[Refactor][doc] add data model and index doc (#8916)
This commit is contained in:
@ -79,8 +79,10 @@ CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "user min dwell time"
|
||||
)
|
||||
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
|
||||
... /* ignore Partition and Distribution */
|
||||
;
|
||||
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
As you can see, this is a typical fact table of user information and access behavior.
|
||||
@ -262,8 +264,10 @@ CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
`register_time` DATETIME COMMENT "29992;" 25143;"27880;" 20876;"26102;" 38388;"
|
||||
)
|
||||
Unique Key (`user_id`, `username`)
|
||||
... /* ignore Partition and Distribution */
|
||||
;
|
||||
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
This table structure is exactly the same as the following table structure described by the aggregation model:
|
||||
@ -293,8 +297,10 @@ CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
`register_time` DATETIME REPLACE COMMENT "29992;" 25143;"27880;" 20876;"26102;"
|
||||
)
|
||||
AGGREGATE KEY(`user_id`, `username`)
|
||||
... /* ignore Partition and Distribution */
|
||||
;
|
||||
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
That is to say, Uniq model can be completely replaced by REPLACE in aggregation model. Its internal implementation and data storage are exactly the same. No further examples will be given here.
|
||||
@ -316,16 +322,18 @@ The TABLE statement is as follows:
|
||||
```
|
||||
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
(
|
||||
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
|
||||
`type` INT NOT NULL COMMENT "日志类型",
|
||||
"Error"\\\\\\\\\\\\\
|
||||
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
|
||||
`op_id` BIGINT COMMENT "负责人id",
|
||||
OP `op `time ` DATETIME COMMENT "22788;" 29702;"26102;" 388;"
|
||||
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
|
||||
`type` INT NOT NULL COMMENT "日志类型",
|
||||
`error_code` INT COMMENT "错误码",
|
||||
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
|
||||
`op_id` BIGINT COMMENT "负责人id",
|
||||
`op_time` DATETIME COMMENT "处理时间"
|
||||
)
|
||||
DUPLICATE KEY(`timestamp`, `type`)
|
||||
... /* 省略 Partition 和 Distribution 信息 */
|
||||
;
|
||||
DISTRIBUTED BY HASH(`type`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
This data model is different from Aggregate and Uniq models. Data is stored entirely in accordance with the data in the imported file, without any aggregation. Even if the two rows of data are identical, they will be retained.
|
||||
@ -333,197 +341,6 @@ The DUPLICATE KEY specified in the table building statement is only used to spec
|
||||
|
||||
This data model is suitable for storing raw data without aggregation requirements and primary key uniqueness constraints. For more usage scenarios, see the ** Limitations of the Aggregation Model ** section.
|
||||
|
||||
## ROLLUP
|
||||
|
||||
ROLLUP in multidimensional analysis means "scroll up", which means that data is aggregated further at a specified granularity.
|
||||
|
||||
### Basic concepts
|
||||
|
||||
In Doris, we make the table created by the user through the table building statement a Base table. Base table holds the basic data stored in the way specified by the user's table-building statement.
|
||||
|
||||
On top of the Base table, we can create any number of ROLLUP tables. These ROLLUP data are generated based on the Base table and physically **stored independently**.
|
||||
|
||||
The basic function of ROLLUP tables is to obtain coarser aggregated data on the basis of Base tables.
|
||||
|
||||
Let's illustrate the ROLLUP tables and their roles in different data models with examples.
|
||||
|
||||
#### ROLLUP in Aggregate Model and Uniq Model
|
||||
|
||||
Because Uniq is only a special case of the Aggregate model, we do not distinguish it here.
|
||||
|
||||
Example 1: Get the total consumption per user
|
||||
|
||||
Following **Example 2** in the **Aggregate Model** section, the Base table structure is as follows:
|
||||
|
||||
|ColumnName|Type|AggregationType|Comment|
|
||||
|---|---|---|---|
|
||||
| user_id | LARGEINT | | user id|
|
||||
| date | DATE | | date of data filling|
|
||||
| Time stamp | DATETIME | | Data filling time, accurate to seconds|
|
||||
| City | VARCHAR (20) | | User City|
|
||||
| age | SMALLINT | | User age|
|
||||
| sex | TINYINT | | User gender|
|
||||
| Last_visit_date | DATETIME | REPLACE | Last user access time|
|
||||
| Cost | BIGINT | SUM | Total User Consumption|
|
||||
| max dwell time | INT | MAX | Maximum user residence time|
|
||||
| min dwell time | INT | MIN | User minimum residence time|
|
||||
|
||||
The data stored are as follows:
|
||||
|
||||
|user_id|date|timestamp|city|age|sex|last\_visit\_date|cost|max\_dwell\_time|min\_dwell\_time|
|
||||
|---|---|---|---|---|---|---|---|---|---|
|
||||
| 10000 | 2017-10-01 | 2017-10-01 08:00:05 | Beijing | 20 | 0 | 2017-10-01 06:00 | 20 | 10 | 10|
|
||||
| 10000 | 2017-10-01 | 2017-10-01 09:00:05 | Beijing | 20 | 0 | 2017-10-01 07:00 | 15 | 2 | 2|
|
||||
| 10001 | 2017-10-01 | 2017-10-01 18:12:10 | Beijing | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22|
|
||||
| 10002 | 2017-10-02 | 2017-10-02 13:10:00 | Shanghai | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5|
|
||||
| 10003 | 2017-10-02 | 2017-10-02 13:15:00 | Guangzhou | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11|
|
||||
| 10004 | 2017-10-01 | 2017-10-01 12:12:48 | Shenzhen | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3|
|
||||
| 10004 | 2017-10-03 | 2017-10-03 12:38:20 | Shenzhen | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6|
|
||||
|
||||
On this basis, we create a ROLLUP:
|
||||
|
||||
|ColumnName|
|
||||
|---|
|
||||
|user_id|
|
||||
|cost|
|
||||
|
||||
The ROLLUP contains only two columns: user_id and cost. After the creation, the data stored in the ROLLUP is as follows:
|
||||
|
||||
|user\_id|cost|
|
||||
|---|---|
|
||||
|10000|35|
|
||||
|10001|2|
|
||||
|10002|200|
|
||||
|10003|30|
|
||||
|10004|111|
|
||||
|
||||
As you can see, ROLLUP retains only the results of SUM on the cost column for each user_id. So when we do the following query:
|
||||
|
||||
`SELECT user_id, sum(cost) FROM table GROUP BY user_id;`
|
||||
|
||||
Doris automatically hits the ROLLUP table, thus completing the aggregated query by scanning only a very small amount of data.
