||
|
||||
#### 2.runtime_filter_mode
|
||||
Used to control the transmission range of Runtime Filter between instances.
|
||||
|
||||
**Type**: Number (0, 1, 2) or corresponding mnemonic string (OFF, LOCAL, GLOBAL), default 2 (GLOBAL).
|
||||
|
||||
**Precautions for use**
|
||||
|
||||
LOCAL: Relatively conservative, the constructed Runtime Filter can only be used in the same Fragment on the same instance (the smallest unit of query execution), that is, the Runtime Filter producer (the HashJoinNode that constructs the Filter) and the consumer (the ScanNode that uses the RuntimeFilter) The same Fragment, such as the general scene of broadcast join;
|
||||
|
||||
GLOBAL: Relatively radical. In addition to satisfying the scenario of the LOCAL strategy, the Runtime Filter can also be combined and transmitted to different Fragments on different instances via the network. For example, the Runtime Filter producer and consumer are in different Fragments, such as shuffle join.
|
||||
|
||||
In most cases, the GLOBAL strategy can optimize queries in a wider range of scenarios, but in some shuffle joins, the cost of generating and merging Runtime Filters exceeds the performance advantage brought to the query, and you can consider changing to the LOCAL strategy.
|
||||
|
||||
If the join query involved in the cluster does not improve performance due to Runtime Filter, you can change the setting to OFF to completely turn off the function.
|
||||
|
||||
When building and applying Runtime Filters on different Fragments, the reasons and strategies for merging Runtime Filters can be found in [ISSUE 6116](https://github.com/apache/incubator-doris/issues/6116)
|
||||
|
||||
#### 3.runtime_filter_wait_time_ms
|
||||
Waiting for Runtime Filter is time consuming.
|
||||
|
||||
**Type**: integer, default 1000, unit ms
|
||||
|
||||
**Precautions for use**
|
||||
|
||||
After the Runtime Filter is turned on, the ScanNode in the table on the left will wait for a period of time for each Runtime Filter assigned to itself before scanning the data, that is, if the ScanNode is assigned 3 Runtime Filters, it will wait at most 3000ms.
|
||||
|
||||
Because it takes time to build and merge the Runtime Filter, ScanNode will try to push down the Runtime Filter that arrives within the waiting time to the storage engine. If the waiting time is exceeded, ScanNode will directly start scanning data using the Runtime Filter that has arrived.
|
||||
|
||||
If the Runtime Filter arrives after ScanNode starts scanning, ScanNode will not push the Runtime Filter down to the storage engine. Instead, it will use expression filtering on ScanNode based on the Runtime Filter for the data that has been scanned from the storage engine. The scanned data will not apply the Runtime Filter, so the intermediate data size obtained will be larger than the optimal solution, but serious cracking can be avoided.
|
||||
|
||||
If the cluster is busy and there are many resource-intensive or long-time-consuming queries on the cluster, consider increasing the waiting time to avoid missing optimization opportunities for complex queries. If the cluster load is light, and there are many small queries on the cluster that only take a few seconds, you can consider reducing the waiting time to avoid an increase of 1s for each query.
|
||||
|
||||
#### 4.runtime_filters_max_num
|
||||
The upper limit of the number of Bloom Filters in the Runtime Filter generated by each query.
|
||||
|
||||
**Type**: integer, default 10
|
||||
|
||||
**Precautions for use**
|
||||
Currently, only the number of Bloom Filters is limited, because the construction and application of Bloom Filters are more expensive than MinMax Filter and IN predicate.
|
||||
|
||||
If the number of Bloom Filters generated exceeds the maximum allowable number, then the Bloom Filter with a large selectivity is retained. A large selectivity means that more rows are expected to be filtered. This setting can prevent Bloom Filter from consuming too much memory overhead and causing potential problems.
|
||||
```
|
||||
Selectivity = (HashJoinNode Cardinality / HashJoinNode left child Cardinality)
|
||||
- Because the cardinality of FE is currently inaccurate, the selectivity of Bloom Filter calculation here is inaccurate, so in the end, it may only randomly reserve part of Bloom Filter.
|
||||
```
|
||||
This query option needs to be adjusted only when tuning some long-consuming queries involving joins between large tables.
|
||||
|
||||
#### 5. Bloom Filter length related parameters
|
||||
Including `runtime_bloom_filter_min_size`, `runtime_bloom_filter_max_size`, `runtime_bloom_filter_size`, used to determine the size (in bytes) of the Bloom Filter data structure used by the Runtime Filter.
|
||||
|
||||
**Type**: Integer
|
||||
|
||||
**Precautions for use**
|
||||
Because it is necessary to ensure that the length of the Bloom Filter constructed by each HashJoinNode is the same to be merged, the length of the Bloom Filter is currently calculated in the FE query planning.
|
||||
|
||||
If you can get the number of data rows (Cardinality) in the statistical information of the join right table, it will try to estimate the optimal size of the Bloom Filter based on Cardinality, and round to the nearest power of 2 (log value with the base 2). If the Cardinality of the table on the right cannot be obtained, the default Bloom Filter length `runtime_bloom_filter_size` will be used. `runtime_bloom_filter_min_size` and `runtime_bloom_filter_max_size` are used to limit the minimum and maximum length of the final Bloom Filter.
|
||||
|
||||
Larger Bloom Filters are more effective when processing high-cardinality input sets, but require more memory. If the query needs to filter high cardinality columns (for example, containing millions of different values), you can consider increasing the value of `runtime_bloom_filter_size` for some benchmark tests, which will help make the Bloom Filter filter more accurate, so as to obtain the expected Performance improvement.
|
||||
|
||||
The effectiveness of Bloom Filter depends on the data distribution of the query, so it is usually only for some specific queries to additionally adjust the length of the Bloom Filter, rather than global modification, generally only for some long time-consuming queries involving joins between large tables. Only when you need to adjust this query option.
|
||||
|
||||
### View Runtime Filter generated by query
|
||||
|
||||
The query plan that can be displayed by the `explain` command includes the join on clause information used by each Fragment, as well as comments on the generation and use of the Runtime Filter by the Fragment, so as to confirm whether the Runtime Filter is applied to the desired join on clause.
|
||||
- The comment contained in the Fragment that generates the Runtime Filter, such as `runtime filters: filter_id[type] <- table.column`.
|
||||
- Use the comment contained in the fragment of Runtime Filter such as `runtime filters: filter_id[type] -> table.column`.
|
||||
|
||||
The query in the following example uses a Runtime Filter with ID RF000.
|
||||
```
|
||||
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2 PROPERTIES("replication_num" = "1");
|
||||
INSERT INTO test VALUES (1), (2), (3), (4);
|
||||
|
||||
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2 PROPERTIES("replication_num" = "1");
|
||||
INSERT INTO test2 VALUES (3), (4), (5);
|
||||
|
||||
EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
|
||||
+-------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+-------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:`t1` |
|
||||
| |
|
||||
| 4:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: `default_cluster:ssb`.`test`.`t1` |
|
||||
| |
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
|
||||
| | equal join conjunct: `test`.`t1` = `test2`.`t2` |
|
||||
| | runtime filters: RF000[in] <- `test2`.`t2` |
|
||||
| | |
|
||||
| |----3:EXCHANGE |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: test |
|
||||
| runtime filters: RF000[in] -> `test`.`t1` |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: `default_cluster:ssb`.`test2`.`t2` |
|
||||
| |
|
||||
| 1:OlapScanNode |
|
||||
| TABLE: test2 |
|
||||
+-------------------------------------------------------------------+
|
||||
-- The line of `runtime filters` above shows that `2:HASH JOIN` of `PLAN FRAGMENT 1` generates IN predicate with ID RF000,
|
||||
-- Among them, the key values of `test2`.`t2` are only known at runtime,
|
||||
-- This IN predicate is used in `0:OlapScanNode` to filter unnecessary data when reading `test`.`t1`.
|
||||
|
||||
SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
|
||||
-- Return 2 rows of results [3, 4];
|
||||
|
||||
-- Through the query profile (set enable_profile=true;) you can view the detailed information of the internal work of the query,
|
||||
-- Including whether each Runtime Filter is pushed down, waiting time,
|
||||
-- and the total time from prepare to receiving Runtime Filter for OLAP_SCAN_NODE.
|
||||
RuntimeFilter:in:
|
||||
- HasPushDownToEngine: true
|
||||
- AWaitTimeCost: 0ns
|
||||
- EffectTimeCost: 2.76ms
|
||||
|
||||
-- In addition, in the OLAP_SCAN_NODE of the profile, you can also view the filtering effect
|
||||
-- and time consumption after the Runtime Filter is pushed down.
|
||||
- RowsVectorPredFiltered: 9.320008M (9320008)
|
||||
- VectorPredEvalTime: 364.39ms
|
||||
```
|
||||
|
||||
## Runtime Filter planning rules
|
||||
1. Only support the generation of Runtime Filter for the equivalent conditions in the join on clause, excluding the Null-safe condition, because it may filter out the null value of the join left table.
|
||||
2. Does not support pushing down Runtime Filter to the left table of left outer, full outer, and anti join;
|
||||
3. Does not support src expr or target expr is constant;
|
||||
4. The equality of src expr and target expr is not supported;
|
||||
5. The type of src expr is not supported to be equal to `HLL` or `BITMAP`;
|
||||
6. Currently only supports pushing down Runtime Filter to OlapScanNode;
|
||||
7. Target expr does not support NULL-checking expressions, such as `COALESCE/IFNULL/CASE`, because when the join on clause of other joins at the upper level of the outer join contains NULL-checking expressions and a Runtime Filter is generated, this Runtime Filter is downloaded Pushing to the left table of outer join may cause incorrect results;
|
||||
8. The column (slot) in target expr is not supported, and an equivalent column cannot be found in the original table;
|
||||
9. Column conduction is not supported. This includes two cases:
|
||||
- First, when the join on clause contains A.k = B.k and B.k = C.k, currently C.k can only be pushed down to B.k, but not to A.k;
|
||||
- Second, for example, the join on clause contains Aa + Bb = Cc. If Aa can be transmitted to Ba, that is, Aa and Ba are equivalent columns, then you can replace Aa with Ba, and then you can try to push the Runtime Filter down to B ( If Aa and Ba are not equivalent columns, they cannot be pushed down to B, because target expr must be bound to the only join left table);
|
||||
10. The types of Target expr and src expr must be equal, because Bloom Filter is based on hash, if the types are not equal, it will try to convert the type of target expr to the type of src expr;
|
||||
11. The Runtime Filter generated by `PlanNode.Conjuncts` is not supported. Unlike HashJoinNode's `eqJoinConjuncts` and `otherJoinConjuncts`, the Runtime Filter generated by `PlanNode.Conjuncts` found in the test that it may cause incorrect results, such as ` When an IN` subquery is converted to a join, the automatically generated join on clause will be stored in `PlanNode.Conjuncts`. At this time, applying Runtime Filter may result in missing some rows in the result.
|
||||
|
||||
@ -25,3 +25,217 @@ under the License.
|
||||
-->
|
||||
|
||||
# Schema Change
|
||||
|
||||
Users can modify the schema of existing tables through the Schema Change operation. Doris currently supports the following modifications:
|
||||
|
||||
* Add and delete columns
|
||||
* Modify column type
|
||||
* Adjust column order
|
||||
* Add and modify Bloom Filter
|
||||
* Add and delete bitmap index
|
||||
|
||||
This document mainly describes how to create a Schema Change job, as well as some considerations and frequently asked questions about Schema Change.
|
||||
## Glossary
|
||||
|
||||
* Base Table: When each table is created, it corresponds to a base table. The base table stores the complete data of this table. Rollups are usually created based on the data in the base table (and can also be created from other rollups).
|
||||
* Index: Materialized index. Rollup or Base Table are both called materialized indexes.
|
||||
* Transaction: Each import task is a transaction, and each transaction has a unique incrementing Transaction ID.
|
||||
* Rollup: Roll-up tables based on base tables or other rollups.
|
||||
|
||||
## Basic Principles
|
||||
|
||||
The basic process of executing a Schema Change is to generate a copy of the index data of the new schema from the data of the original index. Among them, two parts of data conversion are required. One is the conversion of existing historical data, and the other is the conversion of newly arrived imported data during the execution of Schema Change.
|
||||
```
|
||||
+----------+
|
||||
| Load Job |
|
||||
+----+-----+
|
||||
|
|
||||
| Load job generates both origin and new index data
|
||||
|
|
||||
| +------------------+ +---------------+
|
||||
| | Origin Index | | Origin Index |
|
||||
+------> New Incoming Data| | History Data |
|
||||
| +------------------+ +------+--------+
|
||||
| |
|
||||
| | Convert history data
|
||||
| |
|
||||
| +------------------+ +------v--------+
|
||||
| | New Index | | New Index |
|
||||
+------> New Incoming Data| | History Data |
|
||||
+------------------+ +---------------+
|
||||
```
|
||||
|
||||
Before starting the conversion of historical data, Doris will obtain a latest transaction ID. And wait for all import transactions before this Transaction ID to complete. This Transaction ID becomes a watershed. This means that Doris guarantees that all import tasks after the watershed will generate data for both the original Index and the new Index. In this way, when the historical data conversion is completed, the data in the new Index can be guaranteed to be complete.
|
||||
## Create Job
|
||||
|
||||
The specific syntax for creating a Schema Change can be found in the help [ALTER TABLE COLUMN](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md) for the description of the Schema Change section .
|
||||
|
||||
The creation of Schema Change is an asynchronous process. After the job is submitted successfully, the user needs to view the job progress through the `SHOW ALTER TABLE COLUMN` command.
|
||||
## View Job
|
||||
|
||||
`SHOW ALTER TABLE COLUMN` You can view the Schema Change jobs that are currently executing or completed. When multiple indexes are involved in a Schema Change job, the command displays multiple lines, each corresponding to an index. For example:
|
||||
|
||||
```sql
|
||||
mysql> SHOW ALTER TABLE COLUMN\G;
|
||||
*************************** 1. row ***************************
|
||||
JobId: 20021
|
||||
TableName: tbl1
|
||||
CreateTime: 2019-08-05 23:03:13
|
||||
FinishTime: 2019-08-05 23:03:42
|
||||
IndexName: tbl1
|
||||
IndexId: 20022
|
||||
OriginIndexId: 20017
|
||||
SchemaVersion: 2:792557838
|
||||
TransactionId: 10023
|
||||
State: FINISHED
|
||||
Msg:
|
||||
Progress: NULL
|
||||
Timeout: 86400
|
||||
1 row in set (0.00 sec)
|
||||
```
|
||||
|
||||
* JobId: A unique ID for each Schema Change job.
|
||||
* TableName: The table name of the base table corresponding to Schema Change.
|
||||
* CreateTime: Job creation time.
|
||||
* FinishedTime: The end time of the job. If it is not finished, "N / A" is displayed.
|
||||
* IndexName: The name of an Index involved in this modification.
|
||||
* IndexId: The unique ID of the new Index.
|
||||
* OriginIndexId: The unique ID of the old Index.
|
||||
* SchemaVersion: Displayed in M: N format. M is the version of this Schema Change, and N is the corresponding hash value. With each Schema Change, the version is incremented.
|
||||
* TransactionId: the watershed transaction ID of the conversion history data.
|
||||
* State: The phase of the operation.
|
||||
* PENDING: The job is waiting in the queue to be scheduled.
|
||||
* WAITING_TXN: Wait for the import task before the watershed transaction ID to complete.
|
||||
* RUNNING: Historical data conversion.
|
||||
* FINISHED: The operation was successful.
|
||||
* CANCELLED: The job failed.
|
||||
* Msg: If the job fails, a failure message is displayed here.
|
||||
* Progress: operation progress. Progress is displayed only in the RUNNING state. Progress is displayed in M / N. Where N is the total number of copies involved in the Schema Change. M is the number of copies of historical data conversion completed.
|
||||
* Timeout: Job timeout time. Unit of second.
|
||||
|
||||
## Cancel Job
|
||||
|
||||
In the case that the job status is not FINISHED or CANCELLED, you can cancel the Schema Change job with the following command:
|
||||
`CANCEL ALTER TABLE COLUMN FROM tbl_name;`
|
||||
|
||||
## Best Practice
|
||||
|
||||
Schema Change can make multiple changes to multiple indexes in one job. For example:
|
||||
Source Schema:
|
||||
|
||||
```
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| IndexName | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| tbl1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
| | k3 | INT | No | true | N/A | |
|
||||
| | | | | | | |
|
||||
| rollup2 | k2 | INT | No | true | N/A | |
|
||||
| | | | | | | |
|
||||
| rollup1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
```
|
||||
|
||||
You can add a row k4 to both rollup1 and rollup2 by adding the following k5 to rollup2:
|
||||
```
|
||||
ALTER TABLE tbl1
|
||||
ADD COLUMN k4 INT default "1" to rollup1,
|
||||
ADD COLUMN k4 INT default "1" to rollup2,
|
||||
ADD COLUMN k5 INT default "1" to rollup2;
|
||||
```
|
||||
|
||||
When completion, the Schema becomes:
|
||||
|
||||
```
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| IndexName | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| tbl1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
| | k3 | INT | No | true | N/A | |
|
||||
| | k4 | INT | No | true | 1 | |
|
||||
| | k5 | INT | No | true | 1 | |
|
||||
| | | | | | | |
|
||||
| rollup2 | k2 | INT | No | true | N/A | |
|
||||
| | k4 | INT | No | true | 1 | |
|
||||
| | k5 | INT | No | true | 1 | |
|
||||
| | | | | | | |
|
||||
| rollup1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
| | k4 | INT | No | true | 1 | |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
```
|
||||
|
||||
As you can see, the base table tbl1 also automatically added k4, k5 columns. That is, columns added to any rollup are automatically added to the Base table.
|
||||
|
||||
At the same time, columns that already exist in the Base table are not allowed to be added to Rollup. If you need to do this, you can re-create a Rollup with the new columns and then delete the original Rollup.
|
||||
## Notice
|
||||
|
||||
* Only one Schema Change job can be running on a table at a time.
|
||||
|
||||
* Schema Change operation does not block import and query operations.
|
||||
|
||||
* The partition column and bucket column cannot be modified.
|
||||
|
||||
* If there is a value column aggregated by REPLACE in the schema, the Key column is not allowed to be deleted.
|
||||
|
||||
If the Key column is deleted, Doris cannot determine the value of the REPLACE column.
|
||||
|
||||
All non-Key columns of the Unique data model table are REPLACE aggregated.
|
||||
|
||||
* When adding a value column whose aggregation type is SUM or REPLACE, the default value of this column has no meaning to historical data.
|
||||
|
||||
Because the historical data has lost the detailed information, the default value cannot actually reflect the aggregated value.
|
||||
|
||||
* When modifying the column type, fields other than Type need to be completed according to the information on the original column.
|
||||
|
||||
If you modify the column `k1 INT SUM NULL DEFAULT" 1 "` as type BIGINT, you need to execute the following command:
|
||||
|
||||
```ALTER TABLE tbl1 MODIFY COLUMN `k1` BIGINT SUM NULL DEFAULT "1"; ```
|
||||
|
||||
Note that in addition to the new column types, such as the aggregation mode, Nullable attributes, and default values must be completed according to the original information.
|
||||
|
||||
* Modifying column names, aggregation types, nullable attributes, default values, and column comments is not supported.
|
||||
|
||||
## FAQ
|
||||
|
||||
* the execution speed of Schema Change
|
||||
|
||||
At present, the execution speed of Schema Change is estimated to be about 10MB / s according to the worst efficiency. To be conservative, users can set the timeout for jobs based on this rate.
|
||||
|
||||
* Submit job error `Table xxx is not stable. ...`
|
||||
|
||||
Schema Change can only be started when the table data is complete and unbalanced. If some data shard copies of the table are incomplete, or if some copies are undergoing an equalization operation, the submission is rejected.
|
||||
|
||||
Whether the data shard copy is complete can be checked with the following command:
|
||||
```ADMIN SHOW REPLICA STATUS FROM tbl WHERE STATUS != "OK";```
|
||||
|
||||
If a result is returned, there is a problem with the copy. These problems are usually fixed automatically by the system. You can also use the following commands to repair this table first:
|
||||
```ADMIN REPAIR TABLE tbl1;```
|
||||
|
||||
You can check if there are running balancing tasks with the following command:
|
||||
|
||||
```SHOW PROC "/cluster_balance/pending_tablets";```
|
||||
|
||||
You can wait for the balancing task to complete, or temporarily disable the balancing operation with the following command:
|
||||
|
||||
```ADMIN SET FRONTEND CONFIG ("disable_balance" = "true");```
|
||||
|
||||
## Configurations
|
||||
|
||||
### FE Configurations
|
||||
|
||||
* `alter_table_timeout_second`: The default timeout for the job is 86400 seconds.
|
||||
|
||||
### BE Configurations
|
||||
|
||||
* `alter_tablet_worker_count`: Number of threads used to perform historical data conversion on the BE side. The default is 3. If you want to speed up the Schema Change job, you can increase this parameter appropriately and restart the BE. But too many conversion threads can cause increased IO pressure and affect other operations. This thread is shared with the Rollup job.
|
||||
|
||||
|
||||
|
||||
## More Help
|
||||
|
||||
For more detailed syntax and best practices used by Schema Change, see [ALTER TABLE COLUMN](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md ) command manual, you can also enter `HELP ALTER TABLE COLUMN` in the MySql client command line for more help information.
|
||||
|
||||
|
||||
@ -26,3 +26,107 @@ under the License.
|
||||
|
||||
# File Manager
|
||||
|
||||
Some functions in Doris require some user-defined files. For example, public keys, key files, certificate files and so on are used to access external data sources. The File Manager provides a function that allows users to upload these files in advance and save them in Doris system, which can then be referenced or accessed in other commands.
|
||||
|
||||
## Noun Interpretation
|
||||
|
||||
* BDBJE: Oracle Berkeley DB Java Edition. Distributed embedded database for persistent metadata in FE.
|
||||
* SmallFileMgr: File Manager. Responsible for creating and maintaining user files.
|
||||
|
||||
## Basic concepts
|
||||
|
||||
Files are files created and saved by users in Doris.
|
||||
|
||||
A file is located by `database`, `catalog`, `file_name`. At the same time, each file also has a globally unique ID (file_id), which serves as the identification in the system.
|
||||
|
||||
File creation and deletion can only be performed by users with `admin` privileges. A file belongs to a database. Users who have access to a database (queries, imports, modifications, etc.) can use the files created under the database.
|
||||
|
||||
## Specific operation
|
||||
|
||||
File management has three main commands: `CREATE FILE`, `SHOW FILE` and `DROP FILE`, creating, viewing and deleting files respectively. The specific syntax of these three commands can be viewed by connecting to Doris and executing `HELP cmd;`.
|
||||
|
||||
### CREATE FILE
|
||||
|
||||
This statement is used to create and upload a file to the Doris cluster. For details, see [CREATE FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-FILE.md).
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
1. Create file ca.pem , classified as kafka
|
||||
|
||||
CREATE FILE "ca.pem"
|
||||
PROPERTIES
|
||||
(
|
||||
"url" = "https://test.bj.bcebos.com/kafka-key/ca.pem",
|
||||
"catalog" = "kafka"
|
||||
);
|
||||
|
||||
2. Create a file client.key, classified as my_catalog
|
||||
|
||||
CREATE FILE "client.key"
|
||||
IN my_database
|
||||
PROPERTIES
|
||||
(
|
||||
"url" = "https://test.bj.bcebos.com/kafka-key/client.key",
|
||||
"catalog" = "my_catalog",
|
||||
"md5" = "b5bb901bf10f99205b39a46ac3557dd9"
|
||||
);
|
||||
```
|
||||
|
||||
### SHOW FILE
|
||||
|
||||
This statement can view the files that have been created successfully. For details, see [SHOW FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-FILE.md).
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
1. View uploaded files in database my_database
|
||||
|
||||
SHOW FILE FROM my_database;
|
||||
```
|
||||
|
||||
### DROP FILE
|
||||
|
||||
This statement can view and delete an already created file. For specific operations, see [DROP FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-FILE.md).
