Add best practice docs in advanced module (#9049)
Add best practice docs in advanced module
This commit is contained in:
@ -257,6 +257,16 @@ module.exports = [
|
||||
],
|
||||
sidebarDepth: 1,
|
||||
},
|
||||
{
|
||||
title: "Best Practice",
|
||||
directoryPath: "best-practice/",
|
||||
initialOpenGroupIndex: -1,
|
||||
children: [
|
||||
"query-analysis",
|
||||
"import-analysis",
|
||||
"debug-log"
|
||||
]
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
|
||||
@ -257,6 +257,16 @@ module.exports = [
|
||||
],
|
||||
sidebarDepth: 1,
|
||||
},
|
||||
{
|
||||
title: "最佳实践",
|
||||
directoryPath: "best-practice/",
|
||||
initialOpenGroupIndex: -1,
|
||||
children: [
|
||||
"query-analysis",
|
||||
"import-analysis",
|
||||
"debug-log"
|
||||
],
|
||||
}
|
||||
],
|
||||
},
|
||||
{
|
||||
|
||||
121
new-docs/en/advanced/best-practice/debug-log.md
Normal file
121
new-docs/en/advanced/best-practice/debug-log.md
Normal file
@ -0,0 +1,121 @@
|
||||
---
|
||||
{
|
||||
"title": "Debug Log",
|
||||
"language": "en"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
|
||||
# Debug Log
|
||||
|
||||
The system operation logs of Doris's FE and BE nodes are at INFO level by default. It can usually satisfy the analysis of system behavior and the localization of basic problems. However, in some cases, it may be necessary to enable DEBUG level logs to further troubleshoot the problem. This document mainly introduces how to enable the DEBUG log level of FE and BE nodes.
|
||||
|
||||
> It is not recommended to adjust the log level to WARN or higher, which is not conducive to the analysis of system behavior and the location of problems.
|
||||
|
||||
>Enable DEBUG log may cause a large number of logs to be generated, **Please be careful to open it in production environment**.
|
||||
|
||||
## Enable FE Debug log
|
||||
|
||||
The Debug level log of FE can be turned on by modifying the configuration file, or it can be turned on at runtime through the interface or API.
|
||||
|
||||
1. Open via configuration file
|
||||
|
||||
Add the configuration item `sys_log_verbose_modules` to fe.conf. An example is as follows:
|
||||
|
||||
````text
|
||||
# Only enable Debug log for class org.apache.doris.catalog.Catalog
|
||||
sys_log_verbose_modules=org.apache.doris.catalog.Catalog
|
||||
|
||||
# Open the Debug log of all classes under the package org.apache.doris.catalog
|
||||
sys_log_verbose_modules=org.apache.doris.catalog
|
||||
|
||||
# Enable Debug logs for all classes under package org
|
||||
sys_log_verbose_modules=org
|
||||
````
|
||||
|
||||
Add configuration items and restart the FE node to take effect.
|
||||
|
||||
2. Via FE UI interface
|
||||
|
||||
The log level can be modified at runtime through the UI interface. There is no need to restart the FE node. Open the http port of the FE node (8030 by default) in the browser, and log in to the UI interface. Then click on the `Log` tab in the upper navigation bar.
|
||||
|
||||
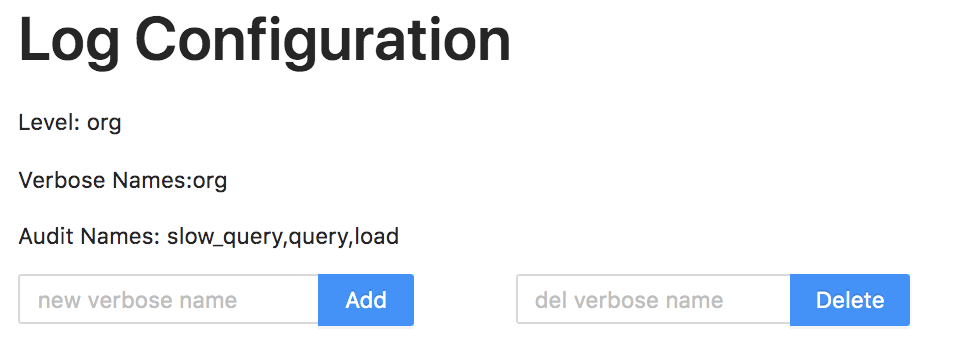
|
||||
|
||||
We can enter the package name or specific class name in the Add input box to open the corresponding Debug log. For example, enter `org.apache.doris.catalog.Catalog` to open the Debug log of the Catalog class:
|
||||
|
||||
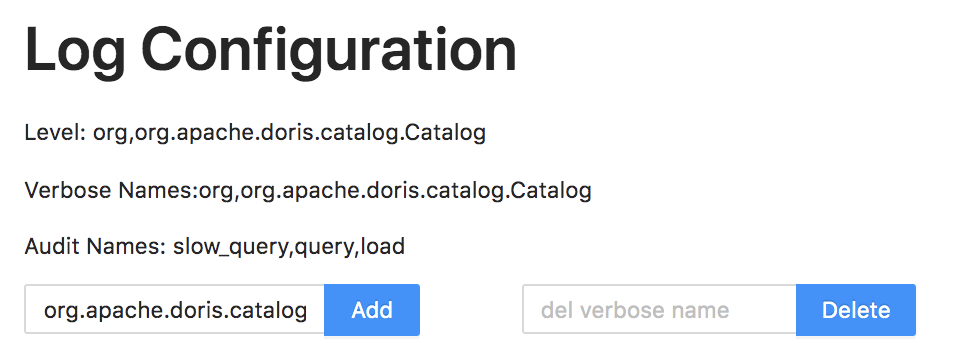
|
||||
|
||||
You can also enter the package name or specific class name in the Delete input box to close the corresponding Debug log.
|
||||
|
||||
> The modification here will only affect the log level of the corresponding FE node. Does not affect the log level of other FE nodes.
|
||||
|
||||
3. Modification via API
|
||||
|
||||
The log level can also be modified at runtime via the following API. There is no need to restart the FE node.
|
||||
|
||||
```bash
|
||||
curl -X POST -uuser:passwd fe_host:http_port/rest/v1/log?add_verbose=org.apache.doris.catalog.Catalog
|
||||
````
|
||||
|
||||
The username and password are the root or admin users who log in to Doris. The `add_verbose` parameter specifies the package or class name to enable Debug logging. Returns if successful:
|
||||
|
||||
````json
|
||||
{
|
||||
"msg": "success",
|
||||
"code": 0,
|
||||
"data": {
|
||||
"LogConfiguration": {
|
||||
"VerboseNames": "org,org.apache.doris.catalog.Catalog",
|
||||
"AuditNames": "slow_query,query,load",
|
||||
"Level": "INFO"
|
||||
}
|
||||
},
|
||||
"count": 0
|
||||
}
|
||||
````
|
||||
|
||||
Debug logging can also be turned off via the following API:
|
||||
|
||||
```bash
|
||||
curl -X POST -uuser:passwd fe_host:http_port/rest/v1/log?del_verbose=org.apache.doris.catalog.Catalog
|
||||
````
|
||||
|
||||
The `del_verbose` parameter specifies the package or class name for which to turn off Debug logging.
|
||||
|
||||
## Enable BE Debug log
|
||||
|
||||
BE's Debug log currently only supports modifying and restarting the BE node through the configuration file to take effect.
|
||||
|
||||
````text
|
||||
sys_log_verbose_modules=plan_fragment_executor,olap_scan_node
|
||||
sys_log_verbose_level=3
|
||||
````
|
||||
|
||||
`sys_log_verbose_modules` specifies the file name to be opened, which can be specified by the wildcard *. for example:
|
||||
|
||||
````text
|
||||
sys_log_verbose_modules=*
|
||||
````
|
||||
|
||||
Indicates that all DEBUG logs are enabled.
|
||||
|
||||
`sys_log_verbose_level` indicates the level of DEBUG. The higher the number, the more detailed the DEBUG log. The value range is 1-10.
|
||||
171
new-docs/en/advanced/best-practice/import-analysis.md
Normal file
171
new-docs/en/advanced/best-practice/import-analysis.md
Normal file
@ -0,0 +1,171 @@
|
||||
---
|
||||
{
|
||||
"title": "Import Analysis",
|
||||
"language": "en"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
|
||||
# Import Analysis
|
||||
|
||||
Doris provides a graphical command to help users analyze a specific import more easily. This article describes how to use this feature.
|
||||
|
||||
> This function is currently only for Broker Load analysis.
|
||||
|
||||
## Import plan tree
|
||||
|
||||
If you don't know much about Doris' query plan tree, please read the previous article [DORIS/best practices/query analysis](./query-analysis.html).
|
||||
|
||||
The execution process of a [Broker Load](../../data-operate/import/import-way/broker-load-manual.html) request is also based on Doris' query framework. A Broker Load job will be split into multiple subtasks based on the number of DATA INFILE clauses in the import request. Each subtask can be regarded as an independent import execution plan. An import plan consists of only one Fragment, which is composed as follows:
|
||||
|
||||
```sql
|
||||
┌────────────────┐
|
||||
│OlapTableSink│
|
||||
└────────────────┘
|
||||
│
|
||||
┌────────────────┐
|
||||
│BrokerScanNode│
|
||||
└────────────────┘
|
||||
````
|
||||
|
||||
BrokerScanNode is mainly responsible for reading the source data and sending it to OlapTableSink, and OlapTableSink is responsible for sending data to the corresponding node according to the partition and bucketing rules, and the corresponding node is responsible for the actual data writing.
|
||||
|
||||
The Fragment of the import execution plan will be divided into one or more Instances according to the number of imported source files, the number of BE nodes and other parameters. Each Instance is responsible for part of the data import.
|
||||
|
||||
The execution plans of multiple subtasks are executed concurrently, and multiple instances of an execution plan are also executed in parallel.
|
||||
|
||||
## View import Profile
|
||||
|
||||
The user can open the session variable `is_report_success` with the following command:
|
||||
|
||||
```sql
|
||||
SET is_report_success=true;
|
||||
````
|
||||
|
||||
Then submit a Broker Load import request and wait until the import execution completes. Doris will generate a Profile for this import. Profile contains the execution details of importing each subtask and Instance, which helps us analyze import bottlenecks.
|
||||
|
||||
> Viewing profiles of unsuccessful import jobs is currently not supported.
