8.0 KiB
执行计划展示 (EXPLAIN)
SQL 执行计划的展示是了解 SQL 执行逻辑和性能调优的最重要的手段。用户可以通过 EXPLAIN 命令查看优化器针对给定 SQL 生成的逻辑执行计划。在执行 EXPLAIN 命令时,系统会为给定的 SQL 生成最终的逻辑执行计划并展示给用户,但并不会生成相应的物理执行计划(可执行的代码),也不会真正执行该计划或者将该计划放入计划缓存。
由于 EXPLAIN 并不会真正执行给定的 SQL,用户一般可以放心使用该功能而不用担心在性能调试中可能给系统性能带来影响。也正是因为没有真正执行 SQL,EXPLAIN 所展示的计划是在执行命令时优化器根据当前的用户输入和数据统计信息所生成的逻辑执行计划,而并不是在计划缓存中真正被使用的物理执行计划(二者在某些场景下可能会有不同)。展示计划缓存中的物理计划的方式请参考 实时执行计划展示。
EXPLAIN 命令格式
EXPLAIN 命令格式如下例所示,展示的格式包括 BASIC、EXTENDED、PARTITIONS 等等,内容的详细程度有所区别。
EXPLAIN [BASIC | EXTENDED | PARTITIONS | FORMAT = format_name] explainable_stmt
format_name: { TRADITIONAL | JSON }
explainable_stmt: { SELECT statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement }
计划形状与算子信息
EXPLAIN 输出的第一部分是执行计划的树形结构展示。其中每一个操作在树中的层次通过其在 operator 中的缩进予以展示。如下例所示的执行计划:
|==========================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------------
|0 |SORT | |1 |2763|
|1 | MERGE INNER JOIN| |1 |2735|
|2 | SORT | |1000 |1686|
|3 | TABLE SCAN |t2 |1000 |1180|
|4 | TABLE SCAN |t1 |1 |815 |
==========================================
其对应的树状执行计划如下图所示:
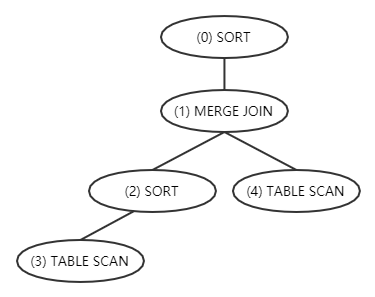
表格中的各项的含义如下:
| 列名 | 含义 |
|---|---|
| ID | 执行树按照前序遍历的方式得到的编号(从0 开始) |
| OPERATOR | 操作算子的名称 |
| NAME | 对应表操作的表名(索引名) |
| EST. ROWS | 估算的该操作算子的输出行数 |
| COST | 该操作算子的执行代价(微秒) |
在表操作中,name 字段会显示该操作涉及的表的名称(别名),如果是使用索引访问,还会在名称后的括号中展示该索引的名称, 例如 t1(t1_c2) 表示使用了 t1_c2 这个索引。另外,如果扫描的顺序是逆序,还会在后面使用 reserve 关键字标识,例如 t1(t1_c2,reverse)。
一些常见的算子类型归纳如下表:
| 类型 | 算子 |
|---|---|
| 表访问 | TABLE SCAN, TABLE GET |
| 连接 | NESTED-LOOP, BLK-NESTED-LOOP,MERGE、HASH |
| 排序 | SORT,TOP-N SORT |
| 聚合 | MERGE GROUP-BY,HASH GROUP-BY, WINDOW FUNCTION |
| 分布式 | EXCHANGE IN/OUT REMOTE/DISTRIBUTE |
| 集合 | UNION, EXCEPT, INTERSECT,MINUS |
| 其他 | LIMIT, MATERIAL, SUBPLAN, EXPRESSION, COUNT |
操作算子详细输出
EXPLAIN 输出的第二部分是各操作算子的详细信息,包括输出表达式、过滤条件、分区信息以及各算子的独有信息,包括排序键、连接键、下压条件等。
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), sort_keys([t1.c1, ASC], [t1.c2, ASC]), prefix_pos(1)
1 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil),
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
2 - output([t2.c1], [t2.c2]), filter(nil), sort_keys([t2.c2, ASC])
3 - output([t2.c2], [t2.c1]), filter(nil),
access([t2.c2], [t2.c1]), partitions(p0)
4 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)
重点的信息如下:
-
output在执行树中每一个算子都需要向上游算子输出一些表达式以供后面的计算,也叫做投影操作,这里列出了需要进行投影的表达式(包括普通列)。
-
filtersOceanBase 数据库的所有算子都有执行过滤条件的能力,
filters列出了该算子需要执行的过滤操作,对于表访问操作,我们会将所有过滤条件(包括回表前后的过滤条件都下压到存储层)。
-
access表访问操作中需要调用存储层的接口访问具体的数据,
access展示了存储层的对外输出(投影)列名。
-
is_index_back和filter_before_indexbackOceanBase 数据库区分了哪些过滤条件可以在索引回表前执行,哪些需要在回表后执行,这个标示可以通过
filter_before_indexback得到。如果表操作所有的filter都可以再回表前执行,则is_index_back为 true,否则为 false。
-
partitionsOceanBase 数据库内部支持二级分区。针对用户 SQL 给定的条件,优化器会将不需要访问的分区过滤掉,这一步骤我们称为分区裁剪。
partitions显示了经过分区裁剪后剩下的分区,其中如果涉及到多个连续分区,例如从分区 0 到分区 20,会按照"起始分区号------结束分区号"的形式展示,例如partitions(p0-20)。 -
range_key和rangeOceanBase 数据库中的物理表理论上都是索引组织表(包括二级索引本身),扫描的时候都会按照一定的顺序进行扫面,这个顺序就是该表的主键,体现在
range_key中,当用户给定不同条件时,优化器会定位到最终扫描的范围,通过range展示,如下例所示的计划:
obclient> explain extended
select /*+ index(t1 t1_c2) */* from t1 where c3 = 5 and c1 = 6 order by c2, c3;
========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------
|0 |TABLE SCAN|t1(t1_c2)|1 |1255|
========================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1(0x7f1d520a0a98)], [t1.c2(0x7f1d520a0d98)], [t1.c3(0x7f1d5209fbe0)]), filter([t1.c3(0x7f1d5209fbe0) = 5(0x7f1d5209f5d8)], [t1.c1(0x7f1d520a0a98) = 6(0x7f1d520a0490)]),
access([t1.c3(0x7f1d5209fbe0)], [t1.c1(0x7f1d520a0a98)], [t1.c2(0x7f1d520a0d98)]), partitions(p0),
is_index_back=true, filter_before_indexback[false,true],
range_key([t1.c2(0x7f1d520a0d98)], [t1.c1(0x7f1d520a0a98)]), range(MIN,MIN ; MAX,MAX)always true
可以看出要访问的表为 t1_c2 这张索引表,表的主键为 (c2, c1),扫描的范围是全表扫描。
-
sort_keys排序操作的排序键,包括其排序方向。
一些常用的信息含义如下表:
| 信息名称 | 含义 |
|---|---|
| output | 该算子的输出表达式列表 |
| filter | 该算子执行的过滤条件 |
| access | 表访问中存储层的投影列名 |
| partitions | 分区裁剪的信息 |
| sort_keys | 排序操作的排序键 |
| prefix_pos | 局部有序的偏移位置 |
| equal_conds | 连接操作中执行的等值连接条件 |
| other_conds | 连接操作中执行的非等值连接条件 |