236 lines
7.0 KiB
Markdown
236 lines
7.0 KiB
Markdown
分布式执行计划管理
|
|
==============================
|
|
|
|
分布式执行计划可以使用 Hint 管理,以提高 SQL 查询性能。
|
|
|
|
分布式执行框架支持的 Hint 包括 `ORDERED`、`LEADING`、`USE_NL`、`USE_HASH` 和 `USE_MERGE` 等。
|
|
|
|
NO_USE_PX
|
|
------------------------------
|
|
|
|
如果某个查询确定不走并行执行框架,使用 `NO_USE_PX` 拉回数据并生成本地执行计划。
|
|
|
|
PARALLEL
|
|
-----------------------------
|
|
|
|
指定分布式执行的并行度。启用 3 个 Worker 并行执行扫描,如下例所示:
|
|
|
|
```sql
|
|
obclient>SELECT /*+ PARALLEL(3) */ MAX(L_QUANTITY) FROM table_name;
|
|
```
|
|
|
|
|
|
**注意**
|
|
|
|
|
|
|
|
在复杂查询中,调度器可以调度 2 个 DFO 并行流水执行,此时,启用的 Worker 数量为并行度的 2倍,即 `PARALLEL * 2`。
|
|
|
|
ORDERED
|
|
----------------------------
|
|
|
|
`ORDERED` Hint 指定并行查询计划中 `JOIN` 的顺序,严格按照 `FROM` 语句中的顺序生成。
|
|
|
|
如下例所示,强制要求 `customer` 为左表,`orders` 为右表,并且使用 `NESTED LOOP JOIN`:
|
|
|
|
```javascript
|
|
obclient>CREATE TABLE lineitem(
|
|
l_orderkey NUMBER(20) NOT NULL ,
|
|
|
|
l_linenumber NUMBER(20) NOT NULL ,
|
|
l_quantity NUMBER(20) NOT NULL ,
|
|
l_extendedprice DECIMAL(10,2) NOT NULL ,
|
|
l_discount DECIMAL(10,2) NOT NULL ,
|
|
l_tax DECIMAL(10,2) NOT NULL ,
|
|
|
|
l_shipdate DATE NOT NULL,
|
|
|
|
PRIMARY KEY(L_ORDERKEY, L_LINENUMBER));
|
|
Query OK, 1 row affected (0.00 sec)
|
|
|
|
obclient>CREATE TABLE customer(
|
|
c_custkey NUMBER(20) NOT NULL ,
|
|
c_name VARCHAR(25) DEFAULT NULL,
|
|
c_address VARCHAR(40) DEFAULT NULL,
|
|
c_nationkey NUMBER(20) DEFAULT NULL,
|
|
c_phone CHAR(15) DEFAULT NULL,
|
|
c_acctbal DECIMAL(10,2) DEFAULT NULL,
|
|
c_mktsegment CHAR(10) DEFAULT NULL,
|
|
c_comment VARCHAR(117) DEFAULT NULL,
|
|
PRIMARY KEY(c_custkey));
|
|
Query OK, 1 row affected (0.00 sec)
|
|
|
|
obclient>CREATE TABLE orders(
|
|
o_orderkey NUMBER(20) NOT NULL ,
|
|
o_custkey NUMBER(20) NOT NULL ,
|
|
o_orderstatus CHAR(1) DEFAULT NULL,
|
|
o_totalprice DECIMAL(10,2) DEFAULT NULL,
|
|
o_orderdate DATE NOT NULL,
|
|
o_orderpriority CHAR(15) DEFAULT NULL,
|
|
o_clerk CHAR(15) DEFAULT NULL,
|
|
o_shippriority NUMBER(20) DEFAULT NULL,
|
|
o_comment VARCHAR(79) DEFAULT NULL,
|
|
PRIMARY KEY(o_orderkey,o_orderdate,o_custkey));
|
|
Query OK, 1 row affected (0.00 sec)
|
|
|
|
obclient> INSERT INTO lineitem VALUES(1,2,3,6.00,0.20,0.01,'01-JUN-02');
|
|
Query OK, 1 row affected (0.01 sec)
|
|
|
|
obclient> INSERT INTO customer VALUES(1,'Leo',null,null,'13700461258',null,'BUILDING',null);
|
|
Query OK, 1 row affected (0.01 sec)
|
|
|
|
obclient> INSERT INTO orders VALUES(1,1,null,null,'01-JUN-20',10,null,8,null);
|
|
Query OK, 1 row affected (0.00 sec)
|
|
|
|
obclient>SELECT /*+ ORDERED USE_NL(orders) */o_orderdate, o_shippriority
|
|
FROM customer, orders WHERE c_mktsegment = 'BUILDING' AND
|
|
c_custkey = o_custkey GROUP BY o_orderdate, o_shippriority;
|
|
|
|
+-------------+----------------+
|
|
| O_ORDERDATE | O_SHIPPRIORITY |
|
|
+-------------+----------------+
|
|
| 01-JUN-20 | 8 |
|
|
+-------------+----------------+
|
|
1 row in set (0.01 sec)
|
|
```
|
|
|
|
|
|
|
|
在手写 SQL 时,`ORDERED` 较为有用,用户知道 `JOIN` 的最佳顺序时,可以将表按照顺序写在 `FROM` 的后面,然后加上 `ORDERED` Hint。
|
|
|
|
LEADING
|