|
||||
|
||||
We can get the Profile list first with the following command:
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/";
|
||||
+---------+------+-----------+------+------------+- --------------------+---------------------------------+------- ----+------------+
|
||||
| QueryId | User | DefaultDb | SQL | QueryType | StartTime | EndTime | TotalTime | QueryState |
|
||||
+---------+------+-----------+------+------------+- --------------------+---------------------------------+------- ----+------------+
|
||||
| 10441 | N/A | N/A | N/A | Load | 2021-04-10 22:15:37 | 2021-04-10 22:18:54 | 3m17s | N/A |
|
||||
+---------+------+-----------+------+------------+- --------------------+---------------------------------+------- ----+------------+
|
||||
````
|
||||
|
||||
This command will list all currently saved import profiles. Each line corresponds to one import. where the QueryId column is the ID of the import job. This ID can also be viewed through the SHOW LOAD statement. We can select the QueryId corresponding to the Profile we want to see to see the specific situation.
|
||||
|
||||
**Viewing a Profile is divided into 3 steps:**
|
||||
|
||||
1. View the subtask overview
|
||||
|
||||
View an overview of subtasks with imported jobs by running the following command:
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/10441";
|
||||
+-----------------------------------+------------+
|
||||
| TaskId | ActiveTime |
|
||||
+-----------------------------------+------------+
|
||||
| 980014623046410a-88e260f0c43031f1 | 3m14s |
|
||||
+-----------------------------------+------------+
|
||||
````
|
||||
|
||||
As shown in the figure above, it means that the import job 10441 has a total of one subtask, in which ActiveTime indicates the execution time of the longest instance in this subtask.
|
||||
|
||||
2. View the Instance overview of the specified subtask
|
||||
|
||||
When we find that a subtask takes a long time, we can further check the execution time of each instance of the subtask:
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/10441/980014623046410a-88e260f0c43031f1";
|
||||
+-----------------------------------+------------- -----+------------+
|
||||
| Instances | Host | ActiveTime |
|
||||
+-----------------------------------+------------- -----+------------+
|
||||
| 980014623046410a-88e260f0c43031f2 | 10.81.85.89:9067 | 3m7s |
|
||||
| 980014623046410a-88e260f0c43031f3 | 10.81.85.89:9067 | 3m6s |
|
||||
| 980014623046410a-88e260f0c43031f4 | 10.81.85.89:9067 | 3m10s |
|
||||
| 980014623046410a-88e260f0c43031f5 | 10.81.85.89:9067 | 3m14s |
|
||||
+-----------------------------------+------------- -----+------------+
|
||||
````
|
||||
|
||||
This shows the time-consuming of four instances of the subtask 980014623046410a-88e260f0c43031f1, and also shows the execution node where the instance is located.
|
||||
|
||||
3. View the specific Instance
|
||||
|
||||
We can continue to view the detailed profile of each operator on a specific Instance:
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/10441/980014623046410a-88e260f0c43031f1/980014623046410a-88e260f0c43031f5"\G
|
||||
**************************** 1. row ******************** ******
|
||||
Instance:
|
||||
┌-----------------------------------------┐
|
||||
│[-1: OlapTableSink] │
|
||||
│(Active: 2m17s, non-child: 70.91) │
|
||||
│ - Counters: │
|
||||
│ - CloseWaitTime: 1m53s │
|
||||
│ - ConvertBatchTime: 0ns │
|
||||
│ - MaxAddBatchExecTime: 1m46s │
|
||||
│ - NonBlockingSendTime: 3m11s │
|
||||
│ - NumberBatchAdded: 782 │
|
||||
│ - NumberNodeChannels: 1 │
|
||||
│ - OpenTime: 743.822us │
|
||||
│ - RowsFiltered: 0 │
|
||||
│ - RowsRead: 1.599729M (1599729) │
|
||||
│ - RowsReturned: 1.599729M (1599729)│
|
||||
│ - SendDataTime: 11s761ms │
|
||||
│ - TotalAddBatchExecTime: 1m46s │
|
||||
│ - ValidateDataTime: 9s802ms │
|
||||
└-----------------------------------------┘
|
||||
│
|
||||
┌------------------------------------------------- ----┐
|
||||
│[0: BROKER_SCAN_NODE] │
|
||||
│(Active: 56s537ms, non-child: 29.06) │
|
||||
│ - Counters: │
|
||||
│ - BytesDecompressed: 0.00 │
|
||||
│ - BytesRead: 5.77 GB │
|
||||
│ - DecompressTime: 0ns │
|
||||
│ - FileReadTime: 34s263ms │
|
||||
│ - MaterializeTupleTime(*): 45s54ms │
|
||||
│ - NumDiskAccess: 0 │
|
||||
│ - PeakMemoryUsage: 33.03 MB │
|
||||
│ - RowsRead: 1.599729M (1599729) │
|
||||
│ - RowsReturned: 1.599729M (1599729) │
|
||||
│ - RowsReturnedRate: 28.295K /sec │
|
||||
│ - TotalRawReadTime(*): 1m20s │
|
||||
│ - TotalReadThroughput: 30.39858627319336 MB/sec│
|
||||
│ - WaitScannerTime: 56s528ms │
|
||||
└------------------------------------------------- ----┘
|
||||
````
|
||||
|
||||
The figure above shows the specific profiles of each operator of Instance 980014623046410a-88e260f0c43031f5 in subtask 980014623046410a-88e260f0c43031f1.
|
||||
|
||||
Through the above three steps, we can gradually check the execution bottleneck of an import task.
|
||||
499
new-docs/en/advanced/best-practice/query-analysis.md
Normal file
499
new-docs/en/advanced/best-practice/query-analysis.md
Normal file
@ -0,0 +1,499 @@
|
||||
---
|
||||
{
|
||||
"title": "Query Analysis",
|
||||
"language": "en"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
|
||||
# Query Analysis
|
||||
|
||||
Doris provides a graphical command to help users analyze a specific query or import more easily. This article describes how to use this feature.
|
||||
|
||||
## query plan tree
|
||||
|
||||
SQL is a descriptive language, and users describe the data they want to get through a SQL. The specific execution mode of a SQL depends on the implementation of the database. The query planner is used to determine how the database executes a SQL.
|
||||
|
||||
For example, if the user specifies a Join operator, the query planner needs to decide the specific Join algorithm, such as Hash Join or Merge Sort Join; whether to use Shuffle or Broadcast; whether the Join order needs to be adjusted to avoid Cartesian product; on which nodes to execute and so on.
|
||||
|
||||
Doris' query planning process is to first convert an SQL statement into a single-machine execution plan tree.
|
||||
|
||||
````text
|
||||
┌────┐
|
||||
│Sort│
|
||||
└────┘
|
||||
│
|
||||
┌──────────────┐
|
||||
│Aggregation│
|
||||
└──────────────┘
|
||||
│
|
||||
┌────┐
|
||||
│Join│
|
||||
└────┘
|
||||
┌────┴────┐
|
||||
┌──────┐ ┌──────┐
|
||||
│Scan-1│ │Scan-2│
|
||||
└──────┘ └──────┘
|
||||
````
|
||||
|
||||
After that, the query planner will convert the single-machine query plan into a distributed query plan according to the specific operator execution mode and the specific distribution of data. The distributed query plan is composed of multiple fragments, each fragment is responsible for a part of the query plan, and the data is transmitted between the fragments through the ExchangeNode operator.
|
||||
|
||||
````text
|
||||
┌────┐
|
||||
│Sort│
|
||||
│F1 │
|
||||
└────┘
|
||||
│
|
||||
┌──────────────┐
|
||||
│Aggregation│
|
||||
│F1 │
|
||||
└──────────────┘
|
||||
│
|
||||
┌────┐
|
||||
│Join│
|
||||
│F1 │
|
||||
└────┘
|
||||
┌──────┴────┐
|
||||
┌──────┐ ┌────────────┐
|
||||
│Scan-1│ │ExchangeNode│
|
||||
│F1 │ │F1 │
|
||||
└──────┘ └────────────┘
|
||||
│
|
||||
┌────────────────┐
|
||||
│DataStreamDink│
|
||||
│F2 │
|
||||
└────────────────┘
|
||||
│
|
||||
┌──────┐
|
||||
│Scan-2│
|
||||
│F2 │
|
||||
└──────┘
|
||||
````
|
||||
|
||||
As shown above, we divided the stand-alone plan into two Fragments: F1 and F2. Data is transmitted between two Fragments through an ExchangeNode.
|
||||
|
||||
And a Fragment will be further divided into multiple Instances. Instance is the final concrete execution instance. Dividing into multiple Instances helps to make full use of machine resources and improve the execution concurrency of a Fragment.
|
||||
|
||||
## View query plan
|
||||
|
||||
You can view the execution plan of a SQL through the following two commands.