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
1. delete file ca.pem
|
||||
|
||||
DROP FILE "ca.pem" properties("catalog" = "kafka");
|
||||
```
|
||||
|
||||
## Implementation details
|
||||
|
||||
### Create and delete files
|
||||
|
||||
When the user executes the `CREATE FILE` command, FE downloads the file from a given URL. The contents of the file are stored in FE memory directly in the form of Base64 encoding. At the same time, the file content and meta-information related to the file will be persisted in BDBJE. All created files, their meta-information and file content reside in FE memory. If the FE goes down and restarts, meta information and file content will also be loaded into memory from the BDBJE. When a file is deleted, the relevant information is deleted directly from FE memory and persistent information is deleted from BDBJE.
|
||||
|
||||
### Use of documents
|
||||
|
||||
If the FE side needs to use the created file, SmallFileMgr will directly save the data in FE memory as a local file, store it in the specified directory, and return the local file path for use.
|
||||
|
||||
If the BE side needs to use the created file, BE will download the file content to the specified directory on BE through FE's HTTP interface `api/get_small_file` for use. At the same time, BE also records the information of the files that have been downloaded in memory. When BE requests a file, it first checks whether the local file exists and verifies it. If the validation passes, the local file path is returned directly. If the validation fails, the local file is deleted and downloaded from FE again. When BE restarts, local files are preloaded into memory.
|
||||
|
||||
## Use restrictions
|
||||
|
||||
Because the file meta-information and content are stored in FE memory. So by default, only files with size less than 1MB can be uploaded. And the total number of files is limited to 100. The configuration items described in the next section can be modified.
|
||||
|
||||
## Relevant configuration
|
||||
|
||||
1. FE configuration
|
||||
|
||||
* `Small_file_dir`: The path used to store uploaded files, defaulting to the `small_files/` directory of the FE runtime directory.
|
||||
* `max_small_file_size_bytes`: A single file size limit in bytes. The default is 1MB. File creation larger than this configuration will be rejected.
|
||||
* `max_small_file_number`: The total number of files supported by a Doris cluster. The default is 100. When the number of files created exceeds this value, subsequent creation will be rejected.
|
||||
|
||||
> If you need to upload more files or increase the size limit of a single file, you can modify the `max_small_file_size_bytes` and `max_small_file_number` parameters by using the `ADMIN SET CONFIG` command. However, the increase in the number and size of files will lead to an increase in FE memory usage.
|
||||
|
||||
2. BE configuration
|
||||
|
||||
* `Small_file_dir`: The path used to store files downloaded from FE by default is in the `lib/small_files/` directory of the BE runtime directory.
|
||||
|
||||
## More Help
|
||||
|
||||
For more detailed syntax and best practices used by the file manager, see [CREATE FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-FILE.html), [DROP FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-FILE.html) and [SHOW FILE](../sql-manual/sql-reference-v2 /Show-Statements/SHOW-FILE.md) command manual, you can also enter `HELP CREATE FILE`, `HELP DROP FILE` and `HELP SHOW FILE` in the MySql client command line to get more help information.
|
||||
|
||||
@ -24,4 +24,83 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Bucket Shuffle Join
|
||||
# Bucket Shuffle Join
|
||||
|
||||
Bucket Shuffle Join 是在 Doris 0.14 版本中正式加入的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
|
||||
|
||||
它的设计、实现和效果可以参阅 [ISSUE 4394](https://github.com/apache/incubator-doris/issues/4394)。
|
||||
|
||||
## 名词解释
|
||||
|
||||
- 左表:Join查询时,左边的表。进行Probe操作。可被Join Reorder调整顺序。
|
||||
- 右表:Join查询时,右边的表。进行Build操作。可被Join Reorder调整顺序。
|
||||
|
||||
## 原理
|
||||
|
||||
Doris支持的常规分布式Join方式包括了shuffle join 和broadcast join。这两种join都会导致不小的网络开销:
|
||||
|
||||
举个例子,当前存在A表与B表的Join查询,它的Join方式为HashJoin,不同Join类型的开销如下:
|
||||
|
||||
- **Broadcast Join**: 如果根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量的发送到3个HashJoinNode,那么它的网络开销是`3B`,它的内存开销也是`3B`。
|
||||
- **Shuffle Join**: Shuffle Join会将A,B两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为 `A + B`,内存开销为`B`。
|
||||
|
||||
在FE之中保存了Doris每个表的数据分布信息,如果join语句命中了表的数据分布列,我们应该使用数据分布信息来减少join语句的网络与内存开销,这就是Bucket Shuffle Join的思路来源。
|
||||
|
||||
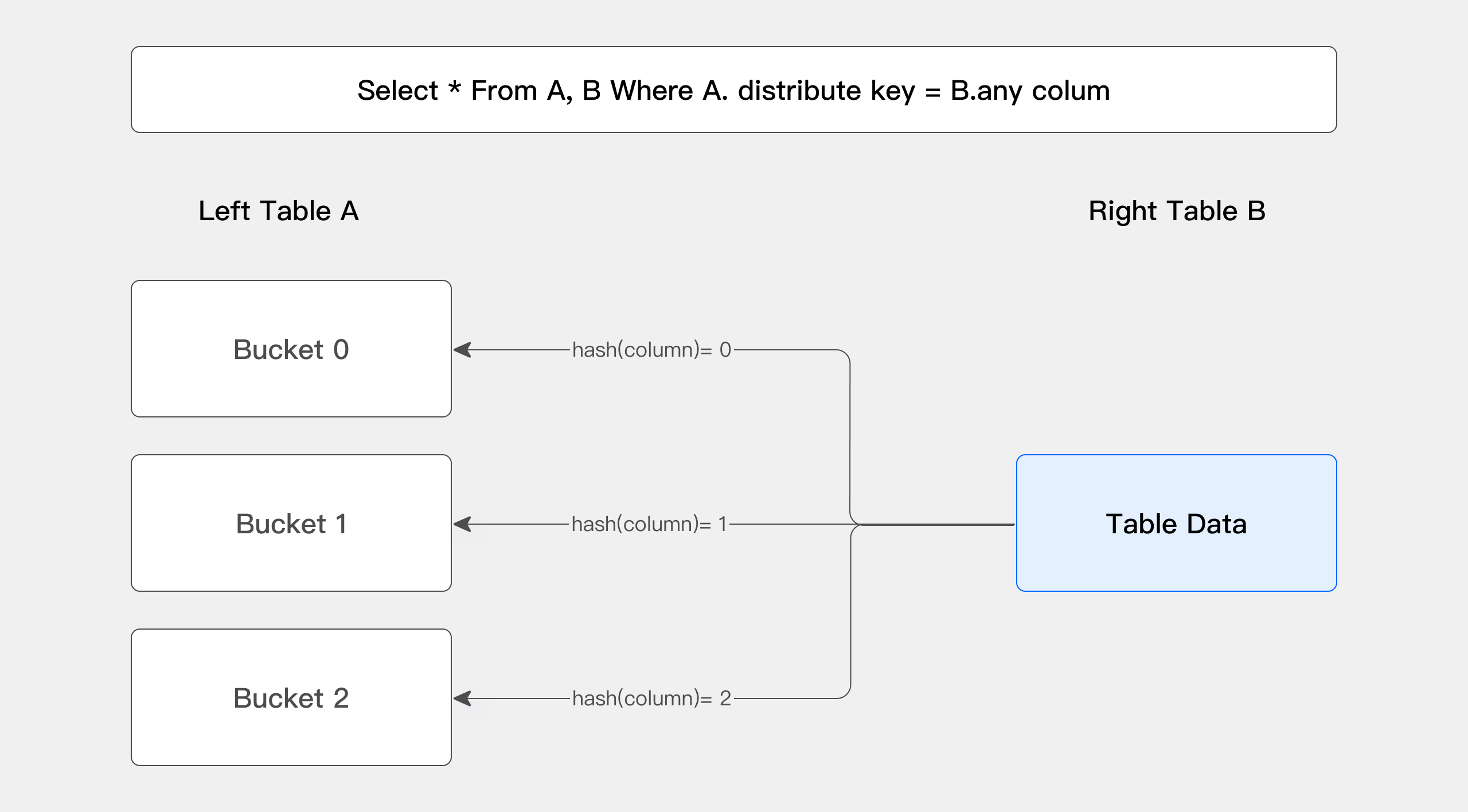
|
||||
|
||||
上面的图片展示了Bucket Shuffle Join的工作原理。SQL语句为 A表 join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储计算节点。Bucket Shuffle Join开销如下:
|
||||
|
||||
- 网络开销: `B < min(3B, A + B)`
|
||||
- 内存开销: `B <= min(3B, B)`
|
||||
|
||||
可见,相比于Broadcast Join与Shuffle Join, Bucket Shuffle Join有着较为明显的性能优势。减少数据在节点间的传输耗时和Join时的内存开销。相对于Doris原有的Join方式,它有着下面的优点
|
||||
|
||||
- 首先,Bucket-Shuffle-Join降低了网络与内存开销,使一些Join查询具有了更好的性能。尤其是当FE能够执行左表的分区裁剪与桶裁剪时。
|
||||
- 其次,同时与Colocate Join不同,它对于表的数据分布方式并没有侵入性,这对于用户来说是透明的。对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
|
||||
- 最后,它可以为Join Reorder提供更多可能的优化空间。
|
||||
|
||||
## 使用方式
|
||||
|
||||
### 设置Session变量
|
||||
|
||||
将session变量`enable_bucket_shuffle_join`设置为`true`,则FE在进行查询规划时就会默认将能够转换为Bucket Shuffle Join的查询自动规划为Bucket Shuffle Join。
|
||||
|
||||
```sql
|
||||
set enable_bucket_shuffle_join = true;
|
||||
```
|
||||
|
||||
在FE进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是如果用户显式hint了Join的类型,如:
|
||||
|
||||
```sql
|
||||
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
|
||||
```
|
||||
|
||||
则上述的选择优先顺序则不生效。
|
||||
|
||||
该session变量在0.14版本默认为`true`, 而0.13版本需要手动设置为`true`。
|
||||
|
||||
### 查看Join的类型
|
||||
|
||||
可以通过`explain`命令来查看Join是否为Bucket Shuffle Join:
|
||||
|
||||
```sql
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
|
||||
| | hash predicates: |
|
||||
| | colocate: false, reason: table not in the same group |
|
||||
| | equal join conjunct: `test`.`k1` = `baseall`.`k1`
|
||||
```
|
||||
|
||||
在Join类型之中会指明使用的Join方式为:`BUCKET_SHUFFLE`。
|
||||
|
||||
## Bucket Shuffle Join的规划规则
|
||||
|
||||
在绝大多数场景之中,用户只需要默认打开session变量的开关就可以透明的使用这种Join方式带来的性能提升,但是如果了解Bucket Shuffle Join的规划规则,可以帮助我们利用它写出更加高效的SQL。
|
||||
|
||||
- Bucket Shuffle Join只生效于Join条件为等值的场景,原因与Colocate Join类似,它们都依赖hash来计算确定的数据分布。
|
||||
- 在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join。
|
||||
- 由于不同的数据类型的hash值计算结果不同,所以Bucket Shuffle Join要求左表的分桶列的类型与右表等值join列的类型需要保持一致,否则无法进行对应的规划。
|
||||
- Bucket Shuffle Join只作用于Doris原生的OLAP表,对于ODBC,MySQL,ES等外表,当其作为左表时是无法规划生效的。
|
||||
- 对于分区表,由于每一个分区的数据分布规则可能不同,所以Bucket Shuffle Join只能保证左表为单分区时生效。所以在SQL执行之中,需要尽量使用`where`条件使分区裁剪的策略能够生效。
|
||||
- 假如左表为Colocate的表,那么它每个分区的数据分布规则是确定的,Bucket Shuffle Join能在Colocate表上表现更好。
|
||||
|
||||
|
||||
235
new-docs/zh-CN/advanced/cache/partition-cache.md
vendored
235
new-docs/zh-CN/advanced/cache/partition-cache.md
vendored
@ -24,4 +24,237 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 分区缓存
|
||||
# 分区缓存
|
||||
|
||||
## 需求场景
|
||||
|
||||
大部分数据分析场景是写少读多,数据写入一次,多次频繁读取,比如一张报表涉及的维度和指标,数据在凌晨一次性计算好,但每天有数百甚至数千次的页面访问,因此非常适合把结果集缓存起来。在数据分析或BI应用中,存在下面的业务场景:
|
||||
|
||||
- **高并发场景**,Doris可以较好的支持高并发,但单台服务器无法承载太高的QPS
|
||||
- **复杂图表的看板**,复杂的Dashboard或者大屏类应用,数据来自多张表,每个页面有数十个查询,虽然每个查询只有数十毫秒,但是总体查询时间会在数秒
|
||||
- **趋势分析**,给定日期范围的查询,指标按日显示,比如查询最近7天内的用户数的趋势,这类查询数据量大,查询范围广,查询时间往往需要数十秒
|
||||
- **用户重复查询**,如果产品没有防重刷机制,用户因手误或其他原因重复刷新页面,导致提交大量的重复的SQL
|
||||
|
||||
以上四种场景,在应用层的解决方案,把查询结果放到Redis中,周期性的更新缓存或者用户手工刷新缓存,但是这个方案有如下问题:
|
||||
|
||||
- **数据不一致**,无法感知数据的更新,导致用户经常看到旧的数据
|
||||
- **命中率低**,缓存整个查询结果,如果数据实时写入,缓存频繁失效,命中率低且系统负载较重
|
||||
- **额外成本**,引入外部缓存组件,会带来系统复杂度,增加额外成本
|
||||
|
||||
## 解决方案
|
||||
|
||||
本分区缓存策略可以解决上面的问题,优先保证数据一致性,在此基础上细化缓存粒度,提升命中率,因此有如下特点:
|
||||
|
||||
- 用户无需担心数据一致性,通过版本来控制缓存失效,缓存的数据和从BE中查询的数据是一致的
|
||||
- 没有额外的组件和成本,缓存结果存储在BE的内存中,用户可以根据需要调整缓存内存大小
|
||||
- 实现了两种缓存策略,SQLCache和PartitionCache,后者缓存粒度更细
|
||||
- 用一致性哈希解决BE节点上下线的问题,BE中的缓存算法是改进的LRU
|
||||
|
||||
## SQLCache
|
||||
|
||||
SQLCache按SQL的签名、查询的表的分区ID、分区最新版本来存储和获取缓存。三者组合确定一个缓存数据集,任何一个变化了,如SQL有变化,如查询字段或条件不一样,或数据更新后版本变化了,会导致命中不了缓存。
|
||||
|
||||
如果多张表Join,使用最近更新的分区ID和最新的版本号,如果其中一张表更新了,会导致分区ID或版本号不一样,也一样命中不了缓存。
|
||||
|
||||
SQLCache,更适合T+1更新的场景,凌晨数据更新,首次查询从BE中获取结果放入到缓存中,后续相同查询从缓存中获取。实时更新数据也可以使用,但是可能存在命中率低的问题,可以参考如下PartitionCache。
|
||||
|
||||
## PartitionCache
|
||||
|
||||
### 设计原理
|
||||
|
||||
1. SQL可以并行拆分,Q = Q1 ∪ Q2 ... ∪ Qn,R= R1 ∪ R2 ... ∪ Rn,Q为查询语句,R为结果集
|
||||
2. 拆分为只读分区和可更新分区,只读分区缓存,更新分区不缓存
|
||||
|
||||
如上,查询最近7天的每天用户数,如按日期分区,数据只写当天分区,当天之外的其他分区的数据,都是固定不变的,在相同的查询SQL下,查询某个不更新分区的指标都是固定的。如下,在2020-03-09当天查询前7天的用户数,2020-03-03至2020-03-07的数据来自缓存,2020-03-08第一次查询来自分区,后续的查询来自缓存,2020-03-09因为当天在不停写入,所以来自分区。
|
||||
|
||||
因此,查询N天的数据,数据更新最近的D天,每天只是日期范围不一样相似的查询,只需要查询D个分区即可,其他部分都来自缓存,可以有效降低集群负载,减少查询时间。
|
||||
|
||||
```sql
|
||||
MySQL [(none)]> SELECT eventdate,count(userid) FROM testdb.appevent WHERE eventdate>="2020-03-03" AND eventdate<="2020-03-09" GROUP BY eventdate ORDER BY eventdate;
|
||||
+------------+-----------------+
|
||||
| eventdate | count(`userid`) |
|
||||
+------------+-----------------+
|
||||
| 2020-03-03 | 15 |
|
||||
| 2020-03-04 | 20 |
|
||||
| 2020-03-05 | 25 |
|
||||
| 2020-03-06 | 30 |
|
||||
| 2020-03-07 | 35 |
|
||||
| 2020-03-08 | 40 | //第一次来自分区,后续来自缓存
|
||||
| 2020-03-09 | 25 | //来自分区
|
||||
+------------+-----------------+
|
||||
7 rows in set (0.02 sec)
|
||||
```
|
||||
|
||||
在PartitionCache中,缓存第一级Key是去掉了分区条件后的SQL的128位MD5签名,下面是改写后的待签名的SQL:
|
||||
|
||||
```sql
|
||||
SELECT eventdate,count(userid) FROM testdb.appevent GROUP BY eventdate ORDER BY eventdate;
|
||||
```
|
||||
|
||||
缓存的第二级Key是查询结果集的分区字段的内容,比如上面查询结果的eventdate列的内容,二级Key的附属信息是分区的版本号和版本更新时间。
|
||||
|
||||
下面演示上面SQL在2020-03-09当天第一次执行的流程:
|
||||
|
||||
1. 从缓存中获取数据
|
||||
|
||||
```text
|
||||
+------------+-----------------+
|
||||
| 2020-03-03 | 15 |
|
||||
| 2020-03-04 | 20 |
|
||||
| 2020-03-05 | 25 |
|
||||
| 2020-03-06 | 30 |
|
||||
| 2020-03-07 | 35 |
|
||||
+------------+-----------------+
|
||||
```
|
||||
|
||||
1. 从BE中获取数据的SQL和数据
|
||||
|
||||
```sql
|
||||
SELECT eventdate,count(userid) FROM testdb.appevent WHERE eventdate>="2020-03-08" AND eventdate<="2020-03-09" GROUP BY eventdate ORDER BY eventdate;
|
||||
|
||||
+------------+-----------------+
|
||||
| 2020-03-08 | 40 |
|
||||
+------------+-----------------+
|
||||
| 2020-03-09 | 25 |
|
||||
+------------+-----------------+
|
||||
```
|
||||
|
||||
1. 最后发送给终端的数据
|
||||
|
||||
```text
|
||||
+------------+-----------------+
|
||||
| eventdate | count(`userid`) |
|
||||
+------------+-----------------+
|
||||
| 2020-03-03 | 15 |
|
||||
| 2020-03-04 | 20 |
|
||||
| 2020-03-05 | 25 |
|
||||
| 2020-03-06 | 30 |
|
||||
| 2020-03-07 | 35 |
|
||||
| 2020-03-08 | 40 |
|
||||
| 2020-03-09 | 25 |
|
||||
+------------+-----------------+
|
||||
```
|
||||
|
||||
1. 发送给缓存的数据
|
||||
|
||||
```text
|
||||
+------------+-----------------+
|
||||
| 2020-03-08 | 40 |
|
||||
+------------+-----------------+
|
||||
```
|
||||
|
||||
Partition缓存,适合按日期分区,部分分区实时更新,查询SQL较为固定。
|
||||
|
||||
分区字段也可以是其他字段,但是需要保证只有少量分区更新。
|
||||
|
||||
### 一些限制
|
||||
|
||||
- 只支持OlapTable,其他存储如MySQL的表没有版本信息,无法感知数据是否更新
|
||||
- 只支持按分区字段分组,不支持按其他字段分组,按其他字段分组,该分组数据都有可能被更新,会导致缓存都失效
|
||||
- 只支持结果集的前半部分、后半部分以及全部命中缓存,不支持结果集被缓存数据分割成几个部分
|
||||
|
||||
## 使用方式
|
||||
|
||||
### 开启SQLCache
|
||||
|
||||
确保fe.conf的cache_enable_sql_mode=true(默认是true)
|
||||
|
||||
```text
|
||||
vim fe/conf/fe.conf
|
||||
cache_enable_sql_mode=true
|
||||
```
|
||||
|
||||
在MySQL命令行中设置变量
|
||||
|
||||
```sql
|
||||
MySQL [(none)]> set [global] enable_sql_cache=true;
|
||||
```
|
||||
|
||||
注:global是全局变量,不加指当前会话变量
|
||||
|
||||
### 开启PartitionCache
|
||||
|
||||
确保fe.conf的cache_enable_partition_mode=true(默认是true)
|
||||
|
||||
```text
|
||||
vim fe/conf/fe.conf
|
||||
cache_enable_partition_mode=true
|
||||
```
|
||||
|
||||
在MySQL命令行中设置变量
|
||||
|
||||
```sql
|
||||
MySQL [(none)]> set [global] enable_partition_cache=true;
|
||||
```
|
||||
|
||||
如果同时开启了两个缓存策略,下面的参数,需要注意一下:
|
||||
|
||||
```text
|
||||
cache_last_version_interval_second=900
|
||||
```
|
||||
|
||||
如果分区的最新版本的时间离现在的间隔,大于cache_last_version_interval_second,则会优先把整个查询结果缓存。如果小于这个间隔,如果符合PartitionCache的条件,则按PartitionCache数据。
|
||||
|
||||
### 监控
|
||||
|
||||
FE的监控项:
|
||||
|
||||
```text
|
||||
query_table //Query中有表的数量
|
||||
query_olap_table //Query中有Olap表的数量
|
||||
cache_mode_sql //识别缓存模式为sql的Query数量
|
||||
cache_hit_sql //模式为sql的Query命中Cache的数量
|
||||
query_mode_partition //识别缓存模式为Partition的Query数量
|
||||
cache_hit_partition //通过Partition命中的Query数量
|
||||
partition_all //Query中扫描的所有分区
|
||||
partition_hit //通过Cache命中的分区数量
|
||||
|
||||
Cache命中率 = (cache_hit_sql + cache_hit_partition) / query_olap_table
|
||||
Partition命中率 = partition_hit / partition_all
|
||||
```
|
||||
|
||||
BE的监控项:
|
||||
|
||||
```text
|
||||
query_cache_memory_total_byte //Cache内存大小
|
||||
query_query_cache_sql_total_count //Cache的SQL的数量
|
||||
query_cache_partition_total_count //Cache分区数量
|
||||
|
||||
SQL平均数据大小 = cache_memory_total / cache_sql_total
|
||||
Partition平均数据大小 = cache_memory_total / cache_partition_total
|
||||
```
|
||||
|
||||
其他监控: 可以从Grafana中查看BE节点的CPU和内存指标,Query统计中的Query Percentile等指标,配合Cache参数的调整来达成业务目标。
|
||||
|
||||
### 优化参数
|
||||
|
||||
FE的配置项cache_result_max_row_count,查询结果集放入缓存的最大行数,可以根据实际情况调整,但建议不要设置过大,避免过多占用内存,超过这个大小的结果集不会被缓存。
|
||||
|
||||
```text
|
||||
vim fe/conf/fe.conf
|
||||
cache_result_max_row_count=3000
|
||||
```
|
||||
|
||||
BE最大分区数量cache_max_partition_count,指每个SQL对应的最大分区数,如果是按日期分区,能缓存2年多的数据,假如想保留更长时间的缓存,请把这个参数设置得更大,同时修改cache_result_max_row_count的参数。
|
||||
|
||||
```text
|
||||
vim be/conf/be.conf
|
||||
cache_max_partition_count=1024
|
||||
```
|
||||
|
||||
BE中缓存内存设置,有两个参数query_cache_max_size和query_cache_elasticity_size两部分组成(单位MB),内存超过query_cache_max_size + cache_elasticity_size会开始清理,并把内存控制到query_cache_max_size以下。可以根据BE节点数量,节点内存大小,和缓存命中率来设置这两个参数。
|
||||
|
||||
```text
|
||||
query_cache_max_size_mb=256
|
||||
query_cache_elasticity_size_mb=128
|
||||
```
|
||||
|
||||
计算方法:
|
||||
|
||||
假如缓存10K个Query,每个Query缓存1000行,每行是128个字节,分布在10台BE上,则每个BE需要128M内存(10K*1000*128/10)。
|
||||
|
||||
## 未尽事项
|
||||
|
||||
- T+1的数据,是否也可以用Partition缓存? 目前不支持
|
||||
- 类似的SQL,之前查询了2个指标,现在查询3个指标,是否可以利用2个指标的缓存? 目前不支持
|
||||
- 按日期分区,但是需要按周维度汇总数据,是否可用PartitionCache? 目前不支持
|
||||
26
new-docs/zh-CN/advanced/cache/query-cache.md
vendored
26
new-docs/zh-CN/advanced/cache/query-cache.md
vendored
@ -1,26 +0,0 @@
|
||||
---
|
||||
{
|
||||
"title": "查询缓存",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
# 查询缓存
|
||||
@ -24,4 +24,388 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Colocation Join
|
||||
# Colocation Join
|
||||
|
||||
Colocation Join 是在 Doris 0.9 版本中引入的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,加速查询。
|
||||
|
||||
最初的设计、实现和效果可以参阅 [ISSUE 245](https://github.com/apache/incubator-doris/issues/245)。
|
||||
|
||||
Colocation Join 功能经过一次改版,设计和使用方式和最初设计稍有不同。本文档主要介绍 Colocation Join 的原理、实现、使用方式和注意事项。
|
||||
|
||||
## 名词解释
|