|
||||
|
||||
2. Example 2: Get the total consumption, the longest and shortest page residence time of users of different ages in different cities
|
||||
|
||||
Follow example 1. Based on the Base table, we create a ROLLUP:
|
||||
|
||||
|ColumnName|Type|AggregationType|Comment|
|
||||
|---|---|---|---|
|
||||
| City | VARCHAR (20) | | User City|
|
||||
| age | SMALLINT | | User age|
|
||||
| Cost | BIGINT | SUM | Total User Consumption|
|
||||
| max dwell time | INT | MAX | Maximum user residence time|
|
||||
| min dwell time | INT | MIN | User minimum residence time|
|
||||
|
||||
After the creation, the data stored in the ROLLUP is as follows:
|
||||
|
||||
|city|age|cost|max\_dwell\_time|min\_dwell\_time|
|
||||
|---|---|---|---|---|
|
||||
| Beijing | 20 | 35 | 10 | 2|
|
||||
| Beijing | 30 | 2 | 22 | 22|
|
||||
| Shanghai | 20 | 200 | 5 | 5|
|
||||
| Guangzhou | 32 | 30 | 11 | 11|
|
||||
| Shenzhen | 35 | 111 | 6 | 3|
|
||||
|
||||
When we do the following queries:
|
||||
|
||||
* Select City, Age, Sum (Cost), Max (Max dwell time), min (min dwell time) from table group by City, age;*
|
||||
* `SELECT city, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city;`
|
||||
* `SELECT city, age, sum(cost), min(min_dwell_time) FROM table GROUP BY city, age;`
|
||||
|
||||
Doris automatically hits the ROLLUP table.
|
||||
|
||||
#### ROLLUP in Duplicate Model
|
||||
|
||||
Because the Duplicate model has no aggregate semantics. So the ROLLLUP in this model has lost the meaning of "scroll up". It's just to adjust the column order to hit the prefix index. In the next section, we will introduce prefix index in detail, and how to use ROLLUP to change prefix index in order to achieve better query efficiency.
|
||||
|
||||
### Prefix Index and ROLLUP
|
||||
|
||||
#### prefix index
|
||||
|
||||
Unlike traditional database design, Doris does not support indexing on any column. OLAP databases based on MPP architecture such as Doris usually handle large amounts of data by improving concurrency.
|
||||
In essence, Doris's data is stored in a data structure similar to SSTable (Sorted String Table). This structure is an ordered data structure, which can be sorted and stored according to the specified column. In this data structure, it is very efficient to search by sorting columns.
|
||||
|
||||
In Aggregate, Uniq and Duplicate three data models. The underlying data storage is sorted and stored according to the columns specified in AGGREGATE KEY, UNIQ KEY and DUPLICATE KEY in their respective table-building statements.
|
||||
|
||||
The prefix index, which is based on sorting, implements an index method to query data quickly according to a given prefix column.
|
||||
|
||||
We use the prefix index of **36 bytes** of a row of data as the prefix index of this row of data. When a VARCHAR type is encountered, the prefix index is truncated directly. We give examples to illustrate:
|
||||
|
||||
1. The prefix index of the following table structure is user_id (8 Bytes) + age (4 Bytes) + message (prefix 20 Bytes).
|
||||
|
||||
|ColumnName|Type|
|
||||
|---|---|
|
||||
|user_id|BIGINT|
|
||||
|age|INT|
|
||||
|message|VARCHAR(100)|
|
||||
|max\_dwell\_time|DATETIME|
|
||||
|min\_dwell\_time|DATETIME|
|
||||
|
||||
2. The prefix index of the following table structure is user_name (20 Bytes). Even if it does not reach 36 bytes, because it encounters VARCHAR, it truncates directly and no longer continues.
|
||||
|
||||
|ColumnName|Type|
|
||||
|---|---|
|
||||
|user_name|VARCHAR(20)|
|
||||
|age|INT|
|
||||
|message|VARCHAR(100)|
|
||||
|max\_dwell\_time|DATETIME|
|
||||
|min\_dwell\_time|DATETIME|
|
||||
|
||||
When our query condition is the prefix of ** prefix index **, it can greatly speed up the query speed. For example, in the first example, we execute the following queries:
|
||||
|
||||
`SELECT * FROM table WHERE user_id=1829239 and age=20;`
|
||||
|
||||
The efficiency of this query is much higher than that of ** the following queries:
|
||||
|
||||
`SELECT * FROM table WHERE age=20;`
|
||||
|
||||
Therefore, when constructing tables, ** correctly choosing column order can greatly improve query efficiency **.
|
||||
|
||||
#### ROLLUP adjusts prefix index
|
||||
|
||||
Because column order is specified when a table is built, there is only one prefix index for a table. This may be inefficient for queries that use other columns that cannot hit prefix indexes as conditions. Therefore, we can manually adjust the order of columns by creating ROLLUP. Examples are given.
|
||||
|
||||
The structure of the Base table is as follows:
|
||||
|
||||
|ColumnName|Type|
|
||||
|---|---|
|
||||
|user\_id|BIGINT|
|
||||
|age|INT|
|
||||
|message|VARCHAR(100)|
|
||||
|max\_dwell\_time|DATETIME|
|
||||
|min\_dwell\_time|DATETIME|
|
||||
|
||||
On this basis, we can create a ROLLUP table:
|
||||
|
||||
|ColumnName|Type|
|
||||
|---|---|
|
||||
|age|INT|
|
||||
|user\_id|BIGINT|
|
||||
|message|VARCHAR(100)|
|
||||
|max\_dwell\_time|DATETIME|
|
||||
|min\_dwell\_time|DATETIME|
|
||||
|
||||
As you can see, the columns of ROLLUP and Base tables are exactly the same, just changing the order of user_id and age. So when we do the following query:
|
||||
|
||||
`SELECT * FROM table where age=20 and massage LIKE "%error%";`
|
||||
|
||||
The ROLLUP table is preferred because the prefix index of ROLLUP matches better.
|
||||
|
||||
### Some Explanations of ROLLUP
|
||||
|
||||
* The fundamental role of ROLLUP is to improve the query efficiency of some queries (whether by aggregating to reduce the amount of data or by modifying column order to match prefix indexes). Therefore, the meaning of ROLLUP has gone beyond the scope of "roll-up". That's why we named it Materialized Index in the source code.
|
||||
* ROLLUP is attached to the Base table and can be seen as an auxiliary data structure of the Base table. Users can create or delete ROLLUP based on the Base table, but cannot explicitly specify a query for a ROLLUP in the query. Whether ROLLUP is hit or not is entirely determined by the Doris system.
|
||||
* ROLLUP data is stored in separate physical storage. Therefore, the more ROLLUP you create, the more disk space you occupy. It also has an impact on the speed of import (the ETL phase of import automatically generates all ROLLUP data), but it does not reduce query efficiency (only better).
|
||||
* Data updates for ROLLUP are fully synchronized with Base representations. Users need not care about this problem.
|
||||
* Columns in ROLLUP are aggregated in exactly the same way as Base tables. There is no need to specify or modify ROLLUP when creating it.
|
||||
* A necessary (inadequate) condition for a query to hit ROLLUP is that all columns ** (including the query condition columns in select list and where) involved in the query exist in the column of the ROLLUP. Otherwise, the query can only hit the Base table.
|
||||
* Certain types of queries (such as count (*)) cannot hit ROLLUP under any conditions. See the next section **Limitations of the aggregation model**.
|
||||
* The query execution plan can be obtained by `EXPLAIN your_sql;` command, and in the execution plan, whether ROLLUP has been hit or not can be checked.