|
||||
|
||||
- `EXPLAIN GRAPH select ...;`
|
||||
- `EXPLAIN select ...;`
|
||||
|
||||
The first command displays a query plan graphically. This command can more intuitively display the tree structure of the query plan and the division of Fragments:
|
||||
|
||||
```sql
|
||||
mysql> desc graph select tbl1.k1, sum(tbl1.k2) from tbl1 join tbl2 on tbl1.k1 = tbl2.k1 group by tbl1.k1 order by tbl1.k1;
|
||||
+---------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------+
|
||||
| |
|
||||
| ┌───────────────┐ |
|
||||
| │[9: ResultSink]│ |
|
||||
| │[Fragment: 4] │ |
|
||||
| │RESULT SINK │ |
|
||||
| └───────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────────────┐ |
|
||||
| │[9: MERGING-EXCHANGE]│ |
|
||||
| │[Fragment: 4] │ |
|
||||
| └─────────────────────┘ |
|
||||
| │ |
|
||||
| ┌───────────────────┐ |
|
||||
| │[9: DataStreamSink]│ |
|
||||
| │[Fragment: 3] │ |
|
||||
| │STREAM DATA SINK │ |
|
||||
| │ EXCHANGE ID: 09 │ |
|
||||
| │ UNPARTITIONED │ |
|
||||
| └───────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────┐ |
|
||||
| │[4: TOP-N] │ |
|
||||
| │[Fragment: 3]│ |
|
||||
| └─────────────┘ |
|
||||
| │ |
|
||||
| ┌───────────────────────────────┐ |
|
||||
| │[8: AGGREGATE (merge finalize)]│ |
|
||||
| │[Fragment: 3] │ |
|
||||
| └───────────────────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────┐ |
|
||||
| │[7: EXCHANGE]│ |
|
||||
| │[Fragment: 3]│ |
|
||||
| └─────────────┘ |
|
||||
| │ |
|
||||
| ┌───────────────────┐ |
|
||||
| │[7: DataStreamSink]│ |
|
||||
| │[Fragment: 2] │ |
|
||||
| │STREAM DATA SINK │ |
|
||||
| │ EXCHANGE ID: 07 │ |
|
||||
| │ HASH_PARTITIONED │ |
|
||||
| └───────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────────────────────────┐ |
|
||||
| │[3: AGGREGATE (update serialize)]│ |
|
||||
| │[Fragment: 2] │ |
|
||||
| │STREAMING │ |
|
||||
| └─────────────────────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────────────────────────┐ |
|
||||
| │[2: HASH JOIN] │ |
|
||||
| │[Fragment: 2] │ |
|
||||
| │join op: INNER JOIN (PARTITIONED)│ |
|
||||
| └─────────────────────────────────┘ |
|
||||
| ┌──────────┴──────────┐ |
|
||||
| ┌─────────────┐ ┌─────────────┐ |
|
||||
| │[5: EXCHANGE]│ │[6: EXCHANGE]│ |
|
||||
| │[Fragment: 2]│ │[Fragment: 2]│ |
|
||||
| └─────────────┘ └─────────────┘ |
|
||||
| │ │ |
|
||||
| ┌───────────────────┐ ┌───────────────────┐ |
|
||||
| │[5: DataStreamSink]│ │[6: DataStreamSink]│ |
|
||||
| │[Fragment: 0] │ │[Fragment: 1] │ |
|
||||
| │STREAM DATA SINK │ │STREAM DATA SINK │ |
|
||||
| │ EXCHANGE ID: 05 │ │ EXCHANGE ID: 06 │ |
|
||||
| │ HASH_PARTITIONED │ │ HASH_PARTITIONED │ |
|
||||
| └───────────────────┘ └───────────────────┘ |
|
||||
| │ │ |
|
||||
| ┌─────────────────┐ ┌─────────────────┐ |
|
||||
| │[0: OlapScanNode]│ │[1: OlapScanNode]│ |
|
||||
| │[Fragment: 0] │ │[Fragment: 1] │ |
|
||||
| │TABLE: tbl1 │ │TABLE: tbl2 │ |
|
||||
| └─────────────────┘ └─────────────────┘ |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
As can be seen from the figure, the query plan tree is divided into 5 fragments: 0, 1, 2, 3, and 4. For example, `[Fragment: 0]` on the `OlapScanNode` node indicates that this node belongs to Fragment 0. Data is transferred between each Fragment through DataStreamSink and ExchangeNode.
|
||||
|
||||
The graphics command only displays the simplified node information. If you need to view more specific node information, such as the filter conditions pushed to the node as follows, you need to view the more detailed text version information through the second command:
|
||||
|
||||
```sql
|
||||
mysql> explain select tbl1.k1, sum(tbl1.k2) from tbl1 join tbl2 on tbl1.k1 = tbl2.k1 group by tbl1.k1 order by tbl1.k1;
|
||||
+----------------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+----------------------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:<slot 5> <slot 3> `tbl1`.`k1` | <slot 6> <slot 4> sum(`tbl1`.`k2`) |
|
||||
| PARTITION: UNPARTITIONED |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 9:MERGING-EXCHANGE |
|
||||
| limit: 65535 |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: <slot 3> `tbl1`.`k1` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 09 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 4:TOP-N |
|
||||
| | order by: <slot 5> <slot 3> `tbl1`.`k1` ASC |
|
||||
| | offset: 0 |
|
||||
| | limit: 65535 |
|
||||
| | |
|
||||
| 8:AGGREGATE (merge finalize) |
|
||||
| | output: sum(<slot 4> sum(`tbl1`.`k2`)) |
|
||||
| | group by: <slot 3> `tbl1`.`k1` |
|
||||
| | cardinality=-1 |
|
||||
| | |
|
||||
| 7:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: `tbl1`.`k1` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 07 |
|
||||
| HASH_PARTITIONED: <slot 3> `tbl1`.`k1` |
|
||||
| |
|
||||
| 3:AGGREGATE (update serialize) |
|
||||
| | STREAMING |
|
||||
| | output: sum(`tbl1`.`k2`) |
|
||||
| | group by: `tbl1`.`k1` |
|
||||
| | cardinality=-1 |
|
||||
| | |
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN (PARTITIONED) |
|
||||
| | runtime filter: false |
|
||||
| | hash predicates: |
|
||||
| | colocate: false, reason: table not in the same group |
|
||||
| | equal join conjunct: `tbl1`.`k1` = `tbl2`.`k1` |
|
||||
| | cardinality=2 |
|
||||
| | |
|
||||
| |----6:EXCHANGE |
|
||||
| | |
|
||||
| 5:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 3 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 06 |
|
||||
| HASH_PARTITIONED: `tbl2`.`k1` |
|
||||
| |
|
||||
| 1:OlapScanNode |
|
||||
| TABLE: tbl2 |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: tbl2 |
|
||||
| tabletRatio=3/3 |
|
||||
| tabletList=105104776,105104780,105104784 |
|
||||
| cardinality=1 |
|
||||
| avgRowSize=4.0 |
|
||||
| numNodes=6 |
|
||||
| |
|
||||
| PLAN FRAGMENT 4 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 05 |
|
||||
| HASH_PARTITIONED: `tbl1`.`k1` |
|
||||
| |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: tbl1 |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: tbl1 |
|
||||
| tabletRatio=3/3 |
|
||||
| tabletList=105104752,105104763,105104767 |
|
||||
| cardinality=2 |
|
||||
| avgRowSize=8.0 |
|
||||
| numNodes=6 |
|
||||
+----------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
> The information displayed in the query plan is still being standardized and improved, and we will introduce it in detail in subsequent articles.
|
||||
|
||||
## View query Profile
|
||||
|
||||
The user can open the session variable `is_report_success` with the following command:
|
||||
|
||||
```sql
|
||||
SET is_report_success=true;
|
||||
````
|
||||
|
||||
Then execute the query, and Doris will generate a Profile of the query. Profile contains the specific execution of a query for each node, which helps us analyze query bottlenecks.
|
||||
|
||||
After executing the query, we can first get the Profile list with the following command:
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/"\G
|
||||
**************************** 1. row ******************** ******
|
||||
QueryId: c257c52f93e149ee-ace8ac14e8c9fef9
|
||||
User: root
|
||||
DefaultDb: default_cluster:db1
|
||||
SQL: select tbl1.k1, sum(tbl1.k2) from tbl1 join tbl2 on tbl1.k1 = tbl2.k1 group by tbl1.k1 order by tbl1.k1
|
||||
QueryType: Query
|
||||
StartTime: 2021-04-08 11:30:50
|
||||
EndTime: 2021-04-08 11:30:50
|
||||
TotalTime: 9ms
|
||||
QueryState: EOF
|
||||
````
|
||||
|
||||
This command will list all currently saved profiles. Each row corresponds to a query. We can select the QueryId corresponding to the Profile we want to see to see the specific situation.
|
||||
|
||||
Viewing a Profile is divided into 3 steps:
|
||||
|
||||
1. View the overall execution plan tree
|
||||
|
||||
This step is mainly used to analyze the execution plan as a whole and view the execution time of each Fragment.
|
||||
```sql
|
||||
mysql> show query profile "/c257c52f93e149ee-ace8ac14e8c9fef9"\G
|
||||
*************************** 1. row ***************************
|
||||
Fragments:
|
||||
┌──────────────────────┐
|
||||
│[-1: DataBufferSender]│
|
||||
│Fragment: 0 │
|
||||
│MaxActiveTime: 6.626ms│
|
||||
└──────────────────────┘
|
||||
│
|
||||
┌──────────────────┐
|
||||
│[9: EXCHANGE_NODE]│
|
||||
│Fragment: 0 │
|
||||
└──────────────────┘
|
||||
│
|
||||
┌──────────────────────┐
|
||||
│[9: DataStreamSender] │
|
||||
│Fragment: 1 │
|
||||
│MaxActiveTime: 5.449ms│
|
||||
└──────────────────────┘
|
||||
│
|
||||
┌──────────────┐
|
||||
│[4: SORT_NODE]│
|
||||
│Fragment: 1 │
|
||||
└──────────────┘
|
||||
┌┘
|
||||
┌─────────────────────┐
|
||||
│[8: AGGREGATION_NODE]│
|
||||
│Fragment: 1 │
|
||||
└─────────────────────┘
|
||||
└┐
|
||||
┌──────────────────┐
|
||||
│[7: EXCHANGE_NODE]│
|
||||
│Fragment: 1 │
|
||||
└──────────────────┘
|
||||
│
|
||||
┌──────────────────────┐
|
||||
│[7: DataStreamSender] │
|
||||
│Fragment: 2 │
|
||||
│MaxActiveTime: 3.505ms│
|
||||
└──────────────────────┘
|
||||
┌┘
|
||||
┌─────────────────────┐
|
||||
│[3: AGGREGATION_NODE]│
|
||||
│Fragment: 2 │
|
||||
└─────────────────────┘
|
||||
│
|
||||
┌───────────────────┐
|
||||
│[2: HASH_JOIN_NODE]│
|
||||
│Fragment: 2 │
|
||||
└───────────────────┘
|
||||
┌────────────┴────────────┐
|
||||
┌──────────────────┐ ┌──────────────────┐
|
||||
│[5: EXCHANGE_NODE]│ │[6: EXCHANGE_NODE]│
|
||||
│Fragment: 2 │ │Fragment: 2 │
|
||||
└──────────────────┘ └──────────────────┘
|
||||
│ │
|
||||
┌─────────────────────┐ ┌────────────────────────┐
|
||||
│[5: DataStreamSender]│ │[6: DataStreamSender] │
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
│MaxActiveTime: 1.87ms│ │MaxActiveTime: 636.767us│
|
||||
└─────────────────────┘ └────────────────────────┘
|
||||
│ ┌┘
|
||||
┌───────────────────┐ ┌───────────────────┐
|
||||
│[0: OLAP_SCAN_NODE]│ │[1: OLAP_SCAN_NODE]│
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
└───────────────────┘ └───────────────────┘
|
||||
│ │
|
||||
┌─────────────┐ ┌─────────────┐
|
||||
│[OlapScanner]│ │[OlapScanner]│
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
└─────────────┘ └─────────────┘
|
||||
│ │
|
||||
┌─────────────────┐ ┌─────────────────┐
|
||||
│[SegmentIterator]│ │[SegmentIterator]│
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
└─────────────────┘ └─────────────────┘
|
||||
|
||||
1 row in set (0.02 sec)
|
||||
```
|
||||
As shown in the figure above, each node is marked with the Fragment to which it belongs, and at the Sender node of each Fragment, the execution time of the Fragment is marked. This time-consuming is the longest of all Instance execution times under Fragment. This helps us find the most time-consuming Fragment from an overall perspective.