||||
|
||||
- Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布。
|
||||
- Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及副本数等。
|
||||
|
||||
## 原理
|
||||
|
||||
Colocation Join 功能,是将一组拥有相同 CGS 的 Table 组成一个 CG。并保证这些 Table 对应的数据分片会落在同一个 BE 节点上。使得当 CG 内的表进行分桶列上的 Join 操作时,可以通过直接进行本地数据 Join,减少数据在节点间的传输耗时。
|
||||
|
||||
一个表的数据,最终会根据分桶列值 Hash、对桶数取模的后落在某一个分桶内。假设一个 Table 的分桶数为 8,则共有 `[0, 1, 2, 3, 4, 5, 6, 7]` 8 个分桶(Bucket),我们称这样一个序列为一个 `BucketsSequence`。每个 Bucket 内会有一个或多个数据分片(Tablet)。当表为单分区表时,一个 Bucket 内仅有一个 Tablet。如果是多分区表,则会有多个。
|
||||
|
||||
为了使得 Table 能够有相同的数据分布,同一 CG 内的 Table 必须保证以下属性相同:
|
||||
|
||||
1. 分桶列和分桶数
|
||||
|
||||
分桶列,即在建表语句中 `DISTRIBUTED BY HASH(col1, col2, ...)` 中指定的列。分桶列决定了一张表的数据通过哪些列的值进行 Hash 划分到不同的 Tablet 中。同一 CG 内的 Table 必须保证分桶列的类型和数量完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
|
||||
|
||||
2. 副本数
|
||||
|
||||
同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
|
||||
|
||||
同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
|
||||
|
||||
在固定了分桶列和分桶数后,同一个 CG 内的表会拥有相同的 BucketsSequence。而副本数决定了每个分桶内的 Tablet 的多个副本,存放在哪些 BE 上。假设 BucketsSequence 为 `[0, 1, 2, 3, 4, 5, 6, 7]`,BE 节点有 `[A, B, C, D]` 4个。则一个可能的数据分布如下:
|
||||
|
||||
```text
|
||||
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
|
||||
| 0 | | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 |
|
||||
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
|
||||
| A | | B | | C | | D | | A | | B | | C | | D |
|
||||
| | | | | | | | | | | | | | | |
|
||||
| B | | C | | D | | A | | B | | C | | D | | A |
|
||||
| | | | | | | | | | | | | | | |
|
||||
| C | | D | | A | | B | | C | | D | | A | | B |
|
||||
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
|
||||
```
|
||||
|
||||
CG 内所有表的数据都会按照上面的规则进行统一分布,这样就保证了,分桶列值相同的数据都在同一个 BE 节点上,可以进行本地数据 Join。
|
||||
|
||||
## 使用方式
|
||||
|
||||
### 建表
|
||||
|
||||
建表时,可以在 `PROPERTIES` 中指定属性 `"colocate_with" = "group_name"`,表示这个表是一个 Colocation Join 表,并且归属于一个指定的 Colocation Group。
|
||||
|
||||
示例:
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl (k1 int, v1 int sum)
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
BUCKETS 8
|
||||
PROPERTIES(
|
||||
"colocate_with" = "group1"
|
||||
);
|
||||
```
|
||||
|
||||
如果指定的 Group 不存在,则 Doris 会自动创建一个只包含当前这张表的 Group。如果 Group 已存在,则 Doris 会检查当前表是否满足 Colocation Group Schema。如果满足,则会创建该表,并将该表加入 Group。同时,表会根据已存在的 Group 中的数据分布规则创建分片和副本。 Group 归属于一个 Database,Group 的名字在一个 Database 内唯一。在内部存储是 Group 的全名为 `dbId_groupName`,但用户只感知 groupName。
|
||||
|
||||
### 删表
|
||||
|
||||
当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过 `DROP TABLE` 命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除。
|
||||
|
||||
### 查看 Group
|
||||
|
||||
以下命令可以查看集群内已存在的 Group 信息。
|
||||
|
||||
```sql
|
||||
SHOW PROC '/colocation_group';
|
||||
|
||||
+-------------+--------------+--------------+------------+----------------+----------+----------+
|
||||
| GroupId | GroupName | TableIds | BucketsNum | ReplicationNum | DistCols | IsStable |
|
||||
+-------------+--------------+--------------+------------+----------------+----------+----------+
|
||||
| 10005.10008 | 10005_group1 | 10007, 10040 | 10 | 3 | int(11) | true |
|
||||
+-------------+--------------+--------------+------------+----------------+----------+----------+
|
||||
```
|
||||
|
||||
- GroupId: 一个 Group 的全集群唯一标识,前半部分为 db id,后半部分为 group id。
|
||||
- GroupName: Group 的全名。
|
||||
- TabletIds: 该 Group 包含的 Table 的 id 列表。
|
||||
- BucketsNum: 分桶数。
|
||||
- ReplicationNum: 副本数。
|
||||
- DistCols: Distribution columns,即分桶列类型。
|
||||
- IsStable: 该 Group 是否稳定(稳定的定义,见 `Colocation 副本均衡和修复` 一节)。
|
||||
|
||||
通过以下命令可以进一步查看一个 Group 的数据分布情况:
|
||||
|
||||
```sql
|
||||
SHOW PROC '/colocation_group/10005.10008';
|
||||
|
||||
+-------------+---------------------+
|
||||
| BucketIndex | BackendIds |
|
||||
+-------------+---------------------+
|
||||
| 0 | 10004, 10002, 10001 |
|
||||
| 1 | 10003, 10002, 10004 |
|
||||
| 2 | 10002, 10004, 10001 |
|
||||
| 3 | 10003, 10002, 10004 |
|
||||
| 4 | 10002, 10004, 10003 |
|
||||
| 5 | 10003, 10002, 10001 |
|
||||
| 6 | 10003, 10004, 10001 |
|
||||
| 7 | 10003, 10004, 10002 |
|
||||
+-------------+---------------------+
|
||||
```
|
||||
|
||||
- BucketIndex: 分桶序列的下标。
|
||||
- BackendIds: 分桶中数据分片所在的 BE 节点 id 列表。
|
||||
|
||||
> 以上命令需要 ADMIN 权限。暂不支持普通用户查看。
|
||||
|
||||
### 修改表 Colocate Group 属性
|
||||
|
||||
可以对一个已经创建的表,修改其 Colocation Group 属性。示例:
|
||||
|
||||
```sql
|
||||
ALTER TABLE tbl SET ("colocate_with" = "group2");
|
||||
```
|
||||
|
||||
- 如果该表之前没有指定过 Group,则该命令检查 Schema,并将该表加入到该 Group(Group 不存在则会创建)。
|
||||
- 如果该表之前有指定其他 Group,则该命令会先将该表从原有 Group 中移除,并加入新 Group(Group 不存在则会创建)。
|
||||
|
||||
也可以通过以下命令,删除一个表的 Colocation 属性:
|
||||
|
||||
```sql
|
||||
ALTER TABLE tbl SET ("colocate_with" = "");
|
||||
```
|
||||
|
||||
### 其他相关操作
|
||||
|
||||
当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。
|
||||
|
||||
## Colocation 副本均衡和修复
|
||||
|
||||
Colocation 表的副本分布需要遵循 Group 中指定的分布,所以在副本修复和均衡方面和普通分片有所区别。
|
||||
|
||||
Group 自身有一个 Stable 属性,当 Stable 为 true 时,表示当前 Group 内的表的所有分片没有正在进行变动,Colocation 特性可以正常使用。当 Stable 为 false 时(Unstable),表示当前 Group 内有部分表的分片正在做修复或迁移,此时,相关表的 Colocation Join 将退化为普通 Join。
|
||||
|
||||
### 副本修复
|
||||
|
||||
副本只能存储在指定的 BE 节点上。所以当某个 BE 不可用时(宕机、Decommission 等),需要寻找一个新的 BE 进行替换。Doris 会优先寻找负载最低的 BE 进行替换。替换后,该 Bucket 内的所有在旧 BE 上的数据分片都要做修复。迁移过程中,Group 被标记为 Unstable。
|
||||
|
||||
### 副本均衡
|
||||
|
||||
Doris 会尽力将 Colocation 表的分片均匀分布在所有 BE 节点上。对于普通表的副本均衡,是以单副本为粒度的,即单独为每一个副本寻找负载较低的 BE 节点即可。而 Colocation 表的均衡是 Bucket 级别的,即一个 Bucket 内的所有副本都会一起迁移。我们采用一个简单的均衡算法,即在不考虑副本实际大小,而只根据副本数量,将 BucketsSequence 均匀的分布在所有 BE 上。具体算法可以参阅 `ColocateTableBalancer.java` 中的代码注释。
|
||||
|
||||
> 注1:当前的 Colocation 副本均衡和修复算法,对于异构部署的 Doris 集群效果可能不佳。所谓异构部署,即 BE 节点的磁盘容量、数量、磁盘类型(SSD 和 HDD)不一致。在异构部署情况下,可能出现小容量的 BE 节点和大容量的 BE 节点存储了相同的副本数量。
|
||||
>
|
||||
> 注2:当一个 Group 处于 Unstable 状态时,其中的表的 Join 将退化为普通 Join。此时可能会极大降低集群的查询性能。如果不希望系统自动均衡,可以设置 FE 的配置项 `disable_colocate_balance` 来禁止自动均衡。然后在合适的时间打开即可。(具体参阅 `高级操作` 一节)
|
||||
|
||||
## 查询
|
||||
|
||||
对 Colocation 表的查询方式和普通表一样,用户无需感知 Colocation 属性。如果 Colocation 表所在的 Group 处于 Unstable 状态,将自动退化为普通 Join。
|
||||
|
||||
举例说明:
|
||||
|
||||
表1:
|
||||
|
||||
```sql
|
||||
CREATE TABLE `tbl1` (
|
||||
`k1` date NOT NULL COMMENT "",
|
||||
`k2` int(11) NOT NULL COMMENT "",
|
||||
`v1` int(11) SUM NOT NULL COMMENT ""
|
||||
) ENGINE=OLAP
|
||||
AGGREGATE KEY(`k1`, `k2`)
|
||||
PARTITION BY RANGE(`k1`)
|
||||
(
|
||||
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
|
||||
PARTITION p2 VALUES LESS THAN ('2019-06-30')
|
||||
)
|
||||
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
|
||||
PROPERTIES (
|
||||
"colocate_with" = "group1"
|
||||
);
|
||||
```
|
||||
|
||||
表2:
|
||||
|
||||
```sql
|
||||
CREATE TABLE `tbl2` (
|
||||
`k1` datetime NOT NULL COMMENT "",
|
||||
`k2` int(11) NOT NULL COMMENT "",
|
||||
`v1` double SUM NOT NULL COMMENT ""
|
||||
) ENGINE=OLAP
|
||||
AGGREGATE KEY(`k1`, `k2`)
|
||||
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
|
||||
PROPERTIES (
|
||||
"colocate_with" = "group1"
|
||||
);
|
||||
```
|
||||
|
||||
查看查询计划:
|
||||
|
||||
```sql
|
||||
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);
|
||||
|
||||
+----------------------------------------------------+
|
||||
| Explain String |
|
||||
+----------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:`tbl1`.`k1` | |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN |
|
||||
| | hash predicates: |
|
||||
| | colocate: true |
|
||||
| | `tbl1`.`k2` = `tbl2`.`k2` |
|
||||
| | tuple ids: 0 1 |
|
||||
| | |
|
||||
| |----1:OlapScanNode |
|
||||
| | TABLE: tbl2 |
|
||||
| | PREAGGREGATION: OFF. Reason: null |
|
||||
| | partitions=0/1 |
|
||||
| | rollup: null |
|
||||
| | buckets=0/0 |
|
||||
| | cardinality=-1 |
|
||||
| | avgRowSize=0.0 |
|
||||
| | numNodes=0 |
|
||||
| | tuple ids: 1 |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: tbl1 |
|
||||
| PREAGGREGATION: OFF. Reason: No AggregateInfo |
|
||||
| partitions=0/2 |
|
||||
| rollup: null |
|
||||
| buckets=0/0 |
|
||||
| cardinality=-1 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=0 |
|
||||
| tuple ids: 0 |
|
||||
+----------------------------------------------------+
|
||||
```
|
||||
|
||||
如果 Colocation Join 生效,则 Hash Join 节点会显示 `colocate: true`。
|
||||
|
||||
如果没有生效,则查询计划如下:
|
||||
|
||||
```sql
|
||||
+----------------------------------------------------+
|
||||
| Explain String |
|
||||
+----------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:`tbl1`.`k1` | |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN (BROADCAST) |
|
||||
| | hash predicates: |
|
||||
| | colocate: false, reason: group is not stable |
|
||||
| | `tbl1`.`k2` = `tbl2`.`k2` |
|
||||
| | tuple ids: 0 1 |
|
||||
| | |
|
||||
| |----3:EXCHANGE |
|
||||
| | tuple ids: 1 |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: tbl1 |
|
||||
| PREAGGREGATION: OFF. Reason: No AggregateInfo |
|
||||
| partitions=0/2 |
|
||||
| rollup: null |
|
||||
| buckets=0/0 |
|
||||
| cardinality=-1 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=0 |
|
||||
| tuple ids: 0 |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 03 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 1:OlapScanNode |
|
||||
| TABLE: tbl2 |
|
||||
| PREAGGREGATION: OFF. Reason: null |
|
||||
| partitions=0/1 |
|
||||
| rollup: null |
|
||||
| buckets=0/0 |
|
||||
| cardinality=-1 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=0 |
|
||||
| tuple ids: 1 |
|
||||
+----------------------------------------------------+
|
||||
```
|
||||
|
||||
HASH JOIN 节点会显示对应原因:`colocate: false, reason: group is not stable`。同时会有一个 EXCHANGE 节点生成。
|
||||
|
||||
## 高级操作
|
||||
|
||||
### FE 配置项
|
||||
|
||||
- disable_colocate_relocate
|
||||
|
||||
是否关闭 Doris 的自动 Colocation 副本修复。默认为 false,即不关闭。该参数只影响 Colocation 表的副本修复,不影响普通表。
|
||||
|
||||
- disable_colocate_balance
|
||||
|
||||
是否关闭 Doris 的自动 Colocation 副本均衡。默认为 false,即不关闭。该参数只影响 Colocation 表的副本均衡,不影响普通表。
|
||||
|
||||
以上参数可以动态修改,设置方式请参阅 `HELP ADMIN SHOW CONFIG;` 和 `HELP ADMIN SET CONFIG;`。
|
||||
|
||||
- disable_colocate_join
|
||||
|
||||
是否关闭 Colocation Join 功能。在 0.10 及之前的版本,默认为 true,即关闭。在之后的某个版本中将默认为 false,即开启。
|
||||
|
||||
- use_new_tablet_scheduler
|
||||
|
||||
在 0.10 及之前的版本中,新的副本调度逻辑与 Colocation Join 功能不兼容,所以在 0.10 及之前版本,如果 `disable_colocate_join = false`,则需设置 `use_new_tablet_scheduler = false`,即关闭新的副本调度器。之后的版本中,`use_new_tablet_scheduler` 将衡为 true。
|
||||
|
||||
### HTTP Restful API
|
||||
|
||||
Doris 提供了几个和 Colocation Join 有关的 HTTP Restful API,用于查看和修改 Colocation Group。
|
||||
|
||||
该 API 实现在 FE 端,使用 `fe_host:fe_http_port` 进行访问。需要 ADMIN 权限。
|
||||
|
||||
1. 查看集群的全部 Colocation 信息
|
||||
|
||||
```text
|
||||
GET /api/colocate
|
||||
|
||||
返回以 Json 格式表示内部 Colocation 信息。
|
||||
|
||||
{
|
||||
"msg": "success",
|
||||
"code": 0,
|
||||
"data": {
|
||||
"infos": [
|
||||
["10003.12002", "10003_group1", "10037, 10043", "1", "1", "int(11)", "true"]
|
||||
],
|
||||
"unstableGroupIds": [],
|
||||
"allGroupIds": [{
|
||||
"dbId": 10003,
|
||||
"grpId": 12002
|
||||
}]
|
||||
},
|
||||
"count": 0
|
||||
}
|
||||
```
|
||||
|
||||
2. 将 Group 标记为 Stable 或 Unstable
|
||||
|
||||
- 标记为 Stable
|
||||
|
||||
```text
|
||||
POST /api/colocate/group_stable?db_id=10005&group_id=10008
|
||||
|
||||
返回:200
|
||||
```
|
||||
|
||||
- 标记为 Unstable
|
||||
|
||||
```text
|
||||
DELETE /api/colocate/group_stable?db_id=10005&group_id=10008
|
||||
|
||||
返回:200
|
||||
```
|
||||
|
||||
3. 设置 Group 的数据分布
|
||||
|
||||
该接口可以强制设置某一 Group 的数分布。
|
||||
|
||||
```text
|
||||
POST /api/colocate/bucketseq?db_id=10005&group_id=10008
|
||||
|
||||
Body:
|
||||
[[10004,10002],[10003,10002],[10002,10004],[10003,10002],[10002,10004],[10003,10002],[10003,10004],[10003,10004],[10003,10004],[10002,10004]]
|
||||
|
||||
返回 200
|
||||
```
|
||||
|
||||
其中 Body 是以嵌套数组表示的 BucketsSequence 以及每个 Bucket 中分片分布所在 BE 的 id。
|
||||
|
||||
注意,使用该命令,可能需要将 FE 的配置 `disable_colocate_relocate` 和 `disable_colocate_balance` 设为 true。即关闭系统自动的 Colocation 副本修复和均衡。否则可能在修改后,会被系统自动重置。
|
||||
@ -24,4 +24,464 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 物化视图
|
||||
# 物化视图
|
||||
|
||||
物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表。
|
||||
|
||||
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
|
||||
|
||||
## 适用场景
|
||||
|
||||
- 分析需求覆盖明细数据查询以及固定维度查询两方面。
|
||||
- 查询仅涉及表中的很小一部分列或行。
|
||||
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
|
||||
- 查询需要匹配不同前缀索引。
|
||||
|
||||
## 优势
|
||||
|
||||
- 对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。
|
||||
- Doris自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证base 表和物化视图表的数据一致性。无需任何额外的人工维护成本。
|
||||
- 查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。
|
||||
|
||||
*自动维护物化视图的数据会造成一些维护开销,会在后面的物化视图的局限性中展开说明。*
|
||||
|
||||
## 物化视图 VS Rollup
|
||||
|
||||
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
|
||||
|
||||
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是 Rollup 的一个超集。
|
||||
|
||||
也就是说,之前 [ALTER TABLE ADD ROLLUP](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-ROLLUP.md) 语法支持的功能现在均可以通过 [CREATE MATERIALIZED VIEW](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-MATERIALIZED-VIEW.md) 实现。
|
||||
|
||||
## 使用物化视图
|
||||
|
||||
Doris 系统提供了一整套对物化视图的 DDL 语法,包括创建,查看,删除。DDL 的语法和 PostgreSQL, Oracle都是一致的。
|
||||
|
||||
### 创建物化视图
|
||||
|
||||
这里首先你要根据你的查询语句的特点来决定创建一个什么样的物化视图。这里并不是说你的物化视图定义和你的某个查询语句一模一样就最好。这里有两个原则:
|
||||
|
||||
1. 从查询语句中**抽象**出,多个查询共有的分组和聚合方式作为物化视图的定义。
|
||||
2. 不需要给所有维度组合都创建物化视图。
|
||||
|
||||
首先第一个点,一个物化视图如果抽象出来,并且多个查询都可以匹配到这张物化视图。这种物化视图效果最好。因为物化视图的维护本身也需要消耗资源。
|
||||
|
||||
如果物化视图只和某个特殊的查询很贴合,而其他查询均用不到这个物化视图。则会导致这张物化视图的性价比不高,既占用了集群的存储资源,还不能为更多的查询服务。
|
||||
|
||||
所以用户需要结合自己的查询语句,以及数据维度信息去抽象出一些物化视图的定义。
|
||||
|
||||
第二点就是,在实际的分析查询中,并不会覆盖到所有的维度分析。所以给常用的维度组合创建物化视图即可,从而到达一个空间和时间上的平衡。
|
||||
|
||||
创建物化视图是一个异步的操作,也就是说用户成功提交创建任务后,Doris 会在后台对存量的数据进行计算,直到创建成功。
|
||||
|
||||
具体的语法可查看[CREATE MATERIALIZED VIEW](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-MATERIALIZED-VIEW.html) 。
|
||||
|
||||
### 支持聚合函数
|
||||
|
||||
目前物化视图创建语句支持的聚合函数有:
|
||||
|
||||
- SUM, MIN, MAX (Version 0.12)
|
||||
- COUNT, BITMAP_UNION, HLL_UNION (Version 0.13)
|
||||
- BITMAP_UNION 的形式必须为:`BITMAP_UNION(TO_BITMAP(COLUMN))` column 列的类型只能是整数(largeint也不支持), 或者 `BITMAP_UNION(COLUMN)` 且 base 表为 AGG 模型。
|
||||
- HLL_UNION 的形式必须为:`HLL_UNION(HLL_HASH(COLUMN))` column 列的类型不能是 DECIMAL , 或者 `HLL_UNION(COLUMN)` 且 base 表为 AGG 模型。
|
||||
|
||||
### 更新策略
|
||||
|
||||
为保证物化视图表和 Base 表的数据一致性, Doris 会将导入,删除等对 base 表的操作都同步到物化视图表中。并且通过增量更新的方式来提升更新效率。通过事务方式来保证原子性。
|
||||
|
||||
比如如果用户通过 INSERT 命令插入数据到 base 表中,则这条数据会同步插入到物化视图中。当 base 表和物化视图表均写入成功后,INSERT 命令才会成功返回。
|
||||
|
||||
### 查询自动匹配
|
||||
|
||||
物化视图创建成功后,用户的查询不需要发生任何改变,也就是还是查询的 base 表。Doris 会根据当前查询的语句去自动选择一个最优的物化视图,从物化视图中读取数据并计算。
|
||||
|
||||
用户可以通过 EXPLAIN 命令来检查当前查询是否使用了物化视图。
|
||||
|
||||
物化视图中的聚合和查询中聚合的匹配关系:
|
||||
|
||||
| 物化视图聚合 | 查询中聚合 |
|
||||
| ------------ | ------------------------------------------------------ |
|
||||
| sum | sum |
|
||||
| min | min |
|
||||
| max | max |
|
||||
| count | count |
|
||||
| bitmap_union | bitmap_union, bitmap_union_count, count(distinct) |