|
----------------------------
|
|
|
|
`LEADING` Hint 指定并行查询计划中最先 `JOIN` 哪些表,`LEADING` 中的表从左到右的顺序,也是 `JOIN` 的顺序。它比 `ORDERED` 有更大的灵活性。
|
|
**注意**
|
|
|
|
|
|
|
|
如果 `ORDERED` 和 `LEADING` 同时使用,仅 `ORDERED` 生效。
|
|
|
|
PQ_DISTRIBUTE
|
|
----------------------------------
|
|
|
|
PQ Hint 即 `PQ_DISTRIBUTE`,用于指定并行查询计划中的数据分布方式。PQ Hint 会改变分布式 `JOIN` 时的数据分发方式。
|
|
|
|
PQ Hint 的基本语法如下:
|
|
|
|
```unknow
|
|
PQ_DISTRIBUTE(tablespec outer_distribution inner_distribution)
|
|
```
|
|
|
|
|
|
|
|
参数解释如下:
|
|
|
|
* `tablespec` 指定关注的表,关注 `JOIN` 的右表。
|
|
|
|
|
|
|
|
* `outer_distribution` 指定左表的数据分发方式。
|
|
|
|
|
|
|
|
* `inner_distribution` 指定右表的数据分发方式。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
两表的数据分发方式共有以下六种:
|
|
|
|
* `HASH`, `HASH`
|
|
|
|
|
|
|
|
* `BROADCAST`, `NONE`
|
|
|
|
|
|
|
|
* `NONE`, `BROADCAST`
|
|
|
|
|
|
|
|
* `PARTITION`, `NONE`
|
|
|
|
|
|
|
|
* `NONE`, `PARTITION`
|
|
|
|
|
|
|
|
* `NONE`, `NONE`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其中,带分区的两种分发方式要求左表或右表有分区,而且分区键就是 `JOIN` 的键。如果不满足要求的话,PQ Hint 不会生效。
|
|
|
|
```sql
|
|
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT, c3 INT, c4 DATE);
|
|
Query OK, 0 rows affected (0.09 sec)
|
|
|
|
obclient>CREATE INDEX i1 ON t1(c3);
|
|
Query OK, 0 rows affected (0.09 sec)
|
|
|
|
obclient>CREATE TABLE t2(c1 INT(11) NOT NULL, c2 INT(11) NOT NULL, c3 INT(11)
|
|
NOT NULL,
|
|
PRIMARY KEY (c1, c2, c3)) PARTITION BY KEY(c2) PARTITIONS 4;
|
|
Query OK, 0 rows affected (0.09 sec)
|
|
|
|
obclient>EXPLAIN BASIC SELECT /*+USE_PX PARALLEL(3) PQ_DISTRIBUTE
|
|
(t2 BROADCAST NONE) LEADING(t1 t2)*/ * FROM t1 JOIN t2 ON
|
|
t1.c2 = t2.c2\G;
|
|
*************************** 1. row ***************************
|
|
Query Plan:
|
|
================================================
|
|
|ID|OPERATOR |NAME |
|
|
------------------------------------------------
|
|
|0 |EXCHANGE IN DISTR | |
|
|
|1 | EXCHANGE OUT DISTR |:EX10001|
|
|
|2 | HASH JOIN | |
|
|
|3 | EXCHANGE IN DISTR | |
|
|
|4 | EXCHANGE OUT DISTR (BROADCAST)|:EX10000|
|
|
|5 | PX BLOCK ITERATOR | |
|
|
|6 | TABLE SCAN |t1 |
|
|
|7 | PX BLOCK ITERATOR | |
|
|
|8 | TABLE SCAN |t2 |
|
|
================================================
|
|
```
|
|
|
|
|
|
|
|
USE_NL
|
|
---------------------------
|
|
|
|
`USE_NL` Hint 指定使用 `NESTED LOOP JOIN`,并且需要满足 `USE_NL` 中指定的表是 `JOIN` 的右表。
|
|
|
|
如下例所示,如果希望 `join1` 为 `NESTED LOOP JOIN`,则 Hint 写法为 `LEADING(a, (b,c)) USE_NL((b,c))`。
|
|
|
|
当 `USE_NLJ` 和 `ORDERED`、`LEADING` Hint 一起使用时,如果 `USE_NLJ` 中注明的表不是右表,则 `USE_NLJ` Hint 会被忽略。
|
|
|
|
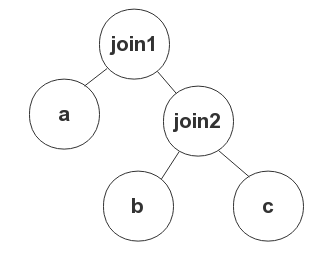
|
|
|
|
USE_HASH
|
|
-----------------------------
|
|
|
|
`USE_HASH` Hint 指定使用 `HASH JOIN`,并且需要满足 `USE_HASH` 中指定的表是 `JOIN` 的右表。
|
|
**注意**
|
|
|
|
|
|
|
|
如果没有使用 `ORDERED` 和 `LEADING` Hint,并且优化器生成的联接顺序中指定的表之间不是直接 `JOIN` 的关系,那么 `USE_HASH` Hint 会被忽略。
|
|
|
|
USE_MERGE
|
|
------------------------------
|
|
|
|
`USE_MERGE` Hint 指定使用 `MERGE JOIN`,并且需要满足 `USE_MERGE` 中指定的表是 `JOIN` 的右表。
|
|
**注意**
|
|
|
|
|
|
|
|
如果没有使用 `ORDERED` 和 `LEADING` Hint,并且优化器生成的联接顺序中指定的表之间不是直接 `JOIN` 的关系,那么 `USE_MERGE` Hint 会被忽略。
|