|
||||
* Base tables and all created ROLLUP can be displayed by `DESC tbl_name ALL;` statement.
|
||||
|
||||
In this document, you can see [Query how to hit Rollup](hit-the-rollup)
|
||||
|
||||
## Limitations of aggregation model
|
||||
|
||||
Here we introduce the limitations of Aggregate model (including Uniq model).
|
||||
|
||||
@ -36,29 +36,29 @@ Creating and dropping index is essentially a schema change job. For details, ple
|
||||
[Schema Change](alter-table-schema-change.html).
|
||||
|
||||
## Syntax
|
||||
There are two forms of index creation and modification related syntax, one is integrated with alter table statement, and the other is using separate
|
||||
create/drop index syntax
|
||||
1. Create Index
|
||||
### Create index
|
||||
|
||||
Please refer to [CREATE INDEX](../../sql-reference/sql-statements/Data%20Definition/CREATE%20INDEX.html)
|
||||
or [ALTER TABLE](../../sql-reference/sql-statements/Data%20Definition/ALTER%20TABLE.html),
|
||||
You can also specify a bitmap index when creating a table, Please refer to [CREATE TABLE](../../sql-reference/sql-statements/Data%20Definition/CREATE%20TABLE.html)
|
||||
Create a bitmap index for siteid on table1
|
||||
|
||||
2. Show Index
|
||||
```sql
|
||||
CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP COMMENT 'balabala';
|
||||
```
|
||||
|
||||
Please refer to [SHOW INDEX](../../sql-reference/sql-statements/Administration/SHOW%20INDEX.html)
|
||||
### View index
|
||||
|
||||
3. Drop Index
|
||||
Display the lower index of the specified table_name
|
||||
|
||||
Please refer to [DROP INDEX](../../sql-reference/sql-statements/Data%20Definition/DROP%20INDEX.html) or [ALTER TABLE](../../sql-reference/sql-statements/Data%20Definition/ALTER%20TABLE.html)
|
||||
```sql
|
||||
SHOW INDEX FROM example_db.table_name;
|
||||
```
|
||||
|
||||
## Create Job
|
||||
Please refer to [Schema Change](alter-table-schema-change.html)
|
||||
## View Job
|
||||
Please refer to [Schema Change](alter-table-schema-change.html)
|
||||
### Delete index
|
||||
|
||||
## Cancel Job
|
||||
Please refer to [Schema Change](alter-table-schema-change.html)
|
||||
Display the lower index of the specified table_name
|
||||
|
||||
```sql
|
||||
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;
|
||||
```
|
||||
|
||||
## Notice
|
||||
* Currently only index of bitmap type is supported.
|
||||
@ -78,3 +78,7 @@ Please refer to [Schema Change](alter-table-schema-change.html)
|
||||
* `DECIMAL`
|
||||
* `BOOL`
|
||||
* The bitmap index takes effect only in segmentV2. The table's storage format will be converted to V2 automatically when creating index.
|
||||
|
||||
### More Help
|
||||
|
||||
For more detailed syntax and best practices for using bitmap indexes, please refer to the [CREARE INDEX](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-INDEX.md) / [SHOW INDEX](../../sql-manual/sql-reference-v2/Show-Statements/SHOW-INDEX.html) / [DROP INDEX](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-INDEX.html) command manual. You can also enter HELP CREATE INDEX / HELP SHOW INDEX / HELP DROP INDEX on the MySql client command line.
|
||||
|
||||
@ -24,4 +24,56 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Prefix Index
|
||||
# Prefix Index
|
||||
|
||||
## Basic concept
|
||||
|
||||
Unlike traditional database designs, Doris does not support creating indexes on arbitrary columns. OLAP databases with MPP architectures such as Doris usually process large amounts of data by improving concurrency.
|
||||
|
||||
Essentially, Doris' data is stored in a data structure similar to SSTable (Sorted String Table). This structure is an ordered data structure that can be sorted and stored according to the specified column. In this data structure, it is very efficient to use the sorted column as a condition to search.
|
||||
|
||||
In the three data models of Aggregate, Unique and Duplicate. The underlying data storage is sorted and stored according to the columns specified in the AGGREGATE KEY, UNIQUE KEY and DUPLICATE KEY in the respective table creation statements.
|
||||
|
||||
The prefix index, that is, on the basis of sorting, implements an index method to quickly query data according to a given prefix column.
|
||||
|
||||
## Example
|
||||
|
||||
We use the first 36 bytes of a row of data as the prefix index of this row of data. Prefix indexes are simply truncated when a VARCHAR type is encountered. We give an example:
|
||||
|
||||
1. The prefix index of the following table structure is user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes).
|
||||
|
||||
| ColumnName | Type |
|
||||
| -------------- | ------------ |
|
||||
| user_id | BIGINT |
|
||||
| age | INT |
|
||||
| message | VARCHAR(100) |
|
||||
| max_dwell_time | DATETIME |
|
||||
| min_dwell_time | DATETIME |
|
||||
|
||||
2. The prefix index of the following table structure is user_name(20 Bytes). Even if it does not reach 36 bytes, because VARCHAR is encountered, it is directly truncated and will not continue further.
|
||||
|
||||
| ColumnName | Type |
|
||||
| -------------- | ------------ |
|
||||
| user_name | VARCHAR(20) |
|
||||
| age | INT |
|
||||
| message | VARCHAR(100) |
|
||||
| max_dwell_time | DATETIME |
|
||||
| min_dwell_time | DATETIME |
|
||||
|
||||
When our query condition is the prefix of the prefix index, the query speed can be greatly accelerated. For example, in the first example, we execute the following query:
|
||||
|
||||
```sql
|
||||
SELECT * FROM table WHERE user_id=1829239 and age=20;
|
||||
```
|
||||
|
||||
This query will be much more efficient than the following query:
|
||||
|
||||
```sql
|
||||
SELECT * FROM table WHERE age=20;
|
||||
```
|
||||
|
||||
Therefore, when building a table, choosing the correct column order can greatly improve query efficiency.
|
||||
|
||||
## Adjust prefix index by ROLLUP
|
||||
|
||||
Because the column order has been specified when the table is created, there is only one prefix index for a table. This may not be efficient for queries that use other columns that cannot hit the prefix index as conditions. Therefore, we can artificially adjust the column order by creating a ROLLUP. For details, please refer to [ROLLUP](../hit-the-rollup.md).