|
||||
| hll_union | hll_raw_agg, hll_union_agg, ndv, approx_count_distinct |
|
||||
|
||||
其中 bitmap 和 hll 的聚合函数在查询匹配到物化视图后,查询的聚合算子会根据物化视图的表结构进行一个改写。详细见实例2。
|
||||
|
||||
### 查询物化视图
|
||||
|
||||
查看当前表都有哪些物化视图,以及他们的表结构都是什么样的。通过下面命令:
|
||||
|
||||
```sql
|
||||
MySQL [test]> desc mv_test all;
|
||||
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
|
||||
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
|
||||
| mv_test | DUP_KEYS | k1 | INT | Yes | true | NULL | |
|
||||
| | | k2 | BIGINT | Yes | true | NULL | |
|
||||
| | | k3 | LARGEINT | Yes | true | NULL | |
|
||||
| | | k4 | SMALLINT | Yes | false | NULL | NONE |
|
||||
| | | | | | | | |
|
||||
| mv_2 | AGG_KEYS | k2 | BIGINT | Yes | true | NULL | |
|
||||
| | | k4 | SMALLINT | Yes | false | NULL | MIN |
|
||||
| | | k1 | INT | Yes | false | NULL | MAX |
|
||||
| | | | | | | | |
|
||||
| mv_3 | AGG_KEYS | k1 | INT | Yes | true | NULL | |
|
||||
| | | to_bitmap(`k2`) | BITMAP | No | false | | BITMAP_UNION |
|
||||
| | | | | | | | |
|
||||
| mv_1 | AGG_KEYS | k4 | SMALLINT | Yes | true | NULL | |
|
||||
| | | k1 | BIGINT | Yes | false | NULL | SUM |
|
||||
| | | k3 | LARGEINT | Yes | false | NULL | SUM |
|
||||
| | | k2 | BIGINT | Yes | false | NULL | MIN |
|
||||
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
|
||||
```
|
||||
|
||||
可以看到当前 `mv_test` 表一共有三张物化视图:mv_1, mv_2 和 mv_3,以及他们的表结构。
|
||||
|
||||
### 删除物化视图
|
||||
|
||||
如果用户不再需要物化视图,则可以通过命令删除物化视图。
|
||||
|
||||
具体的语法可查看[DROP MATERIALIZED VIEW](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-MATERIALIZED-VIEW.html)
|
||||
|
||||
|
||||
|
||||
## 最佳实践1
|
||||
|
||||
使用物化视图一般分为以下几个步骤:
|
||||
|
||||
1. 创建物化视图
|
||||
2. 异步检查物化视图是否构建完成
|
||||
3. 查询并自动匹配物化视图
|
||||
|
||||
**首先是第一步:创建物化视图**
|
||||
|
||||
假设用户有一张销售记录明细表,存储了每个交易的交易id,销售员,售卖门店,销售时间,以及金额。建表语句为:
|
||||
|
||||
假设用户有一张销售记录明细表,存储了每个交易的交易id,销售员,售卖门店,销售时间,以及金额。建表语句为:
|
||||
|
||||
```sql
|
||||
create table sales_records(record_id int, seller_id int, store_id int, sale_date date, sale_amt bigint) distributed by hash(record_id) properties("replication_num" = "1");
|
||||
```
|
||||
|
||||
这张 `sales_records` 的表结构如下:
|
||||
|
||||
```sql
|
||||
MySQL [test]> desc sales_records;
|
||||
+-----------+--------+------+-------+---------+-------+
|
||||
| Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+--------+------+-------+---------+-------+
|
||||
| record_id | INT | Yes | true | NULL | |
|
||||
| seller_id | INT | Yes | true | NULL | |
|
||||
| store_id | INT | Yes | true | NULL | |
|
||||
| sale_date | DATE | Yes | false | NULL | NONE |
|
||||
| sale_amt | BIGINT | Yes | false | NULL | NONE |
|
||||
+-----------+--------+------+-------+---------+-------+
|
||||
```
|
||||
|
||||
这时候如果用户经常对不同门店的销售量进行一个分析查询,则可以给这个 `sales_records` 表创建一张以售卖门店分组,对相同售卖门店的销售额求和的一个物化视图。创建语句如下:
|
||||
|
||||
```sql
|
||||
MySQL [test]> create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
|
||||
```
|
||||
|
||||
后端返回下图,则说明创建物化视图任务提交成功。
|
||||
|
||||
```sql
|
||||
Query OK, 0 rows affected (0.012 sec)
|
||||
```
|
||||
|
||||
**第二步:检查物化视图是否构建完成**
|
||||
|
||||
由于创建物化视图是一个异步的操作,用户在提交完创建物化视图任务后,需要异步的通过命令检查物化视图是否构建完成。命令如下:
|
||||
|
||||
```sql
|
||||
SHOW ALTER TABLE ROLLUP FROM db_name; (Version 0.12)
|
||||
SHOW ALTER TABLE MATERIALIZED VIEW FROM db_name; (Version 0.13)
|
||||
```
|
||||
|
||||
这个命令中 `db_name` 是一个参数, 你需要替换成自己真实的 db 名称。命令的结果是显示这个 db 的所有创建物化视图的任务。结果如下:
|
||||
|
||||
```sql
|
||||
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
|
||||
| JobId | TableName | CreateTime | FinishedTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
|
||||
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
|
||||
| 22036 | sales_records | 2020-07-30 20:04:28 | 2020-07-30 20:04:57 | sales_records | store_amt | 22037 | 5008 | FINISHED | | NULL | 86400 |
|
||||
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
|
||||
```
|
||||
|
||||
其中 TableName 指的是物化视图的数据来自于哪个表,RollupIndexName 指的是物化视图的名称叫什么。其中比较重要的指标是 State。
|
||||
|
||||
当创建物化视图任务的 State 已经变成 FINISHED 后,就说明这个物化视图已经创建成功了。这就意味着,查询的时候有可能自动匹配到这张物化视图了。
|
||||
|
||||
**第三步:查询**
|
||||
|
||||
当创建完成物化视图后,用户再查询不同门店的销售量时,就会直接从刚才创建的物化视图 `store_amt` 中读取聚合好的数据。达到提升查询效率的效果。
|
||||
|
||||
用户的查询依旧指定查询 `sales_records` 表,比如:
|
||||
|
||||
```sql
|
||||
SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
|
||||
```
|
||||
|
||||
上面查询就能自动匹配到 `store_amt`。用户可以通过下面命令,检验当前查询是否匹配到了合适的物化视图。
|
||||
|
||||
```sql
|
||||
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+-----------------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:<slot 2> `store_id` | <slot 3> sum(`sale_amt`) |
|
||||
| PARTITION: UNPARTITIONED |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 4:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: <slot 2> `store_id` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 04 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 3:AGGREGATE (merge finalize) |
|
||||
| | output: sum(<slot 3> sum(`sale_amt`)) |
|
||||
| | group by: <slot 2> `store_id` |
|
||||
| | |
|
||||
| 2:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 02 |
|
||||
| HASH_PARTITIONED: <slot 2> `store_id` |
|
||||
| |
|
||||
| 1:AGGREGATE (update serialize) |
|
||||
| | STREAMING |
|
||||
| | output: sum(`sale_amt`) |
|
||||
| | group by: `store_id` |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: sales_records |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: store_amt |
|
||||
| tabletRatio=10/10 |
|
||||
| tabletList=22038,22040,22042,22044,22046,22048,22050,22052,22054,22056 |
|
||||
| cardinality=0 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=1 |
|
||||
+-----------------------------------------------------------------------------+
|
||||
45 rows in set (0.006 sec)
|
||||
```
|
||||
|
||||
其中最重要的就是 OlapScanNode 中的 rollup 属性。可以看到当前查询的 rollup 显示的是 `store_amt`。也就是说查询已经正确匹配到物化视图 `store_amt`, 并直接从物化视图中读取数据了。
|
||||
|
||||
## 最佳实践2 PV,UV
|
||||
|
||||
业务场景: 计算广告的 UV,PV
|
||||
|
||||
假设用户的原始广告点击数据存储在 Doris,那么针对广告 PV, UV 查询就可以通过创建 `bitmap_union` 的物化视图来提升查询速度。
|
||||
|
||||
通过下面语句首先创建一个存储广告点击数据明细的表,包含每条点击的点击事件,点击的是什么广告,通过什么渠道点击,以及点击的用户是谁。
|
||||
|
||||
```sql
|
||||
MySQL [test]> create table advertiser_view_record(time date, advertiser varchar(10), channel varchar(10), user_id int) distributed by hash(time) properties("replication_num" = "1");
|
||||
Query OK, 0 rows affected (0.014 sec)
|
||||
```
|
||||
|
||||
原始的广告点击数据表结构为:
|
||||
|
||||
```sql
|
||||
MySQL [test]> desc advertiser_view_record;
|
||||
+------------+-------------+------+-------+---------+-------+
|
||||
| Field | Type | Null | Key | Default | Extra |
|
||||
+------------+-------------+------+-------+---------+-------+
|
||||
| time | DATE | Yes | true | NULL | |
|
||||
| advertiser | VARCHAR(10) | Yes | true | NULL | |
|
||||
| channel | VARCHAR(10) | Yes | false | NULL | NONE |
|
||||
| user_id | INT | Yes | false | NULL | NONE |
|
||||
+------------+-------------+------+-------+---------+-------+
|
||||
4 rows in set (0.001 sec)
|
||||
```
|
||||
|
||||
1. 创建物化视图
|
||||
|
||||
由于用户想要查询的是广告的 UV 值,也就是需要对相同广告的用户进行一个精确去重,则查询一般为:
|
||||
|
||||
```sql
|
||||
SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
|
||||
```
|
||||
|
||||
针对这种求 UV 的场景,我们就可以创建一个带 `bitmap_union` 的物化视图从而达到一个预先精确去重的效果。
|
||||
|
||||
在 Doris 中,`count(distinct)` 聚合的结果和 `bitmap_union_count`聚合的结果是完全一致的。而`bitmap_union_count` 等于 `bitmap_union` 的结果求 count, 所以如果查询中**涉及到 `count(distinct)` 则通过创建带 `bitmap_union` 聚合的物化视图方可加快查询**。
|
||||
|
||||
针对这个 case,则可以创建一个根据广告和渠道分组,对 `user_id` 进行精确去重的物化视图。
|
||||
|
||||
```sql
|
||||
MySQL [test]> create materialized view advertiser_uv as select advertiser, channel, bitmap_union(to_bitmap(user_id)) from advertiser_view_record group by advertiser, channel;
|
||||
Query OK, 0 rows affected (0.012 sec)
|
||||
```
|
||||
|
||||
*注意:因为本身 user_id 是一个 INT 类型,所以在 Doris 中需要先将字段通过函数 `to_bitmap` 转换为 bitmap 类型然后才可以进行 `bitmap_union` 聚合。*
|
||||
|
||||
创建完成后, 广告点击明细表和物化视图表的表结构如下:
|
||||
|
||||
```sql
|
||||
MySQL [test]> desc advertiser_view_record all;
|
||||
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
|
||||
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
|
||||
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
|
||||
| advertiser_view_record | DUP_KEYS | time | DATE | Yes | true | NULL | |
|
||||
| | | advertiser | VARCHAR(10) | Yes | true | NULL | |
|
||||
| | | channel | VARCHAR(10) | Yes | false | NULL | NONE |
|
||||
| | | user_id | INT | Yes | false | NULL | NONE |
|
||||
| | | | | | | | |
|
||||
| advertiser_uv | AGG_KEYS | advertiser | VARCHAR(10) | Yes | true | NULL | |
|
||||
| | | channel | VARCHAR(10) | Yes | true | NULL | |
|
||||
| | | to_bitmap(`user_id`) | BITMAP | No | false | | BITMAP_UNION |
|
||||
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
|
||||
```
|
||||
|
||||
2. 查询自动匹配
|
||||
|
||||
当物化视图表创建完成后,查询广告 UV 时,Doris就会自动从刚才创建好的物化视图 `advertiser_uv` 中查询数据。比如原始的查询语句如下:
|
||||
|
||||
```sql
|
||||
SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
|
||||
```
|
||||
|
||||
在选中物化视图后,实际的查询会转化为:
|
||||
|
||||
```sql
|
||||
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id)) FROM advertiser_uv GROUP BY advertiser, channel;
|
||||
```
|
||||
|
||||
通过 EXPLAIN 命令可以检验到 Doris 是否匹配到了物化视图:
|
||||
|
||||
```sql
|
||||
MySQL [test]> explain SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
|
||||
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:<slot 7> `advertiser` | <slot 8> `channel` | <slot 9> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`) |
|
||||
| PARTITION: UNPARTITIONED |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 4:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: <slot 4> `advertiser`, <slot 5> `channel` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 04 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 3:AGGREGATE (merge finalize) |
|
||||
| | output: bitmap_union_count(<slot 6> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`)) |
|
||||
| | group by: <slot 4> `advertiser`, <slot 5> `channel` |
|
||||
| | |
|
||||
| 2:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 02 |
|
||||
| HASH_PARTITIONED: <slot 4> `advertiser`, <slot 5> `channel` |
|
||||
| |
|
||||
| 1:AGGREGATE (update serialize) |
|
||||
| | STREAMING |
|
||||
| | output: bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mv_bitmap_union_user_id`) |
|
||||
| | group by: `advertiser`, `channel` |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: advertiser_view_record |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: advertiser_uv |
|
||||
| tabletRatio=10/10 |
|
||||
| tabletList=22084,22086,22088,22090,22092,22094,22096,22098,22100,22102 |
|
||||
| cardinality=0 |
|
||||
| avgRowSize=0.0 |
|
||||
| numNodes=1 |
|
||||
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
45 rows in set (0.030 sec)
|
||||
```
|
||||
|
||||
在 EXPLAIN 的结果中,首先可以看到 OlapScanNode 的 rollup 属性值为 advertiser_uv。也就是说,查询会直接扫描物化视图的数据。说明匹配成功。
|
||||
|
||||
其次对于 `user_id` 字段求 `count(distinct)` 被改写为求 `bitmap_union_count(to_bitmap)`。也就是通过 bitmap 的方式来达到精确去重的效果。
|
||||
|
||||
## 最佳实践3
|
||||
|
||||
业务场景:匹配更丰富的前缀索引
|
||||
|
||||
用户的原始表有 (k1, k2, k3) 三列。其中 k1, k2 为前缀索引列。这时候如果用户查询条件中包含 `where k1=1 and k2=2` 就能通过索引加速查询。
|
||||
|
||||
但是有些情况下,用户的过滤条件无法匹配到前缀索引,比如 `where k3=3`。则无法通过索引提升查询速度。
|
||||
|
||||
创建以 k3 作为第一列的物化视图就可以解决这个问题。
|
||||
|
||||
1. 创建物化视图
|
||||
|
||||
```sql
|
||||
CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;
|
||||
```
|
||||
|
||||
通过上面语法创建完成后,物化视图中既保留了完整的明细数据,且物化视图的前缀索引为 k3 列。表结构如下:
|
||||
|
||||
```sql
|
||||
MySQL [test]> desc tableA all;
|
||||
+-----------+---------------+-------+------+------+-------+---------+-------+
|
||||
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+---------------+-------+------+------+-------+---------+-------+
|
||||
| tableA | DUP_KEYS | k1 | INT | Yes | true | NULL | |
|
||||
| | | k2 | INT | Yes | true | NULL | |
|
||||
| | | k3 | INT | Yes | true | NULL | |
|
||||
| | | | | | | | |
|
||||
| mv_1 | DUP_KEYS | k3 | INT | Yes | true | NULL | |
|
||||
| | | k2 | INT | Yes | false | NULL | NONE |
|
||||
| | | k1 | INT | Yes | false | NULL | NONE |
|
||||
+-----------+---------------+-------+------+------+-------+---------+-------+
|
||||
```
|
||||
|
||||
2. 查询匹配
|
||||
|
||||
这时候如果用户的查询存在 k3 列的过滤条件是,比如:
|
||||
|
||||
```sql
|
||||
select k1, k2, k3 from table A where k3=3;
|
||||
```
|
||||
|
||||
这时候查询就会直接从刚才创建的 mv_1 物化视图中读取数据。物化视图对 k3 是存在前缀索引的,查询效率也会提升。
|
||||
|
||||
## 局限性
|
||||
|
||||
1. 物化视图的聚合函数的参数不支持表达式仅支持单列,比如: sum(a+b)不支持。
|
||||
2. 如果删除语句的条件列,在物化视图中不存在,则不能进行删除操作。如果一定要删除数据,则需要先将物化视图删除,然后方可删除数据。
|
||||
3. 单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 base 表数据是同步更新的,如果一张表的物化视图表超过10张,则有可能导致导入速度很慢。这就像单次导入需要同时导入10张表数据是一样的。
|
||||
4. 相同列,不同聚合函数,不能同时出现在一张物化视图中,比如:select sum(a), min(a) from table 不支持。
|
||||
5. 物化视图针对 Unique Key数据模型,只能改变列顺序,不能起到聚合的作用,所以在Unique Key模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作
|
||||
|
||||
## 异常错误
|
||||
|
||||
1. DATA_QUALITY_ERR: "The data quality does not satisfy, please check your data" 由于数据质量问题导致物化视图创建失败。 注意:bitmap类型仅支持正整型, 如果原始数据中存在负数,会导致物化视图创建失败
|
||||
|
||||
|
||||
|
||||
## 更多帮助
|
||||
|
||||
关于物化视图使用的更多详细语法及最佳实践,请参阅 [CREATE MATERIALIZED VIEW](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-MATERIALIZED-VIEW.md) 和 [DROP MATERIALIZED VIEW](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-MATERIALIZED-VIEW.html) 命令手册,你也可以在 MySql 客户端命令行下输入 `HELP CREATE MATERIALIZED VIEW` 和`HELP DROP MATERIALIZED VIEW` 获取更多帮助信息。
|
||||
|
||||
@ -24,4 +24,138 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# BITMAP精准去重
|
||||
# BITMAP精准去重
|
||||
|
||||
## 背景
|
||||
|
||||
Doris原有的Bitmap聚合函数设计比较通用,但对亿级别以上bitmap大基数的交并集计算性能较差。排查后端be的bitmap聚合函数逻辑,发现主要有两个原因。一是当bitmap基数较大时,如bitmap大小超过1g,网络/磁盘IO处理时间比较长;二是后端be实例在scan数据后全部传输到顶层节点进行求交和并运算,给顶层单节点带来压力,成为处理瓶颈。
|
||||
|
||||
解决思路是将bitmap列的值按照range划分,不同range的值存储在不同的分桶中,保证了不同分桶的bitmap值是正交的。当查询时,先分别对不同分桶中的正交bitmap进行聚合计算,然后顶层节点直接将聚合计算后的值合并汇总,并输出。如此会大大提高计算效率,解决了顶层单节点计算瓶颈问题。
|
||||
|
||||
## 使用指南
|
||||
|
||||
1. 建表,增加hid列,表示bitmap列值id范围, 作为hash分桶列
|
||||
2. 使用场景
|
||||
|
||||
### Create table
|
||||
|
||||
建表时需要使用聚合模型,数据类型是 bitmap , 聚合函数是 bitmap_union
|
||||
|
||||
```sql
|
||||
CREATE TABLE `user_tag_bitmap` (
|
||||
`tag` bigint(20) NULL COMMENT "用户标签",
|
||||
`hid` smallint(6) NULL COMMENT "分桶id",
|
||||
`user_id` bitmap BITMAP_UNION NULL COMMENT ""
|
||||
) ENGINE=OLAP
|
||||
AGGREGATE KEY(`tag`, `hid`)
|
||||
COMMENT "OLAP"
|
||||
DISTRIBUTED BY HASH(`hid`) BUCKETS 3
|
||||
```
|
||||
|
||||
表schema增加hid列,表示id范围, 作为hash分桶列。
|
||||
|
||||
注:hid数和BUCKETS要设置合理,hid数设置至少是BUCKETS的5倍以上,以使数据hash分桶尽量均衡
|
||||
|
||||
### Data Load
|
||||
|
||||
```sql
|
||||
LOAD LABEL user_tag_bitmap_test
|
||||
(
|
||||
DATA INFILE('hdfs://abc')
|
||||
INTO TABLE user_tag_bitmap
|
||||
COLUMNS TERMINATED BY ','
|
||||
(tmp_tag, tmp_user_id)
|
||||
SET (
|
||||
tag = tmp_tag,
|
||||
hid = ceil(tmp_user_id/5000000),
|
||||
user_id = to_bitmap(tmp_user_id)
|
||||
)
|
||||
)
|
||||
注意:5000000这个数不固定,可按需调整
|
||||
...
|
||||
```
|
||||
|
||||
数据格式:
|
||||
|
||||
```text
|
||||
11111111,1
|
||||
11111112,2
|
||||
11111113,3
|
||||
11111114,4
|
||||
...