|
||||
|
||||
2. View the Instance list under the specific Fragment
|
||||
|
||||
For example, if we find that Fragment 1 takes the longest time, we can continue to view the Instance list of Fragment 1:
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/c257c52f93e149ee-ace8ac14e8c9fef9/1";
|
||||
+-----------------------------------+-------------------+------------+
|
||||
| Instances | Host | ActiveTime |
|
||||
+-----------------------------------+-------------------+------------+
|
||||
| c257c52f93e149ee-ace8ac14e8c9ff03 | 10.200.00.01:9060 | 5.449ms |
|
||||
| c257c52f93e149ee-ace8ac14e8c9ff05 | 10.200.00.02:9060 | 5.367ms |
|
||||
| c257c52f93e149ee-ace8ac14e8c9ff04 | 10.200.00.03:9060 | 5.358ms |
|
||||
+-----------------------------------+-------------------+------------+
|
||||
```
|
||||
This shows the execution nodes and time consumption of all three Instances on Fragment 1.
|
||||
|
||||
1. View the specific Instance
|
||||
|
||||
We can continue to view the detailed profile of each operator on a specific Instance:
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/c257c52f93e149ee-ace8ac14e8c9fef9/1/c257c52f93e149ee-ace8ac14e8c9ff03"\G
|
||||
**************************** 1. row ******************** ******
|
||||
Instance:
|
||||
┌────────────────────────────────────────────┐
|
||||
│[9: DataStreamSender] │
|
||||
│(Active: 37.222us, non-child: 0.40) │
|
||||
│ - Counters: │
|
||||
│ - BytesSent: 0.00 │
|
||||
│ - IgnoreRows: 0 │
|
||||
│ - OverallThroughput: 0.0 /sec │
|
||||
│ - PeakMemoryUsage: 8.00 KB │
|
||||
│ - SerializeBatchTime: 0ns │
|
||||
│ - UncompressedRowBatchSize: 0.00 │
|
||||
└──────────────────────────────────────────┘
|
||||
└┐
|
||||
│
|
||||
┌──────────────────────────────────────┐
|
||||
│[4: SORT_NODE] │
|
||||
│(Active: 5.421ms, non-child: 0.71)│
|
||||
│ - Counters: │
|
||||
│ - PeakMemoryUsage: 12.00 KB │
|
||||
│ - RowsReturned: 0 │
|
||||
│ - RowsReturnedRate: 0 │
|
||||
└──────────────────────────────────────┘
|
||||
┌┘
|
||||
│
|
||||
┌──────────────────────────────────────┐
|
||||
│[8: AGGREGATION_NODE] │
|
||||
│(Active: 5.355ms, non-child: 10.68)│
|
||||
│ - Counters: │
|
||||
│ - BuildTime: 3.701us │
|
||||
│ - GetResultsTime: 0ns │
|
||||
│ - HTResize: 0 │
|
||||
│ - HTResizeTime: 1.211us │
|
||||
│ - HashBuckets: 0 │
|
||||
│ - HashCollisions: 0 │
|
||||
│ - HashFailedProbe: 0 │
|
||||
│ - HashFilledBuckets: 0 │
|
||||
│ - HashProbe: 0 │
|
||||
│ - HashTravelLength: 0 │
|
||||
│ - LargestPartitionPercent: 0 │
|
||||
│ - MaxPartitionLevel: 0 │
|
||||
│ - NumRepartitions: 0 │
|
||||
│ - PartitionsCreated: 16 │
|
||||
│ - PeakMemoryUsage: 34.02 MB │
|
||||
│ - RowsProcessed: 0 │
|
||||
│ - RowsRepartitioned: 0 │
|
||||
│ - RowsReturned: 0 │
|
||||
│ - RowsReturnedRate: 0 │
|
||||
│ - SpilledPartitions: 0 │
|
||||
└──────────────────────────────────────┘
|
||||
└┐
|
||||
│
|
||||
┌────────────────────────────────────────────────────┐
|
||||
│[7: EXCHANGE_NODE] │
|
||||
│(Active: 4.360ms, non-child: 46.84) │
|
||||
│ - Counters: │
|
||||
│ - BytesReceived: 0.00 │
|
||||
│ - ConvertRowBatchTime: 387ns │
|
||||
│ - DataArrivalWaitTime: 4.357ms │
|
||||
│ - DeserializeRowBatchTimer: 0ns │
|
||||
│ - FirstBatchArrivalWaitTime: 4.356ms│
|
||||
│ - PeakMemoryUsage: 0.00 │
|
||||
│ - RowsReturned: 0 │
|
||||
│ - RowsReturnedRate: 0 │
|
||||
│ - SendersBlockedTotalTimer(*): 0ns │
|
||||
└────────────────────────────────────────────────────┘
|
||||
````
|
||||
|
||||
The above figure shows the specific profiles of each operator of Instance c257c52f93e149ee-ace8ac14e8c9ff03 in Fragment 1.
|
||||
|
||||
Through the above three steps, we can gradually check the performance bottleneck of a SQL.
|
||||
@ -25,7 +25,7 @@ under the License.
|
||||
-->
|
||||
|
||||
# Batch Delete
|
||||
Currently, Doris supports multiple import methods such as broker load, routine load, stream load, etc. The data can only be deleted through the delete statement at present. When the delete statement is used to delete, a new data version will be generated every time delete is executed. Frequent deletion will seriously affect the query performance, and when using the delete method to delete, it is achieved by generating an empty rowset to record the deletion conditions. Each time you read, you must filter the deletion jump conditions. Also when there are many conditions, Performance affects. Compared with other systems, the implementation of greenplum is more like a traditional database product. Snowflake is implemented through the merge syntax.
|
||||
Currently, Doris supports multiple import methods such as [broker load](../import/import-way/broker-load-manual.html), [routine load](../import/import-way/routine-load-manual.html), [stream load](../import/import-way/stream-load-manual.html), etc. The data can only be deleted through the delete statement at present. When the delete statement is used to delete, a new data version will be generated every time delete is executed. Frequent deletion will seriously affect the query performance, and when using the delete method to delete, it is achieved by generating an empty rowset to record the deletion conditions. Each time you read, you must filter the deletion jump conditions. Also when there are many conditions, Performance affects. Compared with other systems, the implementation of greenplum is more like a traditional database product. Snowflake is implemented through the merge syntax.
|
||||
|
||||
For scenarios similar to the import of cdc data, insert and delete in the data data generally appear interspersed. In this scenario, our current import method is not enough, even if we can separate insert and delete, it can solve the import problem , But still cannot solve the problem of deletion. Use the batch delete function to solve the needs of these scenarios.
|
||||
There are three ways to merge data import:
|
||||
|
||||
@ -1,7 +1,9 @@
|
||||
## {
|
||||
---
|
||||
{
|
||||
"title": "update",
|
||||
"language": "en"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
|
||||
120
new-docs/zh-CN/advanced/best-practice/debug-log.md
Normal file
120
new-docs/zh-CN/advanced/best-practice/debug-log.md
Normal file
@ -0,0 +1,120 @@
|
||||
---
|
||||
{
|
||||
"title": "如何开启Debug日志",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 如何开启Debug日志
|
||||
|
||||
Doris 的 FE 和 BE 节点的系统运行日志默认为 INFO 级别。通常可以满足对系统行为的分析和基本问题的定位。但是某些情况下,可能需要开启 DEBUG 级别的日志来进一步排查问题。本文档主要介绍如何开启 FE、BE节点的 DEBUG 日志级别。
|
||||
|
||||
>不建议将日志级别调整为 WARN 或更高级别,这不利于系统行为的分析和问题的定位。
|
||||
|
||||
>开启 DEBUG 日志可能会导致大量日志产生,**生产环境请谨慎开启**。
|
||||
|
||||
## 开启 FE Debug 日志
|
||||
|
||||
FE 的 Debug 级别日志可以通过修改配置文件开启,也可以通过界面或 API 在运行时打开。
|
||||
|
||||
1. 通过配置文件开启
|
||||
|
||||
在 fe.conf 中添加配置项 `sys_log_verbose_modules`。举例如下:
|
||||
|
||||
```text
|
||||
# 仅开启类 org.apache.doris.catalog.Catalog 的 Debug 日志
|
||||
sys_log_verbose_modules=org.apache.doris.catalog.Catalog
|
||||
|
||||
# 开启包 org.apache.doris.catalog 下所有类的 Debug 日志
|
||||
sys_log_verbose_modules=org.apache.doris.catalog
|
||||
|
||||
# 开启包 org 下所有类的 Debug 日志
|
||||
sys_log_verbose_modules=org
|
||||
```
|
||||
|
||||
添加配置项并重启 FE 节点,即可生效。
|
||||
|
||||
2. 通过 FE UI 界面
|
||||
|
||||
通过 UI 界面可以在运行时修改日志级别。无需重启 FE 节点。在浏览器打开 FE 节点的 http 端口(默认为 8030),并登陆 UI 界面。之后点击上方导航栏的 `Log` 标签。
|
||||
|
||||

|
||||
|
||||
我们在 Add 输入框中可以输入包名或者具体的类名,可以打开对应的 Debug 日志。如输入 `org.apache.doris.catalog.Catalog` 则可以打开 Catalog 类的 Debug 日志:
|
||||
|
||||

|
||||
|
||||
你也可以在 Delete 输入框中输入包名或者具体的类名,来关闭对应的 Debug 日志。
|
||||
|
||||
> 这里的修改只会影响对应的 FE 节点的日志级别。不会影响其他 FE 节点的日志级别。
|
||||
|
||||
3. 通过 API 修改
|
||||
|
||||
通过以下 API 也可以在运行时修改日志级别。无需重启 FE 节点。
|
||||
|
||||
```bash
|
||||
curl -X POST -uuser:passwd fe_host:http_port/rest/v1/log?add_verbose=org.apache.doris.catalog.Catalog
|
||||
```
|
||||
|
||||
其中用户名密码为登陆 Doris 的 root 或 admin 用户。`add_verbose` 参数指定要开启 Debug 日志的包名或类名。若成功则返回:
|
||||
|
||||
```json
|
||||
{
|
||||
"msg": "success",
|
||||
"code": 0,
|
||||
"data": {
|
||||
"LogConfiguration": {
|
||||
"VerboseNames": "org,org.apache.doris.catalog.Catalog",
|
||||
"AuditNames": "slow_query,query,load",
|
||||
"Level": "INFO"
|
||||
}
|
||||
},
|
||||
"count": 0
|
||||
}
|
||||
```
|
||||
|
||||
也可以通过以下 API 关闭 Debug 日志:
|
||||
|
||||
```bash
|
||||
curl -X POST -uuser:passwd fe_host:http_port/rest/v1/log?del_verbose=org.apache.doris.catalog.Catalog
|
||||
```
|
||||
|
||||
`del_verbose` 参数指定要关闭 Debug 日志的包名或类名。
|
||||
|
||||
## 开启 BE Debug 日志
|
||||
|
||||
BE 的 Debug 日志目前仅支持通过配置文件修改并重启 BE 节点以生效。
|
||||
|
||||
```text
|
||||
sys_log_verbose_modules=plan_fragment_executor,olap_scan_node
|
||||
sys_log_verbose_level=3
|
||||
```
|
||||
|
||||
`sys_log_verbose_modules` 指定要开启的文件名,可以通过通配符 * 指定。比如:
|
||||
|
||||
```text
|
||||
sys_log_verbose_modules=*
|
||||
```
|
||||
|
||||
表示开启所有 DEBUG 日志。
|
||||
|
||||
`sys_log_verbose_level` 表示 DEBUG 的级别。数字越大,则 DEBUG 日志越详细。取值范围在 1-10。
|
||||
170
new-docs/zh-CN/advanced/best-practice/import-analysis.md
Normal file
170
new-docs/zh-CN/advanced/best-practice/import-analysis.md
Normal file
@ -0,0 +1,170 @@
|
||||
---
|
||||
{
|
||||
"title": "导入分析",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 导入分析
|
||||
|
||||
Doris 提供了一个图形化的命令以帮助用户更方便的分析一个具体的导入。本文介绍如何使用该功能。
|
||||
|
||||
> 该功能目前仅针对 Broker Load 的分析。
|
||||
|
||||
## 导入计划树
|
||||
|
||||
如果你对 Doris 的查询计划树还不太了解,请先阅读之前的文章 [DORIS/最佳实践/查询分析](./query-analysis.html)。
|
||||
|
||||
一个 [Broker Load](../../data-operate/import/import-way/broker-load-manual.html) 请求的执行过程,也是基于 Doris 的查询框架的。一个Broker Load 作业会根据导入请求中 DATA INFILE 子句的个数讲作业拆分成多个子任务。每个子任务可以视为是一个独立的导入执行计划。一个导入计划的组成只会有一个 Fragment,其组成如下:
|
||||
|
||||
```sql
|
||||
┌─────────────┐
|
||||
│OlapTableSink│
|
||||
└─────────────┘
|
||||
│
|
||||
┌──────────────┐
|
||||
│BrokerScanNode│
|
||||
└──────────────┘
|
||||
```
|
||||
|
||||
BrokerScanNode 主要负责去读源数据并发送给 OlapTableSink,而 OlapTableSink 负责将数据按照分区分桶规则发送到对应的节点,由对应的节点负责实际的数据写入。
|
||||
|
||||
而这个导入执行计划的 Fragment 会根据导入源文件的数量、BE节点的数量等参数,划分成一个或多个 Instance。每个 Instance 负责一部分数据导入。
|
||||
|
||||
多个子任务的执行计划是并发执行的,而一个执行计划的多个 Instance 也是并行执行。
|
||||
|
||||
## 查看导入 Profile
|
||||
|
||||
用户可以通过以下命令打开会话变量 `is_report_success`:
|
||||
|
||||
```sql
|
||||
SET is_report_success=true;
|
||||
```
|
||||
|
||||
然后提交一个 Broker Load 导入请求,并等到导入执行完成。Doris 会产生该导入的一个 Profile。Profile 包含了一个导入各个子任务、Instance 的执行详情,有助于我们分析导入瓶颈。
|
||||
|
||||
> 目前不支持查看未执行成功的导入作业的 Profile。
|
||||
|
||||
我们可以通过如下命令先获取 Profile 列表:
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/";
|
||||
+---------+------+-----------+------+-----------+---------------------+---------------------+-----------+------------+
|
||||
| QueryId | User | DefaultDb | SQL | QueryType | StartTime | EndTime | TotalTime | QueryState |
|
||||
+---------+------+-----------+------+-----------+---------------------+---------------------+-----------+------------+
|
||||
| 10441 | N/A | N/A | N/A | Load | 2021-04-10 22:15:37 | 2021-04-10 22:18:54 | 3m17s | N/A |
|
||||
+---------+------+-----------+------+-----------+---------------------+---------------------+-----------+------------+
|
||||
```
|
||||
|
||||
这个命令会列出当前保存的所有导入 Profile。每行对应一个导入。其中 QueryId 列为导入作业的 ID。这个 ID 也可以通过 SHOW LOAD 语句查看拿到。我们可以选择我们想看的 Profile 对应的 QueryId,查看具体情况。
|
||||
|
||||
**查看一个Profile分为3个步骤:**
|
||||
|
||||
1. 查看子任务总览
|
||||
|
||||
通过以下命令查看有导入作业的子任务概况:
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/10441";
|
||||
+-----------------------------------+------------+
|
||||
| TaskId | ActiveTime |
|
||||
+-----------------------------------+------------+
|
||||
| 980014623046410a-88e260f0c43031f1 | 3m14s |
|
||||
+-----------------------------------+------------+
|
||||
```
|
||||
|
||||
如上图,表示 10441 这个导入作业总共有一个子任务,其中 ActiveTime 表示这个子任务中耗时最长的 Instance 的执行时间。
|
||||
|
||||
2. 查看指定子任务的 Instance 概况
|
||||
|
||||
当我们发现一个子任务耗时较长时,可以进一步查看该子任务的各个 Instance 的执行耗时:
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/10441/980014623046410a-88e260f0c43031f1";
|
||||
+-----------------------------------+------------------+------------+
|
||||
| Instances | Host | ActiveTime |
|
||||
+-----------------------------------+------------------+------------+
|
||||
| 980014623046410a-88e260f0c43031f2 | 10.81.85.89:9067 | 3m7s |
|
||||
| 980014623046410a-88e260f0c43031f3 | 10.81.85.89:9067 | 3m6s |
|
||||
| 980014623046410a-88e260f0c43031f4 | 10.81.85.89:9067 | 3m10s |
|
||||
| 980014623046410a-88e260f0c43031f5 | 10.81.85.89:9067 | 3m14s |
|
||||
+-----------------------------------+------------------+------------+
|
||||
```
|
||||
|
||||
这里展示了 980014623046410a-88e260f0c43031f1 这个子任务的四个 Instance 耗时,并且还展示了 Instance 所在的执行节点。
|
||||
|
||||
3. 查看具体 Instance
|
||||
|
||||
我们可以继续查看某一个具体的 Instance 上各个算子的详细 Profile:
|
||||
|
||||
|
||||
|
||||
```sql
|
||||
mysql> show load profile "/10441/980014623046410a-88e260f0c43031f1/980014623046410a-88e260f0c43031f5"\G
|
||||
*************************** 1. row ***************************
|
||||
Instance:
|
||||
┌-----------------------------------------┐
|
||||
│[-1: OlapTableSink] │
|
||||
│(Active: 2m17s, non-child: 70.91) │
|
||||
│ - Counters: │
|
||||
│ - CloseWaitTime: 1m53s │
|
||||
│ - ConvertBatchTime: 0ns │
|
||||
│ - MaxAddBatchExecTime: 1m46s │
|
||||
│ - NonBlockingSendTime: 3m11s │
|
||||
│ - NumberBatchAdded: 782 │
|
||||
│ - NumberNodeChannels: 1 │
|
||||
│ - OpenTime: 743.822us │
|
||||
│ - RowsFiltered: 0 │
|
||||
│ - RowsRead: 1.599729M (1599729) │
|
||||
│ - RowsReturned: 1.599729M (1599729)│
|
||||
│ - SendDataTime: 11s761ms │
|
||||
│ - TotalAddBatchExecTime: 1m46s │
|
||||
│ - ValidateDataTime: 9s802ms │
|
||||
└-----------------------------------------┘
|
||||
│
|
||||
┌-----------------------------------------------------┐
|
||||
│[0: BROKER_SCAN_NODE] │
|
||||
│(Active: 56s537ms, non-child: 29.06) │
|
||||
│ - Counters: │
|
||||
│ - BytesDecompressed: 0.00 │
|
||||
│ - BytesRead: 5.77 GB │
|
||||
│ - DecompressTime: 0ns │
|
||||
│ - FileReadTime: 34s263ms │
|
||||
│ - MaterializeTupleTime(*): 45s54ms │
|
||||
│ - NumDiskAccess: 0 │
|
||||
│ - PeakMemoryUsage: 33.03 MB │
|
||||
│ - RowsRead: 1.599729M (1599729) │
|
||||
│ - RowsReturned: 1.599729M (1599729) │
|
||||
│ - RowsReturnedRate: 28.295K /sec │
|
||||
│ - TotalRawReadTime(*): 1m20s │
|
||||
│ - TotalReadThroughput: 30.39858627319336 MB/sec│
|
||||
│ - WaitScannerTime: 56s528ms │
|
||||
└-----------------------------------------------------┘
|
||||
```
|
||||
|
||||
上图展示了子任务 980014623046410a-88e260f0c43031f1 中,Instance 980014623046410a-88e260f0c43031f5 的各个算子的具体 Profile。
|
||||
|
||||
通过以上3个步骤,我们可以逐步排查一个导入任务的执行瓶颈。
|
||||
501
new-docs/zh-CN/advanced/best-practice/query-analysis.md
Normal file
501
new-docs/zh-CN/advanced/best-practice/query-analysis.md
Normal file
@ -0,0 +1,501 @@
|
||||
---
|
||||
{
|
||||
"title": "查询分析",
|
||||
"language": "zh-CN"
|
||||
}
|
||||
---
|
||||