|
||||
@ -24,4 +24,438 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# 数据模型、ROLLUP 及前缀索引
|
||||
# 数据模型
|
||||
|
||||
本文档主要从逻辑层面,描述 Doris 的数据模型,以帮助用户更好的使用 Doris 应对不同的业务场景。
|
||||
|
||||
## 基本概念
|
||||
|
||||
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。
|
||||
一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
|
||||
|
||||
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。
|
||||
|
||||
Doris 的数据模型主要分为3类:
|
||||
|
||||
- Aggregate
|
||||
- Unique
|
||||
- Duplicate
|
||||
|
||||
下面我们分别介绍。
|
||||
|
||||
## Aggregate 模型
|
||||
|
||||
我们以实际的例子来说明什么是聚合模型,以及如何正确的使用聚合模型。
|
||||
|
||||
### 示例1:导入数据聚合
|
||||
|
||||
假设业务有如下数据表模式:
|
||||
|
||||
| ColumnName | Type | AggregationType | Comment |
|
||||
| --------------- | ----------- | --------------- | -------------------- |
|
||||
| user_id | LARGEINT | | 用户id |
|
||||
| date | DATE | | 数据灌入日期 |
|
||||
| city | VARCHAR(20) | | 用户所在城市 |
|
||||
| age | SMALLINT | | 用户年龄 |
|
||||
| sex | TINYINT | | 用户性别 |
|
||||
| last_visit_date | DATETIME | REPLACE | 用户最后一次访问时间 |
|
||||
| cost | BIGINT | SUM | 用户总消费 |
|
||||
| max_dwell_time | INT | MAX | 用户最大停留时间 |
|
||||
| min_dwell_time | INT | MIN | 用户最小停留时间 |
|
||||
|
||||
如果转换成建表语句则如下(省略建表语句中的 Partition 和 Distribution 信息)
|
||||
|
||||
```sql
|
||||
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
(
|
||||
`user_id` LARGEINT NOT NULL COMMENT "用户id",
|
||||
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
|
||||
`city` VARCHAR(20) COMMENT "用户所在城市",
|
||||
`age` SMALLINT COMMENT "用户年龄",
|
||||
`sex` TINYINT COMMENT "用户性别",
|
||||
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
|
||||
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
|
||||
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
|
||||
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
|
||||
)
|
||||
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
|
||||
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
可以看到,这是一个典型的用户信息和访问行为的事实表。
|
||||
在一般星型模型中,用户信息和访问行为一般分别存放在维度表和事实表中。这里我们为了更加方便的解释 Doris 的数据模型,将两部分信息统一存放在一张表中。
|
||||
|
||||
表中的列按照是否设置了 `AggregationType`,分为 Key (维度列) 和 Value(指标列)。没有设置 `AggregationType` 的,如 `user_id`、`date`、`age` ... 等称为 **Key**,而设置了 `AggregationType` 的称为 **Value**。
|
||||
|
||||
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 `AggregationType` 进行聚合。 `AggregationType` 目前有以下四种聚合方式:
|
||||
|
||||
1. SUM:求和,多行的 Value 进行累加。
|
||||
2. REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
|
||||
3. MAX:保留最大值。
|
||||
4. MIN:保留最小值。
|
||||
|
||||
假设我们有以下导入数据(原始数据):
|
||||
|
||||
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 06:00:00 | 20 | 10 | 10 |
|
||||
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 15 | 2 | 2 |
|
||||
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
|
||||
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
|
||||
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
|
||||
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
|
||||
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
|
||||
|
||||
我们假设这是一张记录用户访问某商品页面行为的表。我们以第一行数据为例,解释如下:
|
||||
|
||||
| 数据 | 说明 |
|
||||
| ------------------- | -------------------------------------- |
|
||||
| 10000 | 用户id,每个用户唯一识别id |
|
||||
| 2017-10-01 | 数据入库时间,精确到日期 |
|
||||
| 北京 | 用户所在城市 |
|
||||
| 20 | 用户年龄 |
|
||||
| 0 | 性别男(1 代表女性) |
|
||||
| 2017-10-01 06:00:00 | 用户本次访问该页面的时间,精确到秒 |
|
||||
| 20 | 用户本次访问产生的消费 |
|
||||
| 10 | 用户本次访问,驻留该页面的时间 |
|
||||
| 10 | 用户本次访问,驻留该页面的时间(冗余) |
|
||||
|
||||
那么当这批数据正确导入到 Doris 中后,Doris 中最终存储如下:
|
||||
|
||||
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
|
||||
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
|
||||
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
|
||||
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
|
||||
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
|
||||
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
|
||||
|
||||
可以看到,用户 10000 只剩下了一行**聚合后**的数据。而其余用户的数据和原始数据保持一致。这里先解释下用户 10000 聚合后的数据:
|
||||
|
||||
前5列没有变化,从第6列 `last_visit_date` 开始:
|
||||
|
||||
- `2017-10-01 07:00:00`:因为 `last_visit_date` 列的聚合方式为 REPLACE,所以 `2017-10-01 07:00:00` 替换了 `2017-10-01 06:00:00` 保存了下来。
|
||||
|
||||
> 注:在同一个导入批次中的数据,对于 REPLACE 这种聚合方式,替换顺序不做保证。如在这个例子中,最终保存下来的,也有可能是 `2017-10-01 06:00:00`。而对于不同导入批次中的数据,可以保证,后一批次的数据会替换前一批次。
|
||||
|
||||
- `35`:因为 `cost` 列的聚合类型为 SUM,所以由 20 + 15 累加获得 35。
|
||||
|
||||
- `10`:因为 `max_dwell_time` 列的聚合类型为 MAX,所以 10 和 2 取最大值,获得 10。
|
||||
|
||||
- `2`:因为 `min_dwell_time` 列的聚合类型为 MIN,所以 10 和 2 取最小值,获得 2。
|
||||
|
||||
经过聚合,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
|
||||
|
||||
### 示例2:保留明细数据
|
||||
|
||||
接示例1,我们将表结构修改如下:
|
||||
|
||||
| ColumnName | Type | AggregationType | Comment |
|
||||
| --------------- | ----------- | --------------- | ---------------------- |
|
||||
| user_id | LARGEINT | | 用户id |
|
||||
| date | DATE | | 数据灌入日期 |
|
||||
| timestamp | DATETIME | | 数据灌入时间,精确到秒 |
|
||||
| city | VARCHAR(20) | | 用户所在城市 |
|
||||