|
||||
```
|
||||
|
||||
注:第一列代表用户标签,由中文转换成数字
|
||||
|
||||
load数据时,对用户bitmap值range范围纵向切割,例如,用户id在1-5000000范围内的hid值相同,hid值相同的行会分配到一个分桶内,如此每个分桶内到的bitmap都是正交的。可以利用桶内bitmap值正交特性,进行交并集计算,计算结果会被shuffle至top节点聚合。
|
||||
|
||||
#### bitmap_orthogonal_intersect
|
||||
|
||||
求bitmap交集函数
|
||||
|
||||
语法:
|
||||
|
||||
orthogonal_bitmap_intersect(bitmap_column, column_to_filter, filter_values)
|
||||
|
||||
参数:
|
||||
|
||||
第一个参数是Bitmap列,第二个参数是用来过滤的维度列,第三个参数是变长参数,含义是过滤维度列的不同取值
|
||||
|
||||
说明:
|
||||
|
||||
查询规划上聚合分2层,在第一层be节点(update、serialize)先按filter_values为key进行hash聚合,然后对所有key的bitmap求交集,结果序列化后发送至第二层be节点(merge、finalize),在第二层be节点对所有来源于第一层节点的bitmap值循环求并集
|
||||
|
||||
样例:
|
||||
|
||||
```sql
|
||||
select BITMAP_COUNT(orthogonal_bitmap_intersect(user_id, tag, 13080800, 11110200)) from user_tag_bitmap where tag in (13080800, 11110200);
|
||||
```
|
||||
|
||||
#### orthogonal_bitmap_intersect_count
|
||||
|
||||
求bitmap交集count函数,语法同原版intersect_count,但实现不同
|
||||
|
||||
语法:
|
||||
|
||||
orthogonal_bitmap_intersect_count(bitmap_column, column_to_filter, filter_values)
|
||||
|
||||
参数:
|
||||
|
||||
第一个参数是Bitmap列,第二个参数是用来过滤的维度列,第三个参数开始是变长参数,含义是过滤维度列的不同取值
|
||||
|
||||
说明:
|
||||
|
||||
查询规划聚合上分2层,在第一层be节点(update、serialize)先按filter_values为key进行hash聚合,然后对所有key的bitmap求交集,再对交集结果求count,count值序列化后发送至第二层be节点(merge、finalize),在第二层be节点对所有来源于第一层节点的count值循环求sum
|
||||
|
||||
#### orthogonal_bitmap_union_count
|
||||
|
||||
求bitmap并集count函数,语法同原版bitmap_union_count,但实现不同。
|
||||
|
||||
语法:
|
||||
|
||||
orthogonal_bitmap_union_count(bitmap_column)
|
||||
|
||||
参数:
|
||||
|
||||
参数类型是bitmap,是待求并集count的列
|
||||
|
||||
说明:
|
||||
|
||||
查询规划上分2层,在第一层be节点(update、serialize)对所有bitmap求并集,再对并集的结果bitmap求count,count值序列化后发送至第二层be节点(merge、finalize),在第二层be节点对所有来源于第一层节点的count值循环求sum
|
||||
|
||||
### 使用场景
|
||||
|
||||
符合对bitmap进行正交计算的场景,如在用户行为分析中,计算留存,漏斗,用户画像等。
|
||||
|
||||
人群圈选:
|
||||
|
||||
```sql
|
||||
select orthogonal_bitmap_intersect_count(user_id, tag, 13080800, 11110200) from user_tag_bitmap where tag in (13080800, 11110200);
|
||||
注:13080800、11110200代表用户标签
|
||||
```
|
||||
|
||||
计算user_id的去重值:
|
||||
|
||||
```sql
|
||||
select orthogonal_bitmap_union_count(user_id) from user_tag_bitmap where tag in (13080800, 11110200);
|
||||
```
|
||||
@ -24,4 +24,435 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 动态分区
|
||||
# 动态分区
|
||||
|
||||
动态分区是在 Doris 0.12 版本中引入的新功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
|
||||
|
||||
目前实现了动态添加分区及动态删除分区的功能。
|
||||
|
||||
动态分区只支持 Range 分区。
|
||||
|
||||
## 原理
|
||||
|
||||
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
|
||||
|
||||
通过动态分区功能,用户可以在建表时设定动态分区的规则。FE 会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
|
||||
|
||||
## 使用方式
|
||||
|
||||
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则。
|
||||
|
||||
- 建表时指定:
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl1
|
||||
(...)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.prop1" = "value1",
|
||||
"dynamic_partition.prop2" = "value2",
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
- 运行时修改
|
||||
|
||||
```sql
|
||||
ALTER TABLE tbl1 SET
|
||||
(
|
||||
"dynamic_partition.prop1" = "value1",
|
||||
"dynamic_partition.prop2" = "value2",
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
### 动态分区规则参数
|
||||
|
||||
动态分区的规则参数都以 `dynamic_partition.` 为前缀:
|
||||
|
||||
- `dynamic_partition.enable`
|
||||
|
||||
是否开启动态分区特性。可指定为 `TRUE` 或 `FALSE`。如果不填写,默认为 `TRUE`。如果为 `FALSE`,则 Doris 会忽略该表的动态分区规则。
|
||||
|
||||
- `dynamic_partition.time_unit`
|
||||
|
||||
动态分区调度的单位。可指定为 `HOUR`、`DAY`、`WEEK`、`MONTH`。分别表示按天、按星期、按月进行分区创建或删除。
|
||||
|
||||
当指定为 `HOUR` 时,动态创建的分区名后缀格式为 `yyyyMMddHH`,例如`2020032501`。小时为单位的分区列数据类型不能为 DATE。
|
||||
|
||||
当指定为 `DAY` 时,动态创建的分区名后缀格式为 `yyyyMMdd`,例如`20200325`。
|
||||
|
||||
当指定为 `WEEK` 时,动态创建的分区名后缀格式为`yyyy_ww`。即当前日期属于这一年的第几周,例如 `2020-03-25` 创建的分区名后缀为 `2020_13`, 表明目前为2020年第13周。
|
||||
|
||||
当指定为 `MONTH` 时,动态创建的分区名后缀格式为 `yyyyMM`,例如 `202003`。
|
||||
|
||||
- `dynamic_partition.time_zone`
|
||||
|
||||
动态分区的时区,如果不填写,则默认为当前机器的系统的时区,例如 `Asia/Shanghai`,如果想获取当前支持的时区设置,可以参考 `https://en.wikipedia.org/wiki/List_of_tz_database_time_zones`。
|
||||
|
||||
- `dynamic_partition.start`
|
||||
|
||||
动态分区的起始偏移,为负数。根据 `time_unit` 属性的不同,以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写,则默认为 `-2147483648`,即不删除历史分区。
|
||||
|
||||
- `dynamic_partition.end`
|
||||
|
||||
动态分区的结束偏移,为正数。根据 `time_unit` 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。
|
||||
|
||||
- `dynamic_partition.prefix`
|
||||
|
||||
动态创建的分区名前缀。
|
||||
|
||||
- `dynamic_partition.buckets`
|
||||
|
||||
动态创建的分区所对应的分桶数量。
|
||||
|
||||
- `dynamic_partition.replication_num`
|
||||
|
||||
动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量。
|
||||
|
||||
- `dynamic_partition.start_day_of_week`
|
||||
|
||||
当 `time_unit` 为 `WEEK` 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点。
|
||||
|
||||
- `dynamic_partition.start_day_of_month`
|
||||
|
||||
当 `time_unit` 为 `MONTH` 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月1号,28 表示每月28号。默认为 1,即表示每月以1号位起始点。暂不支持以29、30、31号为起始日,以避免因闰年或闰月带来的歧义。
|
||||
|
||||
- `dynamic_partition.create_history_partition`
|
||||
|
||||
默认为 false。当置为 true 时,Doris 会自动创建所有分区,具体创建规则见下文。同时,FE 的参数 `max_dynamic_partition_num` 会限制总分区数量,以避免一次性创建过多分区。当期望创建的分区个数大于 `max_dynamic_partition_num` 值时,操作将被禁止。
|
||||
|
||||
当不指定 `start` 属性时,该参数不生效。
|
||||
|
||||
- `dynamic_partition.history_partition_num`
|
||||
|
||||
当 `create_history_partition` 为 `true` 时,该参数用于指定创建历史分区数量。默认值为 -1, 即未设置。
|
||||
|
||||
- `dynamic_partition.hot_partition_num`
|
||||
|
||||
指定最新的多少个分区为热分区。对于热分区,系统会自动设置其 `storage_medium` 参数为SSD,并且设置 `storage_cooldown_time`。
|
||||
|
||||
`hot_partition_num` 是往前 n 天和未来所有分区
|
||||
|
||||
我们举例说明。假设今天是 2021-05-20,按天分区,动态分区的属性设置为:hot_partition_num=2, end=3, start=-3。则系统会自动创建以下分区,并且设置 `storage_medium` 和 `storage_cooldown_time` 参数:
|
||||
|
||||
```text
|
||||
p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
|
||||
p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
|
||||
p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
|
||||
p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
|
||||
p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
|
||||
p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
|
||||
p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
|
||||
```
|
||||
|
||||
- `dynamic_partition.reserved_history_periods`
|
||||
|
||||
需要保留的历史分区的时间范围。当`dynamic_partition.time_unit` 设置为 "DAY/WEEK/MONTH" 时,需要以 `[yyyy-MM-dd,yyyy-MM-dd],[...,...]` 格式进行设置。当`dynamic_partition.time_unit` 设置为 "HOUR" 时,需要以 `[yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...]` 的格式来进行设置。如果不设置,默认为 `"NULL"`。
|
||||
|
||||
我们举例说明。假设今天是 2021-09-06,按天分类,动态分区的属性设置为:
|
||||
|
||||
`time_unit="DAY/WEEK/MONTH", end=3, start=-3, reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"`。
|
||||
|
||||
则系统会自动保留:
|
||||
|
||||
```text
|
||||
["2020-06-01","2020-06-20"],
|
||||
["2020-10-31","2020-11-15"]
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
`time_unit="HOUR", end=3, start=-3, reserved_history_periods="[2020-06-01 00:00:00,2020-06-01 03:00:00]"`.
|
||||
|
||||
则系统会自动保留:
|
||||
|
||||
```text
|
||||
["2020-06-01 00:00:00","2020-06-01 03:00:00"]
|
||||
```
|
||||
|
||||
这两个时间段的分区。其中,`reserved_history_periods` 的每一个 `[...,...]` 是一对设置项,两者需要同时被设置,且第一个时间不能大于第二个时间。
|
||||
|
||||
#### 创建历史分区规则
|
||||
|
||||
当 `create_history_partition` 为 `true`,即开启创建历史分区功能时,Doris 会根据 `dynamic_partition.start` 和 `dynamic_partition.history_partition_num` 来决定创建历史分区的个数。
|
||||
|
||||
假设需要创建的历史分区数量为 `expect_create_partition_num`,根据不同的设置具体数量如下:
|
||||
|
||||
1. `create_history_partition` = `true`
|
||||
- `dynamic_partition.history_partition_num` 未设置,即 -1.
|
||||
`expect_create_partition_num` = `end` - `start`;
|
||||
- `dynamic_partition.history_partition_num` 已设置
|
||||
`expect_create_partition_num` = `end` - max(`start`, `-histoty_partition_num`);
|
||||
2. `create_history_partition` = `false`
|
||||
不会创建历史分区,`expect_create_partition_num` = `end` - 0;
|
||||
|
||||
当 `expect_create_partition_num` 大于 `max_dynamic_partition_num`(默认500)时,禁止创建过多分区。
|
||||
|
||||
**举例说明:**
|
||||
|
||||
1. 假设今天是 2021-05-20,按天分区,动态分区的属性设置为:`create_history_partition=true, end=3, start=-3, history_partition_num=1`,则系统会自动创建以下分区:
|
||||
|
||||
```text
|
||||
p20210519
|
||||
p20210520
|
||||
p20210521
|
||||
p20210522
|
||||
p20210523
|
||||
```
|
||||
|
||||
2. `history_partition_num=5`,其余属性与 1 中保持一直,则系统会自动创建以下分区:
|
||||
|
||||
```text
|
||||
p20210517
|
||||
p20210518
|
||||
p20210519
|
||||
p20210520
|
||||
p20210521
|
||||
p20210522
|
||||
p20210523
|
||||
```
|
||||
|
||||
3. `history_partition_num=-1` 即不设置历史分区数量,其余属性与 1 中保持一直,则系统会自动创建以下分区:
|
||||
|
||||
```text
|
||||
p20210517
|
||||
p20210518
|
||||
p20210519
|
||||
p20210520
|
||||
p20210521
|
||||
p20210522
|
||||
p20210523
|
||||
```
|
||||
|
||||
### 注意事项
|
||||
|
||||
动态分区使用过程中,如果因为一些意外情况导致 `dynamic_partition.start` 和 `dynamic_partition.end` 之间的某些分区丢失,那么当前时间与 `dynamic_partition.end` 之间的丢失分区会被重新创建,`dynamic_partition.start`与当前时间之间的丢失分区不会重新创建。
|
||||
|
||||
## 示例
|
||||
|
||||
1. 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近7天的分区,并且预先创建未来3天的分区。
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl1
|
||||
(
|
||||
k1 DATE,
|
||||
...
|
||||
)
|
||||
PARTITION BY RANGE(k1) ()
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "DAY",
|
||||
"dynamic_partition.start" = "-7",
|
||||
"dynamic_partition.end" = "3",
|
||||
"dynamic_partition.prefix" = "p",
|
||||
"dynamic_partition.buckets" = "32"
|
||||
);
|
||||
```
|
||||
|
||||
假设当前日期为 2020-05-29。则根据以上规则,tbl1 会产生以下分区:
|
||||
|
||||
```text
|
||||
p20200529: ["2020-05-29", "2020-05-30")
|
||||
p20200530: ["2020-05-30", "2020-05-31")
|
||||
p20200531: ["2020-05-31", "2020-06-01")
|
||||
p20200601: ["2020-06-01", "2020-06-02")
|
||||
```
|
||||
|
||||
在第二天,即 2020-05-30,会创建新的分区 `p20200602: ["2020-06-02", "2020-06-03")`
|
||||
|
||||
在 2020-06-06 时,因为 `dynamic_partition.start` 设置为 7,则将删除7天前的分区,即删除分区 `p20200529`。
|
||||
|
||||
2. 表 tbl1 分区列 k1 类型为 DATETIME,创建一个动态分区规则。按星期分区,只保留最近2个星期的分区,并且预先创建未来2个星期的分区。
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl1
|
||||
(
|
||||
k1 DATETIME,
|
||||
...
|
||||
)
|
||||
PARTITION BY RANGE(k1) ()
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "WEEK",
|
||||
"dynamic_partition.start" = "-2",
|
||||
"dynamic_partition.end" = "2",
|
||||
"dynamic_partition.prefix" = "p",
|
||||
"dynamic_partition.buckets" = "8"
|
||||
);
|
||||
```
|
||||
|
||||
假设当前日期为 2020-05-29,是 2020 年的第 22 周。默认每周起始为星期一。则根于以上规则,tbl1 会产生以下分区:
|
||||
|
||||
```text
|
||||
p2020_22: ["2020-05-25 00:00:00", "2020-06-01 00:00:00")
|
||||
p2020_23: ["2020-06-01 00:00:00", "2020-06-08 00:00:00")
|
||||
p2020_24: ["2020-06-08 00:00:00", "2020-06-15 00:00:00")
|
||||
```
|
||||
|
||||
其中每个分区的起始日期为当周的周一。同时,因为分区列 k1 的类型为 DATETIME,则分区值会补全时分秒部分,且皆为 0。
|
||||
|
||||
在 2020-06-15,即第25周时,会删除2周前的分区,即删除 `p2020_22`。
|
||||
|
||||
在上面的例子中,假设用户指定了周起始日为 `"dynamic_partition.start_day_of_week" = "3"`,即以每周三为起始日。则分区如下:
|
||||
|
||||
```text
|
||||
p2020_22: ["2020-05-27 00:00:00", "2020-06-03 00:00:00")
|
||||
p2020_23: ["2020-06-03 00:00:00", "2020-06-10 00:00:00")
|
||||
p2020_24: ["2020-06-10 00:00:00", "2020-06-17 00:00:00")
|
||||
```
|
||||
|
||||
即分区范围为当周的周三到下周的周二。
|
||||
|
||||
- 注:2019-12-31 和 2020-01-01 在同一周内,如果分区的起始日期为 2019-12-31,则分区名为 `p2019_53`,如果分区的起始日期为 2020-01-01,则分区名为 `p2020_01`。
|
||||
|
||||
3. 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按月分区,不删除历史分区,并且预先创建未来2个月的分区。同时设定以每月3号为起始日。
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl1
|
||||
(
|
||||
k1 DATE,
|
||||
...
|
||||
)
|
||||
PARTITION BY RANGE(k1) ()
|
||||
DISTRIBUTED BY HASH(k1)
|
||||
PROPERTIES
|
||||
(
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "MONTH",
|
||||
"dynamic_partition.end" = "2",
|
||||
"dynamic_partition.prefix" = "p",
|
||||
"dynamic_partition.buckets" = "8",
|
||||
"dynamic_partition.start_day_of_month" = "3"
|
||||
);
|
||||
```
|
||||
|
||||
假设当前日期为 2020-05-29。则根于以上规则,tbl1 会产生以下分区:
|
||||
|
||||
```text
|
||||
p202005: ["2020-05-03", "2020-06-03")
|
||||
p202006: ["2020-06-03", "2020-07-03")
|
||||
p202007: ["2020-07-03", "2020-08-03")
|
||||
```
|
||||
|
||||
因为没有设置 `dynamic_partition.start`,则不会删除历史分区。
|
||||
|
||||
假设今天为 2020-05-20,并设置以每月28号为起始日,则分区范围为:
|
||||
|
||||
```text
|
||||
p202004: ["2020-04-28", "2020-05-28")
|
||||
p202005: ["2020-05-28", "2020-06-28")
|
||||
p202006: ["2020-06-28", "2020-07-28")
|
||||
```
|
||||
|
||||
## 修改动态分区属性
|
||||
|
||||
通过如下命令可以修改动态分区的属性:
|
||||
|
||||
```sql
|
||||
ALTER TABLE tbl1 SET
|
||||
(
|
||||
"dynamic_partition.prop1" = "value1",
|
||||
...
|
||||
);
|
||||
```
|
||||
|
||||
某些属性的修改可能会产生冲突。假设之前分区粒度为 DAY,并且已经创建了如下分区:
|
||||
|
||||
```text
|
||||
p20200519: ["2020-05-19", "2020-05-20")
|
||||
p20200520: ["2020-05-20", "2020-05-21")
|
||||
p20200521: ["2020-05-21", "2020-05-22")
|
||||
```
|
||||
|
||||
如果此时将分区粒度改为 MONTH,则系统会尝试创建范围为 `["2020-05-01", "2020-06-01")` 的分区,而该分区的分区范围和已有分区冲突,所以无法创建。而范围为 `["2020-06-01", "2020-07-01")` 的分区可以正常创建。因此,2020-05-22 到 2020-05-30 时间段的分区,需要自行填补。
|
||||
|
||||
### 查看动态分区表调度情况
|
||||
|
||||
通过以下命令可以进一步查看当前数据库下,所有动态分区表的调度情况:
|
||||
|
||||
```sql
|
||||
mysql> SHOW DYNAMIC PARTITION TABLES;
|
||||
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
|
||||
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
|
||||
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
|
||||
| d3 | true | WEEK | -3 | 3 | p | 1 | MONDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | [2021-12-01,2021-12-31] |
|
||||
| d5 | true | DAY | -7 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d4 | true | WEEK | -3 | 3 | p | 1 | WEDNESDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d6 | true | MONTH | -2147483648 | 2 | p | 8 | 3rd | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d2 | true | DAY | -3 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
| d7 | true | MONTH | -2147483648 | 5 | p | 8 | 24th | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
|
||||
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
|
||||
7 rows in set (0.02 sec)
|
||||
```
|
||||
|
||||
- LastUpdateTime: 最后一次修改动态分区属性的时间
|
||||
- LastSchedulerTime: 最后一次执行动态分区调度的时间
|
||||
- State: 最后一次执行动态分区调度的状态
|
||||
- LastCreatePartitionMsg: 最后一次执行动态添加分区调度的错误信息
|
||||
- LastDropPartitionMsg: 最后一次执行动态删除分区调度的错误信息
|
||||
|
||||
## 高级操作
|
||||
|
||||
### FE 配置项
|
||||
|
||||
- dynamic_partition_enable
|
||||
|
||||
是否开启 Doris 的动态分区功能。默认为 false,即关闭。该参数只影响动态分区表的分区操作,不影响普通表。可以通过修改 fe.conf 中的参数并重启 FE 生效。也可以在运行时执行以下命令生效:
|
||||
|
||||
MySQL 协议:
|
||||
|
||||
`ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true")`
|
||||
|
||||
HTTP 协议:
|
||||
|
||||
`curl --location-trusted -u username:password -XGET http://fe_host:fe_http_port/api/_set_config?dynamic_partition_enable=true`
|
||||
|
||||
若要全局关闭动态分区,则设置此参数为 false 即可。
|
||||
|
||||
- dynamic_partition_check_interval_seconds
|
||||
|
||||
动态分区线程的执行频率,默认为600(10分钟),即每10分钟进行一次调度。可以通过修改 fe.conf 中的参数并重启 FE 生效。也可以在运行时执行以下命令修改:
|
||||
|
||||
MySQL 协议:
|
||||
|
||||
`ADMIN SET FRONTEND CONFIG ("dynamic_partition_check_interval_seconds" = "7200")`
|
||||
|
||||
HTTP 协议:
|
||||
|
||||
`curl --location-trusted -u username:password -XGET http://fe_host:fe_http_port/api/_set_config?dynamic_partition_check_interval_seconds=432000`
|
||||
|
||||
### 动态分区表与手动分区表相互转换
|
||||
|
||||
对于一个表来说,动态分区和手动分区可以自由转换,但二者不能同时存在,有且只有一种状态。
|
||||
|
||||
#### 手动分区转换为动态分区
|
||||
|
||||
如果一个表在创建时未指定动态分区,可以通过 `ALTER TABLE` 在运行时修改动态分区相关属性来转化为动态分区,具体示例可以通过 `HELP ALTER TABLE` 查看。
|
||||
|
||||
开启动态分区功能后,Doris 将不再允许用户手动管理分区,会根据动态分区属性来自动管理分区。
|
||||
|
||||
**注意**:如果已设定 `dynamic_partition.start`,分区范围在动态分区起始偏移之前的历史分区将会被删除。
|
||||
|
||||
#### 动态分区转换为手动分区
|
||||
|
||||
通过执行 `ALTER TABLE tbl_name SET ("dynamic_partition.enable" = "false")` 即可关闭动态分区功能,将其转换为手动分区表。
|
||||
|
||||
关闭动态分区功能后,Doris 将不再自动管理分区,需要用户手动通过 `ALTER TABLE` 的方式创建或删除分区。
|
||||
|
||||
|
||||
## 常见问题
|
||||
|
||||
1. 创建动态分区表后提示 `Could not create table with dynamic partition when fe config dynamic_partition_enable is false`
|
||||
|
||||
由于动态分区的总开关,也就是 FE 的配置 `dynamic_partition_enable` 为 false,导致无法创建动态分区表。
|
||||
|
||||
这时候请修改 FE 的配置文件,增加一行 `dynamic_partition_enable=true`,并重启 FE。或者执行命令 ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true") 将动态分区开关打开即可。
|
||||
|
||||
## 更多帮助
|
||||
|
||||
关于动态分区使用的更多详细语法及最佳实践,请参阅 [SHOW DYNAMIC PARTITION](../../sql-manual/sql-reference-v2/Show-Statements/SHOW-DYNAMIC-PARTITION.md) 命令手册,你也可以在 MySql 客户端命令行下输入 `HELP ALTER TABLE` 获取更多帮助信息。
|
||||
@ -24,4 +24,263 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 临时分区
|
||||
# 临时分区
|
||||
|
||||
在 0.12 版本中,Doris 支持了临时分区功能。
|
||||
|
||||
临时分区是归属于某一分区表的。只有分区表可以创建临时分区。
|
||||
|
||||
## 规则
|
||||
|
||||
- 临时分区的分区列和正式分区相同,且不可修改。
|
||||
- 一张表所有临时分区之间的分区范围不可重叠,但临时分区的范围和正式分区范围可以重叠。
|
||||
- 临时分区的分区名称不能和正式分区以及其他临时分区重复。
|
||||
|
||||
## 支持的操作
|
||||
|
||||
临时分区支持添加、删除、替换操作。
|
||||
|
||||
### 添加临时分区
|
||||
|
||||
可以通过 `ALTER TABLE ADD TEMPORARY PARTITION` 语句对一个表添加临时分区:
|
||||
|
||||
```text
|
||||
ALTER TABLE tbl1 ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01");
|
||||
|
||||
ALTER TABLE tbl2 ADD TEMPORARY PARTITION tp1 VALUES [("2020-01-01"), ("2020-02-01"));
|
||||
|
||||
ALTER TABLE tbl1 ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01")
|
||||
("in_memory" = "true", "replication_num" = "1")
|
||||
DISTRIBUTED BY HASH(k1) BUCKETS 5;
|
||||
|
||||
ALTER TABLE tbl3 ADD TEMPORARY PARTITION tp1 VALUES IN ("Beijing", "Shanghai");
|
||||
|
||||
ALTER TABLE tbl4 ADD TEMPORARY PARTITION tp1 VALUES IN ((1, "Beijing"), (1, "Shanghai"));
|
||||
|
||||
ALTER TABLE tbl3 ADD TEMPORARY PARTITION tp1 VALUES IN ("Beijing", "Shanghai")
|
||||
("in_memory" = "true", "replication_num" = "1")
|
||||
DISTRIBUTED BY HASH(k1) BUCKETS 5;
|
||||
```
|
||||
|
||||
通过 `HELP ALTER TABLE;` 查看更多帮助和示例。
|
||||
|
||||
添加操作的一些说明:
|
||||
|
||||
- 临时分区的添加和正式分区的添加操作相似。临时分区的分区范围独立于正式分区。
|
||||
- 临时分区可以独立指定一些属性。包括分桶数、副本数、是否是内存表、存储介质等信息。
|
||||
|
||||
### 删除临时分区
|
||||
|
||||
可以通过 `ALTER TABLE DROP TEMPORARY PARTITION` 语句删除一个表的临时分区:
|
||||
|
||||
```text
|
||||
ALTER TABLE tbl1 DROP TEMPORARY PARTITION tp1;
|
||||
```
|
||||
|
||||
通过 `HELP ALTER TABLE;` 查看更多帮助和示例。
|
||||
|
||||
删除操作的一些说明:
|
||||
|
||||
- 删除临时分区,不影响正式分区的数据。
|
||||
|
||||
### 替换分区
|
||||
|
||||
可以通过 `ALTER TABLE REPLACE PARTITION` 语句将一个表的正式分区替换为临时分区。
|
||||
|
||||
```text
|
||||
ALTER TABLE tbl1 REPLACE PARTITION (p1) WITH TEMPORARY PARTITION (tp1);
|
||||
|
||||
ALTER TABLE tbl1 REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1, tp2, tp3);
|
||||
|
||||
ALTER TABLE tbl1 REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1, tp2)
|
||||
PROPERTIES (
|
||||
"strict_range" = "false",
|
||||
"use_temp_partition_name" = "true"
|
||||
);
|
||||
```
|
||||
|
||||
通过 `HELP ALTER TABLE;` 查看更多帮助和示例。
|
||||
|
||||
替换操作有两个特殊的可选参数:
|
||||
|
||||
1. `strict_range`
|
||||
|
||||
默认为 true。
|
||||
|
||||
对于 Range 分区,当该参数为 true 时,表示要被替换的所有正式分区的范围并集需要和替换的临时分区的范围并集完全相同。当置为 false 时,只需要保证替换后,新的正式分区间的范围不重叠即可。
|
||||
|
||||
对于 List 分区,该参数恒为 true。要被替换的所有正式分区的枚举值必须和替换的临时分区枚举值完全相同。
|
||||
|
||||
下面举例说明:
|
||||
|
||||
- 示例1
|
||||
|
||||
待替换的分区 p1, p2, p3 的范围 (=> 并集):
|
||||
|
||||
```text
|
||||
[10, 20), [20, 30), [40, 50) => [10, 30), [40, 50)
|
||||
```
|
||||
|
||||
替换分区 tp1, tp2 的范围(=> 并集):
|
||||
|
||||
```text
|
||||
[10, 30), [40, 45), [45, 50) => [10, 30), [40, 50)
|
||||
```
|
||||
|
||||
范围并集相同,则可以使用 tp1 和 tp2 替换 p1, p2, p3。
|
||||
|
||||
- 示例2
|
||||
|
||||
待替换的分区 p1 的范围 (=> 并集):
|
||||
|
||||
```text
|
||||
[10, 50) => [10, 50)
|
||||
```
|
||||
|
||||
替换分区 tp1, tp2 的范围(=> 并集):
|
||||
|
||||
```text
|
||||
[10, 30), [40, 50) => [10, 30), [40, 50)
|
||||
```
|
||||
|
||||
范围并集不相同,如果 `strict_range` 为 true,则不可以使用 tp1 和 tp2 替换 p1。如果为 false,且替换后的两个分区范围 `[10, 30), [40, 50)` 和其他正式分区不重叠,则可以替换。
|
||||
|
||||
- 示例3
|
||||
|
||||
待替换的分区 p1, p2 的枚举值(=> 并集):
|
||||
|
||||
```text
|
||||
(1, 2, 3), (4, 5, 6) => (1, 2, 3, 4, 5, 6)
|
||||
```
|
||||
|
||||
替换分区 tp1, tp2, tp3 的枚举值(=> 并集):
|
||||
|
||||
```text
|
||||
(1, 2, 3), (4), (5, 6) => (1, 2, 3, 4, 5, 6)
|
||||
```
|
||||
|
||||
枚举值并集相同,可以使用 tp1,tp2,tp3 替换 p1,p2
|
||||
|
||||
- 示例4
|
||||
|
||||
待替换的分区 p1, p2,p3 的枚举值(=> 并集):
|
||||
|
||||
```text
|
||||
(("1","beijing"), ("1", "shanghai")), (("2","beijing"), ("2", "shanghai")), (("3","beijing"), ("3", "shanghai")) => (("1","beijing"), ("1", "shanghai"), ("2","beijing"), ("2", "shanghai"), ("3","beijing"), ("3", "shanghai"))
|
||||
```
|
||||
|
||||
替换分区 tp1, tp2 的枚举值(=> 并集):
|
||||
|
||||
```text
|
||||
(("1","beijing"), ("1", "shanghai")), (("2","beijing"), ("2", "shanghai"), ("3","beijing"), ("3", "shanghai")) => (("1","beijing"), ("1", "shanghai"), ("2","beijing"), ("2", "shanghai"), ("3","beijing"), ("3", "shanghai"))
|
||||
```
|
||||
|
||||
枚举值并集相同,可以使用 tp1,tp2 替换 p1,p2,p3
|
||||
|
||||
2. `use_temp_partition_name`
|
||||
|
||||
默认为 false。当该参数为 false,并且待替换的分区和替换分区的个数相同时,则替换后的正式分区名称维持不变。如果为 true,则替换后,正式分区的名称为替换分区的名称。下面举例说明:
|
||||
|
||||
- 示例1
|
||||
|
||||
```text
|
||||
ALTER TABLE tbl1 REPLACE PARTITION (p1) WITH TEMPORARY PARTITION (tp1);
|
||||
```
|
||||
|
||||
`use_temp_partition_name` 默认为 false,则在替换后,分区的名称依然为 p1,但是相关的数据和属性都替换为 tp1 的。
|
||||
|
||||
如果 `use_temp_partition_name` 默认为 true,则在替换后,分区的名称为 tp1。p1 分区不再存在。
|
||||
|
||||
- 示例2
|
||||
|
||||
```text
|
||||
ALTER TABLE tbl1 REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1);
|
||||
```
|
||||
|
||||
`use_temp_partition_name` 默认为 false,但因为待替换分区的个数和替换分区的个数不同,则该参数无效。替换后,分区名称为 tp1,p1 和 p2 不再存在。
|
||||
|
||||
替换操作的一些说明:
|
||||
|
||||
- 分区替换成功后,被替换的分区将被删除且不可恢复。
|
||||
|
||||
## 临时分区的导入和查询
|
||||
|
||||
用户可以将数据导入到临时分区,也可以指定临时分区进行查询。
|
||||
|
||||
1. 导入临时分区
|
||||
|
||||
根据导入方式的不同,指定导入临时分区的语法稍有差别。这里通过示例进行简单说明
|
||||
|
||||
```text
|
||||
INSERT INTO tbl TEMPORARY PARTITION(tp1, tp2, ...) SELECT ....