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 查询分析
|
||||
|
||||
Doris 提供了一个图形化的命令以帮助用户更方便的分析一个具体的查询或导入。本文介绍如何使用该功能。
|
||||
|
||||
## 查询计划树
|
||||
|
||||
SQL 是一个描述性语言,用户通过一个 SQL 来描述想获取的数据。而一个 SQL 的具体执行方式依赖于数据库的实现。而查询规划器就是用来决定数据库如何具体执行一个 SQL 的。
|
||||
|
||||
比如用户指定了一个 Join 算子,则查询规划器需要决定具体的 Join 算法,比如是 Hash Join,还是 Merge Sort Join;是使用 Shuffle 还是 Broadcast;Join 顺序是否需要调整以避免笛卡尔积;以及确定最终的在哪些节点执行等等。
|
||||
|
||||
Doris 的查询规划过程是先将一个 SQL 语句转换成一个单机执行计划树。
|
||||
|
||||
```text
|
||||
┌────┐
|
||||
│Sort│
|
||||
└────┘
|
||||
│
|
||||
┌───────────┐
|
||||
│Aggregation│
|
||||
└───────────┘
|
||||
│
|
||||
┌────┐
|
||||
│Join│
|
||||
└────┘
|
||||
┌───┴────┐
|
||||
┌──────┐ ┌──────┐
|
||||
│Scan-1│ │Scan-2│
|
||||
└──────┘ └──────┘
|
||||
```
|
||||
|
||||
之后,查询规划器会根据具体的算子执行方式、数据的具体分布,将单机查询计划转换为分布式查询计划。分布式查询计划是由多个 Fragment 组成的,每个 Fragment 负责查询计划的一部分,各个 Fragment 之间会通过 ExchangeNode 算子进行数据的传输。
|
||||
|
||||
```text
|
||||
┌────┐
|
||||
│Sort│
|
||||
│F1 │
|
||||
└────┘
|
||||
│
|
||||
┌───────────┐
|
||||
│Aggregation│
|
||||
│F1 │
|
||||
└───────────┘
|
||||
│
|
||||
┌────┐
|
||||
│Join│
|
||||
│F1 │
|
||||
└────┘
|
||||
┌──────┴────┐
|
||||
┌──────┐ ┌────────────┐
|
||||
│Scan-1│ │ExchangeNode│
|
||||
│F1 │ │F1 │
|
||||
└──────┘ └────────────┘
|
||||
│
|
||||
┌──────────────┐
|
||||
│DataStreamDink│
|
||||
│F2 │
|
||||
└──────────────┘
|
||||
│
|
||||
┌──────┐
|
||||
│Scan-2│
|
||||
│F2 │
|
||||
└──────┘
|
||||
```
|
||||
|
||||
如上图,我们将单机计划分成了两个 Fragment:F1 和 F2。两个 Fragment 之间通过一个 ExchangeNode 节点传输数据。
|
||||
|
||||
而一个 Fragment 会进一步的划分为多个 Instance。Instance 是最终具体的执行实例。划分成多个 Instance 有助于充分利用机器资源,提升一个 Fragment 的执行并发度。
|
||||
|
||||
## 查看查询计划
|
||||
|
||||
可以通过以下两种命令查看一个 SQL 的执行计划。
|
||||
|
||||
- `EXPLAIN GRAPH select ...;`
|
||||
- `EXPLAIN select ...;`
|
||||
|
||||
其中第一个命令以图形化的方式展示一个查询计划,这个命令可以比较直观的展示查询计划的树形结构,以及 Fragment 的划分情况:
|
||||
|
||||
```sql
|
||||
mysql> desc graph select tbl1.k1, sum(tbl1.k2) from tbl1 join tbl2 on tbl1.k1 = tbl2.k1 group by tbl1.k1 order by tbl1.k1;
|
||||
+---------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------+
|
||||
| |
|
||||
| ┌───────────────┐ |
|
||||
| │[9: ResultSink]│ |
|
||||
| │[Fragment: 4] │ |
|
||||
| │RESULT SINK │ |
|
||||
| └───────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────────────┐ |
|
||||
| │[9: MERGING-EXCHANGE]│ |
|
||||
| │[Fragment: 4] │ |
|
||||
| └─────────────────────┘ |
|
||||
| │ |
|
||||
| ┌───────────────────┐ |
|
||||
| │[9: DataStreamSink]│ |
|
||||
| │[Fragment: 3] │ |
|
||||
| │STREAM DATA SINK │ |
|
||||
| │ EXCHANGE ID: 09 │ |
|
||||
| │ UNPARTITIONED │ |
|
||||
| └───────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────┐ |
|
||||
| │[4: TOP-N] │ |
|
||||
| │[Fragment: 3]│ |
|
||||
| └─────────────┘ |
|
||||
| │ |
|
||||
| ┌───────────────────────────────┐ |
|
||||
| │[8: AGGREGATE (merge finalize)]│ |
|
||||
| │[Fragment: 3] │ |
|
||||
| └───────────────────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────┐ |
|
||||
| │[7: EXCHANGE]│ |
|
||||
| │[Fragment: 3]│ |
|
||||
| └─────────────┘ |
|
||||
| │ |
|
||||
| ┌───────────────────┐ |
|
||||
| │[7: DataStreamSink]│ |
|
||||
| │[Fragment: 2] │ |
|
||||
| │STREAM DATA SINK │ |
|
||||
| │ EXCHANGE ID: 07 │ |
|
||||
| │ HASH_PARTITIONED │ |
|
||||
| └───────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────────────────────────┐ |
|
||||
| │[3: AGGREGATE (update serialize)]│ |
|
||||
| │[Fragment: 2] │ |
|
||||
| │STREAMING │ |
|
||||
| └─────────────────────────────────┘ |
|
||||
| │ |
|
||||
| ┌─────────────────────────────────┐ |
|
||||
| │[2: HASH JOIN] │ |
|
||||
| │[Fragment: 2] │ |
|
||||
| │join op: INNER JOIN (PARTITIONED)│ |
|
||||
| └─────────────────────────────────┘ |
|
||||
| ┌──────────┴──────────┐ |
|
||||
| ┌─────────────┐ ┌─────────────┐ |
|
||||
| │[5: EXCHANGE]│ │[6: EXCHANGE]│ |
|
||||
| │[Fragment: 2]│ │[Fragment: 2]│ |
|
||||
| └─────────────┘ └─────────────┘ |
|
||||
| │ │ |
|
||||
| ┌───────────────────┐ ┌───────────────────┐ |
|
||||
| │[5: DataStreamSink]│ │[6: DataStreamSink]│ |
|
||||
| │[Fragment: 0] │ │[Fragment: 1] │ |
|
||||
| │STREAM DATA SINK │ │STREAM DATA SINK │ |
|
||||
| │ EXCHANGE ID: 05 │ │ EXCHANGE ID: 06 │ |
|
||||
| │ HASH_PARTITIONED │ │ HASH_PARTITIONED │ |
|
||||
| └───────────────────┘ └───────────────────┘ |
|
||||
| │ │ |
|
||||
| ┌─────────────────┐ ┌─────────────────┐ |
|
||||
| │[0: OlapScanNode]│ │[1: OlapScanNode]│ |
|
||||
| │[Fragment: 0] │ │[Fragment: 1] │ |
|
||||
| │TABLE: tbl1 │ │TABLE: tbl2 │ |
|
||||
| └─────────────────┘ └─────────────────┘ |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
从图中可以看出,查询计划树被分为了5个 Fragment:0、1、2、3、4。如 `OlapScanNode` 节点上的 `[Fragment: 0]` 表示这个节点属于 Fragment 0。每个Fragment之间都通过 DataStreamSink 和 ExchangeNode 进行数据传输。
|
||||
|
||||
图形命令仅展示简化后的节点信息,如果需要查看更具体的节点信息,如下推到节点上的过滤条件等,则需要通过第二个命令查看更详细的文字版信息:
|
||||
|
||||
```sql
|
||||
mysql> explain select tbl1.k1, sum(tbl1.k2) from tbl1 join tbl2 on tbl1.k1 = tbl2.k1 group by tbl1.k1 order by tbl1.k1;
|
||||
+----------------------------------------------------------------------------------+
|
||||
| Explain String |
|
||||
+----------------------------------------------------------------------------------+
|
||||
| PLAN FRAGMENT 0 |
|
||||
| OUTPUT EXPRS:<slot 5> <slot 3> `tbl1`.`k1` | <slot 6> <slot 4> sum(`tbl1`.`k2`) |
|
||||
| PARTITION: UNPARTITIONED |
|
||||
| |
|
||||
| RESULT SINK |
|
||||
| |
|
||||
| 9:MERGING-EXCHANGE |
|
||||
| limit: 65535 |
|
||||
| |
|
||||
| PLAN FRAGMENT 1 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: <slot 3> `tbl1`.`k1` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 09 |
|
||||
| UNPARTITIONED |
|
||||
| |
|
||||
| 4:TOP-N |
|
||||
| | order by: <slot 5> <slot 3> `tbl1`.`k1` ASC |
|
||||
| | offset: 0 |
|
||||
| | limit: 65535 |
|
||||
| | |
|
||||
| 8:AGGREGATE (merge finalize) |
|
||||
| | output: sum(<slot 4> sum(`tbl1`.`k2`)) |
|
||||
| | group by: <slot 3> `tbl1`.`k1` |
|
||||
| | cardinality=-1 |
|
||||
| | |
|
||||
| 7:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 2 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: HASH_PARTITIONED: `tbl1`.`k1` |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 07 |
|
||||
| HASH_PARTITIONED: <slot 3> `tbl1`.`k1` |
|
||||
| |
|
||||
| 3:AGGREGATE (update serialize) |
|
||||
| | STREAMING |
|
||||
| | output: sum(`tbl1`.`k2`) |
|
||||
| | group by: `tbl1`.`k1` |
|
||||
| | cardinality=-1 |
|
||||
| | |
|
||||
| 2:HASH JOIN |
|
||||
| | join op: INNER JOIN (PARTITIONED) |
|
||||
| | runtime filter: false |
|
||||
| | hash predicates: |
|
||||
| | colocate: false, reason: table not in the same group |
|
||||
| | equal join conjunct: `tbl1`.`k1` = `tbl2`.`k1` |
|
||||
| | cardinality=2 |
|
||||
| | |
|
||||
| |----6:EXCHANGE |
|
||||
| | |
|
||||
| 5:EXCHANGE |
|
||||
| |
|
||||
| PLAN FRAGMENT 3 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 06 |
|
||||
| HASH_PARTITIONED: `tbl2`.`k1` |
|
||||
| |
|
||||
| 1:OlapScanNode |
|
||||
| TABLE: tbl2 |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: tbl2 |
|
||||
| tabletRatio=3/3 |
|
||||
| tabletList=105104776,105104780,105104784 |
|
||||
| cardinality=1 |
|
||||
| avgRowSize=4.0 |
|
||||
| numNodes=6 |
|
||||
| |
|
||||
| PLAN FRAGMENT 4 |
|
||||
| OUTPUT EXPRS: |
|
||||
| PARTITION: RANDOM |
|
||||
| |
|
||||
| STREAM DATA SINK |
|
||||
| EXCHANGE ID: 05 |
|
||||
| HASH_PARTITIONED: `tbl1`.`k1` |
|
||||
| |
|
||||
| 0:OlapScanNode |