| age | SMALLINT | | 用户年龄 |
|
||||
| sex | TINYINT | | 用户性别 |
|
||||
| last_visit_date | DATETIME | REPLACE | 用户最后一次访问时间 |
|
||||
| cost | BIGINT | SUM | 用户总消费 |
|
||||
| max_dwell_time | INT | MAX | 用户最大停留时间 |
|
||||
| min_dwell_time | INT | MIN | 用户最小停留时间 |
|
||||
|
||||
即增加了一列 `timestamp`,记录精确到秒的数据灌入时间。
|
||||
|
||||
导入数据如下:
|
||||
|
||||
| user_id | date | timestamp | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ------------------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10000 | 2017-10-01 | 2017-10-01 08:00:05 | 北京 | 20 | 0 | 2017-10-01 06:00:00 | 20 | 10 | 10 |
|
||||
| 10000 | 2017-10-01 | 2017-10-01 09:00:05 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 15 | 2 | 2 |
|
||||
| 10001 | 2017-10-01 | 2017-10-01 18:12:10 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
|
||||
| 10002 | 2017-10-02 | 2017-10-02 13:10:00 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
|
||||
| 10003 | 2017-10-02 | 2017-10-02 13:15:00 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
|
||||
| 10004 | 2017-10-01 | 2017-10-01 12:12:48 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
|
||||
| 10004 | 2017-10-03 | 2017-10-03 12:38:20 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
|
||||
|
||||
那么当这批数据正确导入到 Doris 中后,Doris 中最终存储如下:
|
||||
|
||||
| user_id | date | timestamp | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ------------------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10000 | 2017-10-01 | 2017-10-01 08:00:05 | 北京 | 20 | 0 | 2017-10-01 06:00:00 | 20 | 10 | 10 |
|
||||
| 10000 | 2017-10-01 | 2017-10-01 09:00:05 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 15 | 2 | 2 |
|
||||
| 10001 | 2017-10-01 | 2017-10-01 18:12:10 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
|
||||
| 10002 | 2017-10-02 | 2017-10-02 13:10:00 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
|
||||
| 10003 | 2017-10-02 | 2017-10-02 13:15:00 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
|
||||
| 10004 | 2017-10-01 | 2017-10-01 12:12:48 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
|
||||
| 10004 | 2017-10-03 | 2017-10-03 12:38:20 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
|
||||
|
||||
我们可以看到,存储的数据,和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了 `timestamp` 列,所有行的 Key 都**不完全相同**。也就是说,只要保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
|
||||
|
||||
### 示例3:导入数据与已有数据聚合
|
||||
|
||||
接示例1。假设现在表中已有数据如下:
|
||||
|
||||
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
|
||||
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
|
||||
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
|
||||
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
|
||||
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
|
||||
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 10:20:22 | 11 | 6 | 6 |
|
||||
|
||||
我们再导入一批新的数据:
|
||||
|
||||
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 11:22:00 | 44 | 19 | 19 |
|
||||
| 10005 | 2017-10-03 | 长沙 | 29 | 1 | 2017-10-03 18:11:02 | 3 | 1 | 1 |
|
||||
|
||||
那么当这批数据正确导入到 Doris 中后,Doris 中最终存储如下:
|
||||
|
||||
| user_id | date | city | age | sex | last_visit_date | cost | max_dwell_time | min_dwell_time |
|
||||
| ------- | ---------- | ---- | ---- | ---- | ------------------- | ---- | -------------- | -------------- |
|
||||
| 10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 35 | 10 | 2 |
|
||||
| 10001 | 2017-10-01 | 北京 | 30 | 1 | 2017-10-01 17:05:45 | 2 | 22 | 22 |
|
||||
| 10002 | 2017-10-02 | 上海 | 20 | 1 | 2017-10-02 12:59:12 | 200 | 5 | 5 |
|
||||
| 10003 | 2017-10-02 | 广州 | 32 | 0 | 2017-10-02 11:20:00 | 30 | 11 | 11 |
|
||||
| 10004 | 2017-10-01 | 深圳 | 35 | 0 | 2017-10-01 10:00:15 | 100 | 3 | 3 |
|
||||
| 10004 | 2017-10-03 | 深圳 | 35 | 0 | 2017-10-03 11:22:00 | 55 | 19 | 6 |
|
||||
| 10005 | 2017-10-03 | 长沙 | 29 | 1 | 2017-10-03 18:11:02 | 3 | 1 | 1 |
|
||||
|
||||
可以看到,用户 10004 的已有数据和新导入的数据发生了聚合。同时新增了 10005 用户的数据。
|
||||
|
||||
数据的聚合,在 Doris 中有如下三个阶段发生:
|
||||
|
||||
1. 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
|
||||
2. 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
|
||||
3. 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
|
||||
|
||||
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户**只能查询到**聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以**最终的完成的聚合程度**存在,而**不应假设某些聚合还未发生**。(可参阅**聚合模型的局限性**一节获得更多详情。)
|
||||
|
||||
## Unique 模型
|
||||
|
||||
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Unique 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。我们举例说明。
|
||||
|
||||
| ColumnName | Type | IsKey | Comment |
|
||||
| ------------- | ------------ | ----- | ------------ |
|
||||
| user_id | BIGINT | Yes | 用户id |
|
||||
| username | VARCHAR(50) | Yes | 用户昵称 |
|
||||
| city | VARCHAR(20) | No | 用户所在城市 |
|
||||
| age | SMALLINT | No | 用户年龄 |
|
||||
| sex | TINYINT | No | 用户性别 |
|
||||
| phone | LARGEINT | No | 用户电话 |
|
||||
| address | VARCHAR(500) | No | 用户住址 |
|