|
||||
```
|
||||
|
||||
```text
|
||||
curl --location-trusted -u root: -H "label:123" -H "temporary_partitions: tp1, tp2, ..." -T testData http://host:port/api/testDb/testTbl/_stream_load
|
||||
```
|
||||
|
||||
```text
|
||||
LOAD LABEL example_db.label1
|
||||
(
|
||||
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file")
|
||||
INTO TABLE `my_table`
|
||||
TEMPORARY PARTITION (tp1, tp2, ...)
|
||||
...
|
||||
)
|
||||
WITH BROKER hdfs ("username"="hdfs_user", "password"="hdfs_password");
|
||||
```
|
||||
|
||||
```text
|
||||
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
|
||||
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),
|
||||
TEMPORARY PARTITIONS(tp1, tp2, ...),
|
||||
WHERE k1 > 100
|
||||
PROPERTIES
|
||||
(...)
|
||||
FROM KAFKA
|
||||
(...);
|
||||
```
|
||||
|
||||
2. 查询临时分区
|
||||
|
||||
```text
|
||||
SELECT ... FROM
|
||||
tbl1 TEMPORARY PARTITION(tp1, tp2, ...)
|
||||
JOIN
|
||||
tbl2 TEMPORARY PARTITION(tp1, tp2, ...)
|
||||
ON ...
|
||||
WHERE ...;
|
||||
```
|
||||
|
||||
## 和其他操作的关系
|
||||
|
||||
### DROP
|
||||
|
||||
- 使用 Drop 操作直接删除数据库或表后,可以通过 Recover 命令恢复数据库或表(限定时间内),但临时分区不会被恢复。
|
||||
- 使用 Alter 命令删除正式分区后,可以通过 Recover 命令恢复分区(限定时间内)。操作正式分区和临时分区无关。
|
||||
- 使用 Alter 命令删除临时分区后,无法通过 Recover 命令恢复临时分区。
|
||||
|
||||
### TRUNCATE
|
||||
|
||||
- 使用 Truncate 命令清空表,表的临时分区会被删除,且不可恢复。
|
||||
- 使用 Truncate 命令清空正式分区时,不影响临时分区。
|
||||
- 不可使用 Truncate 命令清空临时分区。
|
||||
|
||||
### ALTER
|
||||
|
||||
- 当表存在临时分区时,无法使用 Alter 命令对表进行 Schema Change、Rollup 等变更操作。
|
||||
- 当表在进行变更操作时,无法对表添加临时分区。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
1. 原子的覆盖写操作
|
||||
|
||||
某些情况下,用户希望能够重写某一分区的数据,但如果采用先删除再导入的方式进行,在中间会有一段时间无法查看数据。这时,用户可以先创建一个对应的临时分区,将新的数据导入到临时分区后,通过替换操作,原子的替换原有分区,以达到目的。对于非分区表的原子覆盖写操作,请参阅[替换表文档](https://doris.apache.org/zh-CN/administrator-guide/alter-table/alter-table-replace-table.html)
|
||||
|
||||
2. 修改分桶数
|
||||
|
||||
某些情况下,用户在创建分区时使用了不合适的分桶数。则用户可以先创建一个对应分区范围的临时分区,并指定新的分桶数。然后通过 `INSERT INTO` 命令将正式分区的数据导入到临时分区中,通过替换操作,原子的替换原有分区,以达到目的。
|
||||
|
||||
3. 合并或分割分区
|
||||
|
||||
某些情况下,用户希望对分区的范围进行修改,比如合并两个分区,或将一个大分区分割成多个小分区。则用户可以先建立对应合并或分割后范围的临时分区,然后通过 `INSERT INTO` 命令将正式分区的数据导入到临时分区中,通过替换操作,原子的替换原有分区,以达到目的。
|
||||
@ -24,4 +24,263 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Runtime Filter
|
||||
# Runtime Filter
|
||||
|
||||
Runtime Filter 是在 Doris 0.15 版本中正式加入的新功能。旨在为某些 Join 查询在运行时动态生成过滤条件,来减少扫描的数据量,避免不必要的I/O和网络传输,从而加速查询。
|
||||
|
||||
它的设计、实现和效果可以参阅 [ISSUE 6116](https://github.com/apache/incubator-doris/issues/6116)。
|
||||
|
||||
## 名词解释
|
||||
|
||||
- 左表:Join查询时,左边的表。进行Probe操作。可被Join Reorder调整顺序。
|
||||
- 右表:Join查询时,右边的表。进行Build操作。可被Join Reorder调整顺序。
|
||||
- Fragment:FE会将具体的SQL语句的执行转化为对应的Fragment并下发到BE进行执行。BE上执行对应Fragment,并将结果汇聚返回给FE。
|
||||
- Join on clause: `A join B on A.a=B.b`中的`A.a=B.b`,在查询规划时基于此生成join conjuncts,包含join Build和Probe使用的expr,其中Build expr在Runtime Filter中称为src expr,Probe expr在Runtime Filter中称为target expr。
|
||||
|
||||
## 原理
|
||||
|
||||
Runtime Filter在查询规划时生成,在HashJoinNode中构建,在ScanNode中应用。
|
||||
|
||||
举个例子,当前存在T1表与T2表的Join查询,它的Join方式为HashJoin,T1是一张事实表,数据行数为100000,T2是一张维度表,数据行数为2000,Doris join的实际情况是:
|
||||
|
||||
```text
|
||||
| > HashJoinNode <
|
||||
| | |
|
||||
| | 100000 | 2000
|
||||
| | |
|
||||
| OlapScanNode OlapScanNode
|
||||
| ^ ^
|
||||
| | 100000 | 2000
|
||||
| T1 T2
|
||||
|
|
||||
```
|
||||
|
||||
显而易见对T2扫描数据要远远快于T1,如果我们主动等待一段时间再扫描T1,等T2将扫描的数据记录交给HashJoinNode后,HashJoinNode根据T2的数据计算出一个过滤条件,比如T2数据的最大和最小值,或者构建一个Bloom Filter,接着将这个过滤条件发给等待扫描T1的ScanNode,后者应用这个过滤条件,将过滤后的数据交给HashJoinNode,从而减少probe hash table的次数和网络开销,这个过滤条件就是Runtime Filter,效果如下:
|
||||
|
||||
```text
|
||||
| > HashJoinNode <
|
||||
| | |
|
||||
| | 6000 | 2000
|
||||
| | |
|
||||
| OlapScanNode OlapScanNode
|
||||
| ^ ^
|
||||
| | 100000 | 2000
|
||||
| T1 T2
|
||||
|
|
||||
```
|
||||
|
||||
如果能将过滤条件(Runtime Filter)下推到存储引擎,则某些情况下可以利用索引来直接减少扫描的数据量,从而大大减少扫描耗时,效果如下:
|
||||
|
||||
```text
|
||||
| > HashJoinNode <
|
||||
| | |
|
||||
| | 6000 | 2000
|
||||
| | |
|
||||
| OlapScanNode OlapScanNode
|
||||
| ^ ^
|
||||
| | 6000 | 2000
|
||||
| T1 T2
|
||||
|
|
||||
```
|
||||
|
||||
可见,和谓词下推、分区裁剪不同,Runtime Filter是在运行时动态生成的过滤条件,即在查询运行时解析join on clause确定过滤表达式,并将表达式广播给正在读取左表的ScanNode,从而减少扫描的数据量,进而减少probe hash table的次数,避免不必要的I/O和网络传输。
|
||||
|
||||
Runtime Filter主要用于大表join小表的优化,如果左表的数据量太小,或者右表的数据量太大,则Runtime Filter可能不会取得预期效果。
|
||||
|
||||
## 使用方式
|
||||
|
||||
### Runtime Filter查询选项
|
||||
|
||||
与Runtime Filter相关的查询选项信息,请参阅以下部分:
|
||||
|
||||
- 第一个查询选项是调整使用的Runtime Filter类型,大多数情况下,您只需要调整这一个选项,其他选项保持默认即可。
|
||||
- `runtime_filter_type`: 包括Bloom Filter、MinMax Filter、IN predicate、IN Or Bloom Filter,默认会使用IN Or Bloom Filter,部分情况下同时使用Bloom Filter、MinMax Filter、IN predicate时性能更高。
|
||||
- 其他查询选项通常仅在某些特定场景下,才需进一步调整以达到最优效果。通常只在性能测试后,针对资源密集型、运行耗时足够长且频率足够高的查询进行优化。
|
||||
- `runtime_filter_mode`: 用于调整Runtime Filter的下推策略,包括OFF、LOCAL、GLOBAL三种策略,默认设置为GLOBAL策略
|
||||
- `runtime_filter_wait_time_ms`: 左表的ScanNode等待每个Runtime Filter的时间,默认1000ms
|
||||
- `runtime_filters_max_num`: 每个查询可应用的Runtime Filter中Bloom Filter的最大数量,默认10
|
||||
- `runtime_bloom_filter_min_size`: Runtime Filter中Bloom Filter的最小长度,默认1048576(1M)
|
||||
- `runtime_bloom_filter_max_size`: Runtime Filter中Bloom Filter的最大长度,默认16777216(16M)
|
||||
- `runtime_bloom_filter_size`: Runtime Filter中Bloom Filter的默认长度,默认2097152(2M)
|
||||
- `runtime_filter_max_in_num`: 如果join右表数据行数大于这个值,我们将不生成IN predicate,默认1024
|
||||
|
||||
下面对查询选项做进一步说明。
|
||||
|
||||
#### 1.runtime_filter_type
|
||||
|
||||
使用的Runtime Filter类型。
|
||||
|
||||
**类型**: 数字(1, 2, 4, 8)或者相对应的助记符字符串(IN, BLOOM_FILTER, MIN_MAX, `IN_OR_BLOOM_FILTER`),默认8(`IN_OR_BLOOM_FILTER`),使用多个时用逗号分隔,注意需要加引号,或者将任意多个类型的数字相加,例如:
|
||||
|
||||
```sql
|
||||
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```sql
|
||||
set runtime_filter_type=7;
|
||||
```
|
||||
|
||||
**使用注意事项**
|
||||
|
||||
- **IN or Bloom Filter**: 根据右表在执行过程中的真实行数,由系统自动判断使用 IN predicate 还是 Bloom Filter
|
||||
- 默认在右表数据行数少于1024时会使用IN predicate(可通过session变量中的`runtime_filter_max_in_num`调整),否则使用Bloom filter。
|
||||
- **Bloom Filter**: 有一定的误判率,导致过滤的数据比预期少一点,但不会导致最终结果不准确,在大部分情况下Bloom Filter都可以提升性能或对性能没有显著影响,但在部分情况下会导致性能降低。
|
||||
- Bloom Filter构建和应用的开销较高,所以当过滤率较低时,或者左表数据量较少时,Bloom Filter可能会导致性能降低。
|
||||
- 目前只有左表的Key列应用Bloom Filter才能下推到存储引擎,而测试结果显示Bloom Filter不下推到存储引擎时往往会导致性能降低。
|
||||
- 目前Bloom Filter仅在ScanNode上使用表达式过滤时有短路(short-circuit)逻辑,即当假阳性率过高时,不继续使用Bloom Filter,但当Bloom Filter下推到存储引擎后没有短路逻辑,所以当过滤率较低时可能导致性能降低。
|
||||
- **MinMax Filter**: 包含最大值和最小值,从而过滤小于最小值和大于最大值的数据,MinMax Filter的过滤效果与join on clause中Key列的类型和左右表数据分布有关。
|
||||
- 当join on clause中Key列的类型为int/bigint/double等时,极端情况下,如果左右表的最大最小值相同则没有效果,反之右表最大值小于左表最小值,或右表最小值大于左表最大值,则效果最好。
|
||||
- 当join on clause中Key列的类型为varchar等时,应用MinMax Filter往往会导致性能降低。
|
||||
- **IN predicate**: 根据join on clause中Key列在右表上的所有值构建IN predicate,使用构建的IN predicate在左表上过滤,相比Bloom Filter构建和应用的开销更低,在右表数据量较少时往往性能更高。
|
||||
- 默认只有右表数据行数少于1024才会下推(可通过session变量中的`runtime_filter_max_in_num`调整)。
|
||||
- 目前IN predicate已实现合并方法。
|
||||
- 当同时指定In predicate和其他filter,并且in的过滤数值没达到runtime_filter_max_in_num时,会尝试把其他filter去除掉。原因是In predicate是精确的过滤条件,即使没有其他filter也可以高效过滤,如果同时使用则其他filter会做无用功。目前仅在Runtime filter的生产者和消费者处于同一个fragment时才会有去除非in filter的逻辑。
|
||||
|
||||
#### 2.runtime_filter_mode
|
||||
|
||||
用于控制Runtime Filter在instance之间传输的范围。
|
||||
|
||||
**类型**: 数字(0, 1, 2)或者相对应的助记符字符串(OFF, LOCAL, GLOBAL),默认2(GLOBAL)。
|
||||
|
||||
**使用注意事项**
|
||||
|
||||
LOCAL:相对保守,构建的Runtime Filter只能在同一个instance(查询执行的最小单元)上同一个Fragment中使用,即Runtime Filter生产者(构建Filter的HashJoinNode)和消费者(使用RuntimeFilter的ScanNode)在同一个Fragment,比如broadcast join的一般场景;
|
||||
|
||||
GLOBAL:相对激进,除满足LOCAL策略的场景外,还可以将Runtime Filter合并后通过网络传输到不同instance上的不同Fragment中使用,比如Runtime Filter生产者和消费者在不同Fragment,比如shuffle join。
|
||||
|
||||
大多数情况下GLOBAL策略可以在更广泛的场景对查询进行优化,但在有些shuffle join中生成和合并Runtime Filter的开销超过给查询带来的性能优势,可以考虑更改为LOCAL策略。
|
||||
|
||||
如果集群中涉及的join查询不会因为Runtime Filter而提高性能,您可以将设置更改为OFF,从而完全关闭该功能。
|
||||
|
||||
在不同Fragment上构建和应用Runtime Filter时,需要合并Runtime Filter的原因和策略可参阅 [ISSUE 6116(opens new window)](https://github.com/apache/incubator-doris/issues/6116)
|
||||
|
||||
#### 3.runtime_filter_wait_time_ms
|
||||
|
||||
Runtime Filter的等待耗时。
|
||||
|
||||
**类型**: 整数,默认1000,单位ms
|
||||
|
||||
**使用注意事项**
|
||||
|
||||
在开启Runtime Filter后,左表的ScanNode会为每一个分配给自己的Runtime Filter等待一段时间再扫描数据,即如果ScanNode被分配了3个Runtime Filter,那么它最多会等待3000ms。
|
||||
|
||||
因为Runtime Filter的构建和合并均需要时间,ScanNode会尝试将等待时间内到达的Runtime Filter下推到存储引擎,如果超过等待时间后,ScanNode会使用已经到达的Runtime Filter直接开始扫描数据。
|
||||
|
||||
如果Runtime Filter在ScanNode开始扫描之后到达,则ScanNode不会将该Runtime Filter下推到存储引擎,而是对已经从存储引擎扫描上来的数据,在ScanNode上基于该Runtime Filter使用表达式过滤,之前已经扫描的数据则不会应用该Runtime Filter,这样得到的中间数据规模会大于最优解,但可以避免严重的裂化。
|
||||
|
||||
如果集群比较繁忙,并且集群上有许多资源密集型或长耗时的查询,可以考虑增加等待时间,以避免复杂查询错过优化机会。如果集群负载较轻,并且集群上有许多只需要几秒的小查询,可以考虑减少等待时间,以避免每个查询增加1s的延迟。
|
||||
|
||||
#### 4.runtime_filters_max_num
|
||||
|
||||
每个查询生成的Runtime Filter中Bloom Filter数量的上限。
|
||||
|
||||
**类型**: 整数,默认10
|
||||
|
||||
**使用注意事项** 目前仅对Bloom Filter的数量进行限制,因为相比MinMax Filter和IN predicate,Bloom Filter构建和应用的代价更高。
|
||||
|
||||
如果生成的Bloom Filter超过允许的最大数量,则保留选择性大的Bloom Filter,选择性大意味着预期可以过滤更多的行。这个设置可以防止Bloom Filter耗费过多的内存开销而导致潜在的问题。
|
||||
|
||||
```text
|
||||
选择性=(HashJoinNode Cardinality / HashJoinNode left child Cardinality)
|
||||
-- 因为目前FE拿到Cardinality不准,所以这里Bloom Filter计算的选择性与实际不准,因此最终可能只是随机保留了部分Bloom Filter。
|
||||
```
|
||||
|
||||
仅在对涉及大表间join的某些长耗时查询进行调优时,才需要调整此查询选项。
|
||||
|
||||
#### 5.Bloom Filter长度相关参数
|
||||
|
||||
包括`runtime_bloom_filter_min_size`、`runtime_bloom_filter_max_size`、`runtime_bloom_filter_size`,用于确定Runtime Filter使用的Bloom Filter数据结构的大小(以字节为单位)。
|
||||
|
||||
**类型**: 整数
|
||||
|
||||
**使用注意事项** 因为需要保证每个HashJoinNode构建的Bloom Filter长度相同才能合并,所以目前在FE查询规划时计算Bloom Filter的长度。
|
||||
|
||||
如果能拿到join右表统计信息中的数据行数(Cardinality),会尝试根据Cardinality估计Bloom Filter的最佳大小,并四舍五入到最接近的2的幂(以2为底的log值)。如果无法拿到右表的Cardinality,则会使用默认的Bloom Filter长度`runtime_bloom_filter_size`。`runtime_bloom_filter_min_size`和`runtime_bloom_filter_max_size`用于限制最终使用的Bloom Filter长度最小和最大值。
|
||||
|
||||
更大的Bloom Filter在处理高基数的输入集时更有效,但需要消耗更多的内存。假如查询中需要过滤高基数列(比如含有数百万个不同的取值),可以考虑增加`runtime_bloom_filter_size`的值进行一些基准测试,这有助于使Bloom Filter过滤的更加精准,从而获得预期的性能提升。
|
||||
|
||||
Bloom Filter的有效性取决于查询的数据分布,因此通常仅对一些特定查询额外调整其Bloom Filter长度,而不是全局修改,一般仅在对涉及大表间join的某些长耗时查询进行调优时,才需要调整此查询选项。
|
||||
|
||||
### 查看query生成的Runtime Filter
|
||||
|
||||
`explain`命令可以显示的查询计划中包括每个Fragment使用的join on clause信息,以及Fragment生成和使用Runtime Filter的注释,从而确认是否将Runtime Filter应用到了期望的join on clause上。
|
||||
|
||||
- 生成Runtime Filter的Fragment包含的注释例如`runtime filters: filter_id[type] <- table.column`。
|
||||
- 使用Runtime Filter的Fragment包含的注释例如`runtime filters: filter_id[type] -> table.column`。
|
||||
|
||||
下面例子中的查询使用了一个ID为RF000的Runtime Filter。
|
||||
|
||||
```sql
|
||||
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2 PROPERTIES("replication_num" = "1");
|
||||
INSERT INTO test VALUES (1), (2), (3), (4);
|
||||
|
||||
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2 PROPERTIES("replication_num" = "1");
|
||||
INSERT INTO test2 VALUES (3), (4), (5);
|
||||
|
||||
EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
|
||||
+-------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+-------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:`t1` |
|
||||
| |
|
||||
| 4:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: `default_cluster:ssb`.`test`.`t1` |
|
||||
| |
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
|
||||
| | equal join conjunct: `test`.`t1` = `test2`.`t2` |
|
||||
| | runtime filters: RF000[in] <- `test2`.`t2` |
|
||||
| | |
|
||||
| |----3:EXCHANGE |
|
||||
| | |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: test |
|
||||
| runtime filters: RF000[in] -> `test`.`t1` |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: `default_cluster:ssb`.`test2`.`t2` |
|
||||
| |
|
||||
| 1:OlapScanNode |
|
||||
| TABLE: test2 |
|
||||
+-------------------------------------------------------------------+
|
||||
-- 上面`runtime filters`的行显示了`PLAN FRAGMENT 1`的`2:HASH JOIN`生成了ID为RF000的IN predicate,
|
||||
-- 其中`test2`.`t2`的key values仅在运行时可知,
|
||||
-- 在`0:OlapScanNode`使用了该IN predicate用于在读取`test`.`t1`时过滤不必要的数据。
|
||||
|
||||
SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
|
||||
-- 返回2行结果[3, 4];
|
||||
|
||||
-- 通过query的profile(set enable_profile=true;)可以查看查询内部工作的详细信息,
|
||||
-- 包括每个Runtime Filter是否下推、等待耗时、以及OLAP_SCAN_NODE从prepare到接收到Runtime Filter的总时长。
|
||||
RuntimeFilter:in:
|
||||
- HasPushDownToEngine: true
|
||||
- AWaitTimeCost: 0ns
|
||||
- EffectTimeCost: 2.76ms
|
||||
|
||||
-- 此外,在profile的OLAP_SCAN_NODE中还可以查看Runtime Filter下推后的过滤效果和耗时。
|
||||
- RowsVectorPredFiltered: 9.320008M (9320008)
|
||||
- VectorPredEvalTime: 364.39ms
|
||||
```
|
||||
|
||||
## Runtime Filter的规划规则
|
||||
|
||||
1. 只支持对join on clause中的等值条件生成Runtime Filter,不包括Null-safe条件,因为其可能会过滤掉join左表的null值。
|
||||
2. 不支持将Runtime Filter下推到left outer、full outer、anti join的左表;
|
||||
3. 不支持src expr或target expr是常量;
|
||||
4. 不支持src expr和target expr相等;
|
||||
5. 不支持src expr的类型等于`HLL`或者`BITMAP`;
|
||||
6. 目前仅支持将Runtime Filter下推给OlapScanNode;
|
||||
7. 不支持target expr包含NULL-checking表达式,比如`COALESCE/IFNULL/CASE`,因为当outer join上层其他join的join on clause包含NULL-checking表达式并生成Runtime Filter时,将这个Runtime Filter下推到outer join的左表时可能导致结果不正确;
|
||||
8. 不支持target expr中的列(slot)无法在原始表中找到某个等价列;
|
||||
9. 不支持列传导,这包含两种情况:
|
||||
- 一是例如join on clause包含A.k = B.k and B.k = C.k时,目前C.k只可以下推给B.k,而不可以下推给A.k;
|
||||
- 二是例如join on clause包含A.a + B.b = C.c,如果A.a可以列传导到B.a,即A.a和B.a是等价的列,那么可以用B.a替换A.a,然后可以尝试将Runtime Filter下推给B(如果A.a和B.a不是等价列,则不能下推给B,因为target expr必须与唯一一个join左表绑定);
|
||||
10. Target expr和src expr的类型必须相等,因为Bloom Filter基于hash,若类型不等则会尝试将target expr的类型转换为src expr的类型;
|
||||