|
||||
| TABLE: tbl1 |
|
||||
| PREAGGREGATION: ON |
|
||||
| partitions=1/1 |
|
||||
| rollup: tbl1 |
|
||||
| tabletRatio=3/3 |
|
||||
| tabletList=105104752,105104763,105104767 |
|
||||
| cardinality=2 |
|
||||
| avgRowSize=8.0 |
|
||||
| numNodes=6 |
|
||||
+----------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
> 查询计划中显示的信息还在不断规范和完善中,我们将在后续的文章中详细介绍。
|
||||
|
||||
## 查看查询 Profile
|
||||
|
||||
用户可以通过以下命令打开会话变量 `is_report_success`:
|
||||
|
||||
```sql
|
||||
SET is_report_success=true;
|
||||
```
|
||||
|
||||
然后执行查询,则 Doris 会产生该查询的一个 Profile。Profile 包含了一个查询各个节点的具体执行情况,有助于我们分析查询瓶颈。
|
||||
|
||||
执行完查询后,我们可以通过如下命令先获取 Profile 列表:
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/"\G
|
||||
*************************** 1. row ***************************
|
||||
QueryId: c257c52f93e149ee-ace8ac14e8c9fef9
|
||||
User: root
|
||||
DefaultDb: default_cluster:db1
|
||||
SQL: select tbl1.k1, sum(tbl1.k2) from tbl1 join tbl2 on tbl1.k1 = tbl2.k1 group by tbl1.k1 order by tbl1.k1
|
||||
QueryType: Query
|
||||
StartTime: 2021-04-08 11:30:50
|
||||
EndTime: 2021-04-08 11:30:50
|
||||
TotalTime: 9ms
|
||||
QueryState: EOF
|
||||
```
|
||||
|
||||
这个命令会列出当前保存的所有 Profile。每行对应一个查询。我们可以选择我们想看的 Profile 对应的 QueryId,查看具体情况。
|
||||
|
||||
查看一个Profile分为3个步骤:
|
||||
|
||||
1. 查看整体执行计划树
|
||||
|
||||
这一步主要用于从整体分析执行计划,并查看每个Fragment的执行耗时。
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/c257c52f93e149ee-ace8ac14e8c9fef9"\G
|
||||
*************************** 1. row ***************************
|
||||
Fragments:
|
||||
┌──────────────────────┐
|
||||
│[-1: DataBufferSender]│
|
||||
│Fragment: 0 │
|
||||
│MaxActiveTime: 6.626ms│
|
||||
└──────────────────────┘
|
||||
│
|
||||
┌──────────────────┐
|
||||
│[9: EXCHANGE_NODE]│
|
||||
│Fragment: 0 │
|
||||
└──────────────────┘
|
||||
│
|
||||
┌──────────────────────┐
|
||||
│[9: DataStreamSender] │
|
||||
│Fragment: 1 │
|
||||
│MaxActiveTime: 5.449ms│
|
||||
└──────────────────────┘
|
||||
│
|
||||
┌──────────────┐
|
||||
│[4: SORT_NODE]│
|
||||
│Fragment: 1 │
|
||||
└──────────────┘
|
||||
┌┘
|
||||
┌─────────────────────┐
|
||||
│[8: AGGREGATION_NODE]│
|
||||
│Fragment: 1 │
|
||||
└─────────────────────┘
|
||||
└┐
|
||||
┌──────────────────┐
|
||||
│[7: EXCHANGE_NODE]│
|
||||
│Fragment: 1 │
|
||||
└──────────────────┘
|
||||
│
|
||||
┌──────────────────────┐
|
||||
│[7: DataStreamSender] │
|
||||
│Fragment: 2 │
|
||||
│MaxActiveTime: 3.505ms│
|
||||
└──────────────────────┘
|
||||
┌┘
|
||||
┌─────────────────────┐
|
||||
│[3: AGGREGATION_NODE]│
|
||||
│Fragment: 2 │
|
||||
└─────────────────────┘
|
||||
│
|
||||
┌───────────────────┐
|
||||
│[2: HASH_JOIN_NODE]│
|
||||
│Fragment: 2 │
|
||||
└───────────────────┘
|
||||
┌────────────┴────────────┐
|
||||
┌──────────────────┐ ┌──────────────────┐
|
||||
│[5: EXCHANGE_NODE]│ │[6: EXCHANGE_NODE]│
|
||||
│Fragment: 2 │ │Fragment: 2 │
|
||||
└──────────────────┘ └──────────────────┘
|
||||
│ │
|
||||
┌─────────────────────┐ ┌────────────────────────┐
|
||||
│[5: DataStreamSender]│ │[6: DataStreamSender] │
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
│MaxActiveTime: 1.87ms│ │MaxActiveTime: 636.767us│
|
||||
└─────────────────────┘ └────────────────────────┘
|
||||
│ ┌┘
|
||||
┌───────────────────┐ ┌───────────────────┐
|
||||
│[0: OLAP_SCAN_NODE]│ │[1: OLAP_SCAN_NODE]│
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
└───────────────────┘ └───────────────────┘
|
||||
│ │
|
||||
┌─────────────┐ ┌─────────────┐
|
||||
│[OlapScanner]│ │[OlapScanner]│
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
└─────────────┘ └─────────────┘
|
||||
│ │
|
||||
┌─────────────────┐ ┌─────────────────┐
|
||||
│[SegmentIterator]│ │[SegmentIterator]│
|
||||
│Fragment: 4 │ │Fragment: 3 │
|
||||
└─────────────────┘ └─────────────────┘
|
||||
|
||||
1 row in set (0.02 sec)
|
||||
```
|
||||
|
||||
如上图,每个节点都标注了自己所属的 Fragment,并且在每个 Fragment 的 Sender节点,标注了该 Fragment 的执行耗时。这个耗时,是Fragment下所有 Instance 执行耗时中最长的一个。这个有助于我们从整体角度发现最耗时的 Fragment。
|
||||
|
||||
2. 查看具体 Fragment 下的 Instance 列表
|
||||
|
||||
比如我们发现 Fragment 1 耗时最长,则可以继续查看 Fragment 1 的 Instance 列表:
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/c257c52f93e149ee-ace8ac14e8c9fef9/1";
|
||||
+-----------------------------------+-------------------+------------+
|
||||
| Instances | Host | ActiveTime |
|
||||
+-----------------------------------+-------------------+------------+
|
||||
| c257c52f93e149ee-ace8ac14e8c9ff03 | 10.200.00.01:9060 | 5.449ms |
|
||||
| c257c52f93e149ee-ace8ac14e8c9ff05 | 10.200.00.02:9060 | 5.367ms |
|
||||
| c257c52f93e149ee-ace8ac14e8c9ff04 | 10.200.00.03:9060 | 5.358ms |
|
||||
+-----------------------------------+-------------------+------------+
|
||||
```
|
||||
|
||||
这里展示了 Fragment 1 上所有的 3 个 Instance 所在的执行节点和耗时。
|
||||
|
||||
1. 查看具体 Instance
|
||||
|
||||
我们可以继续查看某一个具体的 Instance 上各个算子的详细 Profile:
|
||||
|
||||
```sql
|
||||
mysql> show query profile "/c257c52f93e149ee-ace8ac14e8c9fef9/1/c257c52f93e149ee-ace8ac14e8c9ff03"\G
|
||||
*************************** 1. row ***************************
|
||||
Instance:
|
||||
┌───────────────────────────────────────┐
|
||||
│[9: DataStreamSender] │
|
||||
│(Active: 37.222us, non-child: 0.40) │
|
||||
│ - Counters: │
|
||||
│ - BytesSent: 0.00 │
|
||||
│ - IgnoreRows: 0 │
|
||||
│ - OverallThroughput: 0.0 /sec │
|
||||
│ - PeakMemoryUsage: 8.00 KB │
|
||||
│ - SerializeBatchTime: 0ns │
|
||||
│ - UncompressedRowBatchSize: 0.00 │
|
||||
└───────────────────────────────────────┘
|
||||
└┐
|
||||
│
|
||||
┌──────────────────────────────────┐
|
||||
│[4: SORT_NODE] │
|
||||
│(Active: 5.421ms, non-child: 0.71)│
|
||||
│ - Counters: │
|
||||
│ - PeakMemoryUsage: 12.00 KB │
|
||||
│ - RowsReturned: 0 │
|
||||
│ - RowsReturnedRate: 0 │
|
||||
└──────────────────────────────────┘
|
||||
┌┘
|
||||
│
|
||||
┌───────────────────────────────────┐
|
||||
│[8: AGGREGATION_NODE] │
|
||||
│(Active: 5.355ms, non-child: 10.68)│
|
||||
│ - Counters: │
|
||||
│ - BuildTime: 3.701us │
|
||||
│ - GetResultsTime: 0ns │
|
||||
│ - HTResize: 0 │
|
||||
│ - HTResizeTime: 1.211us │
|
||||
│ - HashBuckets: 0 │
|
||||
│ - HashCollisions: 0 │
|
||||
│ - HashFailedProbe: 0 │
|
||||
│ - HashFilledBuckets: 0 │
|
||||
│ - HashProbe: 0 │
|
||||
│ - HashTravelLength: 0 │
|
||||
│ - LargestPartitionPercent: 0 │
|
||||
│ - MaxPartitionLevel: 0 │
|
||||
│ - NumRepartitions: 0 │
|
||||
│ - PartitionsCreated: 16 │
|
||||
│ - PeakMemoryUsage: 34.02 MB │
|
||||
│ - RowsProcessed: 0 │
|
||||
│ - RowsRepartitioned: 0 │
|
||||
│ - RowsReturned: 0 │
|
||||
│ - RowsReturnedRate: 0 │
|
||||
│ - SpilledPartitions: 0 │
|
||||
└───────────────────────────────────┘
|
||||
└┐
|
||||
│
|
||||
┌──────────────────────────────────────────┐
|
||||
│[7: EXCHANGE_NODE] │
|
||||
│(Active: 4.360ms, non-child: 46.84) │
|
||||
│ - Counters: │
|
||||
│ - BytesReceived: 0.00 │
|
||||
│ - ConvertRowBatchTime: 387ns │
|
||||
│ - DataArrivalWaitTime: 4.357ms │
|
||||
│ - DeserializeRowBatchTimer: 0ns │
|
||||
│ - FirstBatchArrivalWaitTime: 4.356ms│
|
||||
│ - PeakMemoryUsage: 0.00 │
|
||||
│ - RowsReturned: 0 │
|
||||
│ - RowsReturnedRate: 0 │
|
||||
│ - SendersBlockedTotalTimer(*): 0ns │
|
||||
└──────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
上图展示了 Fragment 1 中,Instance c257c52f93e149ee-ace8ac14e8c9ff03 的各个算子的具体 Profile。
|
||||
|
||||
通过以上3个步骤,我们可以逐步排查一个SQL的性能瓶颈。
|
||||
@ -26,7 +26,7 @@ under the License.