||||
| register_time | DATETIME | No | 用户注册时间 |
|
||||
|
||||
这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username)。那么我们的建表语句如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
(
|
||||
`user_id` LARGEINT NOT NULL COMMENT "用户id",
|
||||
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
|
||||
`city` VARCHAR(20) COMMENT "用户所在城市",
|
||||
`age` SMALLINT COMMENT "用户年龄",
|
||||
`sex` TINYINT COMMENT "用户性别",
|
||||
`phone` LARGEINT COMMENT "用户电话",
|
||||
`address` VARCHAR(500) COMMENT "用户地址",
|
||||
`register_time` DATETIME COMMENT "用户注册时间"
|
||||
)
|
||||
UNIQUE KEY(`user_id`, `username`)
|
||||
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
而这个表结构,完全同等于以下使用聚合模型描述的表结构:
|
||||
|
||||
| ColumnName | Type | AggregationType | Comment |
|
||||
| ------------- | ------------ | --------------- | ------------ |
|
||||
| user_id | BIGINT | | 用户id |
|
||||
| username | VARCHAR(50) | | 用户昵称 |
|
||||
| city | VARCHAR(20) | REPLACE | 用户所在城市 |
|
||||
| age | SMALLINT | REPLACE | 用户年龄 |
|
||||
| sex | TINYINT | REPLACE | 用户性别 |
|
||||
| phone | LARGEINT | REPLACE | 用户电话 |
|
||||
| address | VARCHAR(500) | REPLACE | 用户住址 |
|
||||
| register_time | DATETIME | REPLACE | 用户注册时间 |
|
||||
|
||||
及建表语句:
|
||||
|
||||
```sql
|
||||
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
(
|
||||
`user_id` LARGEINT NOT NULL COMMENT "用户id",
|
||||
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
|
||||
`city` VARCHAR(20) REPLACE COMMENT "用户所在城市",
|
||||
`age` SMALLINT REPLACE COMMENT "用户年龄",
|
||||
`sex` TINYINT REPLACE COMMENT "用户性别",
|
||||
`phone` LARGEINT REPLACE COMMENT "用户电话",
|
||||
`address` VARCHAR(500) REPLACE COMMENT "用户地址",
|
||||
`register_time` DATETIME REPLACE COMMENT "用户注册时间"
|
||||
)
|
||||
AGGREGATE KEY(`user_id`, `username`)
|
||||
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
即 Unique 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。这里不再继续举例说明。
|
||||
|
||||
## Duplicate 模型
|
||||
|
||||
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求。举例说明。
|
||||
|
||||
| ColumnName | Type | SortKey | Comment |
|
||||
| ---------- | ------------- | ------- | ------------ |
|
||||
| timestamp | DATETIME | Yes | 日志时间 |
|
||||
| type | INT | Yes | 日志类型 |
|
||||
| error_code | INT | Yes | 错误码 |
|
||||
| error_msg | VARCHAR(1024) | No | 错误详细信息 |
|
||||
| op_id | BIGINT | No | 负责人id |
|
||||
| op_time | DATETIME | No | 处理时间 |
|
||||
|
||||
建表语句如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
|
||||
(
|
||||
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
|
||||
`type` INT NOT NULL COMMENT "日志类型",
|
||||
`error_code` INT COMMENT "错误码",
|
||||
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
|
||||
`op_id` BIGINT COMMENT "负责人id",
|
||||
`op_time` DATETIME COMMENT "处理时间"
|
||||
)
|
||||
DUPLICATE KEY(`timestamp`, `type`)
|
||||
DISTRIBUTED BY HASH(`type`) BUCKETS 1
|
||||
PROPERTIES (
|
||||
"replication_allocation" = "tag.location.default: 1"
|
||||
);
|
||||
```
|
||||
|
||||
这种数据模型区别于 Aggregate 和 Unique 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。(更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型。关于 “Sorted Column”的更多解释,可以参阅[前缀索引](./index/prefix-index.html))。在 DUPLICATE KEY 的选择上,我们建议适当的选择前 2-4 列就可以。
|
||||
|
||||
这种数据模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据的存储。更多使用场景,可参阅**聚合模型的局限性**小节。
|
||||
|
||||
## 聚合模型的局限性
|
||||
|
||||
这里我们针对 Aggregate 模型(包括 Unique 模型),来介绍下聚合模型的局限性。
|
||||
|
||||
在聚合模型中,模型对外展现的,是**最终聚合后的**数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
|
||||
|
||||
假设表结构如下:
|
||||
|
||||
| ColumnName | Type | AggregationType | Comment |
|
||||
| ---------- | -------- | --------------- | ------------ |
|
||||
| user_id | LARGEINT | | 用户id |
|
||||
| date | DATE | | 数据灌入日期 |
|
||||
| cost | BIGINT | SUM | 用户总消费 |
|
||||
|
||||
假设存储引擎中有如下两个已经导入完成的批次的数据:
|
||||
|
||||
**batch 1**
|
||||
|
||||
| user_id | date | cost |
|
||||
| ------- | ---------- | ---- |
|
||||
| 10001 | 2017-11-20 | 50 |
|
||||
| 10002 | 2017-11-21 | 39 |
|
||||
|
||||
**batch 2**
|
||||
|
||||
| user_id | date | cost |
|
||||
| ------- | ---------- | ---- |
|
||||
| 10001 | 2017-11-20 | 1 |
|
||||
| 10001 | 2017-11-21 | 5 |
|
||||
| 10003 | 2017-11-22 | 22 |
|
||||
|
||||
可以看到,用户 10001 分属在两个导入批次中的数据还没有聚合。但是为了保证用户只能查询到如下最终聚合后的数据:
|
||||
|
||||
| user_id | date | cost |
|
||||
| ------- | ---------- | ---- |
|
||||
| 10001 | 2017-11-20 | 51 |
|
||||
| 10001 | 2017-11-21 | 5 |
|
||||
| 10002 | 2017-11-21 | 39 |
|
||||
| 10003 | 2017-11-22 | 22 |
|
||||
|
||||
我们在查询引擎中加入了聚合算子,来保证数据对外的一致性。
|
||||
|
||||
另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如我们在如上示例中执行如下查询:
|
||||
|
||||
```
|
||||
SELECT MIN(cost) FROM table;
|
||||
```
|
||||
|
||||
得到的结果是 5,而不是 1。
|
||||
|
||||
同时,这种一致性保证,在某些查询中,会极大的降低查询效率。
|
||||
|
||||
我们以最基本的 count(*) 查询为例:
|
||||
|
||||
```
|
||||
SELECT COUNT(*) FROM table;
|
||||
```
|
||||
|
||||
在其他数据库中,这类查询都会很快的返回结果。因为在实现上,我们可以通过如“导入时对行进行计数,保存 count 的统计信息”,或者在查询时“仅扫描某一列数据,获得 count 值”的方式,只需很小的开销,即可获得查询结果。但是在 Doris 的聚合模型中,这种查询的开销**非常大**。