11. 不支持`PlanNode.Conjuncts`生成的Runtime Filter下推,与HashJoinNode的`eqJoinConjuncts`和`otherJoinConjuncts`不同,`PlanNode.Conjuncts`生成的Runtime Filter在测试中发现可能会导致错误的结果,例如`IN`子查询转换为join时,自动生成的join on clause将保存在`PlanNode.Conjuncts`中,此时应用Runtime Filter可能会导致结果缺少一些行。
|
||||
@ -24,4 +24,227 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Schema Change
|
||||
# Schema Change
|
||||
|
||||
用户可以通过 Schema Change 操作来修改已存在表的 Schema。目前 Doris 支持以下几种修改:
|
||||
|
||||
- 增加、删除列
|
||||
- 修改列类型
|
||||
- 调整列顺序
|
||||
- 增加、修改 Bloom Filter
|
||||
- 增加、删除 bitmap index
|
||||
|
||||
本文档主要介绍如何创建 Schema Change 作业,以及进行 Schema Change 的一些注意事项和常见问题。
|
||||
|
||||
## 名词解释
|
||||
|
||||
- Base Table:基表。每一个表被创建时,都对应一个基表。
|
||||
- Rollup:基于基表或者其他 Rollup 创建出来的上卷表。
|
||||
- Index:物化索引。Rollup 或 Base Table 都被称为物化索引。
|
||||
- Transaction:事务。每一个导入任务都是一个事务,每个事务有一个唯一递增的 Transaction ID。
|
||||
|
||||
## 原理介绍
|
||||
|
||||
执行 Schema Change 的基本过程,是通过原 Index 的数据,生成一份新 Schema 的 Index 的数据。其中主要需要进行两部分数据转换,一是已存在的历史数据的转换,二是在 Schema Change 执行过程中,新到达的导入数据的转换。
|
||||
|
||||
```text
|
||||
+----------+
|
||||
| Load Job |
|
||||
+----+-----+
|
||||
|
|
||||
| Load job generates both origin and new index data
|
||||
|
|
||||
| +------------------+ +---------------+
|
||||
| | Origin Index | | Origin Index |
|
||||
+------> New Incoming Data| | History Data |
|
||||
| +------------------+ +------+--------+
|
||||
| |
|
||||
| | Convert history data
|
||||
| |
|
||||
| +------------------+ +------v--------+
|
||||
| | New Index | | New Index |
|
||||
+------> New Incoming Data| | History Data |
|
||||
+------------------+ +---------------+
|
||||
```
|
||||
|
||||
在开始转换历史数据之前,Doris 会获取一个最新的 Transaction ID。并等待这个 Transaction ID 之前的所有导入事务完成。这个 Transaction ID 成为分水岭。意思是,Doris 保证在分水岭之后的所有导入任务,都会同时为原 Index 和新 Index 生成数据。这样当历史数据转换完成后,可以保证新的 Index 中的数据是完整的。
|
||||
|
||||
## 创建作业
|
||||
|
||||
创建 Schema Change 的具体语法可以查看帮助 [ALTER TABLE COLUMN](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md) 中 Schema Change 部分的说明。
|
||||
|
||||
Schema Change 的创建是一个异步过程,作业提交成功后,用户需要通过 `SHOW ALTER TABLE COLUMN` 命令来查看作业进度。
|
||||
|
||||
## 查看作业
|
||||
|
||||
`SHOW ALTER TABLE COLUMN` 可以查看当前正在执行或已经完成的 Schema Change 作业。当一次 Schema Change 作业涉及到多个 Index 时,该命令会显示多行,每行对应一个 Index。举例如下:
|
||||
|
||||
```sql
|
||||
mysql> SHOW ALTER TABLE COLUMN\G;
|
||||
*************************** 1. row ***************************
|
||||
JobId: 20021
|
||||
TableName: tbl1
|
||||
CreateTime: 2019-08-05 23:03:13
|
||||
FinishTime: 2019-08-05 23:03:42
|
||||
IndexName: tbl1
|
||||
IndexId: 20022
|
||||
OriginIndexId: 20017
|
||||
SchemaVersion: 2:792557838
|
||||
TransactionId: 10023
|
||||
State: FINISHED
|
||||
Msg:
|
||||
Progress: NULL
|
||||
Timeout: 86400
|
||||
1 row in set (0.00 sec)
|
||||
```
|
||||
|
||||
- JobId:每个 Schema Change 作业的唯一 ID。
|
||||
- TableName:Schema Change 对应的基表的表名。
|
||||
- CreateTime:作业创建时间。
|
||||
- FinishedTime:作业结束时间。如未结束,则显示 "N/A"。
|
||||
- IndexName: 本次修改所涉及的某一个 Index 的名称。
|
||||
- IndexId:新的 Index 的唯一 ID。
|
||||
- OriginIndexId:旧的 Index 的唯一 ID。
|
||||
- SchemaVersion:以 M:N 的格式展示。其中 M 表示本次 Schema Change 变更的版本,N 表示对应的 Hash 值。每次 Schema Change,版本都会递增。
|
||||
- TransactionId:转换历史数据的分水岭 transaction ID。
|
||||
- State:作业所在阶段。
|
||||
- PENDING:作业在队列中等待被调度。
|
||||
- WAITING_TXN:等待分水岭 transaction ID 之前的导入任务完成。
|
||||
- RUNNING:历史数据转换中。
|
||||
- FINISHED:作业成功。
|
||||
- CANCELLED:作业失败。
|
||||
- Msg:如果作业失败,这里会显示失败信息。
|
||||
- Progress:作业进度。只有在 RUNNING 状态才会显示进度。进度是以 M/N 的形式显示。其中 N 为 Schema Change 涉及的总副本数。M 为已完成历史数据转换的副本数。
|
||||
- Timeout:作业超时时间。单位秒。
|
||||
|
||||
## 取消作业
|
||||
|
||||
在作业状态不为 FINISHED 或 CANCELLED 的情况下,可以通过以下命令取消 Schema Change 作业:
|
||||
|
||||
```sql
|
||||
CANCEL ALTER TABLE COLUMN FROM tbl_name;
|
||||
```
|
||||
|
||||
## 最佳实践
|
||||
|
||||
Schema Change 可以在一个作业中,对多个 Index 进行不同的修改。举例如下:
|
||||
|
||||
源 Schema:
|
||||
|
||||
```text
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| IndexName | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| tbl1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
| | k3 | INT | No | true | N/A | |
|
||||
| | | | | | | |
|
||||
| rollup2 | k2 | INT | No | true | N/A | |
|
||||
| | | | | | | |
|
||||
| rollup1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
```
|
||||
|
||||
可以通过以下命令给 rollup1 和 rollup2 都加入一列 k4,并且再给 rollup2 加入一列 k5:
|
||||
|
||||
```sql
|
||||
ALTER TABLE tbl1
|
||||
ADD COLUMN k4 INT default "1" to rollup1,
|
||||
ADD COLUMN k4 INT default "1" to rollup2,
|
||||
ADD COLUMN k5 INT default "1" to rollup2;
|
||||
```
|
||||
|
||||
完成后,Schema 变为:
|
||||
|
||||
```text
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| IndexName | Field | Type | Null | Key | Default | Extra |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
| tbl1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
| | k3 | INT | No | true | N/A | |
|
||||
| | k4 | INT | No | true | 1 | |
|
||||
| | k5 | INT | No | true | 1 | |
|
||||
| | | | | | | |
|
||||
| rollup2 | k2 | INT | No | true | N/A | |
|
||||
| | k4 | INT | No | true | 1 | |
|
||||
| | k5 | INT | No | true | 1 | |
|
||||
| | | | | | | |
|
||||
| rollup1 | k1 | INT | No | true | N/A | |
|
||||
| | k2 | INT | No | true | N/A | |
|
||||
| | k4 | INT | No | true | 1 | |
|
||||
+-----------+-------+------+------+------+---------+-------+
|
||||
```
|
||||
|
||||
可以看到,Base 表 tbl1 也自动加入了 k4, k5 列。即给任意 rollup 增加的列,都会自动加入到 Base 表中。
|
||||
|
||||
同时,不允许向 Rollup 中加入 Base 表已经存在的列。如果用户需要这样做,可以重新建立一个包含新增列的 Rollup,之后再删除原 Rollup。
|
||||
|
||||
## 注意事项
|
||||
|
||||
- 一张表在同一时间只能有一个 Schema Change 作业在运行。
|
||||
|
||||
- Schema Change 操作不阻塞导入和查询操作。
|
||||
|
||||
- 分区列和分桶列不能修改。
|
||||
|
||||
- 如果 Schema 中有 REPLACE 方式聚合的 value 列,则不允许删除 Key 列。
|
||||
|
||||
如果删除 Key 列,Doris 无法决定 REPLACE 列的取值。
|
||||
|
||||
Unique 数据模型表的所有非 Key 列都是 REPLACE 聚合方式。
|
||||
|
||||
- 在新增聚合类型为 SUM 或者 REPLACE 的 value 列时,该列的默认值对历史数据没有含义。
|
||||
|
||||
因为历史数据已经失去明细信息,所以默认值的取值并不能实际反映聚合后的取值。
|
||||
|
||||
- 当修改列类型时,除 Type 以外的字段都需要按原列上的信息补全。
|
||||
|
||||
如修改列 `k1 INT SUM NULL DEFAULT "1"` 类型为 BIGINT,则需执行命令如下:
|
||||
|
||||
`ALTER TABLE tbl1 MODIFY COLUMN `k1` BIGINT SUM NULL DEFAULT "1";`
|
||||
|
||||
注意,除新的列类型外,如聚合方式,Nullable 属性,以及默认值都要按照原信息补全。
|
||||
|
||||
- 不支持修改列名称、聚合类型、Nullable 属性、默认值以及列注释。
|
||||
|
||||
## 常见问题
|
||||
|
||||
- Schema Change 的执行速度
|
||||
|
||||
目前 Schema Change 执行速度按照最差效率估计约为 10MB/s。保守起见,用户可以根据这个速率来设置作业的超时时间。
|
||||
|
||||
- 提交作业报错 `Table xxx is not stable. ...`
|
||||
|
||||
Schema Change 只有在表数据完整且非均衡状态下才可以开始。如果表的某些数据分片副本不完整,或者某些副本正在进行均衡操作,则提交会被拒绝。
|
||||
|
||||
数据分片副本是否完整,可以通过以下命令查看:
|
||||
|
||||
`ADMIN SHOW REPLICA STATUS FROM tbl WHERE STATUS != "OK";`
|
||||
|
||||
如果有返回结果,则说明有副本有问题。通常系统会自动修复这些问题,用户也可以通过以下命令优先修复这个表:
|
||||
|
||||
`ADMIN REPAIR TABLE tbl1;`
|
||||
|
||||
用户可以通过以下命令查看是否有正在运行的均衡任务:
|
||||
|
||||
`SHOW PROC "/cluster_balance/pending_tablets";`
|
||||
|
||||
可以等待均衡任务完成,或者通过以下命令临时禁止均衡操作:
|
||||
|
||||
`ADMIN SET FRONTEND CONFIG ("disable_balance" = "true");`
|
||||
|
||||
## 相关配置
|
||||
|
||||
### FE 配置
|
||||
|
||||
- `alter_table_timeout_second`:作业默认超时时间,86400 秒。
|
||||
|
||||
### BE 配置
|
||||
|
||||
- `alter_tablet_worker_count`:在 BE 端用于执行历史数据转换的线程数。默认为 3。如果希望加快 Schema Change 作业的速度,可以适当调大这个参数后重启 BE。但过多的转换线程可能会导致 IO 压力增加,影响其他操作。该线程和 Rollup 作业共用。
|
||||
|
||||
## 更多帮助
|
||||
|
||||
关于Schema Change使用的更多详细语法及最佳实践,请参阅 [ALTER TABLE COLUMN](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md) 命令手册,你也可以在 MySql 客户端命令行下输入 `HELP ALTER TABLE COLUMN` 获取更多帮助信息。
|
||||
|
||||
@ -24,4 +24,111 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 文件管理器
|
||||
# 文件管理器
|
||||
|
||||
Doris 中的一些功能需要使用一些用户自定义的文件。比如用于访问外部数据源的公钥、密钥文件、证书文件等等。文件管理器提供这样一个功能,能够让用户预先上传这些文件并保存在 Doris 系统中,然后可以在其他命令中引用或访问。
|
||||
|
||||
## 名词解释
|
||||
|
||||
- BDBJE:Oracle Berkeley DB Java Edition。FE 中用于持久化元数据的分布式嵌入式数据库。
|
||||
- SmallFileMgr:文件管理器。负责创建并维护用户的文件。
|
||||
|
||||
## 基本概念
|
||||
|
||||
文件是指用户创建并保存在 Doris 中的文件。
|
||||
|
||||
一个文件由 `数据库名称(database)`、`分类(catalog)` 和 `文件名(file_name)` 共同定位。同时每个文件也有一个全局唯一的 id(file_id),作为系统内的标识。
|
||||
|
||||
文件的创建和删除只能由拥有 `admin` 权限的用户进行操作。一个文件隶属于一个数据库。对某一数据库拥有访问权限(查询、导入、修改等等)的用户都可以使用该数据库下创建的文件。
|
||||
|
||||
## 具体操作
|
||||
|
||||
文件管理主要有三个命令:`CREATE FILE`,`SHOW FILE` 和 `DROP FILE`,分别为创建、查看和删除文件。这三个命令的具体语法可以通过连接到 Doris 后,执行 `HELP cmd;` 的方式查看帮助。
|
||||
|
||||
### CREATE FILE
|
||||
|
||||
该语句用于创建并上传一个文件到 Doris 集群,具体操作可查看 [CREATE FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-FILE.md) 。
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
1. 创建文件 ca.pem ,分类为 kafka
|
||||
|
||||
CREATE FILE "ca.pem"
|
||||
PROPERTIES
|
||||
(
|
||||
"url" = "https://test.bj.bcebos.com/kafka-key/ca.pem",
|
||||
"catalog" = "kafka"
|
||||
);
|
||||
|
||||
2. 创建文件 client.key,分类为 my_catalog
|
||||
|
||||
CREATE FILE "client.key"
|
||||
IN my_database
|
||||
PROPERTIES
|
||||
(
|
||||
"url" = "https://test.bj.bcebos.com/kafka-key/client.key",
|
||||
"catalog" = "my_catalog",
|
||||
"md5" = "b5bb901bf10f99205b39a46ac3557dd9"
|
||||
);
|
||||
```
|
||||
|
||||
### SHOW FILE
|
||||
|
||||
该语句可以查看已经创建成功的文件,具体操作可查看 [SHOW FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-FILE.md)。
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
1. 查看数据库 my_database 中已上传的文件
|
||||
|
||||
SHOW FILE FROM my_database;
|
||||
```
|
||||
|
||||
### DROP FILE
|
||||
|
||||
该语句可以查看可以删除一个已经创建的文件,具体操作可查看 [DROP FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-FILE.md)。
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
1. 删除文件 ca.pem
|
||||
|
||||
DROP FILE "ca.pem" properties("catalog" = "kafka");
|
||||
```
|
||||
|
||||
## 实现细节
|
||||
|
||||
### 创建和删除文件
|
||||
|
||||
当用户执行 `CREATE FILE` 命令后,FE 会从给定的 URL 下载文件。并将文件的内容以 Base64 编码的形式直接保存在 FE 的内存中。同时会将文件内容以及文件相关的元信息持久化在 BDBJE 中。所有被创建的文件,其元信息和文件内容都会常驻于 FE 的内存中。如果 FE 宕机重启,也会从 BDBJE 中加载元信息和文件内容到内存中。当文件被删除时,会直接从 FE 内存中删除相关信息,同时也从 BDBJE 中删除持久化的信息。
|
||||
|
||||
### 文件的使用
|
||||
|
||||
如果是 FE 端需要使用创建的文件,则 SmallFileMgr 会直接将 FE 内存中的数据保存为本地文件,存储在指定的目录中,并返回本地的文件路径供使用。
|
||||
|
||||
如果是 BE 端需要使用创建的文件,BE 会通过 FE 的 http 接口 `/api/get_small_file` 将文件内容下载到 BE 上指定的目录中,供使用。同时,BE 也会在内存中记录当前已经下载过的文件的信息。当 BE 请求一个文件时,会先查看本地文件是否存在并校验。如果校验通过,则直接返回本地文件路径。如果校验失败,则会删除本地文件,重新从 FE 下载。当 BE 重启时,会预先加载本地的文件到内存中。
|
||||
|
||||
## 使用限制
|
||||
|
||||
因为文件元信息和内容都存储于 FE 的内存中。所以默认仅支持上传大小在 1MB 以内的文件。并且总文件数量限制为 100 个。可以通过下一小节介绍的配置项进行修改。
|
||||
|
||||
## 相关配置
|
||||
|
||||
1. FE 配置
|
||||
|
||||
- `small_file_dir`:用于存放上传文件的路径,默认为 FE 运行目录的 `small_files/` 目录下。
|
||||
- `max_small_file_size_bytes`:单个文件大小限制,单位为字节。默认为 1MB。大于该配置的文件创建将会被拒绝。
|
||||
- `max_small_file_number`:一个 Doris 集群支持的总文件数量。默认为 100。当创建的文件数超过这个值后,后续的创建将会被拒绝。
|
||||
|
||||
> 如果需要上传更多文件或提高单个文件的大小限制,可以通过 `ADMIN SET CONFIG` 命令修改 `max_small_file_size_bytes` 和 `max_small_file_number` 参数。但文件数量和大小的增加,会导致 FE 内存使用量的增加。
|
||||
|
||||
2. BE 配置
|
||||
|
||||
- `small_file_dir`:用于存放从 FE 下载的文件的路径,默认为 BE 运行目录的 `lib/small_files/` 目录下。
|
||||
|
||||
|
||||
|
||||
## 更多帮助
|
||||
|
||||
关于文件管理器使用的更多详细语法及最佳实践,请参阅 [CREATE FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-FILE.html) 、[DROP FILE](../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-FILE.html) 和 [SHOW FILE](../sql-manual/sql-reference-v2/Show-Statements/SHOW-FILE.md) 命令手册,你也可以在 MySql 客户端命令行下输入 `HELP CREATE FILE` 、`HELP DROP FILE`和`HELP SHOW FILE` 获取更多帮助信息。
|
||||
@ -1,6 +1,6 @@
|
||||
---
|
||||
{
|
||||
"title": "时区设置",
|
||||
"title": "时区",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
@ -24,4 +24,57 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 时区
|
||||
# 时区
|
||||
|
||||
Doris 支持多时区设置
|
||||
|
||||
## 基本概念
|
||||
|
||||
Doris 内部存在多个时区相关参数
|
||||
|
||||
- system_time_zone : 当服务器启动时,会根据机器设置时区自动设置,设置后不可修改。
|
||||
- time_zone : 服务器当前时区,区分session级别和global级别
|
||||
|
||||
## 具体操作
|
||||
|
||||
1. show variables like '%time_zone%'
|
||||
|
||||
查看当前时区相关配置
|
||||
|
||||
2. SET time_zone = 'Asia/Shanghai'
|
||||
|
||||
该命令可以设置session级别的时区,连接断开后失效
|
||||
|
||||
3. SET global time_zone = 'Asia/Shanghai'
|
||||
|
||||
该命令可以设置global级别的时区参数,fe会将参数持久化,连接断开后不失效
|
||||
|
||||
### 时区的影响
|
||||
|
||||
时区设置会影响对时区敏感的时间值的显示和存储。
|
||||
|
||||
包括NOW()或CURTIME()等时间函数显示的值,也包括show load, show backends中的时间值。
|
||||
|
||||
但不会影响 create table 中时间类型分区列的 less than 值,也不会影响存储为 date/datetime 类型的值的显示。
|
||||
|
||||
受时区影响的函数:
|
||||
|
||||
- `FROM_UNIXTIME`:给定一个 UTC 时间戳,返回指定时区的日期时间:如 `FROM_UNIXTIME(0)`, 返回 CST 时区:`1970-01-01 08:00:00`。
|
||||
- `UNIX_TIMESTAMP`:给定一个指定时区日期时间,返回 UTC 时间戳:如 CST 时区 `UNIX_TIMESTAMP('1970-01-01 08:00:00')`,返回 `0`。
|
||||
- `CURTIME`:返回指定时区时间。
|
||||
- `NOW`:返指定地时区日期时间。
|
||||
- `CONVERT_TZ`:将一个日期时间从一个指定时区转换到另一个指定时区。
|
||||
|
||||
## 使用限制
|
||||
|
||||
时区值可以使用几种格式给出,不区分大小写:
|
||||
|
||||
- 表示UTC偏移量的字符串,如'+10:00'或'-6:00'
|
||||
- 标准时区格式,如"Asia/Shanghai"、"America/Los_Angeles"
|
||||
- 不支持缩写时区格式,如"MET"、"CTT"。因为缩写时区在不同场景下存在歧义,不建议使用。
|
||||
- 为了兼容Doris,支持CST缩写时区,内部会将CST转移为"Asia/Shanghai"的中国标准时区
|
||||
|
||||
## 时区格式列表
|
||||
|
||||
[List of tz database time zones](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones)
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
---
|
||||
{
|
||||
"title": "变量及时区",
|
||||
"title": "变量",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
@ -24,4 +24,467 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 变量
|
||||
# 变量
|
||||
|
||||
本文档主要介绍当前支持的变量(variables)。
|
||||
|
||||
Doris 中的变量参考 MySQL 中的变量设置。但部分变量仅用于兼容一些 MySQL 客户端协议,并不产生其在 MySQL 数据库中的实际意义。
|
||||
|
||||
## 变量设置与查看
|
||||
|
||||
### 查看
|
||||
|
||||
可以通过 `SHOW VARIABLES [LIKE 'xxx'];` 查看所有或指定的变量。如:
|
||||
|
||||
```sql
|
||||
SHOW VARIABLES;
|
||||
SHOW VARIABLES LIKE '%time_zone%';
|
||||
```
|
||||
|
||||
### 设置
|
||||
|
||||
部分变量可以设置全局生效或仅当前会话生效。设置全局生效后,后续新的会话连接中会沿用设置值。而设置仅当前会话生效,则变量仅对当前会话产生作用。
|
||||
|
||||
仅当前会话生效,通过 `SET var_name=xxx;` 语句来设置。如:
|
||||
|
||||
```sql
|
||||
SET exec_mem_limit = 137438953472;
|
||||
SET forward_to_master = true;
|
||||
SET time_zone = "Asia/Shanghai";