|
||||
|
||||
# 批量删除
|
||||
|
||||
目前Doris 支持`Broker Load`,` Routine Load`, `Stream Load` 等多种导入方式,对于数据的删除目前只能通过delete语句进行删除,使用delete 语句的方式删除时,每执行一次delete 都会生成一个新的数据版本,如果频繁删除会严重影响查询性能,并且在使用delete方式删除时,是通过生成一个空的rowset来记录删除条件实现,每次读取都要对删除条件进行过滤,同样在条件较多时会对性能造成影响。对比其他的系统,greenplum 的实现方式更像是传统数据库产品,snowflake 通过merge 语法实现。
|
||||
目前Doris 支持 [Broker Load](../import/import-way/broker-load-manual.html),[Routine Load](../import/import-way/routine-load-manual.html), [Stream Load](../import/import-way/stream-load-manual.html) 等多种导入方式,对于数据的删除目前只能通过delete语句进行删除,使用delete 语句的方式删除时,每执行一次delete 都会生成一个新的数据版本,如果频繁删除会严重影响查询性能,并且在使用delete方式删除时,是通过生成一个空的rowset来记录删除条件实现,每次读取都要对删除条件进行过滤,同样在条件较多时会对性能造成影响。对比其他的系统,greenplum 的实现方式更像是传统数据库产品,snowflake 通过merge 语法实现。
|
||||
|
||||
对于类似于cdc数据导入的场景,数据中insert和delete一般是穿插出现的,面对这种场景我们目前的导入方式也无法满足,即使我们能够分离出insert和delete虽然可以解决导入的问题,但是仍然解决不了删除的问题。使用批量删除功能可以解决这些个别场景的需求。数据导入有三种合并方式:
|
||||
|
||||
|
||||
@ -24,4 +24,175 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 最佳实践
|
||||
# 最佳实践
|
||||
|
||||
## 建表
|
||||
|
||||
### 数据模型选择
|
||||
|
||||
Doris 数据模型上目前分为三类: AGGREGATE KEY, UNIQUE KEY, DUPLICATE KEY。三种模型中数据都是按KEY进行排序。
|
||||
|
||||
#### AGGREGATE KEY
|
||||
|
||||
AGGREGATE KEY相同时,新旧记录进行聚合,目前支持的聚合函数有SUM, MIN, MAX, REPLACE。
|
||||
|
||||
AGGREGATE KEY模型可以提前聚合数据, 适合报表和多维分析业务。
|
||||
|
||||
```sql
|
||||
CREATE TABLE site_visit
|
||||
(
|
||||
siteid INT,
|
||||
city SMALLINT,
|
||||
username VARCHAR(32),
|
||||
pv BIGINT SUM DEFAULT '0'
|
||||
)
|
||||
AGGREGATE KEY(siteid, city, username)
|
||||
DISTRIBUTED BY HASH(siteid) BUCKETS 10;
|
||||
```
|
||||
|
||||
#### UNIQUE KEY
|
||||
|
||||
UNIQUE KEY 相同时,新记录覆盖旧记录。目前 UNIQUE KEY 实现上和 AGGREGATE KEY 的 REPLACE 聚合方法一样,二者本质上相同。适用于有更新需求的分析业务。
|
||||
|
||||
```sql
|
||||
CREATE TABLE sales_order
|
||||
(
|
||||
orderid BIGINT,
|
||||
status TINYINT,
|
||||
username VARCHAR(32),
|
||||
amount BIGINT DEFAULT '0'
|
||||
)
|
||||
UNIQUE KEY(orderid)
|
||||
DISTRIBUTED BY HASH(orderid) BUCKETS 10;
|
||||
```
|
||||
|
||||
#### DUPLICATE KEY
|
||||
|
||||
只指定排序列,相同的行不会合并。适用于数据无需提前聚合的分析业务。
|
||||
|
||||
```sql
|
||||
CREATE TABLE session_data
|
||||
(
|
||||
visitorid SMALLINT,
|
||||
sessionid BIGINT,
|
||||
visittime DATETIME,
|
||||
city CHAR(20),
|
||||
province CHAR(20),
|
||||
ip varchar(32),
|
||||
brower CHAR(20),
|
||||
url VARCHAR(1024)
|
||||
)
|
||||
DUPLICATE KEY(visitorid, sessionid)
|
||||
DISTRIBUTED BY HASH(sessionid, visitorid) BUCKETS 10;
|
||||
```
|
||||
|
||||
### 大宽表与 Star Schema
|
||||
|
||||
业务方建表时, 为了和前端业务适配, 往往不对维度信息和指标信息加以区分, 而将 Schema 定义成大宽表。对于 Doris 而言, 这类大宽表往往性能不尽如人意:
|
||||
|
||||
- Schema 中字段数比较多, 聚合模型中可能 key 列比较多, 导入过程中需要排序的列会增加。
|
||||
- 维度信息更新会反应到整张表中,而更新的频率直接影响查询的效率。
|
||||
|
||||
使用过程中,建议用户尽量使用 Star Schema 区分维度表和指标表。频繁更新的维度表也可以放在 MySQL 外部表中。而如果只有少量更新, 可以直接放在 Doris 中。在 Doris 中存储维度表时,可对维度表设置更多的副本,提升 Join 的性能。
|
||||
|
||||
### 分区和分桶
|
||||
|
||||
Doris 支持两级分区存储, 第一层为分区(partition),目前支持 RANGE 分区和 LIST 分区两种类型, 第二层为 HASH 分桶(bucket)。
|
||||
|
||||
#### 分区(partition)
|
||||
|
||||
分区用于将数据划分成不同区间, 逻辑上可以理解为将原始表划分成了多个子表。可以方便的按分区对数据进行管理,例如,删除数据时,更加迅速。
|
||||
|
||||
##### RANGE分区
|
||||
|
||||
业务上,多数用户会选择采用按时间进行partition, 让时间进行partition有以下好处:
|
||||
|
||||
* 可区分冷热数据
|
||||
* 可用上Doris分级存储(SSD + SATA)的功能
|
||||
|
||||
##### LIST分区
|
||||
|
||||
业务上,用户可以选择城市或者其他枚举值进行partition。
|
||||
|
||||
#### HASH分桶(bucket)
|
||||
|
||||
根据hash值将数据划分成不同的 bucket。
|
||||
|
||||
* 建议采用区分度大的列做分桶, 避免出现数据倾斜
|
||||
* 为方便数据恢复, 建议单个 bucket 的 size 不要太大, 保持在 10GB 以内, 所以建表或增加 partition 时请合理考虑 bucket 数目, 其中不同 partition 可指定不同的 buckets 数。
|
||||
|
||||
### 稀疏索引和 Bloom Filter
|
||||
|
||||
Doris对数据进行有序存储, 在数据有序的基础上为其建立稀疏索引,索引粒度为 block(1024行)。
|
||||
|
||||
稀疏索引选取 schema 中固定长度的前缀作为索引内容, 目前 Doris 选取 36 个字节的前缀作为索引。
|
||||
|
||||
- 建表时建议将查询中常见的过滤字段放在 Schema 的前面, 区分度越大,频次越高的查询字段越往前放。
|
||||
- 这其中有一个特殊的地方,就是 varchar 类型的字段。varchar 类型字段只能作为稀疏索引的最后一个字段。索引会在 varchar 处截断, 因此 varchar 如果出现在前面,可能索引的长度可能不足 36 个字节。具体可以参阅 [数据模型](./data-model.html)、[ROLLUP 及查询](./hit-the-rollup.html)。
|
||||
- 除稀疏索引之外, Doris还提供bloomfilter索引, bloomfilter索引对区分度比较大的列过滤效果明显。 如果考虑到varchar不能放在稀疏索引中, 可以建立bloomfilter索引。
|
||||
|
||||
### 物化视图(rollup)
|
||||
|
||||
Rollup 本质上可以理解为原始表(Base Table)的一个物化索引。建立 Rollup 时可只选取 Base Table 中的部分列作为 Schema。Schema 中的字段顺序也可与 Base Table 不同。
|
||||
|
||||
下列情形可以考虑建立 Rollup:
|
||||
|
||||
#### Base Table 中数据聚合度不高。
|
||||
|
||||
这一般是因 Base Table 有区分度比较大的字段而导致。此时可以考虑选取部分列,建立 Rollup。
|
||||
|
||||
如对于 `site_visit` 表:
|
||||
|
||||
```text
|
||||
site_visit(siteid, city, username, pv)
|
||||
```
|
||||
|
||||
siteid 可能导致数据聚合度不高,如果业务方经常根据城市统计pv需求,可以建立一个只有 city, pv 的 Rollup:
|
||||
|
||||
```sql
|
||||
ALTER TABLE site_visit ADD ROLLUP rollup_city(city, pv);
|
||||
```
|
||||
|
||||
#### Base Table 中的前缀索引无法命中
|
||||
|
||||
这一般是 Base Table 的建表方式无法覆盖所有的查询模式。此时可以考虑调整列顺序,建立 Rollup。
|
||||
|
||||
如对于 session_data 表:
|
||||
|
||||
```text
|
||||
session_data(visitorid, sessionid, visittime, city, province, ip, brower, url)
|
||||
```
|
||||
|
||||
如果除了通过 visitorid 分析访问情况外,还有通过 brower, province 分析的情形,可以单独建立 Rollup。
|
||||
|
||||
```sql
|
||||
ALTER TABLE session_data ADD ROLLUP rollup_brower(brower,province,ip,url) DUPLICATE KEY(brower,province);
|
||||
```
|
||||
|
||||
## Schema Change
|
||||
|
||||
Doris中目前进行 Schema Change 的方式有三种:Sorted Schema Change,Direct Schema Change, Linked Schema Change。
|
||||
|
||||
### Sorted Schema Change
|
||||
|
||||
改变了列的排序方式,需对数据进行重新排序。例如删除排序列中的一列, 字段重排序。
|
||||
|
||||
```sql
|
||||
ALTER TABLE site_visit DROP COLUMN city;
|
||||
```
|
||||
|
||||
### Direct Schema Change
|
||||
|
||||
无需重新排序,但是需要对数据做一次转换。例如修改列的类型,在稀疏索引中加一列等。
|
||||
|
||||
```sql
|
||||
ALTER TABLE site_visit MODIFY COLUMN username varchar(64);
|
||||
```
|
||||
|
||||
### Linked Schema Change
|
||||
|
||||
```sql
|
||||
ALTER TABLE site_visit ADD COLUMN click bigint SUM default '0';
|
||||
```
|
||||
|
||||
建表时建议考虑好 Schema,这样在进行 Schema Change 时可以加快速度。
|
||||
Reference in New Issue
Block a user