|
||||
|
||||
我们以刚才的数据为例:
|
||||
|
||||
**batch 1**
|
||||
|
||||
| user_id | date | cost |
|
||||
| ------- | ---------- | ---- |
|
||||
| 10001 | 2017-11-20 | 50 |
|
||||
| 10002 | 2017-11-21 | 39 |
|
||||
|
||||
**batch 2**
|
||||
|
||||
| user_id | date | cost |
|
||||
| ------- | ---------- | ---- |
|
||||
| 10001 | 2017-11-20 | 1 |
|
||||
| 10001 | 2017-11-21 | 5 |
|
||||
| 10003 | 2017-11-22 | 22 |
|
||||
|
||||
因为最终的聚合结果为:
|
||||
|
||||
| user_id | date | cost |
|
||||
| ------- | ---------- | ---- |
|
||||
| 10001 | 2017-11-20 | 51 |
|
||||
| 10001 | 2017-11-21 | 5 |
|
||||
| 10002 | 2017-11-21 | 39 |
|
||||
| 10003 | 2017-11-22 | 22 |
|
||||
|
||||
所以,`select count(*) from table;` 的正确结果应该为 **4**。但如果我们只扫描 `user_id` 这一列,如果加上查询时聚合,最终得到的结果是 **3**(10001, 10002, 10003)。而如果不加查询时聚合,则得到的结果是 **5**(两批次一共5行数据)。可见这两个结果都是不对的。
|
||||
|
||||
为了得到正确的结果,我们必须同时读取 `user_id` 和 `date` 这两列的数据,**再加上查询时聚合**,才能返回 **4** 这个正确的结果。也就是说,在 count(*) 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 `user_id` 和 `date`),并且聚合后,才能得到语意正确的结果。当聚合列非常多时,count(*) 查询需要扫描大量的数据。
|
||||
|
||||
因此,当业务上有频繁的 count(*) 查询时,我们建议用户通过增加一个**值恒为 1 的,聚合类型为 SUM 的列来模拟 count(\*)**。如刚才的例子中的表结构,我们修改如下:
|
||||
|
||||
| ColumnName | Type | AggregateType | Comment |
|
||||
| ---------- | ------ | ------------- | ------------- |
|
||||
| user_id | BIGINT | | 用户id |
|
||||
| date | DATE | | 数据灌入日期 |
|
||||
| cost | BIGINT | SUM | 用户总消费 |
|
||||
| count | BIGINT | SUM | 用于计算count |
|
||||
|
||||
增加一个 count 列,并且导入数据中,该列值**恒为 1**。则 `select count(*) from table;` 的结果等价于 `select sum(count) from table;`。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同的行。否则,`select sum(count) from table;` 只能表述原始导入的行数,而不是 `select count(*) from table;` 的语义。
|
||||
|
||||
另一种方式,就是 **将如上的 `count` 列的聚合类型改为 REPLACE,且依然值恒为 1**。那么 `select sum(count) from table;` 和 `select count(*) from table;` 的结果将是一致的。并且这种方式,没有导入重复行的限制。
|
||||
|
||||
### Duplicate 模型
|
||||
|
||||
Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。
|
||||
|
||||
## 数据模型的选择建议
|
||||
|
||||
因为数据模型在建表时就已经确定,且**无法修改**。所以,选择一个合适的数据模型**非常重要**。
|
||||
|
||||
1. Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
|
||||
2. Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是 REPLACE,没有 SUM 这种聚合方式)。
|
||||
3. Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
|
||||
@ -24,4 +24,64 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Bitmap 索引
|
||||
# Bitmap 索引
|
||||
|
||||
用户可以通过创建bitmap index 加速查询 本文档主要介绍如何创建 index 作业,以及创建 index 的一些注意事项和常见问题。
|
||||
|
||||
## 名词解释
|
||||
|
||||
- bitmap index:位图索引,是一种快速数据结构,能够加快查询速度
|
||||
|
||||
## 原理介绍
|
||||
|
||||
创建和删除本质上是一个 schema change 的作业,具体细节可以参照 [Schema Change](../../advanced/schema-change.html)。
|
||||
|
||||
## 语法
|
||||
|
||||
### 创建索引
|
||||
|
||||
在table1 上为siteid 创建bitmap 索引
|
||||
|
||||
```sql
|
||||
CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP COMMENT 'balabala';
|
||||
```
|
||||
|
||||
### 查看索引
|
||||
|
||||
展示指定 table_name 的下索引
|
||||
|
||||
```sql
|
||||
SHOW INDEX FROM example_db.table_name;
|
||||
```
|
||||
|
||||
### 删除索引
|
||||
|
||||
展示指定 table_name 的下索引
|
||||
|
||||
```sql
|
||||
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;
|
||||
```
|
||||
|
||||
## 注意事项
|
||||
|
||||
- 目前索引仅支持 bitmap 类型的索引。
|
||||
- bitmap 索引仅在单列上创建。
|
||||
- bitmap 索引能够应用在 `Duplicate` 数据模型的所有列和 `Aggregate`, `Uniq` 模型的key列上。
|
||||
- bitmap 索引支持的数据类型如下:
|
||||
- `TINYINT`
|
||||
- `SMALLINT`
|
||||
- `INT`
|
||||
- `UNSIGNEDINT`
|
||||
- `BIGINT`
|
||||
- `CHAR`
|
||||
- `VARCHAR`
|
||||
- `DATE`
|
||||
- `DATETIME`
|
||||
- `LARGEINT`
|
||||
- `DECIMAL`
|
||||
- `BOOL`
|
||||
- bitmap索引仅在 Segment V2 下生效。当创建 index 时,表的存储格式将默认转换为 V2 格式。
|
||||
|
||||
## 更多帮助
|
||||
|
||||
关于 bitmap索引 使用的更多详细语法及最佳实践,请参阅 [CREARE INDEX](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-INDEX.md) / [SHOW INDEX](../../sql-manual/sql-reference-v2/Show-Statements/SHOW-INDEX.html) / [DROP INDEX](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-INDEX.html) 命令手册,你也可以在 MySql 客户端命令行下输入 `HELP CREATE INDEX` / `HELP SHOW INDEX` / `HELP DROP INDEX`。
|
||||
@ -24,4 +24,107 @@ specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# BloomFilter索引
|
||||
# BloomFilter索引
|
||||
|
||||
BloomFilter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合,BloomFilter有以下特点:
|
||||
|
||||
- 空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
|
||||
- 对于一个元素检测是否存在的调用,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在。
|
||||
- 缺点是存在误判,告诉你可能存在,不一定真实存在。
|
||||
|
||||
布隆过滤器实际上是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。
|
||||
|
||||
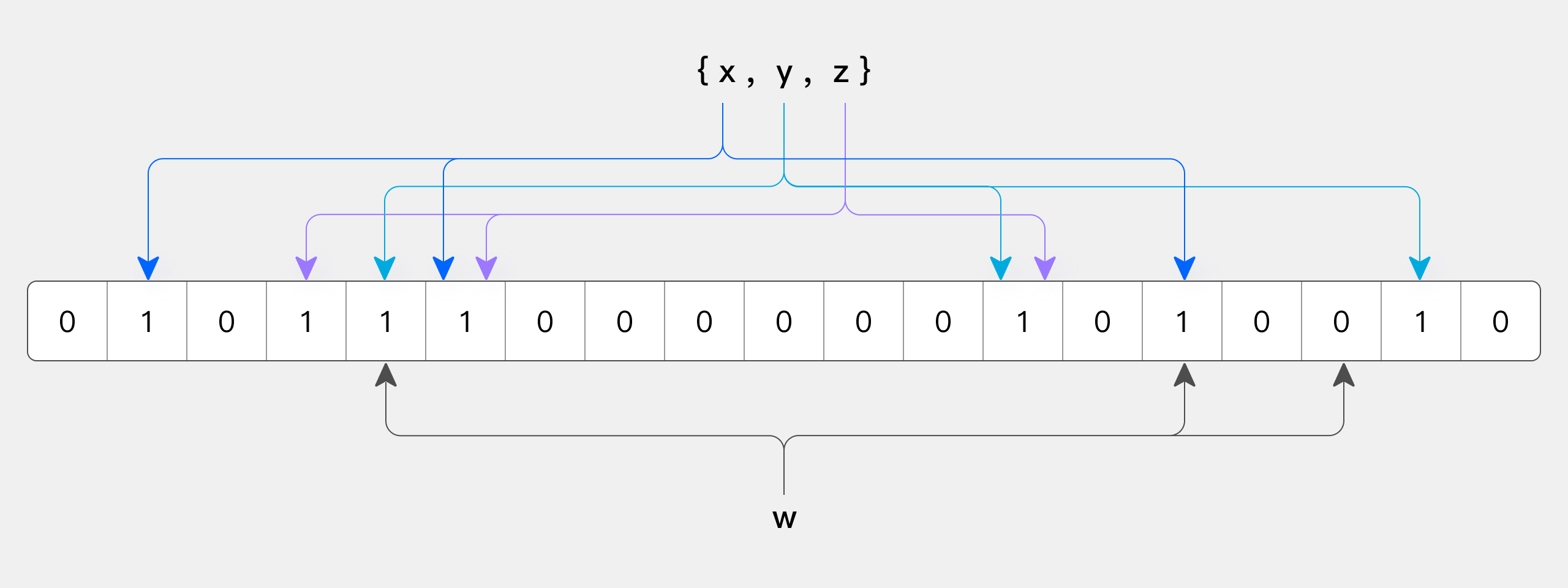
下图所示出一个 m=18, k=3 (m是该Bit数组的大小,k是Hash函数的个数)的Bloom Filter示例。集合中的 x、y、z 三个元素通过 3 个不同的哈希函数散列到位数组中。当查询元素w时,通过Hash函数计算之后因为有一个比特为0,因此w不在该集合中。
|
||||
|
||||
|
||||
|
||||
那么怎么判断谋和元素是否在集合中呢?同样是这个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为1,则判断这个元素在这个集合中,若有一个不为1,则判断这个元素不在这个集合中。就是这么简单!