|
||||
```
|
||||
|
||||
全局生效,通过 `SET GLOBAL var_name=xxx;` 设置。如:
|
||||
|
||||
```sql
|
||||
SET GLOBAL exec_mem_limit = 137438953472
|
||||
```
|
||||
|
||||
> 注1:只有 ADMIN 用户可以设置变量的全局生效。 注2:全局生效的变量不影响当前会话的变量值,仅影响新的会话中的变量。
|
||||
|
||||
既支持当前会话生效又支持全局生效的变量包括:
|
||||
|
||||
- `time_zone`
|
||||
- `wait_timeout`
|
||||
- `sql_mode`
|
||||
- `enable_profile`
|
||||
- `query_timeout`
|
||||
- `exec_mem_limit`
|
||||
- `batch_size`
|
||||
- `allow_partition_column_nullable`
|
||||
- `insert_visible_timeout_ms`
|
||||
- `enable_fold_constant_by_be`
|
||||
|
||||
只支持全局生效的变量包括:
|
||||
|
||||
- `default_rowset_type`
|
||||
|
||||
同时,变量设置也支持常量表达式。如:
|
||||
|
||||
```sql
|
||||
SET exec_mem_limit = 10 * 1024 * 1024 * 1024;
|
||||
SET forward_to_master = concat('tr', 'u', 'e');
|
||||
```
|
||||
|
||||
### 在查询语句中设置变量
|
||||
|
||||
在一些场景中,我们可能需要对某些查询有针对性的设置变量。 通过使用SET_VAR提示可以在查询中设置会话变量(在单个语句内生效)。例子:
|
||||
|
||||
```sql
|
||||
SELECT /*+ SET_VAR(exec_mem_limit = 8589934592) */ name FROM people ORDER BY name;
|
||||
SELECT /*+ SET_VAR(query_timeout = 1, enable_partition_cache=true) */ sleep(3);
|
||||
```
|
||||
|
||||
注意注释必须以/*+ 开头,并且只能跟随在SELECT之后。
|
||||
|
||||
## 支持的变量
|
||||
|
||||
- `SQL_AUTO_IS_NULL`
|
||||
|
||||
用于兼容 JDBC 连接池 C3P0。 无实际作用。
|
||||
|
||||
- `auto_increment_increment`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `autocommit`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `batch_size`
|
||||
|
||||
用于指定在查询执行过程中,各个节点传输的单个数据包的行数。默认一个数据包的行数为 1024 行,即源端节点每产生 1024 行数据后,打包发给目的节点。
|
||||
|
||||
较大的行数,会在扫描大数据量场景下提升查询的吞吐,但可能会在小查询场景下增加查询延迟。同时,也会增加查询的内存开销。建议设置范围 1024 至 4096。
|
||||
|
||||
- `character_set_client`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `character_set_connection`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `character_set_results`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `character_set_server`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `codegen_level`
|
||||
|
||||
用于设置 LLVM codegen 的等级。(当前未生效)。
|
||||
|
||||
- `collation_connection`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `collation_database`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `collation_server`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `delete_without_partition`
|
||||
|
||||
设置为 true 时。当使用 delete 命令删除分区表数据时,可以不指定分区。delete 操作将会自动应用到所有分区。
|
||||
|
||||
但注意,自动应用到所有分区可能到导致 delete 命令耗时触发大量子任务导致耗时较长。如无必要,不建议开启。
|
||||
|
||||
- `disable_colocate_join`
|
||||
|
||||
控制是否启用 [Colocation Join](https://doris.apache.org/zh-CN/administrator-guide/colocation-join.html) 功能。默认为 false,表示启用该功能。true 表示禁用该功能。当该功能被禁用后,查询规划将不会尝试执行 Colocation Join。
|
||||
|
||||
- `enable_bucket_shuffle_join`
|
||||
|
||||
控制是否启用 [Bucket Shuffle Join](https://doris.apache.org/zh-CN/administrator-guide/bucket-shuffle-join.html) 功能。默认为 true,表示启用该功能。false 表示禁用该功能。当该功能被禁用后,查询规划将不会尝试执行 Bucket Shuffle Join。
|
||||
|
||||
- `disable_streaming_preaggregations`
|
||||
|
||||
控制是否开启流式预聚合。默认为 false,即开启。当前不可设置,且默认开启。
|
||||
|
||||
- `enable_insert_strict`
|
||||
|
||||
用于设置通过 INSERT 语句进行数据导入时,是否开启 `strict` 模式。默认为 false,即不开启 `strict` 模式。关于该模式的介绍,可以参阅 [这里](https://doris.apache.org/zh-CN/administrator-guide/load-data/insert-into-manual.html)。
|
||||
|
||||
- `enable_spilling`
|
||||
|
||||
用于设置是否开启大数据量落盘排序。默认为 false,即关闭该功能。当用户未指定 ORDER BY 子句的 LIMIT 条件,同时设置 `enable_spilling` 为 true 时,才会开启落盘排序。该功能启用后,会使用 BE 数据目录下 `doris-scratch/` 目录存放临时的落盘数据,并在查询结束后,清空临时数据。
|
||||
|
||||
该功能主要用于使用有限的内存进行大数据量的排序操作。
|
||||
|
||||
注意,该功能为实验性质,不保证稳定性,请谨慎开启。
|
||||
|
||||
- `exec_mem_limit`
|
||||
|
||||
用于设置单个查询的内存限制。默认为 2GB,单位为B/K/KB/M/MB/G/GB/T/TB/P/PB, 默认为B。
|
||||
|
||||
该参数用于限制一个查询计划中,单个查询计划的实例所能使用的内存。一个查询计划可能有多个实例,一个 BE 节点可能执行一个或多个实例。所以该参数并不能准确限制一个查询在整个集群的内存使用,也不能准确限制一个查询在单一 BE 节点上的内存使用。具体需要根据生成的查询计划判断。
|
||||
|
||||
通常只有在一些阻塞节点(如排序节点、聚合节点、Join 节点)上才会消耗较多的内存,而其他节点(如扫描节点)中,数据为流式通过,并不会占用较多的内存。
|
||||
|
||||
当出现 `Memory Exceed Limit` 错误时,可以尝试指数级增加该参数,如 4G、8G、16G 等。
|
||||
|
||||
- `forward_to_master`
|
||||
|
||||
用户设置是否将一些show 类命令转发到 Master FE 节点执行。默认为 `true`,即转发。Doris 中存在多个 FE 节点,其中一个为 Master 节点。通常用户可以连接任意 FE 节点进行全功能操作。但部分信息查看指令,只有从 Master FE 节点才能获取详细信息。
|
||||
|
||||
如 `SHOW BACKENDS;` 命令,如果不转发到 Master FE 节点,则仅能看到节点是否存活等一些基本信息,而转发到 Master FE 则可以获取包括节点启动时间、最后一次心跳时间等更详细的信息。
|
||||
|
||||
当前受该参数影响的命令如下:
|
||||
|
||||
1. `SHOW FRONTENDS;`
|
||||
|
||||
转发到 Master 可以查看最后一次心跳信息。
|
||||
|
||||
2. `SHOW BACKENDS;`
|
||||
|
||||
转发到 Master 可以查看启动时间、最后一次心跳信息、磁盘容量信息。
|
||||
|
||||
3. `SHOW BROKER;`
|
||||
|
||||
转发到 Master 可以查看启动时间、最后一次心跳信息。
|
||||
|
||||
4. `SHOW TABLET;`/`ADMIN SHOW REPLICA DISTRIBUTION;`/`ADMIN SHOW REPLICA STATUS;`
|
||||
|
||||
转发到 Master 可以查看 Master FE 元数据中存储的 tablet 信息。正常情况下,不同 FE 元数据中 tablet 信息应该是一致的。当出现问题时,可以通过这个方法比较当前 FE 和 Master FE 元数据的差异。
|
||||
|
||||
5. `SHOW PROC;`
|
||||
|
||||
转发到 Master 可以查看 Master FE 元数据中存储的相关 PROC 的信息。主要用于元数据比对。
|
||||
|
||||
- `init_connect`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `interactive_timeout`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `enable_profile`
|
||||
|
||||
用于设置是否需要查看查询的 profile。默认为 false,即不需要 profile。
|
||||
|
||||
默认情况下,只有在查询发生错误时,BE 才会发送 profile 给 FE,用于查看错误。正常结束的查询不会发送 profile。发送 profile 会产生一定的网络开销,对高并发查询场景不利。 当用户希望对一个查询的 profile 进行分析时,可以将这个变量设为 true 后,发送查询。查询结束后,可以通过在当前连接的 FE 的 web 页面查看到 profile:
|
||||
|
||||
`fe_host:fe_http_port/query`
|
||||
|
||||
其中会显示最近100条,开启 `enable_profile` 的查询的 profile。
|
||||
|
||||
- `language`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `license`
|
||||
|
||||
显示 Doris 的 License。无其他作用。
|
||||
|
||||
- `load_mem_limit`
|
||||
|
||||
用于指定导入操作的内存限制。默认为 0,即表示不使用该变量,而采用 `exec_mem_limit` 作为导入操作的内存限制。
|
||||
|
||||
这个变量仅用于 INSERT 操作。因为 INSERT 操作设计查询和导入两个部分,如果用户不设置此变量,则查询和导入操作各自的内存限制均为 `exec_mem_limit`。否则,INSERT 的查询部分内存限制为 `exec_mem_limit`,而导入部分限制为 `load_mem_limit`。
|
||||
|
||||
其他导入方式,如 BROKER LOAD,STREAM LOAD 的内存限制依然使用 `exec_mem_limit`。
|
||||
|
||||
- `lower_case_table_names`
|
||||
|
||||
用于控制用户表表名大小写是否敏感。
|
||||
|
||||
值为 0 时,表名大小写敏感。默认为0。
|
||||
|
||||
值为 1 时,表名大小写不敏感,doris在存储和查询时会将表名转换为小写。
|
||||
优点是在一条语句中可以使用表名的任意大小写形式,下面的sql是正确的:
|
||||
|
||||
```sql
|
||||
mysql> show tables;
|
||||
+------------------+
|
||||
| Tables_in_testdb |
|
||||
+------------------+
|
||||
| cost |
|
||||
+------------------+
|
||||
|
||||
mysql> select * from COST where COst.id < 100 order by cost.id;
|
||||
```
|
||||
|
||||
缺点是建表后无法获得建表语句中指定的表名,`show tables` 查看的表名为指定表名的小写。
|
||||
|
||||
值为 2 时,表名大小写不敏感,doris存储建表语句中指定的表名,查询时转换为小写进行比较。 优点是`show tables` 查看的表名为建表语句中指定的表名;
|
||||
缺点是同一语句中只能使用表名的一种大小写形式,例如对`cost` 表使用表名 `COST` 进行查询:
|
||||
|
||||
```sql
|
||||
mysql> select * from COST where COST.id < 100 order by COST.id;
|
||||
```
|
||||
|
||||
该变量兼容MySQL。需在集群初始化时通过fe.conf 指定 `lower_case_table_names=`进行配置,集群初始化完成后无法通过`set` 语句修改该变量,也无法通过重启、升级集群修改该变量。
|
||||
|
||||
information_schema中的系统视图表名不区分大小写,当`lower_case_table_names`值为 0 时,表现为 2。
|
||||
|
||||
- `max_allowed_packet`
|
||||
|
||||
用于兼容 JDBC 连接池 C3P0。 无实际作用。
|
||||
|
||||
- `max_pushdown_conditions_per_column`
|
||||
|
||||
该变量的具体含义请参阅 [BE 配置项](https://doris.apache.org/zh-CN/administrator-guide/config/be_config.html) 中 `max_pushdown_conditions_per_column` 的说明。该变量默认置为 -1,表示使用 `be.conf` 中的配置值。如果设置大于 0,则当前会话中的查询会使用该变量值,而忽略 `be.conf` 中的配置值。
|
||||
|
||||
- `max_scan_key_num`
|
||||
|
||||
该变量的具体含义请参阅 [BE 配置项](https://doris.apache.org/zh-CN/administrator-guide/config/be_config.html) 中 `doris_max_scan_key_num` 的说明。该变量默认置为 -1,表示使用 `be.conf` 中的配置值。如果设置大于 0,则当前会话中的查询会使用该变量值,而忽略 `be.conf` 中的配置值。
|
||||
|
||||
- `net_buffer_length`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `net_read_timeout`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `net_write_timeout`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `parallel_exchange_instance_num`
|
||||
|
||||
用于设置执行计划中,一个上层节点接收下层节点数据所使用的 exchange node 数量。默认为 -1,即表示 exchange node 数量等于下层节点执行实例的个数(默认行为)。当设置大于0,并且小于下层节点执行实例的个数,则 exchange node 数量等于设置值。
|
||||
|
||||
在一个分布式的查询执行计划中,上层节点通常有一个或多个 exchange node 用于接收来自下层节点在不同 BE 上的执行实例的数据。通常 exchange node 数量等于下层节点执行实例数量。
|
||||
|
||||
在一些聚合查询场景下,如果底层需要扫描的数据量较大,但聚合之后的数据量很小,则可以尝试修改此变量为一个较小的值,可以降低此类查询的资源开销。如在 DUPLICATE KEY 明细模型上进行聚合查询的场景。
|
||||
|
||||
- `parallel_fragment_exec_instance_num`
|
||||
|
||||
针对扫描节点,设置其在每个 BE 节点上,执行实例的个数。默认为 1。
|
||||
|
||||
一个查询计划通常会产生一组 scan range,即需要扫描的数据范围。这些数据分布在多个 BE 节点上。一个 BE 节点会有一个或多个 scan range。默认情况下,每个 BE 节点的一组 scan range 只由一个执行实例处理。当机器资源比较充裕时,可以将增加该变量,让更多的执行实例同时处理一组 scan range,从而提升查询效率。
|
||||
|
||||
而 scan 实例的数量决定了上层其他执行节点,如聚合节点,join 节点的数量。因此相当于增加了整个查询计划执行的并发度。修改该参数会对大查询效率提升有帮助,但较大数值会消耗更多的机器资源,如CPU、内存、磁盘IO。
|
||||
|
||||
- `query_cache_size`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `query_cache_type`
|
||||
|
||||
用于兼容 JDBC 连接池 C3P0。 无实际作用。
|
||||
|
||||
- `query_timeout`
|
||||
|
||||
用于设置查询超时。该变量会作用于当前连接中所有的查询语句,以及 INSERT 语句。默认为 5 分钟,单位为秒。
|
||||
|
||||
- `resource_group`
|
||||
|
||||
暂不使用。
|
||||
|
||||
- `send_batch_parallelism`
|
||||
|
||||
用于设置执行 InsertStmt 操作时发送批处理数据的默认并行度,如果并行度的值超过 BE 配置中的 `max_send_batch_parallelism_per_job`,那么作为协调点的 BE 将使用 `max_send_batch_parallelism_per_job` 的值。
|
||||
|
||||
- `sql_mode`
|
||||
|
||||
用于指定 SQL 模式,以适应某些 SQL 方言。关于 SQL 模式,可参阅 [这里](https://doris.apache.org/zh-CN/administrator-guide/sql-mode.html)。
|
||||
|
||||
- `sql_safe_updates`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `sql_select_limit`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `system_time_zone`
|
||||
|
||||
显示当前系统时区。不可更改。
|
||||
|
||||
- `time_zone`
|
||||
|
||||
用于设置当前会话的时区。时区会对某些时间函数的结果产生影响。关于时区,可以参阅 [这里](https://doris.apache.org/zh-CN/administrator-guide/time-zone.html)。
|
||||
|
||||
- `tx_isolation`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `tx_read_only`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `transaction_read_only`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `transaction_isolation`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `version`
|
||||
|
||||
用于兼容 MySQL 客户端。无实际作用。
|
||||
|
||||
- `performance_schema`
|
||||
|
||||
用于兼容 8.0.16及以上版本的MySQL JDBC。无实际作用。
|
||||
|
||||
- `version_comment`
|
||||
|
||||
用于显示 Doris 的版本。不可更改。
|
||||
|
||||
- `wait_timeout`
|
||||
|
||||
用于设置空闲连接的连接时长。当一个空闲连接在该时长内与 Doris 没有任何交互,则 Doris 会主动断开这个链接。默认为 8 小时,单位为秒。
|
||||
|
||||
- `default_rowset_type`
|
||||
|
||||
用于设置计算节点存储引擎默认的存储格式。当前支持的存储格式包括:alpha/beta。
|
||||
|
||||
- `use_v2_rollup`
|
||||
|
||||
用于控制查询使用segment v2存储格式的rollup索引获取数据。该变量用于上线segment v2的时候,进行验证使用;其他情况,不建议使用。
|
||||
|
||||
- `rewrite_count_distinct_to_bitmap_hll`
|
||||
|
||||
是否将 bitmap 和 hll 类型的 count distinct 查询重写为 bitmap_union_count 和 hll_union_agg 。
|
||||
|
||||
- `prefer_join_method`
|
||||
|
||||
在选择join的具体实现方式是broadcast join还是shuffle join时,如果broadcast join cost和shuffle join cost相等时,优先选择哪种join方式。
|
||||
|
||||
目前该变量的可选值为"broadcast" 或者 "shuffle"。
|
||||
|
||||
- `allow_partition_column_nullable`
|
||||
|
||||
建表时是否允许分区列为NULL。默认为true,表示允许为NULL。false 表示分区列必须被定义为NOT NULL
|
||||
|
||||
- `insert_visible_timeout_ms`
|
||||
|
||||
在执行insert语句时,导入动作(查询和插入)完成后,还需要等待事务提交,使数据可见。此参数控制等待数据可见的超时时间,默认为10000,最小为1000。
|
||||
|
||||
- `enable_exchange_node_parallel_merge`
|
||||
|
||||
在一个排序的查询之中,一个上层节点接收下层节点有序数据时,会在exchange node上进行对应的排序来保证最终的数据是有序的。但是单线程进行多路数据归并时,如果数据量过大,会导致exchange node的单点的归并瓶颈。
|
||||
|
||||
Doris在这部分进行了优化处理,如果下层的数据节点过多。exchange node会启动多线程进行并行归并来加速排序过程。该参数默认为False,即表示 exchange node 不采取并行的归并排序,来减少额外的CPU和内存消耗。
|
||||
|
||||
- `extract_wide_range_expr`
|
||||
|
||||
用于控制是否开启 「宽泛公因式提取」的优化。取值有两种:true 和 false 。默认情况下开启。
|
||||
|
||||
- `enable_fold_constant_by_be`
|
||||
|
||||
用于控制常量折叠的计算方式。默认是 `false`,即在 `FE` 进行计算;若设置为 `true`,则通过 `RPC` 请求经 `BE` 计算。
|
||||
|
||||
- `cpu_resource_limit`
|
||||
|
||||
用于限制一个查询的资源开销。这是一个实验性质的功能。目前的实现是限制一个查询在单个节点上的scan线程数量。限制了scan线程数,从底层返回的数据速度变慢,从而限制了查询整体的计算资源开销。假设设置为 2,则一个查询在单节点上最多使用2个scan线程。
|
||||
|
||||
该参数会覆盖 `parallel_fragment_exec_instance_num` 的效果。即假设 `parallel_fragment_exec_instance_num` 设置为4,而该参数设置为2。则单个节点上的4个执行实例会共享最多2个扫描线程。
|
||||
|
||||
该参数会被 user property 中的 `cpu_resource_limit` 配置覆盖。
|
||||
|
||||
默认 -1,即不限制。
|
||||
|
||||
- `disable_join_reorder`
|
||||
|
||||
用于关闭所有系统自动的 join reorder 算法。取值有两种:true 和 false。默认行况下关闭,也就是采用系统自动的 join reorder 算法。设置为 true 后,系统会关闭所有自动排序的算法,采用 SQL 原始的表顺序,执行 join
|
||||
|
||||
- `return_object_data_as_binary` 用于标识是否在select 结果中返回bitmap/hll 结果。在 select into outfile 语句中,如果导出文件格式为csv 则会将 bimap/hll 数据进行base64编码,如果是parquet 文件格式 将会把数据作为byte array 存储
|
||||
|
||||
- `block_encryption_mode` 可以通过block_encryption_mode参数,控制块加密模式,默认值为:空。当使用AES算法加密时相当于`AES_128_ECB`, 当时用SM3算法加密时相当于`SM3_128_ECB` 可选值:
|
||||
|
||||
```text
|
||||
AES_128_ECB,
|
||||
AES_192_ECB,
|
||||
AES_256_ECB,
|
||||
AES_128_CBC,
|
||||
AES_192_CBC,
|
||||
AES_256_CBC,
|
||||
AES_128_CFB,
|
||||
AES_192_CFB,
|
||||
AES_256_CFB,
|
||||
AES_128_CFB1,
|
||||
AES_192_CFB1,
|
||||
AES_256_CFB1,
|
||||
AES_128_CFB8,
|
||||
AES_192_CFB8,
|
||||
AES_256_CFB8,
|
||||
AES_128_CFB128,
|
||||
AES_192_CFB128,
|
||||
AES_256_CFB128,
|
||||
AES_128_CTR,
|
||||
AES_192_CTR,
|
||||
AES_256_CTR,
|
||||
AES_128_OFB,
|
||||
AES_192_OFB,
|
||||
AES_256_OFB,
|
||||
SM4_128_ECB,
|
||||
SM4_128_CBC,
|
||||
SM4_128_CFB128,
|
||||
SM4_128_OFB,
|
||||
SM4_128_CTR,
|
||||
```
|
||||
|
||||
- `enable_infer_predicate`
|
||||
|
||||
用于控制是否进行谓词推导。取值有两种:true 和 false。默认情况下关闭,系统不在进行谓词推导,采用原始的谓词进行相关操作。设置为 true 后,进行谓词扩展。
|
||||
@ -1,11 +1,11 @@
|
||||
---
|
||||
{
|
||||
"title": "HLL近似精准去重",
|
||||
"title": "SHOW-FILE",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
@ -24,4 +24,15 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# BITMAP精准去重
|
||||
## SHOW-FILE
|
||||
|
||||
### Description
|
||||
|
||||
### Example
|
||||
|
||||
### Keywords
|
||||
|
||||
SHOW, USER
|
||||
|
||||
### Best Practice
|
||||
|
||||
Reference in New Issue
Block a user