|
||||
|
||||
## Doris BloomFilter索引及使用使用场景
|
||||
|
||||
我们在使用HBase的时候,知道Hbase数据块索引提供了一个有效的方法,在访问一个特定的行时用来查找应该读取的HFile的数据块。但是它的效用是有限的。HFile数据块的默认大小是64KB,这个大小不能调整太多。
|
||||
|
||||
如果你要查找一个短行,只在整个数据块的起始行键上建立索引无法给你细粒度的索引信息。例如,如果你的行占用100字节存储空间,一个64KB的数据块包含(64 * 1024)/100 = 655.53 = ~700行,而你只能把起始行放在索引位上。你要查找的行可能落在特定数据块上的行区间里,但也不是肯定存放在那个数据块上。这有多种情况的可能,或者该行在表里不存在,或者存放在另一个HFile里,甚至在MemStore里。这些情况下,从硬盘读取数据块会带来IO开销,也会滥用数据块缓存。这会影响性能,尤其是当你面对一个巨大的数据集并且有很多并发读用户时。
|
||||
|
||||
所以HBase提供了布隆过滤器允许你对存储在每个数据块的数据做一个反向测试。当某行被请求时,先检查布隆过滤器看看该行是否不在这个数据块。布隆过滤器要么确定回答该行不在,要么回答它不知道。这就是为什么我们称它是反向测试。布隆过滤器也可以应用到行里的单元上。当访问某列标识符时先使用同样的反向测试。
|
||||
|
||||
布隆过滤器也不是没有代价。存储这个额外的索引层次占用额外的空间。布隆过滤器随着它们的索引对象数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以帮助你榨干系统的性能潜力。
|
||||
|
||||
Doris的BloomFilter索引是从通过建表的时候指定,或者通过表的ALTER操作来完成。Bloom Filter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回false,则一定不在这个集合内。而如果范围true,则有可能在这个集合内。
|
||||
|
||||
BloomFilter索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询是快速过滤不满足条件的数据。
|
||||
|
||||
下面我们通过实例来看看Doris怎么创建BloomFilter索引。
|
||||
|
||||
### 创建BloomFilter索引
|
||||
|
||||
Doris BloomFilter索引的创建是通过在建表语句的PROPERTIES里加上"bloom_filter_columns"="k1,k2,k3",这个属性,k1,k2,k3是你要创建的BloomFilter索引的Key列名称,例如下面我们对表里的saler_id,category_id创建了BloomFilter索引。
|
||||
|
||||
```sql
|
||||
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
|
||||
sale_date date NOT NULL COMMENT "销售时间",
|
||||
customer_id int NOT NULL COMMENT "客户编号",
|
||||
saler_id int NOT NULL COMMENT "销售员",
|
||||
sku_id int NOT NULL COMMENT "商品编号",
|
||||
category_id int NOT NULL COMMENT "商品分类",
|
||||
sale_count int NOT NULL COMMENT "销售数量",
|
||||
sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",
|
||||
sale_amt DECIMAL(20,2) COMMENT "销售总金额"
|
||||
)
|
||||
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
|
||||
PARTITION BY RANGE(sale_date)
|
||||
(
|
||||
PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01'))
|
||||
)
|
||||
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
|
||||
PROPERTIES (
|
||||
"replication_num" = "3",
|
||||
"bloom_filter_columns"="saler_id,category_id",
|
||||
"dynamic_partition.enable" = "true",
|
||||
"dynamic_partition.time_unit" = "MONTH",
|
||||
"dynamic_partition.time_zone" = "Asia/Shanghai",
|
||||
"dynamic_partition.start" = "-2147483648",
|
||||
"dynamic_partition.end" = "2",
|
||||
"dynamic_partition.prefix" = "P_",
|
||||
"dynamic_partition.replication_num" = "3",
|
||||
"dynamic_partition.buckets" = "3"
|
||||
);
|
||||
```
|
||||
|
||||
### 查看BloomFilter索引
|
||||
|
||||
查看我们在表上建立的BloomFilter索引是使用:
|
||||
|
||||
```sql
|
||||
SHOW CREATE TABLE <table_name>
|
||||
```
|
||||
|
||||
### 删除BloomFilter索引
|
||||
|
||||
删除索引即为将索引列从bloom_filter_columns属性中移除:
|
||||
|
||||
```sql
|
||||
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");
|
||||
```
|
||||
|
||||
### 修改BloomFilter索引
|
||||
|
||||
修改索引即为修改表的bloom_filter_columns属性:
|
||||
|
||||
```sql
|
||||
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");
|
||||
```
|
||||
|
||||
### **Doris BloomFilter使用场景**
|
||||
|
||||
满足以下几个条件时可以考虑对某列建立Bloom Filter 索引:
|
||||
|
||||
1. 首先BloomFilter适用于非前缀过滤.
|
||||
2. 查询会根据该列高频过滤,而且查询条件大多是in和 = 过滤.
|
||||
3. 不同于Bitmap, BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如”性别“列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义
|
||||
|
||||
### **Doris BloomFilter使用注意事项**
|
||||
|
||||
1. 不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
|
||||
2. Bloom Filter索引只对in和 = 过滤查询有加速效果。
|
||||
3. 如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看
|
||||
@ -23,4 +23,56 @@ KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
# 前缀索引
|
||||
# 前缀索引
|
||||
|
||||
## 基本概念
|
||||
|
||||
不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
|
||||
|
||||
本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
|
||||
|
||||
在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
|
||||
|
||||
而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
|
||||
|
||||
## 示例
|
||||
|
||||
我们将一行数据的前 **36 个字节** 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。我们举例说明:
|
||||
|
||||
1. 以下表结构的前缀索引为 user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
|
||||
|
||||
| ColumnName | Type |
|
||||
| -------------- | ------------ |
|
||||
| user_id | BIGINT |
|
||||
| age | INT |
|
||||
| message | VARCHAR(100) |
|
||||
| max_dwell_time | DATETIME |
|
||||
| min_dwell_time | DATETIME |
|
||||
|
||||
2. 以下表结构的前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。
|
||||
|
||||
| ColumnName | Type |
|
||||
| -------------- | ------------ |
|
||||
| user_name | VARCHAR(20) |
|
||||
| age | INT |
|
||||
| message | VARCHAR(100) |
|
||||
| max_dwell_time | DATETIME |
|
||||
| min_dwell_time | DATETIME |
|
||||
|
||||
当我们的查询条件,是**前缀索引的前缀**时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
|
||||
|
||||
```sql
|
||||
SELECT * FROM table WHERE user_id=1829239 and age=20;
|
||||
```
|
||||
|
||||
该查询的效率会**远高于**如下查询:
|
||||
|
||||
```sql
|
||||
SELECT * FROM table WHERE age=20;
|
||||
```
|
||||
|
||||
所以在建表时,**正确的选择列顺序,能够极大地提高查询效率**。
|
||||
|
||||
## 通过ROLLUP来调整前缀索引
|
||||
|
||||
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。详情可参考[ROLLUP](../hit-the-rollup.md)。
|
||||
Reference in New Issue
Block a user